
蓝桥杯省赛将在4月初举行,距离比赛也就剩一个多月的时间。为了提高自己的编程能力,在比赛中取得比较👌的成绩。接下来的一个多月我会在博客中更新蓝桥杯的学习。争取在考前将一些重要的算法过一遍。

蓝桥杯常考的算法我整理到了一张思维导图里面,小伙伴可以看一下噢。
这张蓝桥杯思维导图可能不太全面,以后会经常补充的。。
我是这样想滴,我会对常考的算法做个专题总结,分专题来讲。文章更新的速度呢取决于我刷题的速度啦! 因为每写一个专题必然要写运用到这种算法的题目啦~鲁迅先生说过 “只讲解算法思想,不实际运用就是在耍流氓”。写蓝桥杯文章的过程是这个样子的,先确定要写哪个专题,然后呢大量刷题,模板题啦,经典题啦,最最重要的是历届的蓝桥杯真题啦。刷完之后呢做总结理清这种算法的基本思路,最后就形成了一篇蓝桥杯备考文章啦。当然文章是要时常更改补充的,因为在刷题的过程中可能对某些算法思想有了新的感悟~也要参加蓝桥杯的小伙伴们可以一起期待噢,关注我一定不会让你失望的。噢还有我参加的是C++组所以呢我写的题解也是C++的。
我的CSDN博客 https://blog.csdn.net/ccevv/
好啦接下来进入正题。

我们知道蓝桥杯俗称暴力杯,搜索在蓝桥杯中是最最基本的算法思想。学会DFS和BFS是在蓝桥杯比赛中取得好成绩的基础。我会从这几个方面入手,给小伙伴们详细讲解搜索专题。
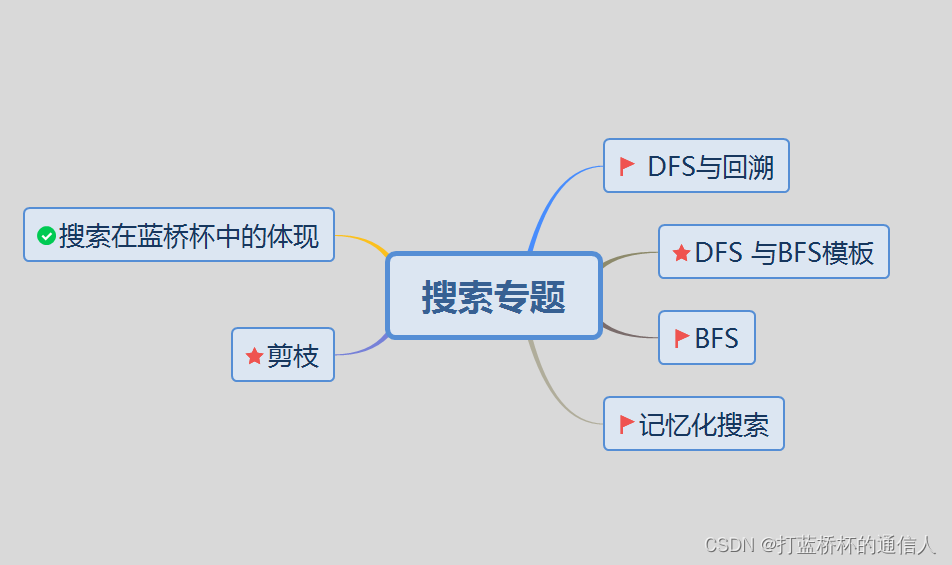
本篇的内容主要有以下几个方面噢,小伙伴们可以有个大致了解。
DFS基本思想(DFS+回溯)
深度优先搜索模板
DFS例题
剪枝思想
剪枝思想在DFS中的应用
文章目录
DFS是一种搜索的策略,简单来说就是一条路走到黑。当走到尽头之后就回退到上一个结点,继续一条路走到黑。回退的过程就叫做回溯。
DFS一般采用递归的方式实现。
对递归的详细讲解会在以后出一个独立的专题,小伙伴们可以期待一下噢!
DFS可以用一个递归搜索树来形象描述,那这棵树长什么样子呢,小伙伴们继续往下看。
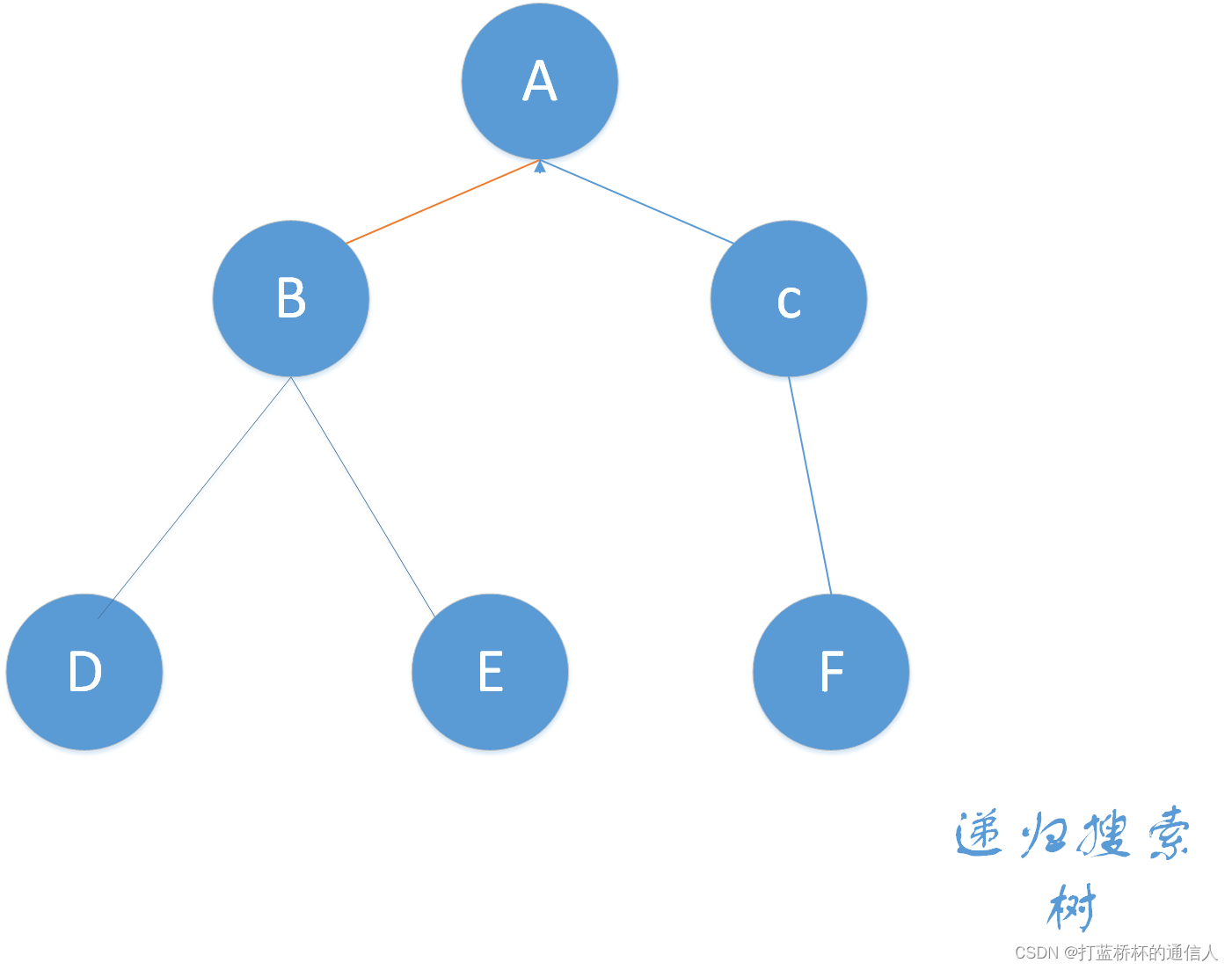
事实上对所有的合法DFS求解过程都可以把它画成树的形式,死胡同就相当于叶子结点。分岔口就相当于非叶子结点。
对某个DFS类型的题目,不妨把一些状态作为树的结点,问题就变得很直观了。
DFS搜索的顺序是A-B-D-E-C-F。从结点A出发,它有两条路可以走,我们选择最左边那一条,到达结点B,结点B有两个分支,选择最左边那个,到达结点D。结点D没有路可走了也就是到达死胡同了,返回上一个结点B,也就是回溯的过程。B还有一条路可走,到达结点E。同理结点E回溯到结点B,结点B没有分支了,回溯到上一个结点A,结点A还有一个分支可以走,到达结点C,结点C有一个分支到达结点F,结点F是死胡同。至此所有的结点都访问了,搜索结束。
其实DFS的搜索顺序和树的先序遍历是一样的。树的先序遍历就是根左右。
从递归树我们就能看出DFS的时间复杂度是很高的,是
O
(
2
n
)
O(2^n)
O(2n)。所以我们常说暴力搜索嘛,就是因为它时间复杂度太高了,当数据很大时很容易就TLE(超时)的。同时我们还能看出DFS会走遍所有的路径,并且走到死胡同就代表一条完整的路径形成。因此深度优先搜索是一种枚举所有路径,遍历所有情况的搜索策略。
在备战蓝桥杯的过程中记住一些算法模板还是非常重要滴。
#include <iostream>
using namespace std;
bool check()
{
...
}
void dfs()
{
if (满足边界条件)
{
return;
}
for (int i = 0; i < 可扩展的路径数; i++)
{
if (check())
{
修改现场;
dfs(下一种情况);
还原现场;
}
}
}
模板不是固定不变的,我们要根据题目灵活地运用它。
题目链接
题目分析
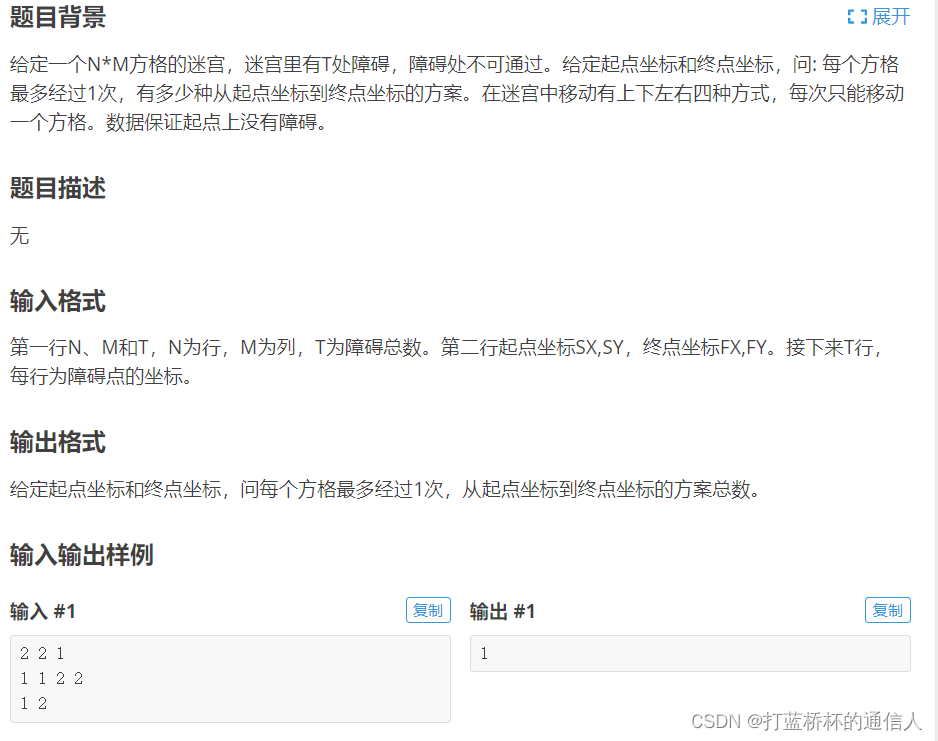
迷宫问题是拿来练习DFS与BFS很经典的题目。迷宫问题有很多种问法,比如迷宫从起点到终点有没有路径,有几条,最短路径是多少。
求从起点到终点的方案数显而易见也是要用DFS,遍历所有的情况。我们要考虑这样一个问题,迷宫里的某点(x,y)是否要被访问呢。当这点是障碍物肯定不能访问,该点不在迷宫里面也不能访问,该点访问过了那就不能访问了。(题目中有每个方格最多经过一次)。因此我们需要一个check()函数来判断某一点是否合法。合法我们就去访问该点。
其实这个过程就是一个剪枝的过程,根据题目条件限制,剪掉一些不可能存在解的分支。
另外我们该如何知道某点是障碍点呢,可以设置一个map数组来表示该迷宫。
map[x][y]==1时表示该点是障碍点map[x][y]==0表示该点是正常点AC代码
#include <iostream>
using namespace std;
const int N = 100;
int dx[4] = {0, 0, -1, 1};
int dy[4] = {1, -1, 0, 0};//方向数组技巧
int n, m, T;//n行m列T障碍总数
int ans;//记录方案总数
int sx, sy, fx, fy, l, r;//起点坐标(sx,sy)终点坐标(fx,fy)障碍点坐标(l,r)
bool visited[N][N];//记录某点是否被访问过
int map[N][N];//map[i][j] == 1表示是障碍
bool check(int x, int y)//check某点是否合法
{
if (x < 1 || x > n || y < 1 || y > m) return false;//该点出界不合法
if (map[x][y]) return false;//该点是障碍点不合法
if (visited[x][y]) return false;//该点被访问过不合法
return true;//其他情况访问合法
}
void dfs(int x, int y)//dfs维护点的坐标参数
{
if (x == fx && y == fy)//满足边界条件,到达终点
{
ans++;//方案数+1
return;
}
for (int i = 0; i < 4; i++)//枚举四个方向
{
int newx = x + dx[i];
int newy = y + dy[i];
if (check(newx, newy))//该点合法
{
visited[x][y] = true;//将(x,y)设置成已访问,修改现场
dfs(newx, newy);//dfs下一个点
visited[x][y] = false;//回溯,恢复现场
}
}
}
int main()
{
cin >> n >> m >> T;
cin >> sx >> sy >> fx >> fy;
while(T--)
{
cin >> l >> r;
map[l][r] = 1;
}
dfs(sx, sy);//从起点开始搜索
cout << ans << endl;
return 0;
}
小伙伴们每道例题都要好好看一下AC代码噢,上面有很详细的注释。
这道题还可以优化下空间,可以只用maze数组来表示迷宫,同时记录迷宫内的某点是否访问过。具体见下面的代码。
//空间优化
#include <iostream>
using namespace std;
const int N = 100;
int dx[4] = {0, 0, -1, 1};
int dy[4] = {1, -1, 0, 0};//方向数组
int n, m, T;
int ans;
int sx, sy, fx, fy, l, r;
//bool visited[N][N];
int map[N][N];//map[i][j] == 1表示是障碍
bool check(int x, int y)//判断某点是否可以访问
{
if (x < 1 || x > n || y < 1 || y > n) return false;
if (map[x][y] || map[x][y] == 3 ) return false;//该点是障碍点或已经访问过,不能访问
//if (visited[x][y]) return false;
return true;
}
void dfs(int x, int y)
{
if (x == fx && y == fy)
{
ans++;
return;
}
for (int i = 0; i < 4; i++)
{
int newx = x + dx[i];
int newy = y + dy[i];
if (check(newx, newy))
{
map[x][y] = 3;//标记成已访问
dfs(newx, newy);
//点(x,y)能访问说明它不是障碍点所以回溯要让map[x][y]=0
//而不是map[x][y]=1
map[x][y] = 0;
}
}
}
int main()
{
cin >> n >> m >> T;
cin >> sx >> sy >> fx >> fy;
while(T--)
{
cin >> l >> r;
map[l][r] = 1;
}
dfs(sx, sy);
cout << ans << endl;
return 0;
}
题目链接
题目分析
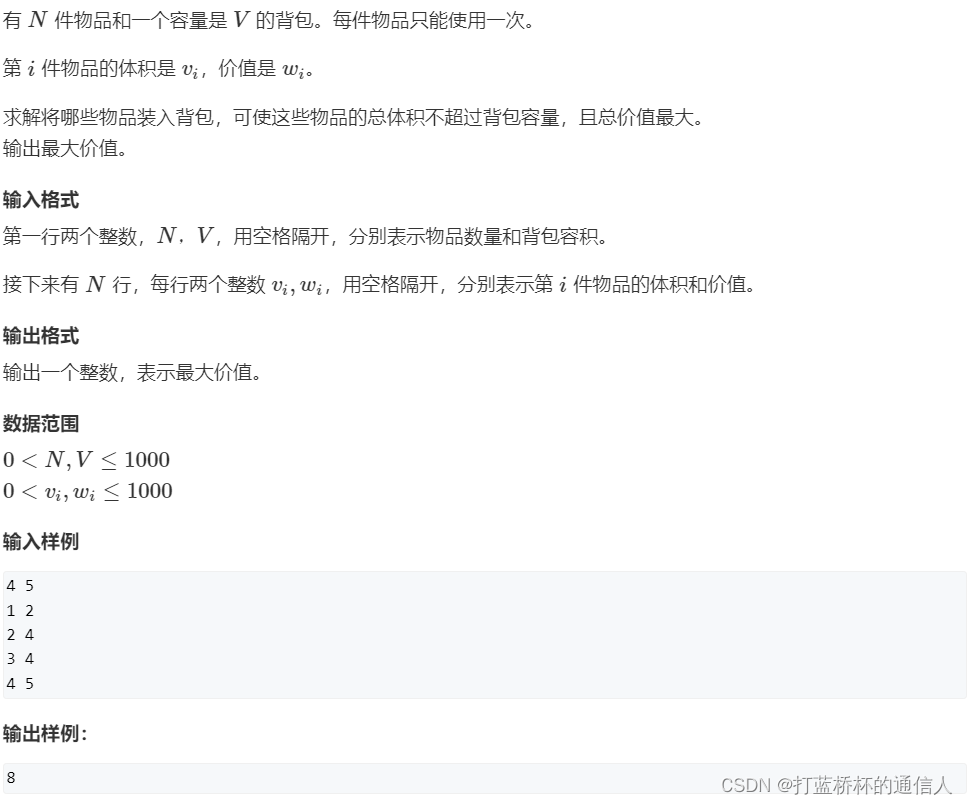
01背包问题是一个很经典的问题,它有多种解法。DFS是其中一种,在学习动态规划的时候还会提到它噢。
第i件物品无非就是选和不选两种情况,在搜索的过程中DFS函数必须要记录当前处理的物品编号index,当前背包的容量sumW,当前的总价值sumC。
index个物品时,那么sumW,sumC是不变的,接着处理第index+1个物品,也就是DFS(index+1, sumW, sumC)。index个物品时,sumW变成sumW+w[index],sumC变成sumC+v[index],接着处理第index+1个物品,也就是DFS(index+1, sumW+w[index],sumC+v[index])。边界条件也就是把最后一件物品也处理完了,即index=n(注意默认index从0开始)。当一条分支结束了该干什么呢,很简单呀就是判断该分支最终满不满足总重量不大于背包容量。即sumW<=v。满足的话我们就更新价值maxvalue,即maxvalue=max(maxvalue,sumC)。
AC代码
//01背包问题的dfs版本
#include <iostream>
#include <algorithm>
using namespace std;
const int N = 10010;
int n, v, maxvalue;
int w[N], c[N];
//DFS维护三个参数,正在选第index个物品,当前的总体积,当前的总价值
void dfs(int index, int sumW, int sumC)
{
if (index == n)
{
if (sumW <= v)
{
maxvalue = max(maxvalue, sumC);
}
return;
}
dfs(index + 1, sumW, sumC);//不选第index个物品
dfs(index + 1, sumW + w[index], sumC + c[index]);//选第index个物品
}
int main()
{
cin >> n >> v;
for (int i = 0; i < n; i++)
{
cin >> w[i] >> c[i];
}
dfs(0, 0, 0);//开始时对第1件物品进行选择,此时背包重量0价值也是0
cout << maxvalue << endl;
return 0;
}
当然了01背包问题如果用
DFS来解决的话,当数据比较大时,是不能AC的。这道题会超出时间限制。即便经过剪枝也是无能为力的。
题目链接

题目分析
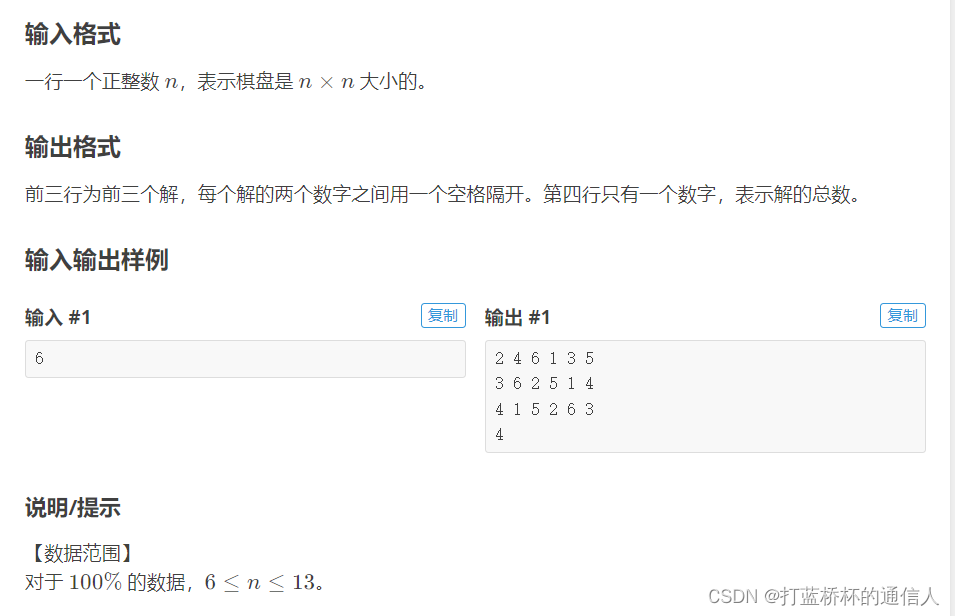
八皇后问题是学习回溯很经典的例题,这道题是八皇后问题的扩展,N皇后问题。也就是棋盘的大小是任意的。
这道题DFS的思路还是比较清晰的,每行有且只有一个棋子,那么DFS可以记录下当前处理的是第几行的棋子。假设当前处理的是第i行的棋子,那么要枚举处在该行的棋子位置,判断哪个是合法的。
什么样的位置算是合法的呢,这个位置的列还有左对角线,右对角线位置都不能有棋子。那么又该如何表示这些位置呢?我们采用一维数组来分别表示列,左对角线,右对角线。列很好表示就是b[j],左对角线我们可以发现行减去列的绝对值是恒定的,即c[i-j+n],右对角线行加列是恒定的。即d[i+j]。
小伙伴们可以自己画画图看一看噢~
当某位置放置了棋子,那么就将和它同列同对角线的位置都取为1,即b[j]=1,c[i-j+n]=1,d[i+j]=1。
AC代码
#include <iostream>
using namespace std;
int a[100], b[100], c[100], d[100];//a[]储存解b列c左斜d右斜
int n;//棋盘大小
int ans;
bool check(int i, int j)//检查(i,j)是否合法
{
if (!b[j] && !c[j - i + n] && !d[j + i]) return true;//b[j],c[i-j+n],d[i+j]为0说明该点可以放置棋子。
return false;
}
void dfs(int i)//dfs第i行棋子
{ //边界条件
if (i > n)//dfs完所有的棋子
{
ans++;
if (ans <= 3)//只要前三个解
{
for (int i = 1; i <= n; i++)//输出解
{
cout << a[i] << ' ';
}
cout << endl;
}
return;
}
for (int j = 1; j <= n; j++)//枚举一行的所有位置
{ //(i,j)点满足放棋子的条件,我们就把棋子放在(i,j)点
if (check(i, j))
{
a[i] = j;//把满足解的列号存在a[i]中
b[j] = 1;//修改现场
c[ j - i + n] = 1;
d[j + i] = 1;
dfs(i + 1);//处理下一行的棋子
b[j] = 0;//回溯,恢复现场
c[j - i + n] = 0;
d[j + i] = 0;
}
}
}
int main()
{
cin >> n;
dfs(1);
cout << ans << endl;
return 0;
}
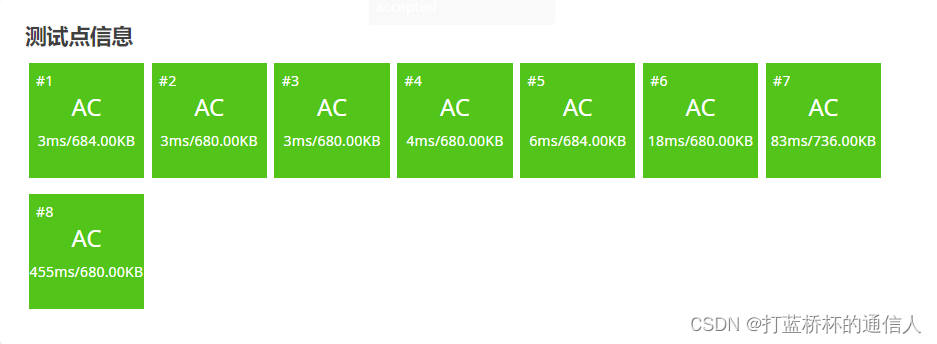
题目链接
题目分析
DFS可以用来处理排列组合问题。
对于全排列问题我们可以这样想,第1个位置可以放1~n任意一个数,第2个位置可以放除了放在第1个位置的数以外的任何一个数,以此类推。因此我们可以画出一个递归搜索树,用map[]来表示储存当前排列。DFS函数要记住当前处理的是第index个位置,从1到n进行遍历,看看这个数是否可以放在第index个位置,需要有一个判重数组hashtable[x]来记录x是否在排列里面。
AC代码
#include <iostream>
using namespace std;
const int N = 11;
//map[N]储存当前的排列,hashtable[N]判断某个数是否在排列里
int map[N];
bool hashtable[N];面。
int n;
void dfs(int index)//当前填第index位置
{
if (index == n + 1)//已经处理完1~n个位置
{
for (int i = 1; i <= n; i++)//输出当前排列
{
cout << map[i] << ' ';
}
cout << endl;
return;
}
for (int i = 1; i <= n; i++)//枚举1~n
{
if (hashtable[i] == false)//当i这个数没有填在map中
{
map[index] = i;//第index位置填入i这个数
hashtable[i] = true;//记i在当前排列
dfs(index + 1);//处理第index+1位置
//处理完map[index]=i的子问题,恢复现场
hashtable[i] = false;
map[index] = 0;
}
}
}
int main()
{
cin >> n;
dfs(1);//从1这个数开始搜索
return 0;
}
题目链接

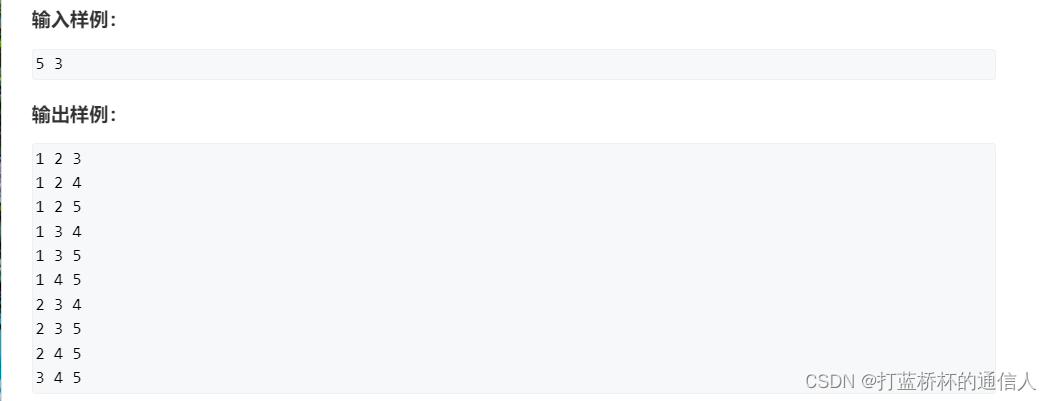
题目分析
组合和排列的最大区别就是组合不需要考虑顺序,也就是说123和132是一样的。
由于题目要求同一行的数必须按升序排序,因此可以让DFS函数记录当前处理的第index个位置,可以选的最小数start。
虽然参数变成了两个,但是不需要判重数组了。
DFS的思路是这个样子的,假设当前处理的是第index个位置,这个位置可以放置start~n其中任意一个数。接着处理第index+1个位置,这个位置可以放置的最小数是前一位数的下一个数。即i+1~n。
AC代码
#include <iostream>
using namespace std;
const int N = 30;
int map[N];//存储解
int n, m;
//dfs记录当前处理的第index个位置,可以选的最小数start
void dfs(int index, int start)
{
if (index > m)//m个位置都处理完了
{
for (int i = 1; i <= m; i++)//输出方案
{
cout << map[i] << " ";
}
cout << endl;
return;
}
//第index个位置可以选择start~n里面的数
for (int i = start; i <= n; i++)
{
map[index] = i;
//处理index+1位置,能选择的最小数是前面选择的数+1
dfs(index + 1, i + 1);
//处理完第index位置放置i这个数的子问题后回溯。
map[index] = 0;
}
}
int main()
{
cin >> n >> m;
dfs(1, 1);
return 0;
}
前面也提到过剪枝的概念,现在详细说下剪枝这种东西。我们知道DFS时间复杂度是很高的,如果不进行一些优化的话,在数据很大的情况下很容易就爆TLE。这个时候我们就可以用剪枝这种东西来优化啦~
在进行DFS的过程中对某条可以确定不存在解的分支采用直接剪短的策略。这样会大大降低计算量。一个搜索树剪掉一些分支就形象的叫它剪枝了。
剪枝一般都是利用题目的限制条件来确定哪些分支是不可能存在解的。
小伙伴们来回忆下01背包问题,我们是在选择完所有物品后才进行判断,看看背包总体积是否超过背包容量。是不是可以在选择的过程中就加入这一判断,这样就可以减少很多的计算量。当选第index件物品时,如果选上它那么背包的总体积就超出背包容量,我们一定不能选了。此时选第index件物品的分支就不可能存在解,直接剪掉。
//DFS维护三个参数,正在选第index个物品,当前的总体积,当前的总价值
void dfs(int index, int sumW, int sumC)
{
if (index == n)//选择完所有的物品,最终的sumW一定不大于v
{
maxvalue = max(maxvalue, sumC);
return;
}
dfs(index + 1, sumW, sumC);//不选第index个物品
if (sum + w[index] <= v)//剪枝
{ //选第index个物品
dfs(index + 1, sumW + w[index], sumC + c[index]);
}
}
小伙伴们再来回忆下前面的组合型枚举问题,我们也可以用到剪枝来优化。可以看出要是剩下的数全都用上也满足不了一共m个数的要求,那么我们直接可以结束这个分支了。即n - start + index < m。
void dfs(int index, int start)
{
if (n - start + index < m) return;//剪枝
if (index > m)//m个位置都处理完了
{
for (int i = 1; i <= m; i++)//输出方案
{
cout << map[i] << " ";
}
cout << endl;
return;
}
//第index个位置可以选择start~n里面的数
for (int i = start; i <= n; i++)
{
map[index] = i;
//处理index+1位置,能选择的最小数是前面选择的数+1
dfs(index + 1, i + 1);
//处理完第index位置放置i这个数的子问题后回溯。
map[index] = 0;
}
}
通过下表我们能看出剪枝之后的运行速度确实快了不少。
想到啥就说啥了,给备战蓝桥杯的小伙伴们提些建议。
我不推荐大家去leetcode上刷题,因为leetcode的形式和蓝桥杯是不太一样的。力扣只需要写函数,输入输出已经内置好了。蓝桥杯的输入输出是需要自己写的。另外呢力扣主要是面向找工作的,题目是面试用的,不是专门打比赛的。因此题目不太适合蓝桥杯竞赛。当然了里面的题目还是很经典的,专门学某一算法是可以刷力扣的。我给大家推荐几个适合的网站还有书籍。
ACwing网站
洛谷
C语言网蓝桥杯题库
蓝桥杯练习系统
蓝桥杯官网题库




这几个网站和书是我一直在用的,真心推荐给大家~
美好的时光总是短暂的,又到了说再见的时候啦~一键三连支持一下吧!

我使用Nokogiri(Rubygem)css搜索寻找某些在我的html里面。看起来Nokogiri的css搜索不喜欢正则表达式。我想切换到Nokogiri的xpath搜索,因为这似乎支持搜索字符串中的正则表达式。如何在xpath搜索中实现下面提到的(伪)css搜索?require'rubygems'require'nokogiri'value=Nokogiri::HTML.parse(ABBlaCD3"HTML_END#my_blockisgivenmy_bl="1"#my_eqcorrespondstothisregexmy_eq="\/[0-9]+\/"#FIXMEThefoll
目录一.加解密算法数字签名对称加密DES(DataEncryptionStandard)3DES(TripleDES)AES(AdvancedEncryptionStandard)RSA加密法DSA(DigitalSignatureAlgorithm)ECC(EllipticCurvesCryptography)非对称加密签名与加密过程非对称加密的应用对称加密与非对称加密的结合二.数字证书图解一.加解密算法加密简单而言就是通过一种算法将明文信息转换成密文信息,信息的的接收方能够通过密钥对密文信息进行解密获得明文信息的过程。根据加解密的密钥是否相同,算法可以分为对称加密、非对称加密、对称加密和非
寻找有用的ruby的好网站是什么? 最佳答案 AgileWebDevelopment列出插件(虽然不是rubygems,我不确定为什么),并允许人们对它们进行评级。RubyToolbox按类别列出gem并比较它们的受欢迎程度。Rubygems有一个搜索框。StackOverflow对最有用的rails插件和rubygems有疑问。 关于ruby-如何搜索有用的ruby,我们在StackOverflow上找到一个类似的问题: https://stacko
我有很多这样的文档:foo_1foo_2foo_3bar_1foo_4...我想通过获取foo_[X]的所有实例并将它们中的每一个替换为foo_[X+1]来转换它们。在这个例子中:foo_2foo_3foo_4bar_1foo_5...我可以用gsub和一个block来做到这一点吗?如果不是,最干净的方法是什么?我真的在寻找一个优雅的解决方案,因为我总是可以暴力破解它,但我觉得有一些正则表达式技巧值得学习。 最佳答案 我(完全)不懂Ruby,但类似这样的东西应该可以工作:"foo_1foo_2".gsub(/(foo_)(\d+)/
我读了"BingSearchAPI-QuickStart"但我不知道如何在Ruby中发出这个http请求(Weary)如何在Ruby中翻译“Stream_context_create()”?这是什么意思?"BingSearchAPI-QuickStart"我想使用RubySDK,但我发现那些已被弃用前(Rbing)https://github.com/mikedemers/rbing您知道Bing搜索API的最新包装器(仅限Web的结果)吗? 最佳答案 好吧,经过一个小时的挫折,我想出了一个办法来做到这一点。这段代码很糟糕,因为它是
给定一个元素和一个数组,Ruby#index方法返回元素在数组中的位置。我使用二进制搜索实现了我自己的索引方法,期望我的方法会优于内置方法。令我惊讶的是,内置的在实验中的运行速度大约是我的三倍。有Rubyist知道原因吗? 最佳答案 内置#indexisnotabinarysearch,这只是一个简单的迭代搜索。但是,它是用C而不是Ruby实现的,因此自然可以快几个数量级。 关于Ruby#index方法VS二进制搜索,我们在StackOverflow上找到一个类似的问题:
我有一个表,'jobs'和一个枚举字段'status'。status具有以下枚举集:enumstatus:[:draft,:active,:archived]使用ransack,我如何过滤表,比如说,所有事件记录? 最佳答案 你可以像这样在模型中声明自己的掠夺者:ransacker:status,formatter:proc{|v|statuses[v]}do|parent|parent.table[:status]end然后您可以使用默认的搜索语法_eq来检查相等性,如下所示:Model.ransack(status_eq:'ac
我一直在使用postgres关注railscast的全文搜索,但我不断收到以下错误#的未定义局部变量或方法“作用域”我关注了railscast确切地。我安装了所有正确的gem。(pg_search,pg)。这是我的代码文章Controller(我在这里也使用acts_as_taggable)defindex@articles=Article.text_search(params[:query]).page(params[:page]).per_page(3)ifparams[:tag]@articles=Article.tagged_with(params[:tag])else@art
我想使用部分字符串搜索数组,然后获取找到该字符串的索引。例如:a=["Thisisline1","Wehaveline2here","andfinallyline3","potato"]a.index("potato")#thisreturns3a.index("Wehave")#thisreturnsnil使用a.grep将返回完整的字符串,使用a.any?将返回正确的true/false语句,但都不会返回匹配的索引找到了,或者至少我不知道该怎么做。我正在编写一段代码,该代码读取文件、查找特定header,然后返回该header的索引,以便它可以将其用作future搜索的偏移量。如果
1.问题描述使用Python的turtle(海龟绘图)模块提供的函数绘制直线。2.问题分析一幅复杂的图形通常都可以由点、直线、三角形、矩形、平行四边形、圆、椭圆和圆弧等基本图形组成。其中的三角形、矩形、平行四边形又可以由直线组成,而直线又是由两个点确定的。我们使用Python的turtle模块所提供的函数来绘制直线。在使用之前我们先介绍一下turtle模块的相关知识点。turtle模块提供面向对象和面向过程两种形式的海龟绘图基本组件。面向对象的接口类如下:1)TurtleScreen类:定义图形窗口作为绘图海龟的运动场。它的构造器需要一个tkinter.Canvas或ScrolledCanva
