ETL,是英文 Extract-Transform-Load 的缩写,用来描述将数据从来源端经过抽取(extract)、转换(transform)、加载(load)至目的端的过程。ETL 一词较常用在数据仓库,但其对象并不限于数据仓库。ETL是构建数据仓库的重要一环,用户从数据源抽取出所需的数据,经过数据清洗,最终按照预先定义好的数据仓库模型,将数据加载到数据仓库中去。ETL过程本质上是数据流动的过程,从不同的数据源流向不同的目标数据。
ETL在数据仓库中的几个特点:
数据同步,它不是一次性倒完数据就拉到,它是经常性的活动,按照固定周期运行的,甚至现在还有人提出了实时ETL的概念。
数据量,一般都是巨大的,值得你将数据流动的过程拆分成E、T和L。
根据E、T、L三个步骤的实现环境,目前有ETL和ELT两种架构。
随着企业的发展,目前的业务线越来越复杂,各个业务系统独立运营。
例如:CRM系统只会生产CRM的 数据;Billing只会生产Billing的数据。各业务系统之间只关心自己的数据,导致各业务系统之间数据相互独立,互不相通。一旦业务系统之间进行数据交互,只能通过传统的webservice接口之间进行数据通信。该种方式对人力成本、时间成本要求比较高。而ETL的诞生就解决了此类问题,企业不需要技术很好、很成熟的开发人员一样可以完成该任务。
ETL工作流程:先抽取、然后加载到目标数据库中、在目标数据库中完成转换操作。
ETL是将业务系统的数据经过抽取(Extract)、清洗转换(Transform)之后加载(Load)到数据仓库的过程,目的是将企业中的分散、零乱、标准不统一的数据整合到一起,为企业的决策提供分析依据。ETL 有两种形式:实时流 ETL 和 离线 ETL。
如下图所示,实时流 ETL 通常有两种形式:一种是通过 Flume 采集服务端日志,再通过 HDFS 直接落地;另一种是先把数据采集到 Kafka,再通过 Storm 或 Spark streaming 落地 HDFS,实时流 ETL 在出现故障的时候很难进行回放恢复。图中仅使用实时流 ETL 进行数据注入和清洗的工作。
根据 Lambda 结构,如果实时流 ETL 出现故障需要离线 ETL 进行修补。
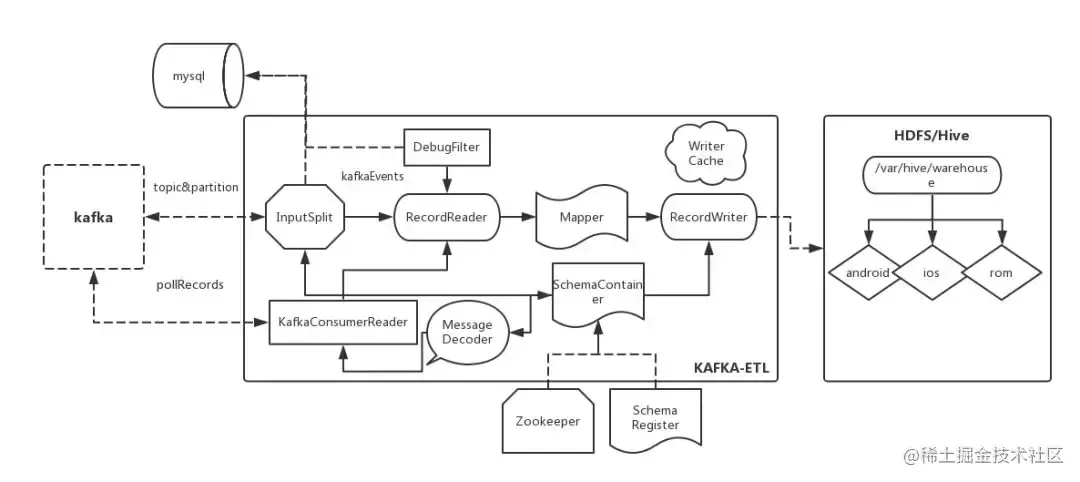
上图是离线 ETL 的基本工作流程:
1.kafka-etl 将业务数据清洗过程中的公共配置信息抽象成一个 etl schema ,代表各个业务不同的数据;
2.在 kafka-etl 启动时会从 zookeeper 拉取本次要处理的业务数据 topic&schema 信息;
3.kafka-etl 将每个业务数据按 topic、partition 获取的本次要消费的 offset 数据(beginOffset、endOffset),并持久化 mysql;
4.kafka-etl 将本次需要处理的 topic&partition 的 offset 信息抽象成 kafkaEvent,然后将这些 kafkaEvent 按照一定策略分片,即每个 mapper 处理一部分 kafkaEvent;
5.RecordReader 会消费这些 offset 信息,解析 decode 成一个个 key-value 数据,传给下游清洗处理;
6.清洗后的 key-value 统一通过 RecordWriter 数据落地 HDFS。
ETL处理分为五大模块,分别是:数据抽取、数据清洗、库内转换、规则检查、数据加载。各模块可灵活进行组合,形成ETL处理流程。
数据抽取
确定数据源,需要确定从哪些源系统进行数据抽取;
定义数据接口,对每个源文件及系统的每个字段进行详细说明;
确定数据抽取的方法:是主动抽取还是由源系统推送?是增量抽取还是全量抽取?是按照每日抽取还是按照每月抽取?
数据清洗与转换 数据清洗 主要将不完整数据、错误数据、重复数据进行处理
数据转换:
空值处理:可捕获字段空值,进行加载或替换为其他含义数据,并可根据字段空值实现分流加载到不同目标库
数据标准:统一元数据、统一标准字段、统一字段类型定义.可实现字段格式约束定义,对于数据源中时间、数值、字符等数据,可自定义加载格式。
数据拆分:依据业务需求做数据拆分,如身份证号,拆分区划、出生日期、性别等.例,主叫号 861082585313-8148,可进行区域码和电话号码分解。
数据验证:时间规则、业务规则、自定义规则.可利用Lookup及拆分功能进行数据验证。例如,主叫号861082585313-8148,进行区域码和电话号码分解后,可利用Lookup返回主叫网关或交换机记载的主叫地区,进行数据验证
数据替换:对于因业务因素,可实现无效数据、缺失数据的替换
数据关联:关联其他数据或数学,保障数据完整性 数据加载 将数据缓冲区的数据直接加载到数据库对应表中,如果是全量方式则采用LOAD方式,如果是增量则根据业务规则MERGE进数据库
Lookup:查获丢失数据 Lookup实现子查询,并返回用其他手段获取的缺失字段,保证字段完整性。
建立ETL过程的主外键约束:对无依赖性的非法数据,可替换或导出到错误数据文件中,保证主键唯一记录的加载。
我在从html页面生成PDF时遇到问题。我正在使用PDFkit。在安装它的过程中,我注意到我需要wkhtmltopdf。所以我也安装了它。我做了PDFkit的文档所说的一切......现在我在尝试加载PDF时遇到了这个错误。这里是错误:commandfailed:"/usr/local/bin/wkhtmltopdf""--margin-right""0.75in""--page-size""Letter""--margin-top""0.75in""--margin-bottom""0.75in""--encoding""UTF-8""--margin-left""0.75in""-
我在我的项目目录中完成了compasscreate.和compassinitrails。几个问题:我已将我的.sass文件放在public/stylesheets中。这是放置它们的正确位置吗?当我运行compasswatch时,它不会自动编译这些.sass文件。我必须手动指定文件:compasswatchpublic/stylesheets/myfile.sass等。如何让它自动运行?文件ie.css、print.css和screen.css已放在stylesheets/compiled。如何在编译后不让它们重新出现的情况下删除它们?我自己编译的.sass文件编译成compiled/t
我正在使用的第三方API的文档状态:"[O]urAPIonlyacceptspaddedBase64encodedstrings."什么是“填充的Base64编码字符串”以及如何在Ruby中生成它们。下面的代码是我第一次尝试创建转换为Base64的JSON格式数据。xa=Base64.encode64(a.to_json) 最佳答案 他们说的padding其实就是Base64本身的一部分。它是末尾的“=”和“==”。Base64将3个字节的数据包编码为4个编码字符。所以如果你的输入数据有长度n和n%3=1=>"=="末尾用于填充n%
我花了三天的时间用头撞墙,试图弄清楚为什么简单的“rake”不能通过我的规范文件。如果您遇到这种情况:任何文件夹路径中都不要有空格!。严重地。事实上,从现在开始,您命名的任何内容都没有空格。这是我的控制台输出:(在/Users/*****/Desktop/LearningRuby/learn_ruby)$rake/Users/*******/Desktop/LearningRuby/learn_ruby/00_hello/hello_spec.rb:116:in`require':cannotloadsuchfile--hello(LoadError) 最佳
关闭。这个问题需要detailsorclarity.它目前不接受答案。想改进这个问题吗?通过editingthispost添加细节并澄清问题.关闭8年前。Improvethisquestion在首页我有:汽车:VolvoSaabMercedesAudistatic_pages_spec.rb中的测试代码:it"shouldhavetherightselect"dovisithome_pathit{shouldhave_select('cars',:options=>['volvo','saab','mercedes','audi'])}end响应是rspec./spec/request
在Rails4.0.2中,我使用s3_direct_upload和aws-sdkgems直接为s3存储桶上传文件。在开发环境中它工作正常,但在生产环境中它会抛出如下错误,ActionView::Template::Error(noimplicitconversionofnilintoString)在View中,create_cv_url,:id=>"s3_uploader",:key=>"cv_uploads/{unique_id}/${filename}",:key_starts_with=>"cv_uploads/",:callback_param=>"cv[direct_uplo
使用Ruby1.9.2运行IDE提示说需要gemruby-debug-base19x并提供安装它。但是,在尝试安装它时会显示消息Failedtoinstallgems.Followinggemswerenotinstalled:C:/ProgramFiles(x86)/JetBrains/RubyMine3.2.4/rb/gems/ruby-debug-base19x-0.11.30.pre2.gem:Errorinstallingruby-debug-base19x-0.11.30.pre2.gem:The'linecache19'nativegemrequiresinstall
在应用开发中,有时候我们需要获取系统的设备信息,用于数据上报和行为分析。那在鸿蒙系统中,我们应该怎么去获取设备的系统信息呢,比如说获取手机的系统版本号、手机的制造商、手机型号等数据。1、获取方式这里分为两种情况,一种是设备信息的获取,一种是系统信息的获取。1.1、获取设备信息获取设备信息,鸿蒙的SDK包为我们提供了DeviceInfo类,通过该类的一些静态方法,可以获取设备信息,DeviceInfo类的包路径为:ohos.system.DeviceInfo.具体的方法如下:ModifierandTypeMethodDescriptionstatic StringgetAbiList()Obt
我知道全局变量$!包含最新的异常对象,但我对下面的语法感到困惑。谁能帮助我理解以下语法?rescue$! 最佳答案 此构造可防止异常停止您的程序并使堆栈跟踪冒泡。它还会将该异常作为值返回,这很有用。a=get_me_datarescue$!在此行之后,a将保存请求的数据或异常。然后您可以分析该异常并采取相应措施。defget_me_dataraise'Nodataforyou'enda=get_me_datarescue$!puts"Executioncarrieson"pa#>>Executioncarrieson#>>#更现实的
作为新的阿里云用户,您可以50免费试用多种优惠,价值高达1,700美元(或8,500美元)。这将让您了解和体验阿里云平台上提供的一系列产品和服务。如果您以个人身份注册免费试用,您将获得价值1,700美元的优惠。但是,如果您是注册公司,您可以选择企业免费试用,提交基本信息通过企业实名注册验证,即可开始价值$8,500的免费试用!本教程介绍了如何设置您的帐户并使用您的免费试用版。关于免费试用在我们开始此试用之前,您还必须遵守以下条款和条件才能访问您的免费试用:只有在一年内创建的账户才有资格获得阿里云免费试用。通过此免费试用优惠,用户可以免费试用免费试用活动页面上列出的每种产品一次。如果您有多个帐