今天遇到这样一道题:
在C语言中,表达式23|2^5的值是()
A 18
B 1
C 23
D 32
正确答案选C,为什么呢?一分钟讲完咱们就下课
“|”、“^”是逻辑位运算符
C语言里,逻辑位运算符“|”、“^”的定义是这样的:
“|” 运算符(位或)用于对两个二进制操作数逐位进行比较,并根据如表格所示的换算表返回结果。
| 第一个数的位值 | 第二个数的位值 | 运算结果 |
|---|---|---|
| 1 | 1 | 1 |
| 1 | 0 | 1 |
| 0 | 1 | 1 |
| 0 | 0 | 0 |
“^”运算符(位异或)用于对两个二进制操作数逐位进行比较,并根据如表格所示的换算表返回结果。
| 第一个数的位值 | 第二个数的位值 | 运算结果 |
|---|---|---|
| 1 | 1 | 0 |
| 1 | 0 | 1 |
| 0 | 1 | 1 |
| 0 | 0 | 0 |
回头来看这道题:
“^”优先级高于“|”
下图以算式的形式解析了 2 和 5 进行位异或运算的过程。
2 和 5 进行位异或运算,得到 7;
下图以算式的形式解析了 7 和 23 进行位或运算的过程。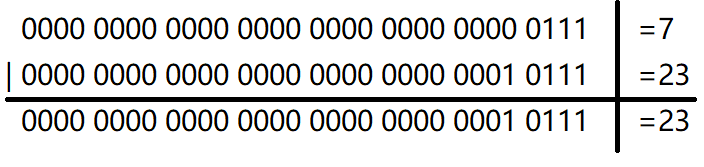
所以,答案是 23,选 C。
有兴趣的可以看看 JS &、|、^和~(逻辑位运算符),
里面写了JS的位或运算符,JS的位或运算符与C语言是一样的。
在我的应用程序中,我需要能够找到所有数字子字符串,然后扫描每个子字符串,找到第一个匹配范围(例如5到15之间)的子字符串,并将该实例替换为另一个字符串“X”。我的测试字符串s="1foo100bar10gee1"我的初始模式是1个或多个数字的任何字符串,例如,re=Regexp.new(/\d+/)matches=s.scan(re)给出["1","100","10","1"]如果我想用“X”替换第N个匹配项,并且只替换第N个匹配项,我该怎么做?例如,如果我想替换第三个匹配项“10”(匹配项[2]),我不能只说s[matches[2]]="X"因为它做了两次替换“1fooX0barXg
我有一个这样的哈希数组:[{:foo=>2,:date=>Sat,01Sep2014},{:foo2=>2,:date=>Sat,02Sep2014},{:foo3=>3,:date=>Sat,01Sep2014},{:foo4=>4,:date=>Sat,03Sep2014},{:foo5=>5,:date=>Sat,02Sep2014}]如果:date相同,我想合并哈希值。我对上面数组的期望是:[{:foo=>2,:foo3=>3,:date=>Sat,01Sep2014},{:foo2=>2,:foo5=>5:date=>Sat,02Sep2014},{:foo4=>4,:dat
我有一个包含多个键的散列和一个字符串,该字符串不包含散列中的任何键或包含一个键。h={"k1"=>"v1","k2"=>"v2","k3"=>"v3"}s="thisisanexamplestringthatmightoccurwithakeysomewhereinthestringk1(withspecialcharacterslike(^&*$#@!^&&*))"检查s是否包含h中的任何键的最佳方法是什么,如果包含,则返回它包含的键的值?例如,对于上面的h和s的例子,输出应该是v1。编辑:只有字符串是用户定义的。哈希将始终相同。 最佳答案
我想获取模块中定义的所有常量的值:moduleLettersA='apple'.freezeB='boy'.freezeendconstants给了我常量的名字:Letters.constants(false)#=>[:A,:B]如何获取它们的值的数组,即["apple","boy"]? 最佳答案 为了做到这一点,请使用mapLetters.constants(false).map&Letters.method(:const_get)这将返回["a","b"]第二种方式:Letters.constants(false).map{|c
@raw_array[i]=~/[\W]/非常简单的正则表达式。当我用一些非拉丁字母(具体来说是俄语)尝试时,条件是错误的。我能用它做什么? 最佳答案 @raw_array[i]=~/[\p{L}]/使用西里尔字符进行测试。引用:http://www.regular-expressions.info/unicode.html#prop 关于ruby-正则表达式将非英文字母匹配为非单词字符,我们在StackOverflow上找到一个类似的问题: https://
假设我有以下类(class):classPersondefinitialize(name,age)@name=name@age=ageenddefget_agereturn@ageendend我有一组Person对象。是否有一种简洁的、类似于Ruby的方法来获取最小(或最大)年龄的人?如何根据它对它们进行排序? 最佳答案 这样做会:people_array.min_by(&:get_age)people_array.max_by(&:get_age)people_array.sort_by(&:get_age)
我需要一个非常简单的字符串验证器来显示第一个符号与所需格式不对应的位置。我想使用正则表达式,但在这种情况下,我必须找到与表达式相对应的字符串停止的位置,但我找不到可以做到这一点的方法。(这一定是一种相当简单的方法……也许没有?)例如,如果我有正则表达式:/^Q+E+R+$/带字符串:"QQQQEEE2ER"期望的结果应该是7 最佳答案 一个想法:你可以做的是标记你的模式并用可选的嵌套捕获组编写它:^(Q+(E+(R+($)?)?)?)?然后你只需要计算你获得的捕获组的数量就可以知道正则表达式引擎在模式中停止的位置,你可以确定匹配结束
我在搜索我的值是方法的散列时遇到问题。我只是不想运行plan_type与键匹配的方法。defmethod(plan_type,plan,user){foo:plan_is_foo(plan,user),bar:plan_is_bar(plan,user),waa:plan_is_waa(plan,user),har:plan_is_har(user)}[plan_type]end目前如果我传入“bar”作为plan_type,所有方法都会运行,我怎么能只运行plan_is_bar方法呢? 最佳答案 这个变体怎么样?defmethod
我想从then子句中访问case语句表达式,即food="cheese"casefoodwhen"dip"then"carrotsticks"when"cheese"then"#{expr}crackers"else"mayo"end在这种情况下,expr是食物的当前值(value)。在这种情况下,我知道,我可以简单地访问变量food,但是在某些情况下,该值可能无法再访问(array.shift等)。除了将expr移出到局部变量然后访问它之外,是否有直接访问caseexpr值的方法?罗亚附注我知道这个具体示例很简单,只是一个示例场景。 最佳答案
这是一个例子:s="abcd+subtext@example.com"s.match(/+[^@]*/)Result=>"+subtext"问题是,我不想在其中包含“+”。我希望结果是“潜台词”,没有+ 最佳答案 您可以在正则表达式中使用括号来创建匹配组:s="abcd+subtext@example.com"s=~/\+([^@]*)/&&$1=>"subtext" 关于ruby-正则表达式-排除一个字符,我们在StackOverflow上找到一个类似的问题: