Lecture 3 Cognitive Computing with Cloud Computing(认知计算与云计算)
Lecture 3 Cognitive Computing with Cloud Computing(认知计算与云计算)
云计算的含义
什么是云:
- 云指的是网络或互联网,存在于远程位置的东西。
- 云可以通过公共网络或私人网络提供服务
- 应用程序:电子邮件、网络会议、客户关系管理
什么是云计算
- 通过网络建立、配置、定制、使用APP
- 通过网络访问数据库,无需担心数据的维护和管理
- 云计算与软硬件计算资源有关,提供在线数据存储
云计算的基本结构
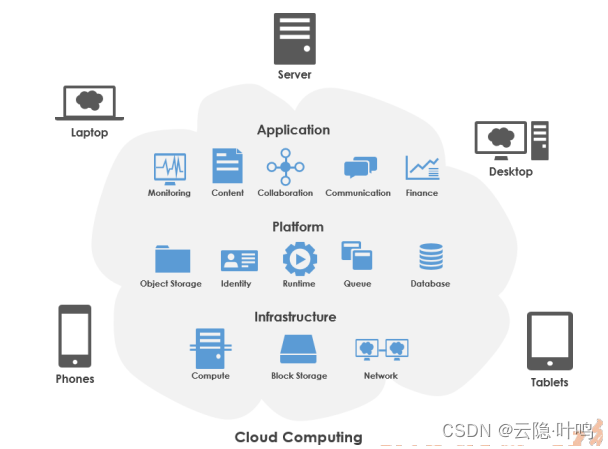
图片引用自东北大学郭朝鹏老师课件(后同)
云计算的特点
- 弹性和自动服务配置
- 弹性:用户对资源使用的调整
- 自动服务配置:自适应的资源配置
- 扩展性
- 分布式计算
使用云进行认知计算
认知系统的需求
- 闭环环境,支持不同软硬件
- 从不同来源收集数据,用不同的特定方法处理数据
- 高效利用数据源,运行算法
- 分布式计算:改变软件管理和交付方式,是商业化认知计算的关键
基于资源分享的分布式计算
- 资源分享方法:应用程序、计算服务、数据存储、网络、软件开发、部署类型和业务流程
- 结合分布式计算整合成系列共享资源
- 通过标准结构部署
- 用计算引擎解决复杂计算、工程、商业问题
- 没有必要购买高性能的系统,而只是在需要的时候使用云服务
云计算的常见模型
计算模型
| 模型 | 特点 |
|---|
| 公有云(public cloud) | 多用户、隐私性和稳定性差 |
| 私有云(private cloud) | 独有,内部使用,安全性高 |
| Community Cloud | 通常情况下为一个组织内部使用 |
| Hybrid Cloud | 公有云+私有云,需要使用时申请对公有云进行独占 |
服务模型
| 模型 | 特点 |
|---|
| IaaS | IaaS 是作为按需扩展服务的技术基础设施。
IaaS 用户可以私人访问基本资源,如物理机、虚拟机、虚拟存储等。
通常根据使用情况计费,是多租户虚拟化环境
可以与操作系统和应用程序支持的托管服务相结合。 |
| PaaS | 为应用程序、开发和部署工具等提供了运行时环境。
PaaS 提供了所有需要的设施来支持完整的生命周期的建设和交付网络。
通常,应用程序的开发必须考虑到特定的平台
多租户环境。
高度可扩展的多层体系结构 |
| SaaS | SaaS 模型允许将软件应用程序作为对最终用户的服务。
SaaS 是一种软件交付方法,它提供许可的多租户远程软件及其功能访问
通常根据使用情况计费,是多租户环境,
高度可伸缩的体系结构 |
面向编程工具的认知计算
分布式处理
特点:在集群中分布式处理,每个节点独立处理数据
CAP理论
- Consistency
- Availability
- Partition tolerance
一个系统之多只可以满足以上三点的任意两个,其中,通常情况下,最经常采用的是以下的两种:
- Availability
- Partition tolerance
- 最终一致性(与Consistency存在一定的差异,是指一段时间后的一致)
特点
| 特点 | 含义 |
|---|
| 容错性 | 系统但出错后自动恢复;关注硬件与任务的故障 |
| 可靠性 | 服务时间长;节点故障不造成数据丢失 |
| 高可用性 | 除了硬件故障,系统均可访问;对性能有一定要求;终端用户的应用不会因为数据而出现停机 |
| 可扩展性 | 垂直可扩展性:新的硬件可以被添加到节点上 水平可扩展性:新的节点可以被添加到云 |
Hadoop
HDFS:分布式文件系统
- HDFS 是一种容错、可扩展、极易于扩展的分布式系统。
- HDFS 是 Hadoop 应用程序的主要分布式存储器。
- HDFS 为应用程序提供了使自己更接近数据的接口。
- HDFS 被设计为“只工作”,但是工作知识有助于诊断和改进
HDFS的组成
- NameNode: 是 HDFS 文件系统的核心,它维护和管理文件系统元数据。例如:文件由哪些块组成,这些块存储在哪些数据节点上。
- DataNode: HDFS 存储实际数据的地方,通常有相当多的 DataNode。
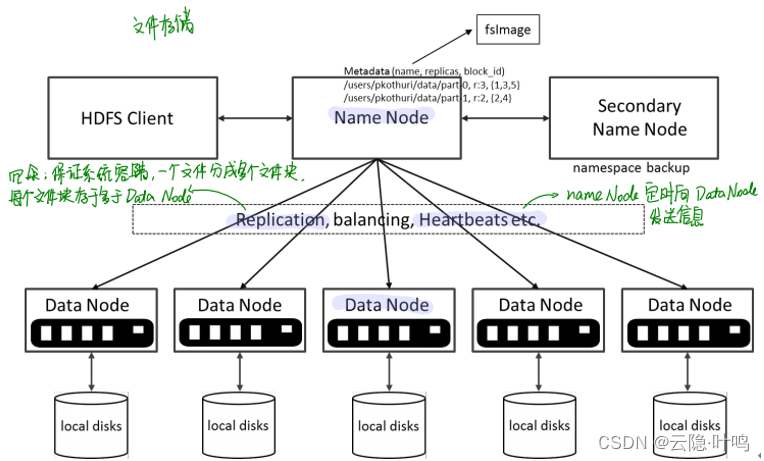
HDFS的结构
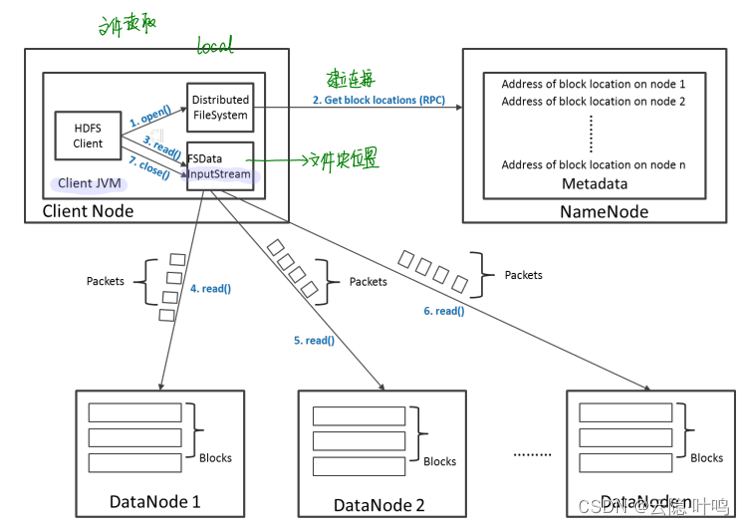
HDFS文件的读取
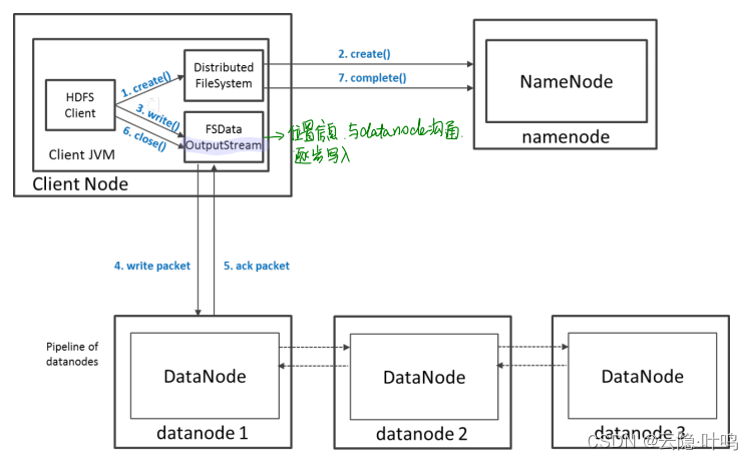
HDFS文件的写入
MapReduce
MapReduce的作用
- 自动并行化
- 分配 I/O 调度
- 容错率:提供机器故障的处理
- MapReduce 向外扩展,而不是升级,即使用大量的商用服务器,而不是一些高端的专用服务器
MapReduce的处理过程
- 读取了大量的数据
- 从每条记录中提取您关心的内容,即键值对
- 清洗和排序
- 减少:汇总、 迭代或转换(Reduce: aggregate, summarize, lter, or transform)
- 输出结果
MapReduce与传统的并行之间的区别
- 传统的并行计算
- 需要设计多线程等操作,不正确的使用会导致错误
- 对硬件不容错
- MapReduce:
Yarn
与传统操作系统的区别
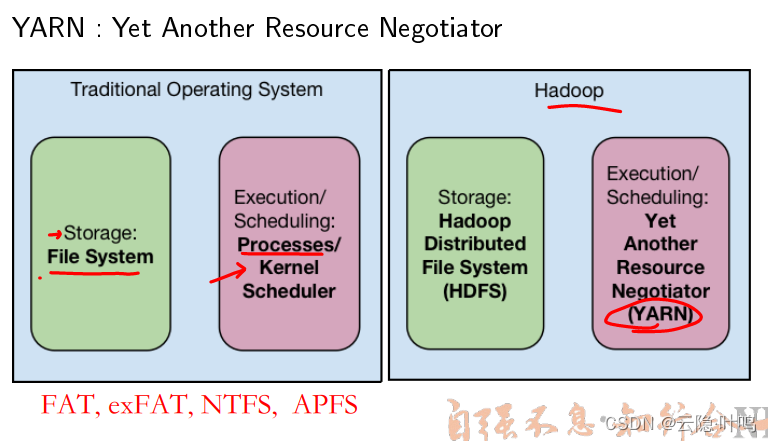
与传统的分布式操作系统的区别
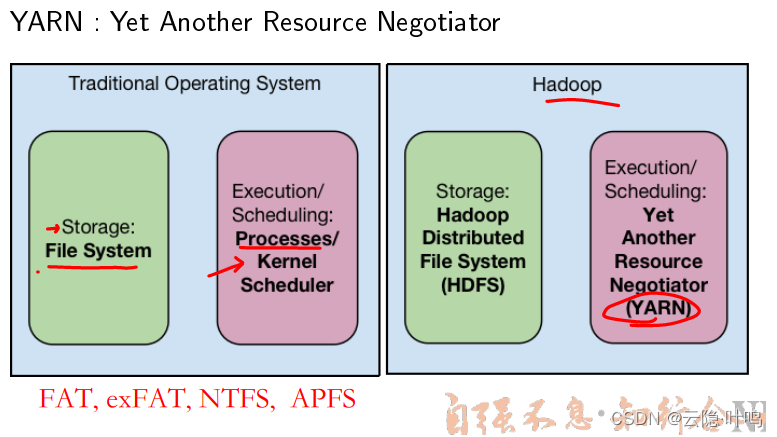
- master和worker是物理节点
- worker用来处理不同task
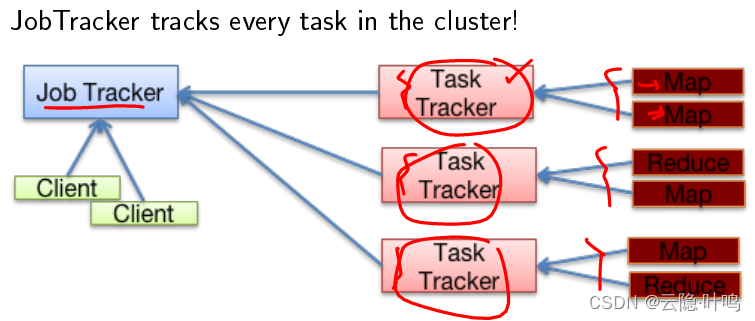
- task tracker和job tracker是MapReduce节点
- job tracker调度task tracker
- task tracker决定有几个map,几个reduce
- 内存分配:外部设置+固定大小的slot model强制slot足够大的任务
YRAN的故障处理机制
1.存在一个内部的资源管理器
2.决定何时何地运行
3.采用队列组织调度的方法
4.应用程序被提交到队列中
5.采用两种调度程序
- Fair Schedule:所有节点保持均衡
- Capacity Schedule:谁空闲谁做
优点
- Scalability:可伸缩性,只跟踪应用程序,而不是所有任务
- Utilization:使用性,只分配所需的资源
- Multi-tenancy:在框架和用户之间共享资源,如物理资源——memory,CPU, disk,network
缺点
- 多个算法可以转换为多个Map与Reduce的组合,但表达能力有限,无法实现join、filter、flatMap、union、intersection
- 基于MapReduce,需要从磁盘读写
- 无状态机器,执行代价高,总是存在硬盘读写的问题
- 只能用Java,不支持其他语言
- 只可进行批处理,但有时候数据并不是数据块的形式,比如交互性数据、流数据