一般来说,前端根据后台返回 code 码展示对应内容只需要在前台判断 code 值展示对应的内容即可,但要是匹配的 code 码比较多或者多个页面用到时,为了便于后期维护,后台就会使用字典表让前端匹配,下面我将在微信小程序中通过 wxs 的方法实现这个操作。
{{method(a,b)}}
可以看到,上述代码是一个调用方法传值的操作,在 vue 中很常见,多用于数据之间的转换,但由于微信小程序诸多限制的原因,你并不能优雅的这样操作,可能有人会说,为什么不用 if 判断实现呢?但是 if 判断的局限性在于如果存在数据量过大时,大量重复性操作和 if 判断会让你的代码显得异常冗余。
wxs
wxs 相当于是一个独立模块,通过独立出来的一个 module 对象,利用 module.exports 向外暴露,在使用文件中引入即可。其主要解决了微信小程序中 {{method(a,b)}} 方法传值不触发的问题,避免了多次 if 判断,利于代码的优化,提高了代码的复用性和后期可维护性。简单来说, wxs 就是可以在 wxml 里面使用 js ,从而对数据进行计算转换。
上面我们说到,wxs 多用于微信小程序页面调用方法传值不触发的问题,下面我们就用一个简单的小实例来展示在代码中 wxs 的具体用法。
external/index.wxs 封装的公共文件代码
通过全局封装的形式以达到在每一个 wxml 文件中都可以调用。
var qxCode = function (optionsQx, dqbm) {
var targetItem = {};
//非空判断是为了避免循环的数组为null而产生报错
if (optionsQx) {
//通过区县编码过滤获取所属对象
for (var i = 0; i < optionsQx.length; i++) {
var code = optionsQx[i].regionCode
if (code == dqbm) {
targetItem = optionsQx[i]
}
}
}
// 有数据时正常展示数据反之展示 “--”
return targetItem.regionName ? targetItem.regionName : '--'
}
// 将方法抛出
module.exports = {
qxCode: qxCode,
};
wxml 文件代码
在 wxml 文件中用到时,通过 <wxs src="路径" module="方法" /> 的方式引入调用。
<!-- 引入封装文件 -->
<wxs src="../external/index.wxs" module="onitceModel" />
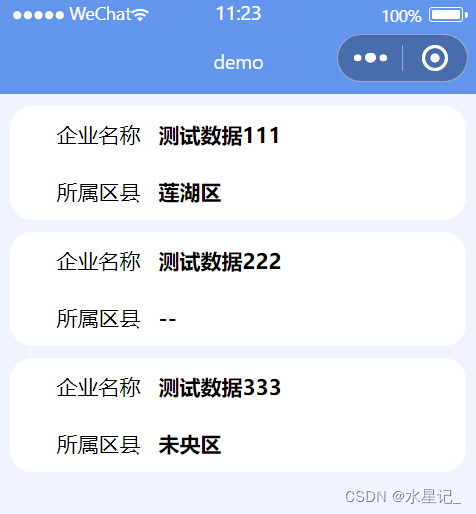
<view class="dataListBox" wx:for="{{dataList}}" wx:key="index">
<view>
<text class="lableBox">企业名称</text>
<text>{{item.qymc}}</text>
</view>
<view>
<text class="lableBox">所属区县</text>
<text>{{onitceModel.qxCode(optionsQx,item.dqbm)}}</text>
</view>
</view>
js 文件代码
借助 js 中模拟的假数据以还原在真实使用场景下的操作。
Page({
data: {
// 模拟字典表数据
optionsQx: [
{regionCode: "610101",regionName: "市辖区"},
{regionCode: "610102",regionName: "新城区"},
{regionCode: "610103",regionName: "碑林区"},
{regionCode: "610104",regionName: "莲湖区"},
{regionCode: "610111",regionName: "灞桥区"},
{regionCode: "610112",regionName: "未央区"},
{regionCode: "610113",regionName: "雁塔区"},
{regionCode: "610114",regionName: "阎良区"},
{regionCode: "610115",regionName: "临潼区"},
{regionCode: "610116",regionName: "长安区"},
{regionCode: "610122",regionName: "蓝田县"},
{regionCode: "610124",regionName: "周至县"},
{regionCode: "610125",regionName: "户县"},
{regionCode: "610126",regionName: "高陵县"}
],
// 模拟列表数据
dataList: [
{qymc: "测试数据111",dqbm: "610104"},
{qymc: "测试数据222",dqbm: ""},
{qymc: "测试数据333",dqbm: "610112"}
],
},
})
当然,如果你对 vue 中的数据匹配感兴趣,也可以参考博主的另一篇文章 vue查询字典表匹配相应数据
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
尝试通过RVM将RubyGems升级到版本1.8.10并出现此错误:$rvmrubygemslatestRemovingoldRubygemsfiles...Installingrubygems-1.8.10forruby-1.9.2-p180...ERROR:Errorrunning'GEM_PATH="/Users/foo/.rvm/gems/ruby-1.9.2-p180:/Users/foo/.rvm/gems/ruby-1.9.2-p180@global:/Users/foo/.rvm/gems/ruby-1.9.2-p180:/Users/foo/.rvm/gems/rub
我正在使用puppet为ruby程序提供一组常量。我需要提供一组主机名,我的程序将对其进行迭代。在我之前使用的bash脚本中,我只是将它作为一个puppet变量hosts=>"host1,host2"我将其提供给bash脚本作为HOSTS=显然这对ruby不太适用——我需要它的格式hosts=["host1","host2"]自从phosts和putsmy_array.inspect提供输出["host1","host2"]我希望使用其中之一。不幸的是,我终其一生都无法弄清楚如何让它发挥作用。我尝试了以下各项:我发现某处他们指出我需要在函数调用前放置“function_”……这
在我的应用程序中,我需要能够找到所有数字子字符串,然后扫描每个子字符串,找到第一个匹配范围(例如5到15之间)的子字符串,并将该实例替换为另一个字符串“X”。我的测试字符串s="1foo100bar10gee1"我的初始模式是1个或多个数字的任何字符串,例如,re=Regexp.new(/\d+/)matches=s.scan(re)给出["1","100","10","1"]如果我想用“X”替换第N个匹配项,并且只替换第N个匹配项,我该怎么做?例如,如果我想替换第三个匹配项“10”(匹配项[2]),我不能只说s[matches[2]]="X"因为它做了两次替换“1fooX0barXg
如何匹配未被反斜杠转义的平衡定界符对(其本身未被反斜杠转义)(无需考虑嵌套)?例如对于反引号,我试过了,但是转义的反引号没有像转义那样工作。regex=/(?!$1:"how\\"#expected"how\\`are"上面的正则表达式不考虑由反斜杠转义并位于反引号前面的反斜杠,但我愿意考虑。StackOverflow如何做到这一点?这样做的目的并不复杂。我有文档文本,其中包括内联代码的反引号,就像StackOverflow一样,我想在HTML文件中显示它,内联代码用一些spanMaterial装饰。不会有嵌套,但转义反引号或转义反斜杠可能出现在任何地方。
我正在编写一个gem,我必须在其中fork两个启动两个webrick服务器的进程。我想通过基类的类方法启动这个服务器,因为应该只有这两个服务器在运行,而不是多个。在运行时,我想调用这两个服务器上的一些方法来更改变量。我的问题是,我无法通过基类的类方法访问fork的实例变量。此外,我不能在我的基类中使用线程,因为在幕后我正在使用另一个不是线程安全的库。所以我必须将每个服务器派生到它自己的进程。我用类变量试过了,比如@@server。但是当我试图通过基类访问这个变量时,它是nil。我读到在Ruby中不可能在分支之间共享类变量,对吗?那么,还有其他解决办法吗?我考虑过使用单例,但我不确定这是
我的最终目标是安装当前版本的RubyonRails。我在OSXMountainLion上运行。到目前为止,这是我的过程:已安装的RVM$\curl-Lhttps://get.rvm.io|bash-sstable检查已知(我假设已批准)安装$rvmlistknown我看到当前的稳定版本可用[ruby-]2.0.0[-p247]输入命令安装$rvminstall2.0.0-p247注意:我也试过这些安装命令$rvminstallruby-2.0.0-p247$rvminstallruby=2.0.0-p247我很快就无处可去了。结果:$rvminstall2.0.0-p247Search
我在理解Enumerator.new方法的工作原理时遇到了一些困难。假设文档中的示例:fib=Enumerator.newdo|y|a=b=1loopdoy[1,1,2,3,5,8,13,21,34,55]循环中断条件在哪里,它如何知道循环应该迭代多少次(因为它没有任何明确的中断条件并且看起来像无限循环)? 最佳答案 Enumerator使用Fibers在内部。您的示例等效于:require'fiber'fiber=Fiber.newdoa=b=1loopdoFiber.yieldaa,b=b,a+bendend10.times.m
我有一个驼峰式字符串,例如:JustAString。我想按照以下规则形成长度为4的字符串:抓取所有大写字母;如果超过4个大写字母,只保留前4个;如果少于4个大写字母,则将最后大写字母后的字母大写并添加字母,直到长度变为4。以下是可能发生的3种情况:ThisIsMyString将产生TIMS(大写字母);ThisIsOneVeryLongString将产生TIOV(前4个大写字母);MyString将生成MSTR(大写字母+tr大写)。我设法用这个片段解决了前两种情况:str.scan(/[A-Z]/).first(4).join但是,我不太确定如何最好地修改上面的代码片段以处理最后一种
有时我需要处理键/值数据。我不喜欢使用数组,因为它们在大小上没有限制(很容易不小心添加超过2个项目,而且您最终需要稍后验证大小)。此外,0和1的索引变成了魔数(MagicNumber),并且在传达含义方面做得很差(“当我说0时,我的意思是head...”)。散列也不合适,因为可能会不小心添加额外的条目。我写了下面的类来解决这个问题:classPairattr_accessor:head,:taildefinitialize(h,t)@head,@tail=h,tendend它工作得很好并且解决了问题,但我很想知道:Ruby标准库是否已经带有这样一个类? 最佳