近年来,对深度学习的需求不断增长,其应用程序被应用于各个商业部门。各公司现在都在寻找能够利用深度学习和机器学习技术的专业人士。在本文中,将整理深度学习面试中最常被问到的25个问题和答案。如果你最近正在参加深度学习相关的面试工作,那么这些问题会对你有所帮助。
1、什么是深度学习?
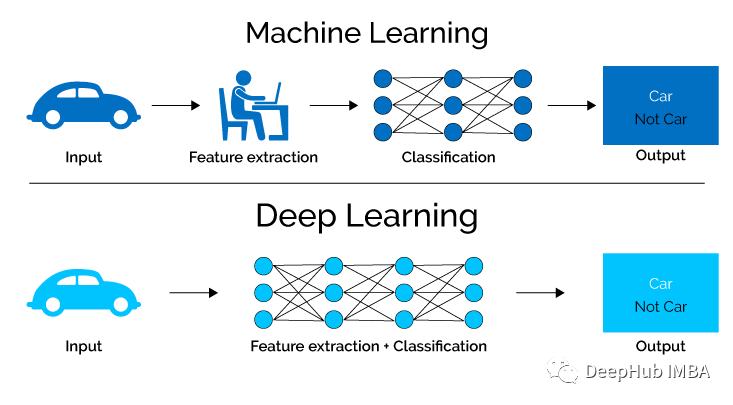
深度学习涉及获取大量结构化或非结构化数据,并使用复杂算法训练神经网络。它执行复杂的操作来提取隐藏的模式和特征(例如,区分猫和狗的图像)
2、什么是神经网络?
神经网络复制了人类的学习方式,灵感来自于我们大脑中的神经元是如何激活的,但是比人类大脑要简单得多。
最常见的神经网络由三个网络层组成:
神经网络用于深度学习算法,如CNN, RNN, GAN等。
3、什么是多层感知机(MLP)?
和神经网络一样,mlp有一个输入层、一个隐藏层和一个输出层。它与具有一个或多个隐藏层的单层感知器的的结构相同。单层感知器只能对具有二进制输出 (0,1) 的线性可分类进行分类,但 MLP 可以对非线性类进行分类。
除输入层外,其他层中的每个节点都使用非线性激活函数。输入层、传入的数据和激活函数基于所有节点和权重相加从而产生输出。MLP 使用一种称为“反向传播”的方法来优化节点的权重。在反向传播中,神经网络在损失函数的帮助下计算误差,从误差的来源向后传播此误差(调整权重以更准确地训练模型)。
4、什么是数据规范化(Normalization),我们为什么需要它?
Normalization的中文翻译一般叫做“规范化”,是一种对数值的特殊函数变换方法,也就是说假设原始的某个数值是x,套上一个起到规范化作用的函数,对规范化之前的数值x进行转换,形成一个规范化后的数值。
规范化将越来越偏的分布拉回到标准化的分布,使得激活函数的输入值落在激活函数对输入比较敏感的区域,从而使梯度变大,加快学习收敛速度,避免梯度消失的问题。
按照规范化操作涉及对象的不同可以分为两大类:
一类是对第L层每个神经元的激活值 进行Normalization操作,比如BatchNorm/ LayerNorm/ InstanceNorm/ GroupNorm等方法都属于这一类;
另外一类是对神经网络中连接相邻隐层神经元之间的边上的权重进行规范化操作,比如Weight Norm就属于这一类。
一般机器学习里看到的损失函数里面加入的对参数的的L1/L2等正则项,本质上也属于这这一类的规范化操作。
L1正则的规范化目标是造成参数的稀疏化,就是争取达到让大量参数值取得0值的效果,而L2正则的规范化目标是有效减小原始参数值的大小。
有了这些规范目标,通过具体的规范化手段来改变参数值,以达到避免模型过拟合的目的。
5、什么是玻尔兹曼机?
最基本的深度学习模型之一是玻尔兹曼机,类似于多层感知器的简化版本。这个模型有一个可见的输入层和一个隐藏层——只是一个两层的神经网络,可以随机决定一个神经元应该打开还是关闭。节点跨层连接,但同一层的两个节点没有连接。
6、激活函数在神经网络中的作用是什么?
激活函数模拟生物学中的神经元是否应该被激发。它接受输入和偏差的加权和作为任何激活函数的输入。从数学角度讲引入激活函数是为了增加神经网络模型的非线性。Sigmoid、ReLU、Tanh 都是常见的激活函数。
7、什么是成本函数?
成本函数也被称为“损失”或“误差”,它是评估模型性能好坏的一种度量方法。它用于计算反向传播过程中输出层的误差。我们通过神经网络将错误向后推并在不同的训练函数中使用它。
8、什么是梯度下降?
梯度下降是一种最小化成本函数或最小化误差的最优算法。目的是找到一个函数的局部全局极小值。这决定了模型应该采取的减少误差的方向。
9、反向传播是什么?
这是深度学习面试中最常被问到的问题之一。
1974年,Paul Werbos首次给出了如何训练一般网络的学习算法—back propagation。这个算法可以高效的计算每一次迭代过程中的梯度。反向传播算法是目前用来训练人工神经网络(Artificial Neural Network,ANN)的最常用且最有效的算法。其主要思想是:
(1)将训练集数据输入到ANN的输入层,经过隐藏层,最后达到输出层并输出结果,这是ANN的前向传播过程;
(2)由于ANN的输出结果与实际结果有误差,则计算估计值与实际值之间的误差,并将该误差从输出层向隐藏层反向传播,直至传播到输入层;
(3)在反向传播的过程中,根据误差调整各种参数的值;不断迭代上述过程,直至收敛。
10、前馈神经网络和循环神经网络有什么区别?
前馈神经网络信号从输入到输出沿一个方向传播。没有反馈回路;网络只考虑当前输入。它无法记住以前的输入(例如 CNN)。
循环神经网络的信号双向传播,形成一个循环网络。它考虑当前输入和先前接收到的输入,以生成层的输出,并且由于其内部存储器,它可以记住过去的数据。
11、循环神经网络 (RNN) 有哪些应用?
RNN 可用于情感分析、文本挖掘等,可以解决时间序列问题,例如预测一个月或季度的股票价格。
12、Softmax 和 ReLU 函数是什么?
Softmax 是一种激活函数,可生成介于 0 和 1 之间的输出。它将每个输出除以所有输出的总和,使得输出的总和等于 1。Softmax 通常用于分类任务的输出层和注意力机制的计算。
ReLU是使用最广泛的激活函数。如果 X 为正,则输出 X,否则为零。ReLU 常用于隐藏层的激活函数。
13、什么是超参数?
这是另一个经常被问到的深度学习面试问题。超参数在机器学习的上下文中,超参数是在开始学习过程之前设置值的参数,而不是通过训练得到的参数数据。因为一般情况下我们将可以根据模型自身的算法,通过数据迭代自动学习出的变量称为参数,而超参数的设置可以影响到这些参数是如何训练,所以称其为超参数。
14、如果学习率设置得太低或太高会发生什么?
当学习率太低时,模型的训练将进展得非常缓慢,因为只对权重进行最小的更新。它需要多次更新才能达到最小值。如果非常小可能最终的梯度可能不会跳出局部最小值,导致训练的结果并不是最优解。
如果学习率设置得太高,由于权重的急剧更新,这将导致损失函数出现不希望的发散行为。可能导致模型无法收敛,甚至发散(网络无法训练)。
15、什么是Dropout和BN?
Dropout是一种随机删除网络中隐藏和可见单元的技术,可以以防止数据过拟合(通常删除20%内的节点)。它使收敛网络所需的迭代次数增加。
BN是一种通过对每一层的输入进行规范化,变为平均为0,标准差为1的正态分布,从而提高神经网络性能和稳定性的技术。
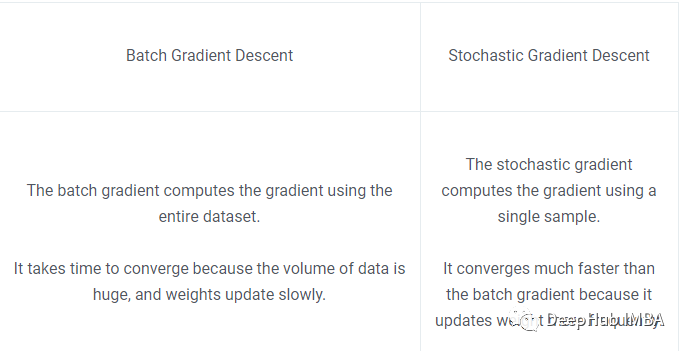
16、批量梯度下降和随机梯度下降的区别是什么?
17、什么是过拟合和欠拟合,以及如何解决?
过拟合是指模型在训练集上表现很好,到了验证和测试阶段就很差,即模型的泛化能力很差。当模型对训练数据中的细节和噪声的学习达到对模型对新信息的执行产生不利影响的程度时,就会发生过拟合。它更可能发生在学习目标函数时具有更大灵活性的非线性模型中。样本数量太少,样本噪音干扰过大,模型复杂度过高都会产生过拟合。
欠拟合是指模型在训练集、验证集和测试集上均表现不佳的情况。这通常发生在训练模型的数据较少且不正确的情况下。
为了防止过拟合和欠拟合,您可以重新采样数据来估计模型的准确性(k-fold交叉验证),并通过一个验证数据集来评估模型。
18、如何在网络中初始化权值?
一般情况下都使用随机初始化权值。
不能将所有权重初始化为0,因为这将使您的模型类似于线性模型。所有的神经元和每一层都执行相同的操作,给出相同的输出,使深层网络无用。
随机初始化所有权重通过将权重初始化为非常接近0的值来随机分配权重。由于每个神经元执行不同的计算,它使模型具有更好的准确性。
19、CNN中常见的层有哪些?
20、CNN的“池化”是什么?它是如何运作的?
池化用于减少CNN的空间维度。它执行下采样操作来降低维数,并通过在输入矩阵上滑动一个过滤器矩阵来创建一个汇集的特征映射。
21、LSTM是如何工作的?
长-短期记忆(LSTM)是一种特殊的循环神经网络,能够学习长期依赖关系。LSTM网络有三个步骤:
22、什么是梯度消失和梯度爆炸?
在训练RNN时,你的斜率可能会变得太小或太大;这使得训练非常困难。当斜率太小时,这个问题被称为“消失梯度”。当坡度趋向于指数增长而不是衰减时,它被称为“爆炸梯度”。梯度问题导致训练时间长,性能差,精度低。
23、深度学习中Epoch、Batch和Iteration的区别是什么?
Epoch —— 表示整个数据集的一次迭代(训练数据的所有内容)。
Batch——指的是因为不能一次性将整个数据集传递给神经网络,所以我们将数据集分成几个批处理进行处理,每一批称为Batch。
Iteration——如果我们有10,000张图像作为数据,Batch大小为200。那么一个Epoch 应该运行50次Iteration(10,000除以50)。
24、深度学习框架中的张量是什么意思?
这是另一个最常被问到的深度学习面试问题。张量是用高维数组表示的数学对象。这些具有不同维度和等级的数据数组作为神经网络的输入被称为“张量”。
25、比较常用的深度学习框架例如Tensorflow,Pytorch
大概说下就可以了,例如:这些框架提供c++和Python api,都支持CPU和GPU计算设备。那个熟悉说那个就可以了比如常用Pytorch,但是因为有些实现是Tensorflow的所以需要看代码所以对Tensorflow也了解一些,不要说谁好谁坏,因为很容易落入圈套,万一你说Tensorflow好,面试公司用Pytorch怎么办。
https://avoid.overfit.cn/post/35ba0e271a734fa3ba67271d90b12c3f
我想为Heroku构建一个Rails3应用程序。他们使用Postgres作为他们的数据库,所以我通过MacPorts安装了postgres9.0。现在我需要一个postgresgem并且共识是出于性能原因你想要pggem。但是我对我得到的错误感到非常困惑当我尝试在rvm下通过geminstall安装pg时。我已经非常明确地指定了所有postgres目录的位置可以找到但仍然无法完成安装:$envARCHFLAGS='-archx86_64'geminstallpg--\--with-pg-config=/opt/local/var/db/postgresql90/defaultdb/po
尝试通过RVM将RubyGems升级到版本1.8.10并出现此错误:$rvmrubygemslatestRemovingoldRubygemsfiles...Installingrubygems-1.8.10forruby-1.9.2-p180...ERROR:Errorrunning'GEM_PATH="/Users/foo/.rvm/gems/ruby-1.9.2-p180:/Users/foo/.rvm/gems/ruby-1.9.2-p180@global:/Users/foo/.rvm/gems/ruby-1.9.2-p180:/Users/foo/.rvm/gems/rub
我的最终目标是安装当前版本的RubyonRails。我在OSXMountainLion上运行。到目前为止,这是我的过程:已安装的RVM$\curl-Lhttps://get.rvm.io|bash-sstable检查已知(我假设已批准)安装$rvmlistknown我看到当前的稳定版本可用[ruby-]2.0.0[-p247]输入命令安装$rvminstall2.0.0-p247注意:我也试过这些安装命令$rvminstallruby-2.0.0-p247$rvminstallruby=2.0.0-p247我很快就无处可去了。结果:$rvminstall2.0.0-p247Search
由于fast-stemmer的问题,我很难安装我想要的任何rubygem。我把我得到的错误放在下面。Buildingnativeextensions.Thiscouldtakeawhile...ERROR:Errorinstallingfast-stemmer:ERROR:Failedtobuildgemnativeextension./System/Library/Frameworks/Ruby.framework/Versions/2.0/usr/bin/rubyextconf.rbcreatingMakefilemake"DESTDIR="cleanmake"DESTDIR=
当我尝试安装Ruby时遇到此错误。我试过查看this和this但无济于事➜~brewinstallrubyWarning:YouareusingOSX10.12.Wedonotprovidesupportforthispre-releaseversion.Youmayencounterbuildfailuresorotherbreakages.Pleasecreatepull-requestsinsteadoffilingissues.==>Installingdependenciesforruby:readline,libyaml,makedepend==>Installingrub
我正在尝试使用boilerpipe来自JRuby。我看过guide从JRuby调用Java,并成功地将它与另一个Java包一起使用,但无法弄清楚为什么同样的东西不能用于boilerpipe。我正在尝试基本上从JRuby中执行与此Java等效的操作:URLurl=newURL("http://www.example.com/some-location/index.html");Stringtext=ArticleExtractor.INSTANCE.getText(url);在JRuby中试过这个:require'java'url=java.net.URL.new("http://www
我意识到这可能是一个非常基本的问题,但我现在已经花了几天时间回过头来解决这个问题,但出于某种原因,Google就是没有帮助我。(我认为部分问题在于我是一个初学者,我不知道该问什么......)我也看过O'Reilly的RubyCookbook和RailsAPI,但我仍然停留在这个问题上.我找到了一些关于多态关系的信息,但它似乎不是我需要的(尽管如果我错了请告诉我)。我正在尝试调整MichaelHartl'stutorial创建一个包含用户、文章和评论的博客应用程序(不使用脚手架)。我希望评论既属于用户又属于文章。我的主要问题是:我不知道如何将当前文章的ID放入评论Controller。
首先回顾一下拉格朗日定理的内容:函数f(x)是在闭区间[a,b]上连续、开区间(a,b)上可导的函数,那么至少存在一个,使得:通过这个表达式我们可以知道,f(x)是函数的主体,a和b可以看作是主体函数f(x)中所取的两个值。那么可以有, 也就意味着我们可以用来替换 这种替换可以用在求某些多项式差的极限中。方法: 外层函数f(x)是一致的,并且h(x)和g(x)是等价无穷小。此时,利用拉格朗日定理,将原式替换为 ,再进行求解,往往会省去复合函数求极限的很多麻烦。使用要注意:1.要先找到主体函数f(x),即外层函数必须相同。2.f(x)找到后,复合部分是等价无穷小。3.要满足作差的形式。如果是加
?博客主页:https://xiaoy.blog.csdn.net?本文由呆呆敲代码的小Y原创,首发于CSDN??学习专栏推荐:Unity系统学习专栏?游戏制作专栏推荐:游戏制作?Unity实战100例专栏推荐:Unity实战100例教程?欢迎点赞?收藏⭐留言?如有错误敬请指正!?未来很长,值得我们全力奔赴更美好的生活✨------------------❤️分割线❤️-------------------------
HashMap中为什么引入红黑树,而不是AVL树呢1.概述开始学习这个知识点之前我们需要知道,在JDK1.8以及之前,针对HashMap有什么不同。JDK1.7的时候,HashMap的底层实现是数组+链表JDK1.8的时候,HashMap的底层实现是数组+链表+红黑树我们要思考一个问题,为什么要从链表转为红黑树呢。首先先让我们了解下链表有什么不好???2.链表上述的截图其实就是链表的结构,我们来看下链表的增删改查的时间复杂度增:因为链表不是线性结构,所以每次添加的时候,只需要移动一个节点,所以可以理解为复杂度是N(1)删:算法时间复杂度跟增保持一致查:既然是非线性结构,所以查询某一个节点的时候