Centos7虚拟机一台
jdk1.8
hadoop-3.1.3
附华为开源镜像站下载地址:https://mirrors.huaweicloud.com/java/jdk/
使用root用户登录并创建文件夹
cd /opt
mkdir app
mkdir soft
将下载好的jdk和hadoop安装包上传到虚拟机的/opt/soft目录下
#创建用户组
groupadd hadoop
#创建用户
useradd hadoop
#hadoop用户设置密码
passwd hadoop
#将/opt目录的所有者修改为hadoop,否则没有权限操作
chown -R hadoop:hadoop /opt
#vim /etc/sudoers找到“root ALL=(ALL) ALL”一行,
#在下面插入新的一行,内容是“hadoop ALL=(ALL) ALL”
vim /etc/sudoers
#加入下面的内容
hadoop ALL=(ALL) ALL
使用:wq! 进行保存并退出编辑。必须加!否则编辑不成功。
#切换成hadoop用户
su hadoop
准备好的安装包及安装包位置

后续的环境搭建和操作均在hadoop用户下进行操作
tar -zxvf jdk-8u151-linux-x64.tar.gz -C ../app/
cd ../app
#注意更换为自己jdk的包名称
mv jdk1.8.0_151/ java
vim ~/.bashrc
#加入下面的内容
export JAVA_HOME=/opt/app/java
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
#然后使配置生效
source ~/.bashrc
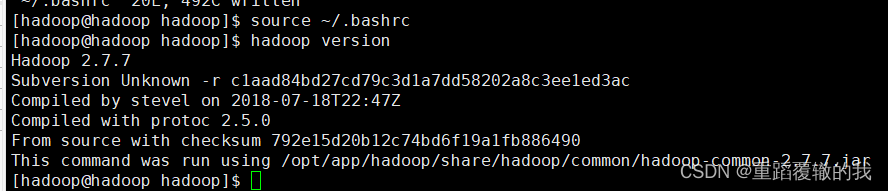
#验证java配置是否生效
java -version
出现下面图片表示安装成功。

cd /opt/soft
tar -zxvf hadoop-2.7.7.tar.gz -C ../app/
#对解压后的包进行重新命名
cd ../app
mv hadoop-2.7.7/ hadoop
配置hadoop的环境变量
#编辑~/.bashrc
vim ~/.bashrc
#添加以下内容
export HADOOP_HOME=/opt/app/hadoop
export PATH=${HADOOP_HOME}/sbin:${HADOOP_HOME}/bin:$PATH
#使环境变量文件生效
source ~/.bashrc
验证环境变量是否设置成功。
#修改虚拟机主机名称
sudo hostnamectl set-hostname hadoop
#查看当前虚拟机名称
hostname
#编辑hosts
sudo vim /etc/hosts

# 执行该命令后遇到提示信息,一直按回车就可以
ssh-keygen -t rsa
# 将你的公共密钥填充到一个远程机器上的authorized_keys文件中
ssh-copy-id hadoop
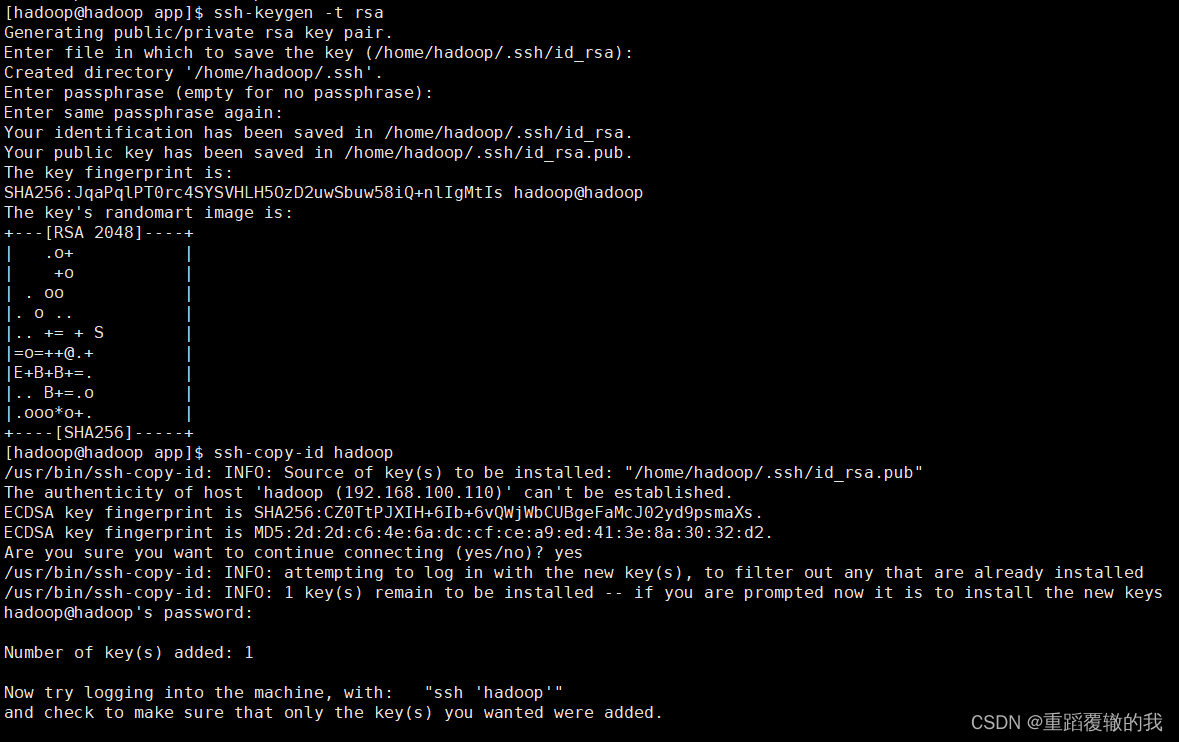
测试ssh是否免密成功
ssh hadoop

cd ./hadoop/etc/hadoop
vim hadoop-env.sh
#在文件中添加或者修改,并保存
export JAVA_HOME=/opt/app/java
vim core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/opt/app/hadoop/tmp</value>
</property>
</configuration>
#注意将ip和路径更换称自己的定义的
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/opt/app/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/opt/app/hadoop/tmp/dfs/data</value>
</property>
</configuration>
#注意将ip和路径更换称自己的定义的
#注意将ip和路径更换称自己的定义的
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop:19888</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/opt/app/hadoop</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/opt/app/hadoop</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/opt/app/hadoop</value>
</property>
</configuration>
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
vim slaves
#修改为
hadoop
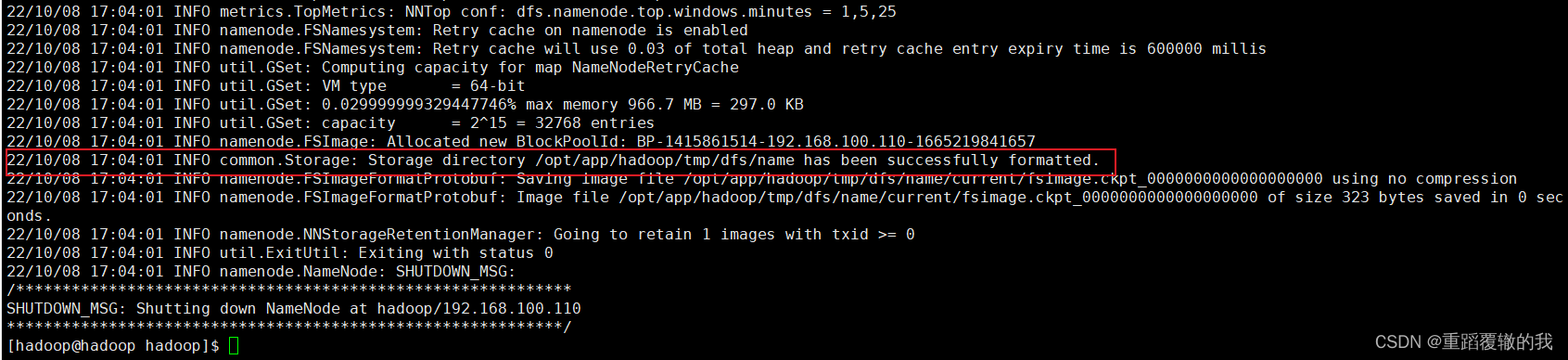
hdfs namenode -format
以下表示格式化成功。
start-all.sh
#或者分别启动hdfs和yarn
start-dfs.sh
start-yarn.sh
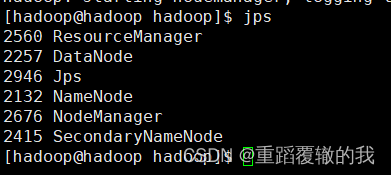
jps进行验证是否启动成功,出现以下5个进程表示启动成功。
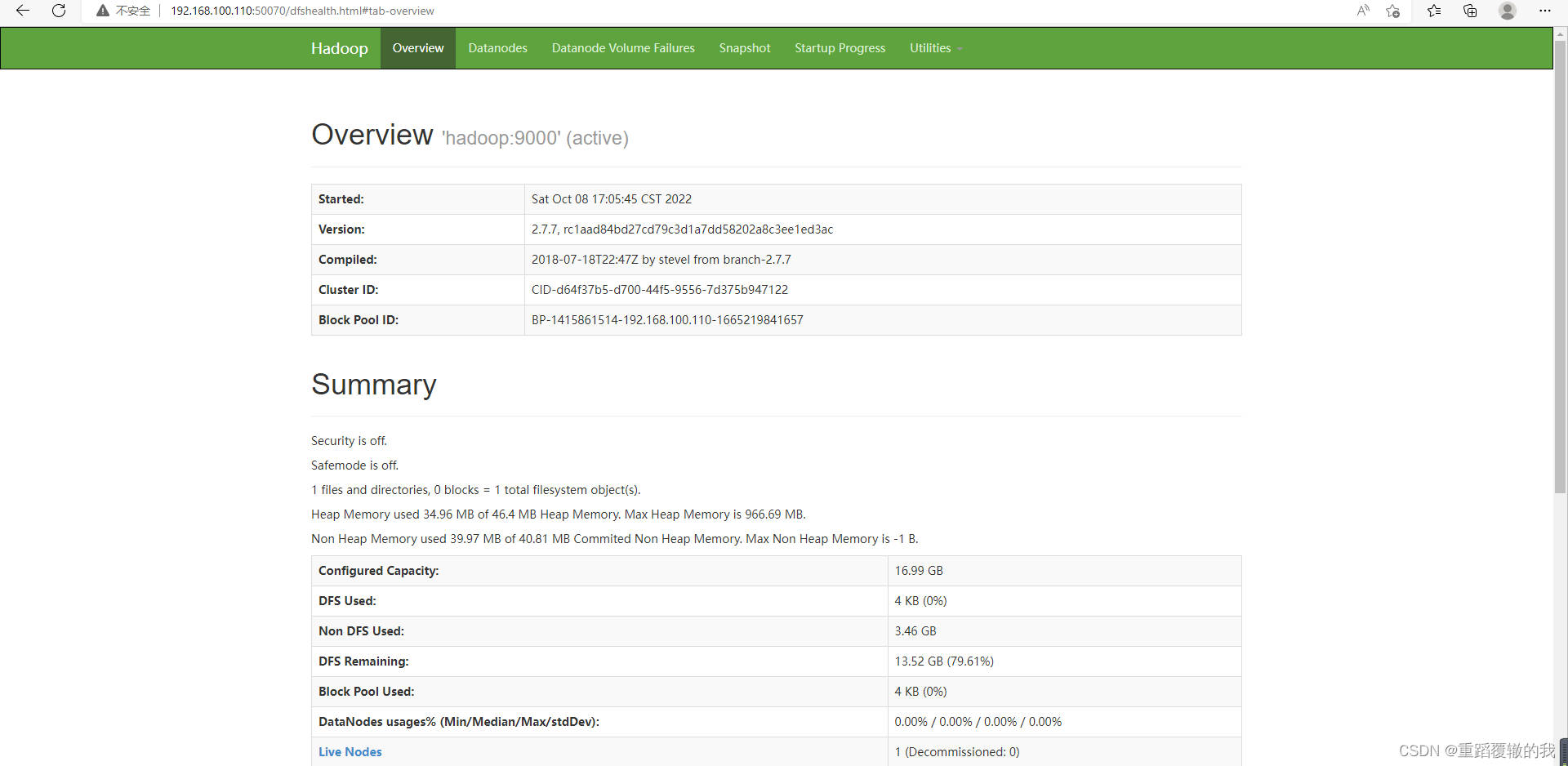
ip:9870进行访问
yarn的访问
ip:8088
到此hadoop伪分布式就算搭建成功了。
我正在尝试在我的centos服务器上安装therubyracer,但遇到了麻烦。$geminstalltherubyracerBuildingnativeextensions.Thiscouldtakeawhile...ERROR:Errorinstallingtherubyracer:ERROR:Failedtobuildgemnativeextension./usr/local/rvm/rubies/ruby-1.9.3-p125/bin/rubyextconf.rbcheckingformain()in-lpthread...yescheckingforv8.h...no***e
我有一个涉及多台机器、消息队列和事务的问题。因此,例如用户点击网页,点击将消息发送到另一台机器,该机器将付款添加到用户的帐户。每秒可能有数千次点击。事务的所有方面都应该是容错的。我以前从未遇到过这样的事情,但一些阅读表明这是一个众所周知的问题。所以我的问题。我假设安全的方法是使用两阶段提交,但协议(protocol)是阻塞的,所以我不会获得所需的性能,我是否正确?我通常写Ruby,但似乎Redis之类的数据库和Rescue、RabbitMQ等消息队列系统对我的帮助不大——即使我实现某种两阶段提交,如果Redis崩溃,数据也会丢失,因为它本质上只是内存。所有这些让我开始关注erlang和
需求:要创建虚拟机,就需要给他提供一个虚拟的磁盘,我们就在/opt目录下创建一个10G大小的raw格式的虚拟磁盘CentOS-7-x86_64.raw命令格式:qemu-imgcreate-f磁盘格式磁盘名称磁盘大小qemu-imgcreate-f磁盘格式-o?1.创建磁盘qemu-imgcreate-fraw/opt/CentOS-7-x86_64.raw10G执行效果#ls/opt/CentOS-7-x86_64.raw2.安装虚拟机使用virt-install命令,基于我们提供的系统镜像和虚拟磁盘来创建一个虚拟机,另外在创建虚拟机之前,提前打开vnc客户端,在创建虚拟机的时候,通过vnc
1.1.1 YARN的介绍 为克服Hadoop1.0中HDFS和MapReduce存在的各种问题⽽提出的,针对Hadoop1.0中的MapReduce在扩展性和多框架⽀持⽅⾯的不⾜,提出了全新的资源管理框架YARN. ApacheYARN(YetanotherResourceNegotiator的缩写)是Hadoop集群的资源管理系统,负责为计算程序提供服务器计算资源,相当于⼀个分布式的操作系统平台,⽽MapReduce等计算程序则相当于运⾏于操作系统之上的应⽤程序。 YARN被引⼊Hadoop2,最初是为了改善MapReduce的实现,但是因为具有⾜够的通⽤性,同样可以⽀持其他的分布式计算模
我有一个启动DRb服务的脚本,然后生成处理程序对象并通过DRb.thread.join等待。我希望脚本一直运行直到被明确杀死,所以我添加了trap"INT"doDRb.stop_serviceend在Ruby1.8下成功停止DRb服务并退出,但在1.9下似乎死锁(在OSX10.6.7上)。对该进程进行采样显示在semaphore_wait_signal_trap中有几个线程在旋转。我假设我在调用stop_service时做错了什么,但我不确定是什么。谁能给我任何关于如何正确处理它的指示? 最佳答案 好的,我想我已经找到了解决方案。如
require'openssl'ifARGV.length==2pkcs12=OpenSSL::PKCS12.new(File.read(ARGV[0]),ARGV[1])ppkcs12.certificateelseputs"Usage:load_cert.rb"end运行它会在Windows上产生错误,但在Linux上不会。错误:OpenSSL::PKCS12::PKCS12Error:PKCS12_parse:macverifyfailurefrom(irb):21:ininitializefrom(irb):21:innewfrom(irb):21fromC:/Ruby192/
一、相关网址1、官网(可以下载,查看文章)https://skywalking.apache.org/downloads/2、github地址:(可提问题寻求帮助)https://github.com/apache/skywalking二、 实验环境操作系统 centos7.9先安装好 elasticsearch7.16.2操作系统安装好jdk8-17,实验机器jdk11java下载地址:https://www.oracle.com/java/technologies/downloads/#java8IP地址为192.168.24.160三、安装skywalking 1、下载skywalkin
目录1、yum安装mysql修改密码(1)在mysql里面修改(2)第二种方式,利用mysqladmin修改密码2、没有密码,登录mysql修改密码3、mysql的安全设置1、yum安装mysql在CentOS中默认安装有MariaDB(MySQL的一个分支),安装完成之后可以直接覆盖MariaDB。rpm-qa|grepmariadb查询是否安装了mariadbrpm-e--nodepsmariadb-libs-5.5.60-1.el7_5.x86_64卸载mariadwgethttp://dev.mysql.com/get/mysql57-community-release-el7-11.
Nginx安装1.官网下载Nginx2.使用XShell和Xftp将压缩包上传到Linux虚拟机中3.解压文件nginx-1.20.2.tar.gz4.配置nginx5.启动nginx6.拓展(修改端口和常用命令)(一)修改nginx端口(二)常用命令1.官网下载Nginxhttp://nginx.org/en/download.html这里我下载的是1.20.2版本,大家按需下载对应稳定版即可2.使用XShell和Xftp将压缩包上传到Linux虚拟机中没有XShell可以参考《Linux操作系统CentOS7连接XShell》3.解压文件nginx-1.20.2.tar.gz1)检查是否存
目录:一、简介二、HQL的执行流程三、索引四、索引案例五、Hive常用DDL操作六、Hive常用DML操作七、查询结果插入到表八、更新和删除操作九、查询结果写出到文件系统十、HiveCLI和Beeline命令行的基本使用十一、Hive配置一、简介Hive是一个构建在Hadoop之上的数据仓库,它可以将结构化的数据文件映射成表,并提供类SQL查询功能,用于查询的SQL语句会被转化为MapReduce作业,然后提交到Hadoop上运行。特点:简单、容易上手(提供了类似sql的查询语言hql),使得精通sql但是不了解Java编程的人也能很好地进行大数据分析;灵活性高,可以自定义用户函数(UDF)和