作者 | 崔皓
审校 | 重楼
一次革命性的技术升级,ChatGPT 4.0的发布震动了整个AI行业。现在,不仅可以让计算机识别并回答日常的自然语言问题,ChatGPT还可以通过对行业数据建模,提供更准确的解决方案。本文将带您深入了解ChatGPT的架构原理及其发展前景,同时介绍如何使用ChatGPT的API训练行业数据。让我们一起探索这个崭新且极具前途的领域,开创一个新的AI时代。
ChatGPT 4.0 已经正式发布了!这一版本的 ChatGPT 引入了跨越式革新,与之前的 ChatGPT 3.5 相比,它在模型的性能和速度方面都有了巨大的提升。在ChatGPT 4.0发布之前,许多人已经关注过ChatGPT,并意识到它在自然语言处理领域的重要性。然而,在3.5以及之前的版本,ChatGPT的局限性仍然存在,因为它的训练数据主要集中在通用领域的语言模型中,难以生成与特定行业相关的内容。但是,随着ChatGPT 4.0的发布,越来越多的人已经开始使用它来训练他们自己的行业数据,并被广泛应用于各个行业。这使得越来越多的人从关注到使用 ChatGPT。接下来,我将为您介绍一下 ChatGPT 的架构原理、发展前景以及在训练行业数据方面的应用。
ChatGPT的架构基于深度学习神经网络,是一种自然语言处理技术,其原理是使用预先训练的大型语言模型来生成文本,使得机器可以理解和生成自然语言。ChatGPT的模型原理基于Transformer网络,使用无监督的语言建模技术进行训练,预测下一个单词的概率分布,以生成连续的文本。使用参数包括网络的层数、每层的神经元数量、Dropout概率、Batch Size等。学习的范围涉及了通用的语言模型,以及特定领域的语言模型。通用领域的模型可以用于生成各种文本,而特定领域的模型则可以根据具体的任务进行微调和优化。
OpenAI利用了海量的文本数据作为GPT-3的训练数据。具体来说,他们使用了超过45TB的英文文本数据和一些其他语言的数据,其中包括了网页文本、电子书、百科全书、维基百科、论坛、博客等等。他们还使用了一些非常大的数据集,例如Common Crawl、WebText、BooksCorpus等等。这些数据集包含了数万亿个单词和数十亿个不同的句子,为模型的训练提供了非常丰富的信息。
既然要学习这么多的内容,使用的算力也是相当可观的。ChatGPT花费的算力较高,需要大量的GPU资源进行训练。据OpenAI在2020年的一份技术报告中介绍,GPT-3在训练时耗费了大约175亿个参数和28500个TPU v3处理器。
从上面的介绍,我们知道了ChatGPT具有强大的能力,同时也需要一个庞大的计算和资源消耗,训练这个大型语言模型需要花费高昂成本。但花费了这样高昂的成本生产出来的AIGC工具却存在其局限性,对于某些专业领域的知识它并没有涉足。例如,当涉及到医疗或法律等专业领域时,ChatGPT就无法生成准确的答案。这是因为ChatGPT的学习数据来源于互联网上的通用语料库,这些数据并不包括某些特定领域的专业术语和知识。因此,要想让ChatGPT在某些专业领域具有较好的表现,需要使用该领域的专业语料库进行训练,也就是说将专业领域专家的知识“教给”ChatGPT进行学习。
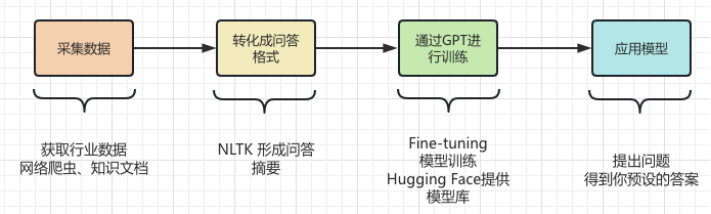
但是,ChatGPT并没有让我们失望。如果将ChatGPT应用到某个行业中,需要先将该行业的专业数据提取出来,并进行预处理。具体来说,需要对数据进行清洗、去重、切分、标注等一系列处理。之后,将处理后的数据进行格式化,将其转换为符合ChatGPT模型输入要求的数据格式。然后,可以利用ChatGPT的API接口,将处理后的数据输入到模型中进行训练。训练的时间和花费取决于数据量和算力大小。训练完成后,可以将模型应用到实际场景中,用于回答用户的问题。
其实建立专业领域的知识库并不难,具体操作就是将行业数据转换为问答格式,然后将问答的格式通过自然语言处理(NLP)技术进行建模,从而回答问题。使用OpenAI的GPT-3 API(以GPT3 为例)可以创建一个问答模型,只需提供一些示例,它就可以根据您提供的问题生成答案。
使用GPT-3 API创建问答模型的大致步骤如下:

整个过程需要调用OpenAI,它提供不同类型的API订阅计划,其中包括Developer、Production和Custom等计划。每个计划都提供不同的功能和API访问权限,并且有不同的价格。因为并不是本文的重点,在这里不展开说明。
从上面的操作步骤来看,第2步转化为问答格式对我们来说是一个挑战。
假设有关于人工智能的历史的领域知识需要教给GPT,并将这些知识转化为回答相关问题的模型。那就要转化成如下的形式:
|
当然整理成这样问答的形式还不够,需要形成GPT能够理解的格式,如下所示:
|
实际上就是在问题后面加上了“\n\n”,而在回答后面加上了“\n”。
解决了问答格式问题,新的问题又来了,我们如何将行业的知识都整理成问答的模式呢?多数情况,我们从网上爬取大量的领域知识,或者找一大堆的领域文档,不管是哪种情况,输入文档对于我们来说是最方便的。但是将大量的文本处理成问答的形式,使用正则表达式或者人工的方式显然是不现实的。
因此就需要引入一种叫做自动摘要(Automatic Summarization)的技术,它可以从一篇文章中提取出关键信息,并生成一个简短的摘要。
自动摘要有两种类型:抽取式自动摘要和生成式自动摘要。抽取式自动摘要从原始文本中抽取出最具代表性的句子来生成摘要,而生成式自动摘要则是通过模型学习从原始文本中提取重要信息,并根据此信息生成摘要。实际上,自动摘要就是将输入的文本生成问答模式。
问题搞清楚了接下来就是上工具了,我们使用NLTK来搞事情,NLTK是Natural Language Toolkit的缩写,是一个Python库,主要用于自然语言处理领域。它包括了各种处理自然语言的工具和库,如文本预处理、词性标注、命名实体识别、语法分析、情感分析等。
我们只需要将文本交给NLTK,它会对文本进行数据预处理操作,包括去除停用词、分词、词性标注等。在预处理之后,可以使用NLTK中的文本摘要生成模块来生成摘要。可以选择不同的算法,例如基于词频、基于TF-IDF等。在生成摘要的同时,可以结合问题模板来生成问答式的摘要,使得生成的摘要更加易读易懂。同时还可以对摘要进行微调,例如句子连贯性不强、答案不准确等,都可以进行调整。
来看下面的代码:
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM, pipeline import nltk # 输入文本 text = """Natural Language Toolkit(自然语言处理工具包,缩写 NLTK)是一套Python库,用于解决人类语言数据的处理问题,例如: 分词 词性标注 句法分析 情感分析 语义分析 语音识别 文本生成等等 """ # 生成摘要 sentences = nltk.sent_tokenize(text) summary = " ".join(sentences[:2]) # 取前两个句子作为摘要 print("摘要:", summary) # 用生成的摘要进行Fine-tuning,得到模型 tokenizer = AutoTokenizer.from_pretrained("t5-base") model = AutoModelForSeq2SeqLM.from_pretrained("t5-base") text = "summarize: " + summary # 构造输入格式 inputs = tokenizer(text, return_tensors="pt", padding=True) # 训练模型 model_name = "first-model" model.save_pretrained(model_name) # 测试模型 qa = pipeline("question-answering", model=model_name, tokenizer=model_name) context = "What is NLTK used for?" # 待回答问题 answer = qa(questinotallow=context, cnotallow=text["input_ids"]) print("问题:", context) print("回答:", answer["answer"]) |
输出结果如下:
摘要: Natural Language Toolkit(自然语言处理工具包,缩写 NLTK)是一套Python库,用于解决人类语言数据的处理问题,例如: - 分词 - 词性标注 问题: NLTK用来做什么的? 答案:自然语言处理工具包 |
上面的代码通过nltk.sent_tokenize方法对输入的文本进行摘要的抽取,也就是进行问答格式化。然后,调用Fine-tuning的AutoModelForSeq2SeqLM.from_pretrained方法对其进行建模,再将名为“first-model”的模型进行保存。最后调用训练好的模型测试结果。
上面不仅通过NLTK生成了问答的摘要,还需要使用Fine-tuning的功能。Fine-tuning是在预训练模型基础上,通过少量的有标签的数据对模型进行微调,以适应特定的任务。实际上就是用原来的模型装你的数据形成你的模型,当然你也可以调整模型的内部结果,例如隐藏层的设置和参数等等。这里我们只是使用了它最简单的功能,可以通过下图了解更多Fine-tuning的信息。
需要说明的是:AutoModelForSeq2SeqLM 类,从预训练模型 "t5-base" 中加载 Tokenizer 和模型。
AutoTokenizer 是 Hugging Face Transformers 库中的一个类,可以根据预训练模型自动选择并加载合适的 Tokenizer。Tokenizer 的作用是将输入的文本编码为模型可以理解的格式,以便后续的模型输入。
AutoModelForSeq2SeqLM 也是 Hugging Face Transformers 库中的一个类,可以根据预训练模型自动选择并加载适当的序列到序列模型。在这里,使用的是基于T5架构的序列到序列模型,用于生成摘要或翻译等任务。在加载预训练模型之后,可以使用此模型进行 Fine-tuning 或生成任务相关的输出。
上面我们对建模代码进行了解释,涉及到了Fine-tunning和Hugging Face的部分,可能听起来比较懵。这里用一个例子帮助大家理解。
假设你要做菜,虽然你已经有食材(行业知识)了,但是不知道如何做。于是你向厨师朋友请教,你告诉他你有什么食材(行业知识)以及要做什么菜(解决的问题),你的朋友基于他的经验和知识(通用模型)给你提供一些建议,这个过程就是Fine-tuning(把行业知识放到通用模型中进行训练)。你朋友的经验和知识就是预先训练的模型,你需要输入行业知识和要解决的问题,并使用预先训练的模型,当然可以对这个模型进行微调,比如:佐料的含量,炒菜的火候,目的就是为了解决你行业的问题。
而 Hugging Face就是菜谱的仓库(代码中"t5-base"就是一个菜谱),它包含了很多定义好的菜谱(模型),比如:鱼香肉丝、宫保鸡丁、水煮肉片的做法。这些现成的菜谱,可以配合我们提供食材和需要做的菜创建出我们的菜谱。我们只需要对这些菜谱进行调整,然后进行训练,就形成了我们自己的菜谱。以后,我们就可以用自己的菜谱进行做菜了(解决行业问题)。
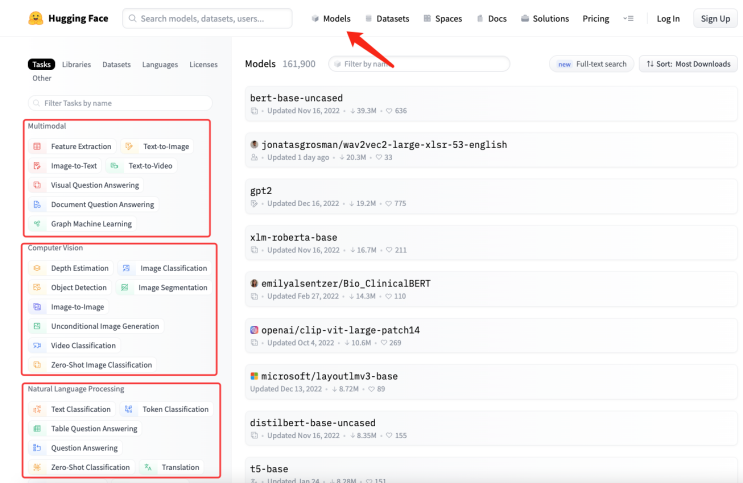
可以在 Hugging Face 的模型库中搜索你需要的模型。如下图所示,在 Hugging Face 的官网上,点击"Models",可以看到模型的分类,同时也可以使用搜索框搜索模型名称。
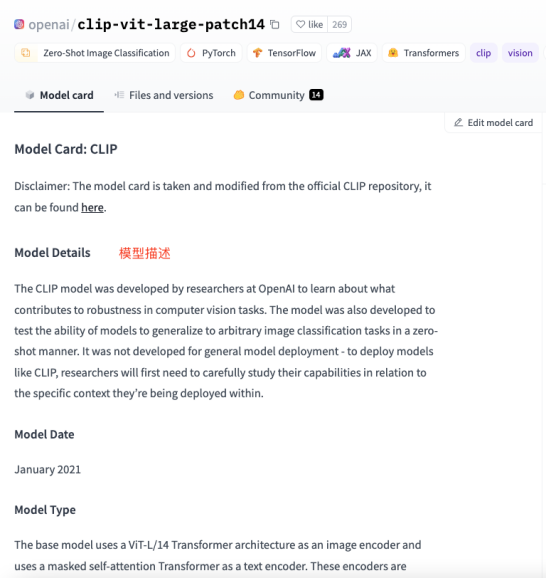
如下图所示,每个模型页面都会提供模型的描述、用法示例、预训练权重下载链接等相关信息。
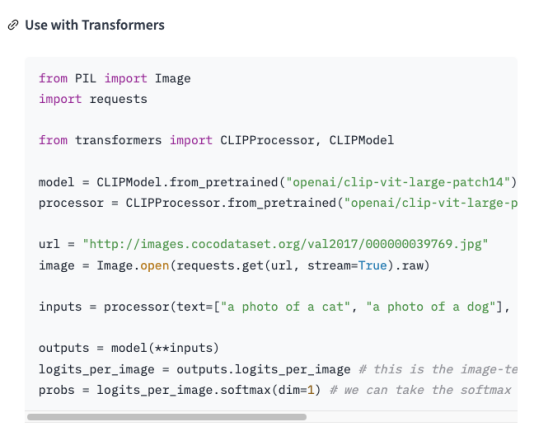
这里将整个行业知识从采集、转化、训练和使用的过程再和大家一起捋一遍。如下图所示:
崔皓,51CTO社区编辑,资深架构师,拥有18年的软件开发和架构经验,10年分布式架构经验。
出于纯粹的兴趣,我很好奇如何按顺序创建PI,而不是在过程结果之后生成数字,而是让数字在过程本身生成时显示。如果是这种情况,那么数字可以自行产生,我可以对以前看到的数字实现垃圾收集,从而创建一个无限系列。结果只是在Pi系列之后每秒生成一个数字。这是我通过互联网筛选的结果:这是流行的计算机友好算法,类机器算法:defarccot(x,unity)xpow=unity/xn=1sign=1sum=0loopdoterm=xpow/nbreakifterm==0sum+=sign*(xpow/n)xpow/=x*xn+=2sign=-signendsumenddefcalc_pi(digits
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
使用带有Rails插件的vim,您可以创建一个迁移文件,然后一次性打开该文件吗?textmate也可以这样吗? 最佳答案 你可以使用rails.vim然后做类似的事情::Rgeneratemigratonadd_foo_to_bar插件将打开迁移生成的文件,这正是您想要的。我不能代表textmate。 关于ruby-使用VimRails,您可以创建一个新的迁移文件并一次性打开它吗?,我们在StackOverflow上找到一个类似的问题: https://sta
我对最新版本的Rails有疑问。我创建了一个新应用程序(railsnewMyProject),但我没有脚本/生成,只有脚本/rails,当我输入ruby./script/railsgeneratepluginmy_plugin"Couldnotfindgeneratorplugin.".你知道如何生成插件模板吗?没有这个命令可以创建插件吗?PS:我正在使用Rails3.2.1和ruby1.8.7[universal-darwin11.0] 最佳答案 随着Rails3.2.0的发布,插件生成器已经被移除。查看变更日志here.现在
如何使用RSpec::Core::RakeTask初始化RSpecRake任务?require'rspec/core/rake_task'RSpec::Core::RakeTask.newdo|t|#whatdoIputinhere?endInitialize函数记录在http://rubydoc.info/github/rspec/rspec-core/RSpec/Core/RakeTask#initialize-instance_method没有很好的记录;它只是说:-(RakeTask)initialize(*args,&task_block)AnewinstanceofRake
从给定URL下载文件并立即将其上传到AmazonS3的更直接的方法是什么(+将有关文件的一些信息保存到数据库中,例如名称、大小等)?现在,我既不使用Paperclip,也不使用Carrierwave。谢谢 最佳答案 简单明了:require'open-uri'require's3'amazon=S3::Service.new(access_key_id:'KEY',secret_access_key:'KEY')bucket=amazon.buckets.find('image_storage')url='http://www.ex
关闭。这个问题需要detailsorclarity.它目前不接受答案。想改进这个问题吗?通过editingthispost添加细节并澄清问题.关闭8年前。Improvethisquestion为什么SecureRandom.uuid创建一个唯一的字符串?SecureRandom.uuid#=>"35cb4e30-54e1-49f9-b5ce-4134799eb2c0"SecureRandom.uuid方法创建的字符串从不重复?
我正在阅读SandiMetz的POODR,并且遇到了一个我不太了解的编码原则。这是代码:classBicycleattr_reader:size,:chain,:tire_sizedefinitialize(args={})@size=args[:size]||1@chain=args[:chain]||2@tire_size=args[:tire_size]||3post_initialize(args)endendclassMountainBike此代码将为其各自的属性输出1,2,3,4,5。我不明白的是查找方法。当一辆山地自行车被实例化时,因为它没有自己的initialize方法
我正在尝试按0-9和a-z的顺序创建数字和字母列表。我有一组值value_array=['0','1','2','3','4','5','6','7','8','9','a','b','光盘','e','f','g','h','i','j','k','l','m','n','o','p','q','r','s','','u','v','w','x','y','z']和一个组合列表的数组,按顺序,这些数字可以产生x个字符,比方说三个list_array=[]和一个当前字母和数字组合的数组(在将它插入列表数组之前我会把它变成一个字符串,]current_combo['0','0','0']
英文版英文链接关注公众号在“亚特兰蒂斯的回声”中踏上一段难忘的冒险之旅,深入未知的海洋深处。足智多谋的考古学家AriaSeaborne偶然发现了一件古代神器,揭示了一张通往失落之城亚特兰蒂斯的隐藏地图。在她神秘的导师内森·兰登教授的指导和勇敢的冒险家亚历克斯·默瑟的帮助下,阿丽亚开始了一段危险的旅程,以揭开这座传说中城市的真相。他们的冒险之旅带领他们穿越险恶的大海、神秘的岛屿和充满陷阱和谜语的致命迷宫。随着Aria潜在的魔法能力的觉醒,她被睿智勇敢的QueenNeria的幻象所指引,她让她为即将到来的挑战做好准备。三人组揭开亚特兰蒂斯令人惊叹的隐藏文明,并了解到邪恶的巫师马拉卡勋爵试图利用其古