数据库重构和维护
数据库安全性、完整性控制等
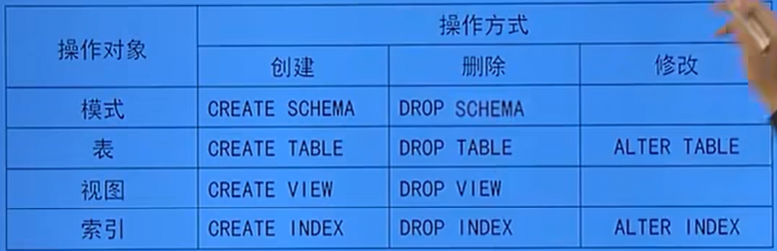
| SQL功能 | 动词 |
| 数据查询 | SELECT |
| 数据定义 | CREATE、DROP、ALTER |
| 数据操纵 | INSERT、UPDATE、DELETE |
| 数据控制 | GRANT、REVOKE |

删除模式的同时把该模式中所有的数据库对象全部删除
RESTRICT(限制)
如果该模式中定义了下属的数据库对象(如表、视图等),则拒绝该删除语句的执行
例子:DROP SCHEMA ZHANG CASCADE;
删除模式ZHANG,同时该模式中定义的表也被删除
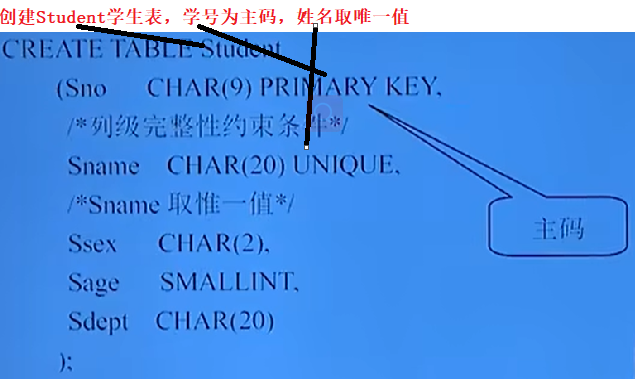
CREATE TABLE <表名>
( <列名> <数据类型> [<列级完整性约束条件>],
<列名> <数据类型> [<列级完整性约束条件>],
[<表级完整性约束条件>]);


数据类型:


字符串类型:
枚举类型:
枚举类型英文为ENUM,对1~255个成员的枚举需要1个字节存储;对于255 ~ 65535个成员,需要2个字节存储。最多允许65535个成员。创建方式:enum(“M”,“F”);
日期类型: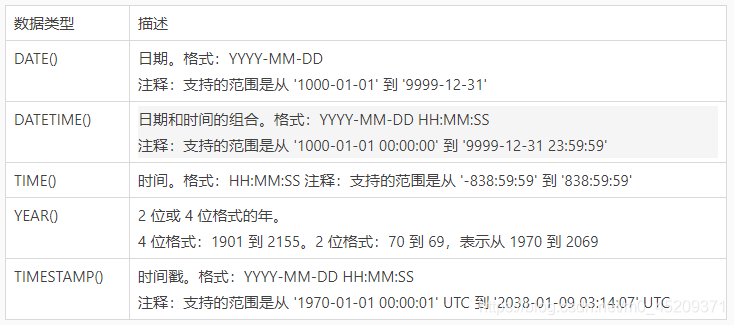
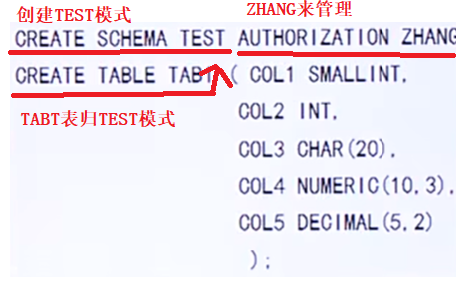
理解:买工具回来放到S-T房间,如果没有S-T房间就放到PUBLIC房间中去
若搜索路径的模式名都不存在,系统将给出错误
若搜索路径中的存在模式,ROMBS还使用模式列表中第一个存在的模式作为数据库对象的模式名
理解:我设置了多个模式名,使用的时候用第一个,如果不存在在找第二个
3.设置所属模式,在创建表中不必给出模式名(就是设置它的搜索路径)

修改基本表:
语法:

例子:

删除基本表:
语法:DROP TABLE <表名>[RESTRICT| CASCADE];
RESTRICT:删除表是有限制的,欲删除的基本表不能被其他表的约束所引用
如果存在依赖该表的对象,则此表不能被删除
CASCADE:删除该表没有限制。
在删除基本表的同时,相关的依赖对象一起删除
例子:

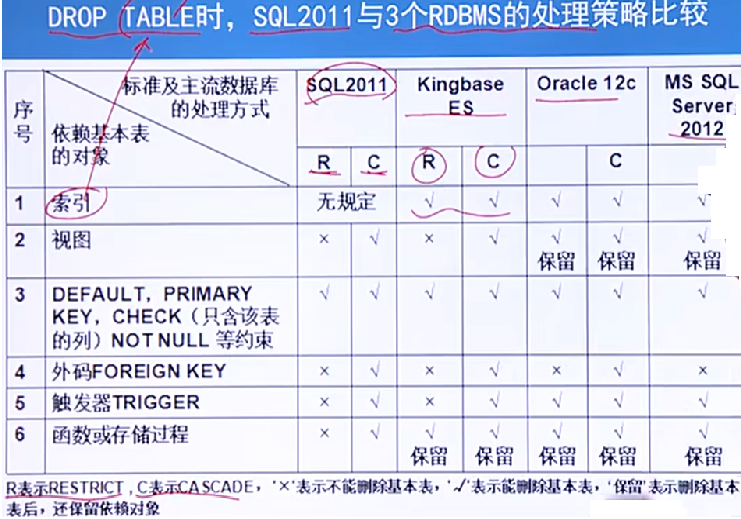
不同数据库处理的策略:
建立索引的目的:加速查询速度
谁可以建立索引:DBA或表的属主(建表人)
DMBS一般会自动建立以下列上的索引(相当于有下面关键字的自动加到目录):
PRIMARY KEY;
UNIQUE;
谁维护索引:DMBS自动完成
使用索引:DMBS自动执行是否使用索引及使用哪些索引
R(R表示关系数据库)DBMS中索引一般采用B+树、HASH索引来实现
B+树索引具有动态平衡的优点
HASH索引具有查找速度快的特点
采用B+树,还是HASH索引 则由具体的RDBMS来决定
索引是关系数据库的内部实现技术,属于内模式的范畴
CREATE INDEX 语句定义索引时,可以定义索引是唯一索引、非唯一索引(如:年龄,年龄可能就是会重复)或聚簇索引
建立索引:
语句:CREATE [UNIQUE(唯一索引)] [CLUSTER(聚簇索引)] INDEX <索引名>
ON <表名>(<列名>[<次序>][,<列名>[<次序>] ]…); - 不写大括号里面的索引,就是非唯一索引

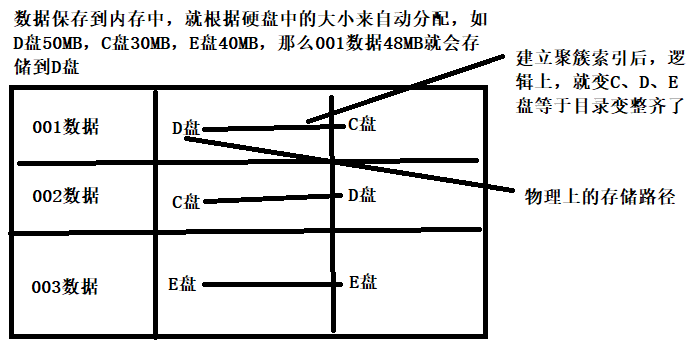
建立聚簇索引例子:

/*
SELECT - 查询
all - 显示所有
distinct - 显示不同的(去重)
from - 去哪个表查
where - 条件
group by - 分组
order by - 排序
*/
SELECT [ALL | DISTINCT ]<目标列表达式>[,<目标列表达式>]...
FROM<表名或视图名>[,<表名或视图名>...] | (<SELECT语句>)[AS]<别名>
[WHERE<条件表达式>]
[GROUP BY<列名1>[HAVING<条件表达式>]]
[ORDER BY<列名2>[ASC | DESC]]/*
查询全体学生的学号和姓名
*/
SELECT son,sname FROM Student;查询表中全部列:
/*
查询全体学生的详细记录
*/
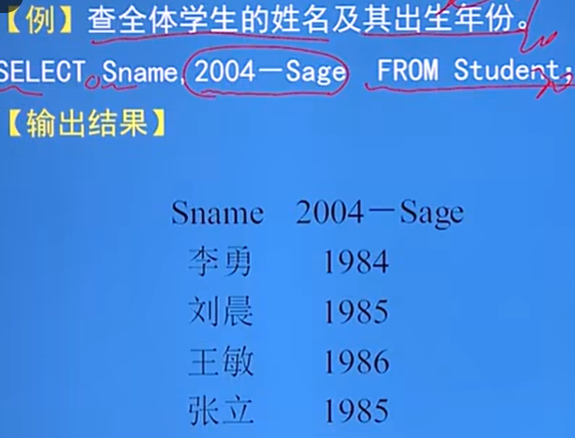
SELECT * FROM Student;选择经过计算的值:
作用:选出表中指定的属性列,经过计算后输出
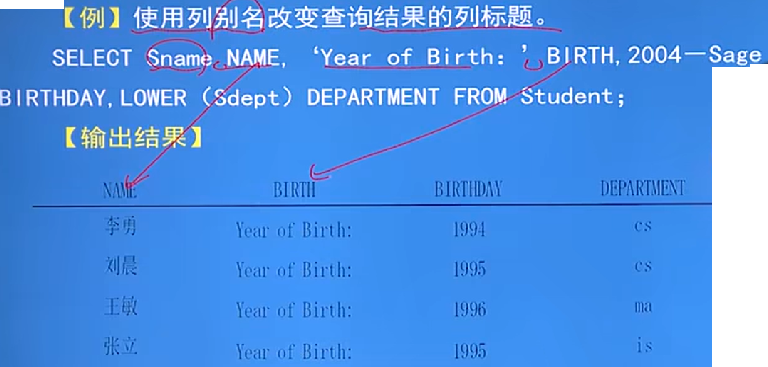
格式:SELECT字语句的<目标列表达式>可以为:算数表达式、字符串常量、函数、列别名
例: 注意表格的名字

例:别名的使用
选择表中的若干元组:
消除取值重复的行(去重):
两个关键字:DISTINCT(显示去重后的)和ALL(显示所有),不写关键字默认是ALL
例:

查询满足条件的元组:
通过关键字where子句实现
| 操作符 | 说 明 |
| = | 等于 |
| <> | 不等于 |
| != | 不等于 |
| < | 小于 |
| <= | 小于等于 |
| !< | 不小于 |
| > | 大于 |
| >= | 大于等于 |
| !> | 不大于 |
| BETWEEN , NOT BETWEEN | 在指定的两个值之间 ,不在指定访问的值 |
| IS NULL, IS NOT NILL |
为NULL的值, 不为NULL的值 |
| AND,OR,NOT |
并且 ,或者,反;不是 |
例子:比较大小

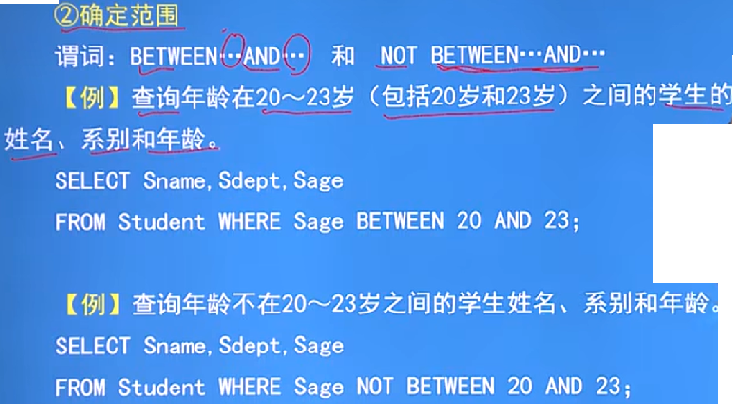
例子:确定范围
例子:确定集合


例子:匹配串为含通配符的字符串
%表示任意长度的字符串
_ ,下斜线表示任意单个字符

例子:使用换码字符串将通配符转义为普通字符
ESCAPE '<换码字符>' - 如:查询的字符串中有& _ 这些特殊字符时,可以通过转码让它转为字符

例子:涉及空值的查询
IS NULL或IS NOT NULL, "IS" 不能用“=”代替

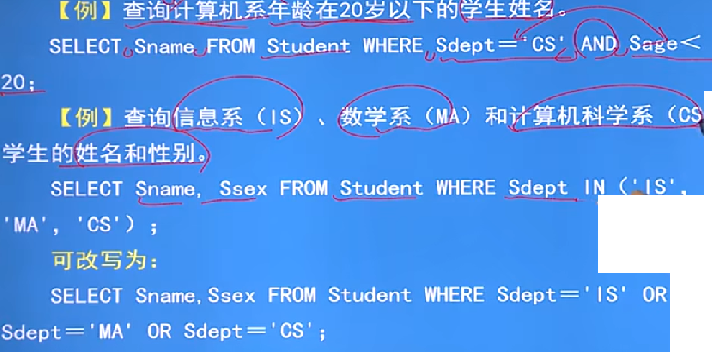
例子:多重条件查询
AND和OR来联结多个查询条件,AND的优先级高于OR,可以用括号来改变优先级
有时候可以用:[NOT] IN 或 [NOT] BETWEEN ... AND ...
例子:ORDER BY子句(排序)
ORDER BY 子句可以按一个或多个属性列排序
升序:ASC; 降序:DESC; - 默认是升序
空值默认是最大值
ASC:排序列为空值的元组最后显示
DESC:排序列为空值的元组最先显示

聚集函数

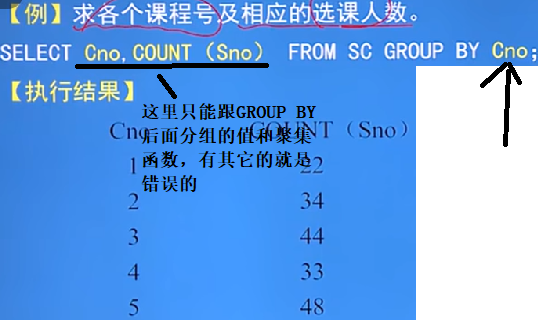
GRIOUP BY子句(分组)
GRIOUP BY子句作用:按指定的一列或多列值分组,值相等的为一组,来细化聚集函数的作用对象
细节:
未对查询结果分组,聚集函数将作用于整个查询结果
对查询结果分组,聚集函数将分别作用于每个组
语
HAVING语句
GROUP BY子句分组后,可以使用HAVING语句指定筛选条件
细节:
HAVING是和GROUP BY语句连在一起的,作用在分组对象中

HAVING短句与WHERE子句的区别
HAVING是和GROUP BY语句连在一起的,作用在分组对象中
WHERE是作用在整个查询对象中
作用对象不同:WHERE子句作用于基表或视图,从中选择满足条件的元组。HAVING短语作用于组,从中选择满足条件的元组
WHERE子句中是不能用聚集函数作为条件表达式的

等值连接:当连接运算符为=时,称为等值连接
非等值连接:所以非=符号时,称为非等值连接
细节:
连接谓词中的列名称为连接字段,并且各连接字段必须是可比的,但名字不必相同
例:
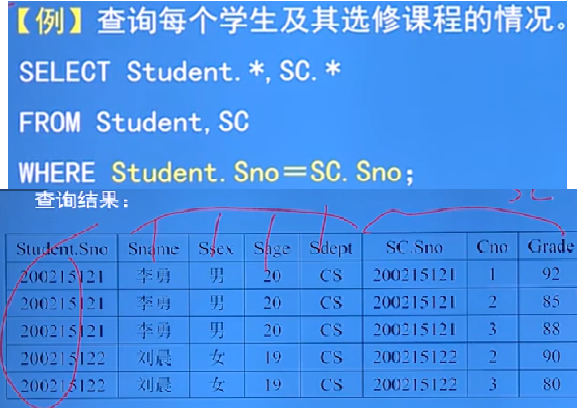
以此类推,拼接得到的表不是真实存在的,随着查询的结束而结束

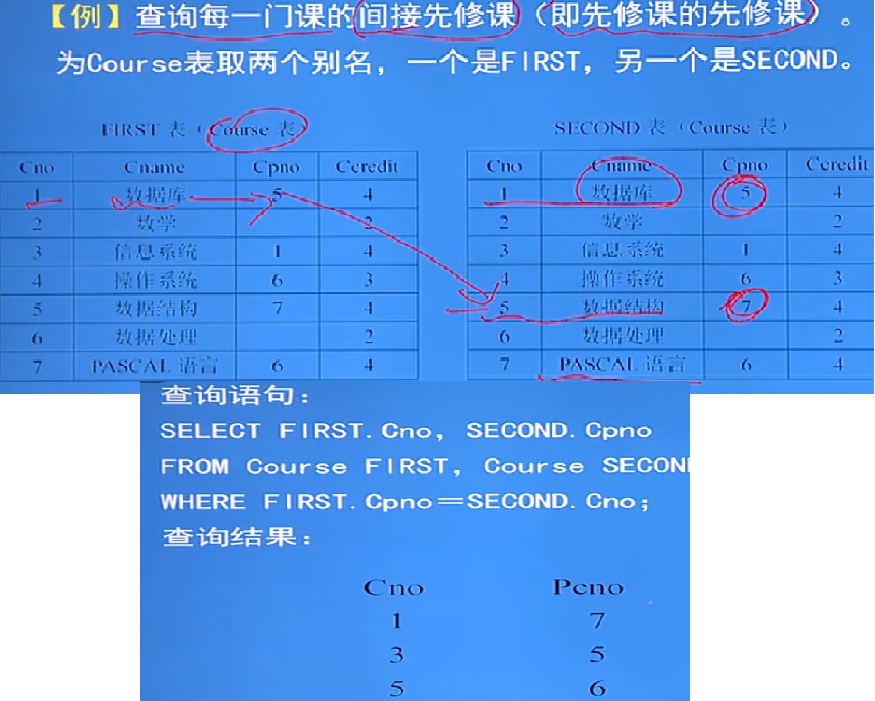
多表连接:
连接操作是流量以上的表进行连接
例: - 下面用到了三个表

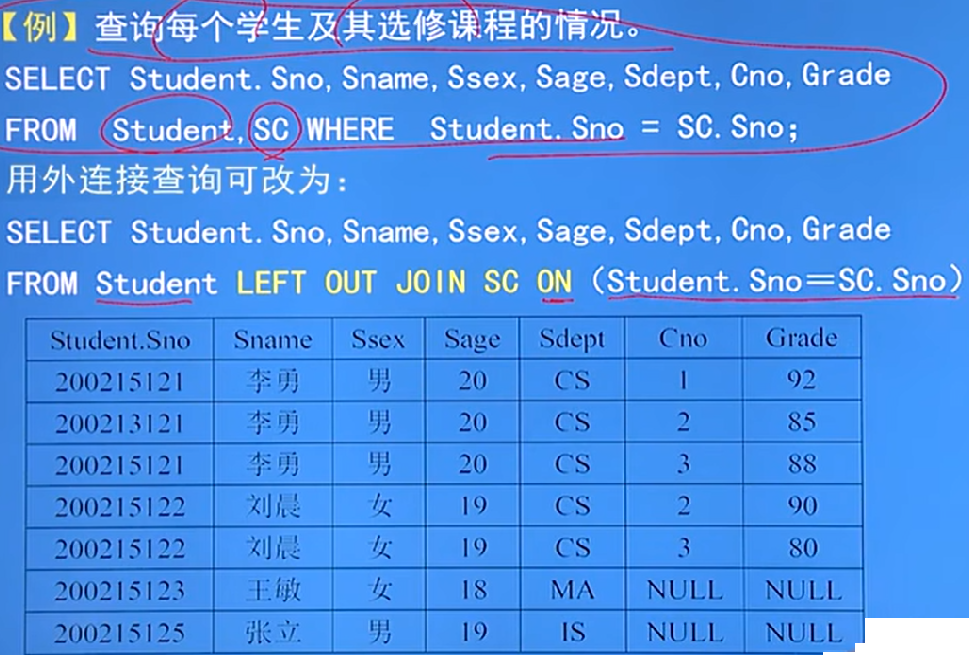
一个SELECT-FROM-WHERE语句陈为一个查询块
嵌套查询定义:是指将一个查询块嵌套在另一个查询块的WHERE子句或HAVING短语的条件中的查询
理解:就是将新的查询语句嵌套在已有的查询语句中的WHERE或HAVLNG中,其它地方不能嵌套
细节;
子查询中不能使用ORDER BY子句
层层嵌套方式反映来哦SQL语言的结构化
有些嵌套查询可以用连接运算代替
外层查询叫:父查询,内层查询叫:子查询
父查询里面嵌套子查询,子程序里面还可以嵌套子查询
不相关子查询:子查询的查询条件不依赖父查询(看案例)
相关子查询:子查询的查询条件依赖于父查询,整个语句称为嵌套查询(看案例)
例:

带有IN谓词的子程查询:


例子2:

带有比较运算符的子查询:
当确切知道内层返回的是单个值时,可以用 >、<、=、>=、<=、!=或<>等运算符
例1:

例2:
例子执行流程:1.x表的第一个Son和y表的每一个Son进行比较,和x的Son一样的就进行表拼接,依此类推
2.得到拼接的表,然后通过函数AVG去求X的Son和y的Son拼接表的平均成绩,和X表的成绩进行比较,大于就显示学号

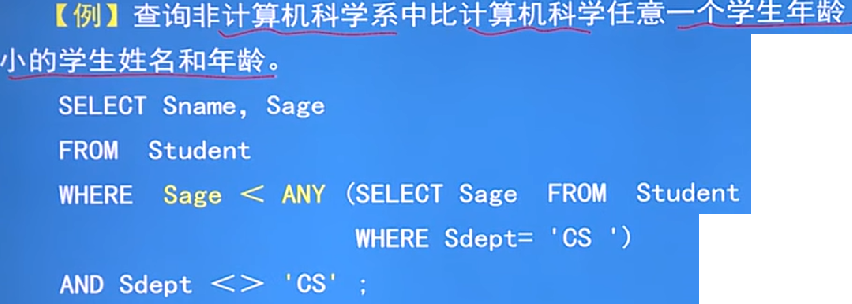
带有ANY(SOME不同的系统可能使用这个)或ALL谓词的子查询:
ANY - - 任意一个值
ALL - - 所以值
ANY和ALL需要配合比较运算符使用

例子: - 执行过程 :先执行子查询,找出计算机科学的的所有人年龄得到一个集合(xx,xx),然后执行父查询不是计算机系的年龄,然后和子程查询的集合比较


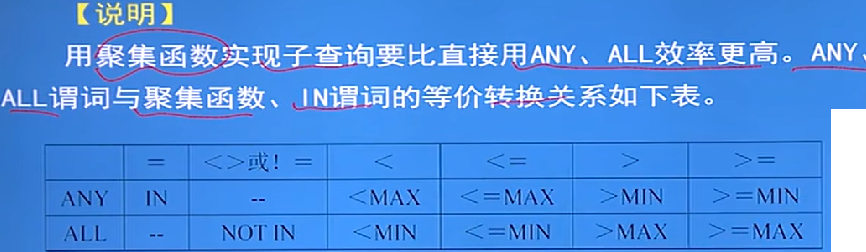
细节: - =ANY等价于IN谓词,<ANY等价于<MAX,<>ALL等价于NOT IN谓词,<ALL等价于<MIN,等等
带有EXISTS谓词的子查询:
EXISTS谓词:代表存在量词∃,带有EXUISTS谓词的子查询,不返回任何数据,只产生逻辑真值"true",或逻辑假值"false"
存在量词:存在,有些,有一个,至少有一个,存在一个,对某一个,对有些,对某些,有的等
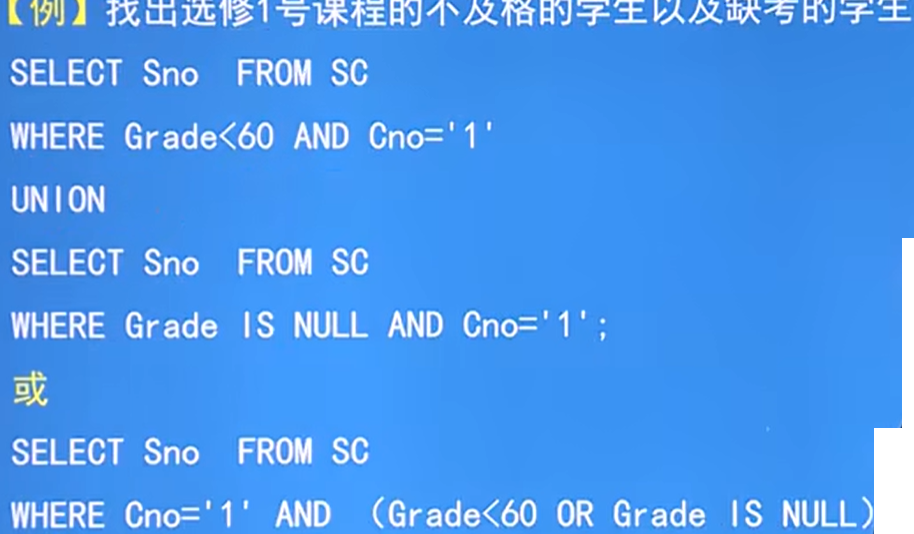
例:查询所有选修了1号课程的学生姓名
思路:需要Student和SC表,通过Student中Son去确定SC中选了课的学生的Sno,并且通过条件AND判断,课程号为1的
细节1:所有存在量词EXISTS后,如若内层查询结果非空,则外层的WHERE子句返回真值,否则返回假值
细节2:由EXISTS引出的子查询,select后通过用*,因为EXISTS返回的只有真和假,用列名没有意义

NOT EXISTS谓词的子查询:
若内查询结果非空,外层WHERE子句返回假值
若内查询结果为空,外层WHERE子句返回真值
例子:思路:内层查询,查询出所有选择了1号课程的学生,通过NOT EXISTS返回没选择的学生就是真

不同形式的查询间的替换:
一些带EXISTS或NOT EXISTS谓词的子程序不能本其他形式的子程序等价替换
所有带IN谓词、比较运算符、ANY和ALL谓词的子查询都能用带EXISTS谓词的子程序等价替换
理解:如IN和ALL的目的就是表达查询结果集里面所有的值,那EXISTS表示真假,就可以完美代替
例:思路:内查询S2表想S1表进行自身连接查询,当S2中的系和S1中的系对应上,并且S2表中的名字是刘晨,返回真(不理解画图)

用EXISTS/NOT EXISTS实现全称量词:
全称量词:一切、每一个、任意
SQL语言中是没有全称量词语的,但可以通过存在量词转为全称量词
例:

用EXISTS/NOT EXISTS实现逻辑蕴涵:
逻辑蕴涵:我来过北京代表我来过中国,我来过中国不代表去过北京



交操作例子:


差操作例子:

在from语句中,成为主存在的子查询叫派生表



语句:UPDATE <表名> SET <列名>=<表达式>[,<列名>=<表达式> ]...[ WHERE < 条件 > ];
功能:修改指定表中满足WHERE子句条件的元组
细节:
SET子句:指定修改方式,修改的列,修改后取值
WHERE子句:指定修改的元组,缺省表示修改所有元组
在执行修改语句时会检查修改操作是否破坏表上已定的完整性规则(如Student,Sc表的学号)
将一个元组或多个元组修改:

带子查询的修改语句:

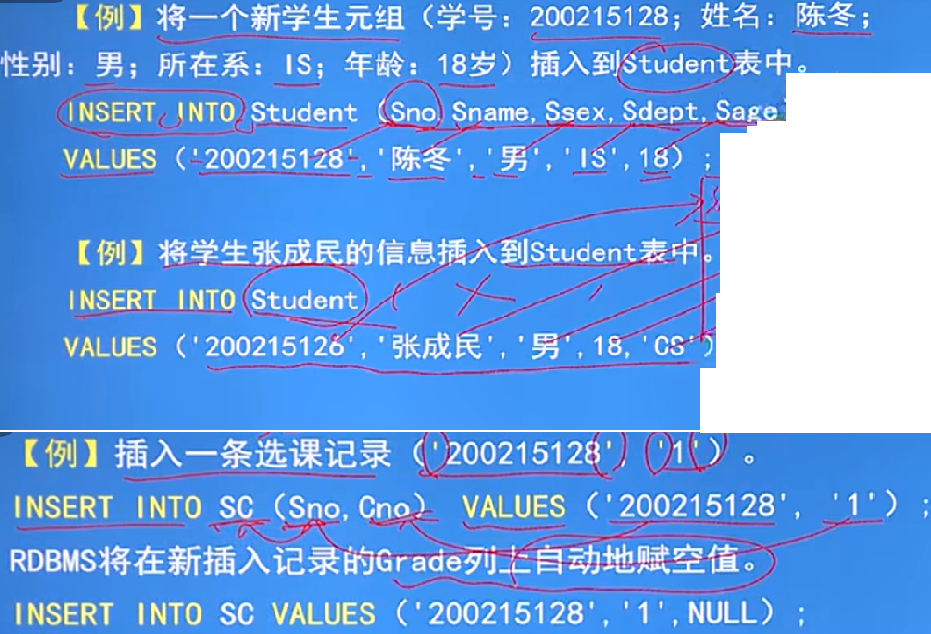
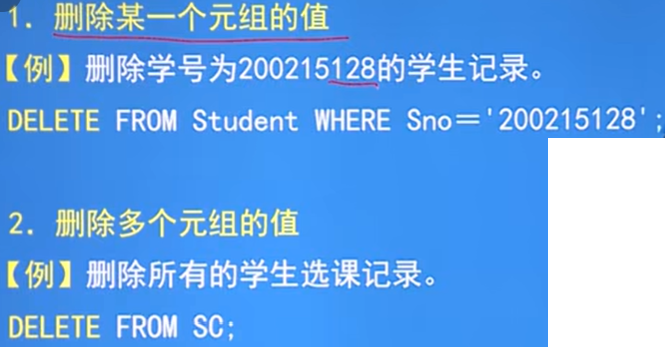
语句:DELETE FROM <表名> [ WHERE <条件> ];
功能:删除指定表中满足WHERE子句条件的元组
细节:
WHERE子句:指定删除的元组,缺省WHERE子句表示删除表中全部元组,但定义仍在
删除一个或多个元组的值:
带子查询的删除语句:


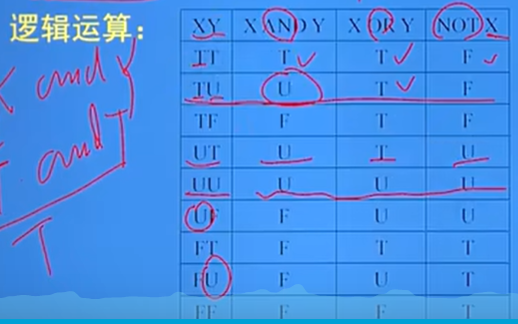
空值的算数运算、比较运算和逻辑运算:
算术运算:空值与一个值(包括另一个空值)的算术的结果为空值
理解:空值和其他值的算术运算(加减乘除)结果都为空
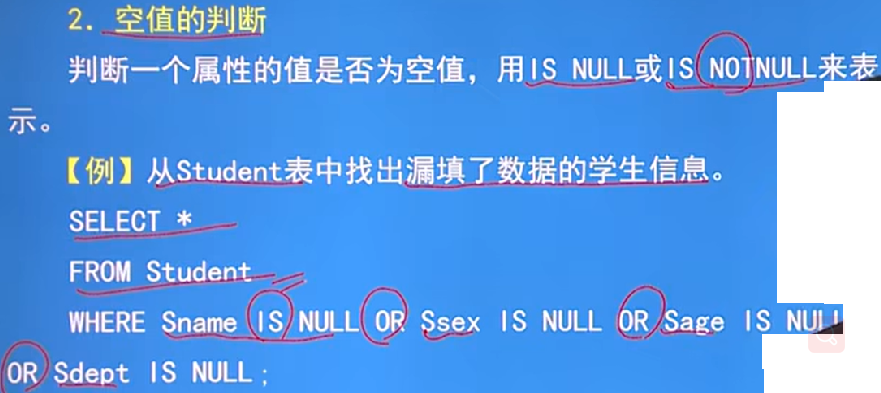
比较运算:空值与另一个值(包括另一个空值)的比较运算结果为UNKNOWN(未知数);
例子:


例子(基于多个表):

例子(基于视图的视图):

例子(带表达式的视图):

例子(分组视图):

例子(不指定属性列):
细节:本例中如修改基本表Student的结构后,Student与视图F_Student视图的映像关系被破坏,导致该视图不能正确工作

语句:DROP VIEW <视图名> [ CASCADE(级联) ];
细节:
该语句从数据字典中删除指定的视图定义
如果该视图还导出了其它视图(如:由视图创建出一个新的视图),使用CASCADE级联删除语句,把该语句和由他导出的所有视图一起删除
删除基本表时,由该基本表导出的所有视图定义都必须显式的使用DEOR VIEW语句删除(因为删除了基本表,但视图还是在的)
例子:


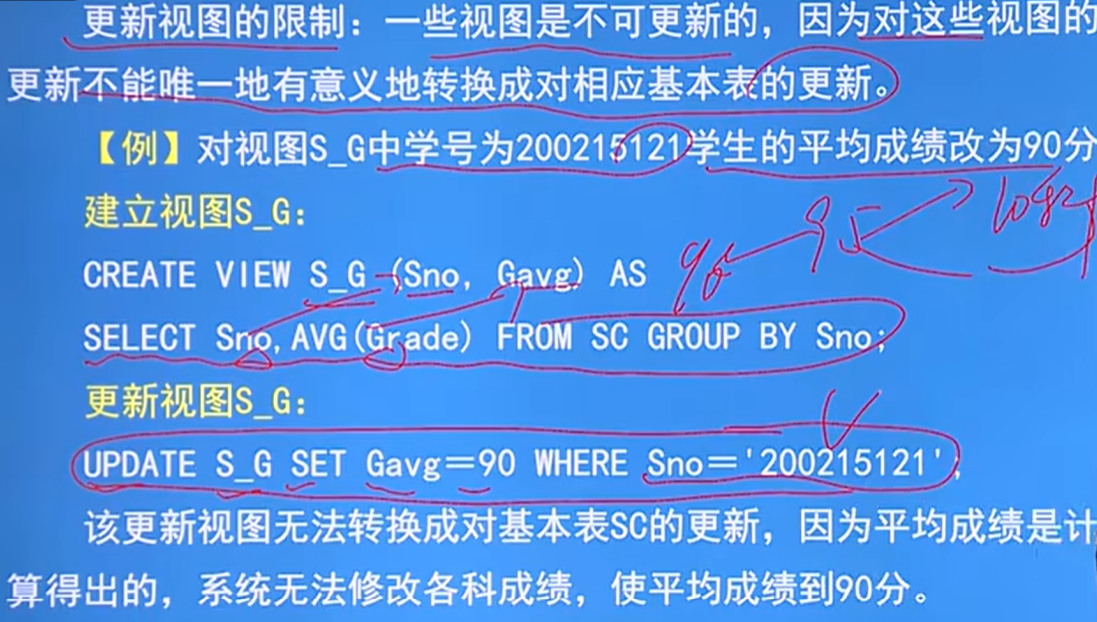
视图消解法的局限:

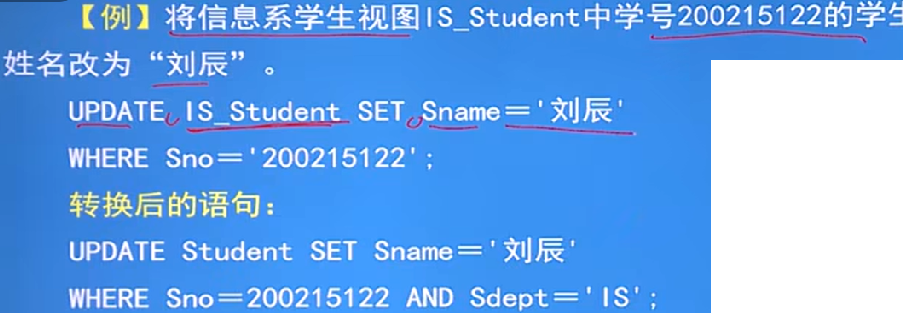
更新视图是指通过视图来插入、删除和修改数据,由于视图是不实际存储数据的虚表,因此对视图的更新最终要转换为对基本表的更新
细节:为防止在更新视图时出错,定义视图时要加上WITH CHECK OPTION子句
例子1(修改数据):
例子2(插入数据):

例子3(删除数据):

更新视图的限制:一些视图是不可以更新的,因为对这些视图的更新不能唯一的有意义的转换成对应基本表的更新
视图能够简化用户的操作
视图使用用户能以多种角度看待同一数据
视图对重构数据库提供了一定程度的逻辑独立性
如:就是基本表和视图是映射关系,基本表变视图就会变
视图能够对机密数据提供安全保护
适当的利用视图可以更清晰的表达查询
如:可以省略一些查询条件判断

我注意到类定义,如果我打开classMyClass,并在不覆盖的情况下添加一些东西我仍然得到了之前定义的原始方法。添加的新语句扩充了现有语句。但是对于方法定义,我仍然想要与类定义相同的行为,但是当我打开defmy_method时似乎,def中的现有语句和end被覆盖了,我需要重写一遍。那么有什么方法可以使方法定义的行为与定义相同,类似于super,但不一定是子类? 最佳答案 我想您正在寻找alias_method:classAalias_method:old_func,:funcdeffuncold_func#similartoca
我想使用spawn(针对多个并发子进程)在Ruby中执行一个外部进程,并将标准输出或标准错误收集到一个字符串中,其方式类似于使用Python的子进程Popen.communicate()可以完成的操作。我尝试将:out/:err重定向到一个新的StringIO对象,但这会生成一个ArgumentError,并且临时重新定义$stdxxx会混淆子进程的输出。 最佳答案 如果你不喜欢popen,这是我的方法:r,w=IO.pipepid=Process.spawn(command,:out=>w,:err=>[:child,:out])
我正在尝试找到一种方法来规范化字符串以将其作为文件名传递。到目前为止我有这个:my_string.mb_chars.normalize(:kd).gsub(/[^\x00-\x7F]/n,'').downcase.gsub(/[^a-z]/,'_')但第一个问题:-字符。我猜这个方法还有更多问题。我不控制名称,名称字符串可以有重音符、空格和特殊字符。我想删除所有这些,用相应的字母('é'=>'e')替换重音符号,并将其余的替换为'_'字符。名字是这样的:“Prélèvements-常规”“健康证”...我希望它们像一个没有空格/特殊字符的文件名:“prelevements_routin
目录第1题连续问题分析:解法:第2题分组问题分析:解法:第3题间隔连续问题分析:解法:第4题打折日期交叉问题分析:解法:第5题同时在线问题分析:解法:第1题连续问题如下数据为蚂蚁森林中用户领取的减少碳排放量iddtlowcarbon10012021-12-1212310022021-12-124510012021-12-134310012021-12-134510012021-12-132310022021-12-144510012021-12-1423010022021-12-154510012021-12-1523.......找出连续3天及以上减少碳排放量在100以上的用户分析:遇到这类
我正在尝试查询我的Rails数据库(Postgres)中的购买表,我想查询时间范围。例如,我想知道在所有日期的下午2点到3点之间进行了多少次购买。此表中有一个created_at列,但我不知道如何在不搜索特定日期的情况下完成此操作。我试过:Purchases.where("created_atBETWEEN?and?",Time.now-1.hour,Time.now)但这最终只会搜索今天与那些时间的日期。 最佳答案 您需要使用PostgreSQL'sdate_part/extractfunction从created_at中提取小时
在添加一些空格以使代码更具可读性时(与上面的代码对齐),我遇到了这个:classCdefx42endendm=C.new现在这将给出“错误数量的参数”:m.x*m.x这将给出“语法错误,意外的tSTAR,期待$end”:2/m.x*m.x这里的解析器到底发生了什么?我使用Ruby1.9.2和2.1.5进行了测试。 最佳答案 *用于运算符(42*42)和参数解包(myfun*[42,42])。当你这样做时:m.x*m.x2/m.x*m.xRuby将此解释为参数解包,而不是*运算符(即乘法)。如果您不熟悉它,参数解包(有时也称为“spl
我想从then子句中访问case语句表达式,即food="cheese"casefoodwhen"dip"then"carrotsticks"when"cheese"then"#{expr}crackers"else"mayo"end在这种情况下,expr是食物的当前值(value)。在这种情况下,我知道,我可以简单地访问变量food,但是在某些情况下,该值可能无法再访问(array.shift等)。除了将expr移出到局部变量然后访问它之外,是否有直接访问caseexpr值的方法?罗亚附注我知道这个具体示例很简单,只是一个示例场景。 最佳答案
如何在Ruby的if语句中检查bash命令的返回值(true/false)。我想要这样的东西,if("/usr/bin/fswscell>/dev/null2>&1")has_afs="true"elsehas_afs="false"end它会提示以下错误含义,它总是返回true。(irb):5:warning:stringliteralincondition正确的语法是什么?更新:/usr/bin/fswscell寻找afs安装和运行状态。它会抛出这样的字符串,Thisworkstationbelongstocell如果afs没有运行,命令以状态1退出 最
我最近与一位同事讨论了以下Ruby语法:value=ifa==0"foo"elsifa>42"bar"else"fizz"end我个人并没有看到太多这种逻辑,但我的同事指出,这实际上是一种相当普遍的Rubyism。我试着用谷歌搜索这个主题,但没有找到任何文章、页面或SO问题来讨论它,这让我相信这可能是一种非常实际的技术。然而,另一位同事发现语法令人困惑,而是将上面的逻辑写成这样:ifa==0value="foo"elsifa>42value="bar"elsevalue="fizz"end缺点是value=的重复声明和隐式elsenil的丢失,如果我们想使用它的话。这也感觉它与Ruby
我经常迷上ruby的一件事是递归模式。例如,假设我有一个数组,它可能包含无限深度的数组作为元素。所以,例如:my_array=[1,[2,3,[4,5,[6,7]]]]我想创建一个方法,可以将数组展平为[1,2,3,4,5,6,7]。我知道.flatten可以完成这项工作,但这个问题是作为我经常遇到的递归问题的一个例子-因此我试图找到一个更可重用的解决方案。简而言之-我猜这种事情有一个标准模式,但我想不出任何特别优雅的东西。任何想法表示赞赏 最佳答案 递归是一种方法,它不依赖于语言。您在编写算法时要考虑两种情况:再次调用函数的情