可以根据业务类型,分发到不同的Topic中,对于每一个Topic,下面可以有多个分区(Partition)日志文件:
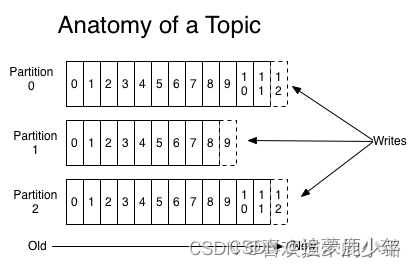
kafka 下的Topic的多个分区,每一个分区实质上就是一个队列,将接收到的消息暂时存储到队列中,根据配置以及消息消费情况来对队列消息删除。
Partition是一个有序的message序列 这些message按顺序添加到一个叫做commit log的文件中。每个partition中的消息都有一个唯一的编号,称之为offset,用来唯一标示某个分区中的message。
每个partition,都对应一个commit log文件。一个partition中的message的offset都是唯一的,但是不同的partition中的message的offset可能是相同的。
可以这么来理解Topic,Partition和Broker
一个topic,代表逻辑上的一个业务数据集,比如按数据库里不同表的数据操作消息区分放入不同topic,订单相关操作消息放入订单topic,用户相关操作消息放入用户topic,
对于大型网站来说,后端数据都是海量的,订单消息很可能是非常巨量的,比如有几百个G甚至达到TB级别,如果把这么多数据都放在一台机器上可定会有容量限制问题,
那么就可以在topic内部划分多个partition来分片存储数据,不同的partition可以位于不同的机器上,每台机器上都运行一个Kafka的进程Broker。
为什么要对Topic下数据进行分区存储?
1、commit log文件会受到所在机器的文件系统大小的限制,分区之后可以将不同的分区放在不同的机器上,相当于对数据做了分布式存储,理论上一个topic可以处理任意数量的数据。
2、为了提高并行度。
每个consumer会定期将自己消费分区的offset提交给kafka内部
topic:__consumer_offsets,提交过去的时候,
key是 consumerGroupId+topic+分区号,value就是当前offset的值,kafka会定期清理topic里的消息,最后就保留最新的那条数据。
因为__consumer_offsets可能会接收高并发的请求,kafka默认给其分配50个分区(可以通过offsets.topic.num.partitions设置),这样可以通过加机器的方式抗大并发
查看指定topic信息
bin/kafka-topics.sh --describe --bootstrap-server node02:9092 --topic test
 可以进入kafka的数据文件存储目录查看test和test1主题的消息日志文件:默认log目录 /tmp/kafka-logs
可以进入kafka的数据文件存储目录查看test和test1主题的消息日志文件:默认log目录 /tmp/kafka-logs

消息日志文件主要存放在分区文件夹里的以log结尾的日志文件里,如下是test-1主题对应的分区0的消息日志:

kafka一般不会删除消息,不管这些消息有没有被消费。只会根据配置的日志保留时间(log.retention.hours)确认消息多久被删除,
默认保留最近一周的日志消息。kafka的性能与保留的消息数据量大小没有关系,
因此保存大量的数据消息日志信息不会有什么影响。
每个consumer是基于自己在commit log中的消费进度(offset)来进行工作的。
在kafka中,消费offset由consumer自己来维护;一般情况下我们按照顺序逐条消费commit log中的消息,
当然我可以通过指定offset来重复消费某些消息,或者跳过某些消息。
这意味kafka中的consumer对集群的影响是非常小的,添加一个或者减少一个consumer,
对于集群或者其他consumer来说,都是没有影响的,因为每个consumer维护各自的消费offset。
Kafka 一个分区的消息数据对应存储在一个文件夹下,以topic名称+分区号命名,消息在分区内是分段(segment)存储,
每个段的消息都存储在不一样的log文件里,这种特性方便old segment file快速被删除,kafka规定了一个段位的 log 文件最大为 1G,做这个限制目的是为了方便把 log 文件加载到内存去操作:
部分消息的offset索引文件,kafka每次往分区发4K(可配置)消息就会记录一条当前消息的offset到index文件,
如果要定位消息的offset会先在这个文件里快速定位,再去log文件里找具体消息
00000000000009936472.index
消息存储文件,主要存offset和消息体
00000000000009936472.log
消息的发送时间索引文件,kafka每次往分区发4K(可配置)消息就会记录一条当前消息的发送时间戳与对应的offset到timeindex文件,
如果需要按照时间来定位消息的offset,,会先在这个文件里查找
00000000000009936472.timeindex
这个 9936472 之类的数字,就是代表了这个日志段文件里包含的起始 Offset,也就说明这个分区里至少都写入了接近1000 万条数据了。
Kafka Broker 有一个参数,log.segment.bytes,限定了每个日志段文件的大小,最大就是 1GB。
一个日志段文件满了,就自动开一个新的日志段文件来写入,避免单个文件过大,影响文件的读写性能,这个过程叫做 log rolling,正在被写入的那个日志段文件,叫做 active log segment。
我是rails的新手,想在form字段上应用验证。myviewsnew.html.erb.....模拟.rbclassSimulation{:in=>1..25,:message=>'Therowmustbebetween1and25'}end模拟Controller.rbclassSimulationsController我想检查模型类中row字段的整数范围,如果不在范围内则返回错误信息。我可以检查上面代码的范围,但无法返回错误消息提前致谢 最佳答案 关键是您使用的是模型表单,一种显示ActiveRecord模型实例属性的表单。c
我的工作要求我为某些测试自动生成电子邮件。我一直在四处寻找,但未能找到可以快速实现的合理解决方案。它需要在outlook而不是其他邮件服务器中,因为我们有一些奇怪的身份验证规则,我们需要保存草稿而不是仅仅发送邮件的选项。显然win32ole可以做到这一点,但我找不到任何相当简单的例子。 最佳答案 假设存储了Outlook凭据并且您设置为自动登录到Outlook,WIN32OLE可以很好地完成此操作:require'win32ole'outlook=WIN32OLE.new('Outlook.Application')message=
我正在使用Ruby,我正在与一个网络端点通信,该端点在发送消息本身之前需要格式化“header”。header中的第一个字段必须是消息长度,它被定义为网络字节顺序中的2二进制字节消息长度。比如我的消息长度是1024。如何将1024表示为二进制双字节? 最佳答案 Ruby(以及Perl和Python等)中字节整理的标准工具是pack和unpack。ruby的packisinArray.您的长度应该是两个字节长,并且按网络字节顺序排列,这听起来像是n格式说明符的工作:n|Integer|16-bitunsigned,network(bi
如果我在模型中设置验证消息validates:name,:presence=>{:message=>'Thenamecantbeblank.'}我如何让该消息显示在闪光警报中,这是我迄今为止尝试过的方法defcreate@message=Message.new(params[:message])if@message.valid?ContactMailer.send_mail(@message).deliverredirect_to(root_path,:notice=>"Thanksforyourmessage,Iwillbeintouchsoon")elseflash[:error]
RSpec似乎按顺序匹配方法接收的消息。我不确定如何使以下代码工作:allow(a).toreceive(:f)expect(a).toreceive(:f).with(2)a.f(1)a.f(2)a.f(3)我问的原因是a.f的一些调用是由我的代码的上层控制的,所以我不能对这些方法调用添加期望。 最佳答案 RSpecspy是测试这种情况的一种方式。要监视一个方法,用allowstub,除了方法名称之外没有任何约束,调用该方法,然后expect确切的方法调用。例如:allow(a).toreceive(:f)a.f(2)a.f(1)
我以为它们存储在cookie中-但不,检查cookie没有任何结果。session也不存储它们。那么,我在哪里可以找到它们?我需要这个来直接设置它们(而不是通过flashhash)。 最佳答案 它们存储在inyoursessionstore.自rails2.0以来的默认设置是cookie存储,但请检查config/initializers/session_store.rb以检查您是否使用默认设置以外的东西。 关于ruby-on-rails-闪存消息存储在哪里?,我们在StackOverf
如何在出现异常时指定全局救援,如果您将Sinatra用于API或应用程序,您将如何处理日志记录? 最佳答案 404可以在not_found方法的帮助下处理,例如:not_founddo'Sitedoesnotexist.'end500s可以通过调用带有block的错误方法来处理,例如:errordo"Applicationerror.Plstrylater."end错误的详细信息可以通过request.env中的sinatra.error访问,如下所示:errordo'Anerroroccured:'+request.env['si
我正在使用ruby标准记录器,我想要每天轮换一次,所以在我的代码中我有:Logger.new("#{$ROOT_PATH}/log/errors.log",'daily')它运行完美,但它创建了两个文件errors.log.20130217和errors.log.20130217.1。如何强制它每天只创建一个文件? 最佳答案 您的代码对于长时间运行的应用程序是正确的。发生的事情是您在给定的一天多次运行代码。第一次运行时,Ruby会创建一个日志文件“errors.log”。当日期改变时,Ruby将文件重命名为“errors.log
在运行Cucumber测试时,我得到(除了测试结果)大量调试/日志相关的输出形式:D,[2013-03-06T12:21:38.911829#49031]DEBUG--:SOAPrequest:D,[2013-03-06T12:21:38.911919#49031]DEBUG--:Pragma:no-cache,SOAPAction:"",Content-Type:text/xml;charset=UTF-8,Content-Length:1592W,[2013-03-06T12:21:38.912360#49031]WARN--:HTTPIexecutesHTTPPOSTusingt
我最近将我的http客户端切换到faraday,一切都按预期工作。我有以下代码来创建连接:@connection=Faraday.new(:url=>base_url)do|faraday|faraday.useCustim::Middlewarefaraday.request:url_encoded#form-encodePOSTparamsfaraday.request:jsonfaraday.response:json,:content_type=>/\bjson$/faraday.response:loggerfaraday.adapterFaraday.default_ada