MapReduce是一种编程范式,它借助Map将一个大任务分解成多个小任务,再借助Reduce归并Map的结果。MapReduce虽然原理很简单,但是使用MapReduce设计出一个解决问题的应用却不是一件简单的事情。下面通过一个简单的小例子来介绍MapReduce。
《Hadoop权威指南》的例子是寻找天气最大值,需要去下载数据。但是我们并不需要完全复刻他的场景,所以这里用了另外一个例子。假设有一批销售日志数据文件,它的一部分是这样的。
66$2021-01-01$5555
67$2021-01-01$5635
每一行代表某一位销售人员某个日期的销售数量,具体格式为
销售用户id$统计日期$销售数量
我们需要寻找每一个销售用户的销售最大值是多少。需要说明的是,这里仅仅是举一个很简单的示例,便于学习MapReduce。
我首先写了一个解析器来识别每一行的文本,它的作用是将每一行文本转换为数据实体,数据实体这里偷了个懒,字段全部设置成了public。代码片段如下:
/**
* 销售数据解释器
* 销售数据格式为
* userId$countDate(yyyy-MM-dd)$saleCount
*/
public class SaleDataParse implements TextParse<SaleDataEntity> {
@Override
public SaleDataEntity parse(String text) {
if (text == null) {
return null;
}
text = text.trim();
if (text.isEmpty()) {
return null;
}
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd");
String[] split = text.split("\\$");
SaleDataEntity data = new SaleDataEntity();
data.userId = Long.valueOf(split[0]);
data.countDate = sdf.parse(split[1], new ParsePosition(0));
data.saleCount = Integer.valueOf(split[2]);
return data;
}
}
/**
* 销售数据实体
*/
public class SaleDataEntity {
/**
* 销售用户id
*/
public Long userId;
/**
* 销售日期
*/
public Date countDate;
/**
* 销售总数
*/
public Integer saleCount;
}
Mapper是一个泛型类,它需要4个泛型参数,从左到右分别是输入键、输入值、输出键和输出值。也就是这样
Mapper<输入键, 输入值, 输出键, 输出值>
其中输入键和输入值的格式是由InputFormatClass决定的,关于输入格式的讨论之后会展开讨论。MapReduce默认会把文件按行拆分,然后偏移量(输入键)->行文本(输入值)的映射传递给Mapper的map方法。输出键和输出值则由用户进行指定。
这里由于是找每一个用户的最大销售数量,Mapper的功能是接收并解析每行数据。所以输出键我设成了销售人员id->销售数量的映射。所以实际的Mapper实现看起来像这样:
/**
* 解析输入的文本数据
*/
public class MaxSaleMapper extends Mapper<LongWritable, Text, LongWritable, IntWritable> {
protected TextParse<SaleDataEntity> saleDataParse = new SaleDataParse();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String s = value.toString();
SaleDataEntity data = saleDataParse.parse(s);
if (data != null) {
//写入输出给Reducer
context.write(new LongWritable(data.userId), new IntWritable(data.saleCount));
}
}
}
其中LongWritable相当于java里的long,Text相当于java里的String,IntWritable相当于java里的int。
这里你可能会想到,既然已经解析成了数据实体,为什么不直接把实体设置成输出值?因为map函数和reduce函数不一定运行在同一个进程里,所以会涉及到序列化和反序列化,这里先不展开。
Reducer也是一个泛型类,它也需要4个参数,从左到右分别是输入键、输入值、输出键和输出值。也就是这样
Reducer<输入键, 输入值, 输出键, 输出值>
与Mapper不同的是,输入键和输入值来源于Mapper的输出,也就是Mapper实现中的context.write()。
输出键和输出值也是由用户指定,默认的输出会写到文件中,关于Reducer的输出以后会讨论。
Reducer的功能是寻找每个用户的最大值,所以Reducer的实现看起来像这样:
/**
* 查找每一个用户的最大销售值
*/
public class MaxSaleReducer extends Reducer<LongWritable, IntWritable, LongWritable, IntWritable> {
@Override
protected void reduce(LongWritable key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int max = 0;
for (IntWritable value : values) {
if (value.get() > max) {
max = value.get();
}
}
context.write(key, new IntWritable(max));
}
}
你可能会奇怪,为什么reduce方法的第二个参数是一个迭代器。简单来说,Mapper会把映射的值进行归并,然后再传递给Reducer。
我们已经完成了map和reduce函数的实现,现在我们需要把它们组装起来。我们需要写一个Main类,它看起来像这样
public class MaxSale {
public static void main(String[] args) throws Exception {
Job job = Job.getInstance();
job.setJarByClass(MaxSale.class);
job.setJobName("MaxSale");
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.setMapperClass(MaxSaleMapper.class);
job.setMapOutputKeyClass(LongWritable.class);
job.setMapOutputValueClass(IntWritable.class);
job.setReducerClass(MaxSaleReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//设置Reduce任务数
job.setNumReduceTasks(1);
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
这里解释一下
使用maven package打包,会生成一个jar,我生成的名字是maxSaleMapReduce-1.0-SNAPSHOT.jar。如果打包的jar有除了Hadoop的其他依赖,需要设置一下HADOOP_CLASSPATH,然后把依赖放到HADOOP_CLASSPATH目录中。
最后输入启动命令,格式为:hadoop jar 生成的jar.jar 输入数据目录 输出数据目录。这里给出我使用的命令示例:
Windows:
set HADOOP_CLASSPATH=C:\xxxxxxxxx\lib\*
hadoop jar maxSaleMapReduce-1.0-SNAPSHOT.jar input output
然后你会看到程序有如下输出,这里截取的部分:
23/01/18 12:10:29 INFO mapred.MapTask: Starting flush of map output
23/01/18 12:10:29 INFO mapred.MapTask: Spilling map output
23/01/18 12:10:29 INFO mapred.MapTask: bufstart = 0; bufend = 17677320; bufvoid = 104857600
23/01/18 12:10:29 INFO mapred.MapTask: kvstart = 26214396(104857584); kvend = 20321960(81287840); length = 5892437/6553600
23/01/18 12:10:30 INFO mapred.MapTask: Finished spill 0
23/01/18 12:10:30 INFO mapred.Task: Task:attempt_local1909247000_0001_m_000000_0 is done. And is in the process of committing
23/01/18 12:10:30 INFO mapred.LocalJobRunner: map
23/01/18 12:10:30 INFO mapred.Task: Task 'attempt_local1909247000_0001_m_000000_0' done.
23/01/18 12:10:30 INFO mapred.Task: Final Counters for attempt_local1909247000_0001_m_000000_0: Counters: 17
File System Counters
FILE: Number of bytes read=33569210
FILE: Number of bytes written=21132276
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
Map-Reduce Framework
Map input records=1473110
Map output records=1473110
Map output bytes=17677320
Map output materialized bytes=20623546
Input split bytes=122
Combine input records=0
Spilled Records=1473110
Failed Shuffles=0
Merged Map outputs=0
GC time elapsed (ms)=36
Total committed heap usage (bytes)=268435456
File Input Format Counters
Bytes Read=33558528
23/01/18 12:10:30 INFO mapred.LocalJobRunner: Finishing task: attempt_local1909247000_0001_m_000000_0
23/01/18 12:10:30 INFO mapred.LocalJobRunner: Starting task: attempt_local1909247000_0001_m_000001_0
23/01/18 12:10:30 INFO output.FileOutputCommitter: File Output Committer Algorithm version is 1
23/01/18 12:10:30 INFO output.FileOutputCommitter: FileOutputCommitter skip cleanup _temporary folders under output directory:false, ignore cleanup failures: false
等待程序执行结束,output文件夹会有输出part-r-00000,文件里每一行是每一个用户的id和他销售最大值。
0 9994
1 9975
2 9987
3 9985
4 9978
5 9998
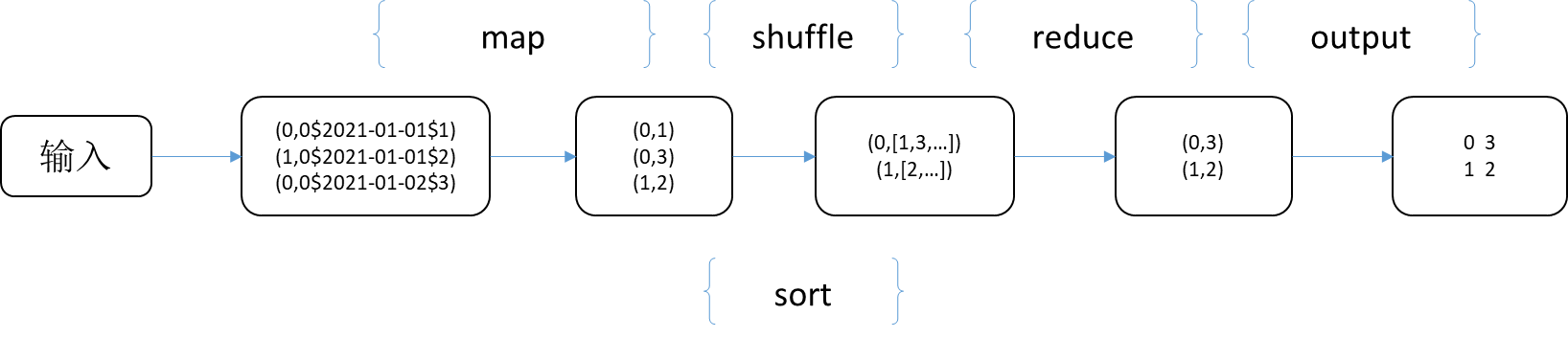
简单分析一下这个示例程度的执行流程:
本文所有的代码放在我的github上,地址是:https://github.com/xunpengliu/hello-hadoop
下面是项目目录说明:
最后需要说明的是,项目代码主要用于学习,代码风格并非代表本人实际风格,不完善之处请轻喷。
java.lang.RuntimeException: java.io.FileNotFoundException: Could not locate Hadoop executable: xxxxxxxxxxxx\bin\winutils.exe -see https://wiki.apache.org/hadoop/WindowsProblems
这个是因为没有下载winutils.exe和hadoop.dll,具体可以参考《安装一个最小化的Hadoop》中windows额外说明
运行出现异常java.lang.NullPointerException
at java.lang.ProcessBuilder.start(ProcessBuilder.java:1012)
at org.apache.hadoop.util.Shell.runCommand(Shell.java:482)
at org.apache.hadoop.util.Shell.run(Shell.java:455)
at org.apache.hadoop.util.Shell$ShellCommandExecutor.execute(Shell.java:702)
......
这个和问题1类似,Hadoop在Windows需要winutils.exe和hadoop.dll访问文件,这两个文件通过org.apache.hadoop.util.Shell#getQualifiedBinPath这个方法获取,而这个方法又依赖Hadoop的安装目录。
设置HADOOP_HOME环境变量,或者传入系统参数hadoop.home.dir为Hadoop程序目录,具体参见《安装一个最小化的Hadoop》
前面一篇关于智能合约翻译文讲到了,是一种计算机程序,既然是程序,那就可以使用程序语言去编写智能合约了。而若想玩区块链上的项目,大部分区块链项目都是开源的,能看得懂智能合约代码,或找出其中的漏洞,那么,学习Solidity这门高级的智能合约语言是有必要的,当然,这都得在公链``````以太坊上,毕竟国内的联盟链有些是不兼容Solidity。Solidity是一种面向对象的高级语言,用于实现智能合约。智能合约是管理以太坊状态下的账户行为的程序。Solidity是运行在以太坊(Ethereum)虚拟机(EVM)上,其语法受到了c++、python、javascript影响。Solidity是静态类型
Halo,这里是Ppeua。平时主要更新C语言,C++,数据结构算法,Linux…感兴趣就关注我吧!你定不会失望。目录1.ls显示当前目录下的文件内内容2.pwd-显示用户当前所在的目录3.cd-改变工作目录。将当前工作目录改变到指定的目录下1.cd-回到上一次待的工作空间2.cd..返回上一层目录1.相对路径:cd../aurora2.绝对路径:cd/home/aurora/lesson1/aurora3.cd~进入用户家目录4.cd/进入root目录4.mkdir-新建目录5.rmdir/rm-删除1.rmdir删除空文件夹2.rm删除1.rm-f2.rm-i3.rm-r1.ls显示当前目
我遇到了错误“2013-03-06”的未定义方法`strftime':String当尝试使用strftime从字符串2013-03-06正常显示日期(2013年6月3日或类似日期)时。在我的index.html.erb中执行此操作的行看起来像这样我只是在学习Rails,所以我确信这只是一个愚蠢的初学者错误,我们将不胜感激。谢谢 最佳答案 当strftime是时间/日期类的方法时,您的截止日期看起来是一个字符串。你可以试试这个:Date.parse(task.duedate).strftime("%B%e,%Y")
文章目录实验二:HDFS+MapReduce数据处理与存储实验1.实验目的2.实验环境3.实验内容3.1HDFS部分3.1.1上传文件3.1.2下载文件3.1.3显示文件信息3.1.4显示目录信息3.1.5删除文件3.1.6移动文件3.2MapReduce部分3.2.0Mapreduce原理3.2.1合并和去重3.2.1.1编写Merge.java代码3.2.1.2编译执行3.2.2文件的排序3.2.2.1编写Sort.java代码3.2.2.2编译执行4.踩坑记录5.心得体会6.源码附录6.1Merge.java完整代码6.2Sort.java完整代码实验二:HDFS+MapReduce数据
gtest是Google开发的一个开源单元测试框架,代码提供丰富的注释和实例,参考实际用例可以很快上手基本单元测试,丰富的代码注释能够让有兴趣的开发者深入了解gtest的代码结构并做部分针对性的二次开发。gtest主要针对c/c++提供了针对函数接口和类方法丰富测试方法,针对单元测试特有的数据或者代码反复编写的这种特性做了集成和优化,满足当前绝大部分对于单元测试的需求。其有如下特点:自动收集测试用例,无需开发者再次组织提供强大的断言集,支持包括布尔、整型、浮点型、字符串等。提供断言方法自定义扩展提供死亡测试功能使用参数化自动生成多个相似的测试用例可以将公共的用例初始化和清理工作放入测试夹具中,
我正在结合riak/riak-js开发nodejs应用程序并遇到以下问题:运行这个请求db.mapreduce.add('logs').run();正确返回存储在存储桶日志中的所有155.000个项目及其ID:['logs','1GXtBX2LvXpcPeeR89IuipRUFmB'],['logs','63vL86NZ96JptsHifW8JDgRjiCv'],['logs','NfseTamulBjwVOenbeWoMSNRZnr'],['logs','VzNouzHc7B7bSzvNeI1xoQ5ih8J'],['logs','UBM1IDcbZkMW4iRWdvo4W7zp6d
一鸿蒙简介HarmonyOS是一款面向万物互联时代的、全新的分布式操作系统。在传统的单设备系统能力基础上,HarmonyOS提出了基于同一套系统能力、适配多种终端形态的分布式理念,能够支持手机、平板、智能穿戴、智慧屏、车机等多种终端设备,提供全场景(移动办公、运动健康、社交通信、媒体娱乐等)业务能力。HarmonyOS提供了支持多种开发语言的API,供开发者进行应用开发。支持的开发语言包括Java、XML(ExtensibleMarkupLanguage)、C/C++、JS(JavaScript)、CSS(CascadingStyleSheets)和HML(HarmonyOSMarkupLan
MapReduce序列化之统计各部门员工薪资总和文章目录MapReduce序列化之统计各部门员工薪资总和1.1实验目的1.2实验环境1.3需求描述1.4实验步骤1.4.1采用IDEA创建一个Maven工程1.4.2自己动手开发Java程序1.4.3使用maven生命周期package打jar包1.4.4通过xftp将jar包上传到linux系统1.4.5在hadoop环境运行jar包1.4.6查看输出结果1.5实验中遇到的问题总结1.5.1问题描述1.5.2问题分析1.5.3解决方法1.1实验目的通过MapReduce的序列化方法统计各个部门员工薪水总和。1.2实验环境搭建IDEA+Maven
这个问题在这里已经有了答案:ParsingRFC-3339/ISO-8601date-timestringinGo(8个答案)关闭3年前。我将如何解析这个时间戳?“2019-09-1904:03:01.770080087+0000UTC”我尝试了以下方法:formatExample:=obj.CreatedOn//obj.CreatedOn="2019-09-1904:03:01.770080087+0000UTC"time,err:=time.Parse(formatExample,obj.CreatedOn)check(err)fmt.Println(time)但我得到的输出是:0
import"github.com/globalsign/mgo"job:=&mgo.MapReduce{Map:"function(){emit(this.name,1)}",Reduce:"function(key,values){returnArray.sum(values)}",Out:"res",}_,err=c.Find(nil).MapReduce(job,nil)如何在上面的golangmgomapreduce中添加'query'?引用:https://docs.mongodb.com/manual/core/map-reduce/https://godoc.org/g