说明: 这里主要以 springboot 应用为基础应用进行整合开发。
Spring Data : Spring 数据框架 JPA 、Redis、Elasticsearch、AMQP、MongoDB
JdbcTemplate
RedisTemplate
ElasticTempalte
AmqpTemplate
MongoTemplate
SpringBoot Spring Data MongoDB
# 引入依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-mongodb</artifactId>
</dependency>
# 编写配置
# mongodb 没有开启任何安全协议
# mongodb(协议)://192.168.204.140(主机):27017(端口)/baizhi(库名)
spring.data.mongodb.uri=mongodb://192.168.204.140:27017/baizhi
# mongodb 存在密码则进行下面配置
#spring.data.mongodb.host=192.168.204.140
#spring.data.mongodb.port=27017
#spring.data.mongodb.database=baizhi
#spring.data.mongodb.username=lb
#spring.data.mongodb.password=lb
注意:库应该提前创建好
创建集合
@Test
public void testCreateCollection(){
mongoTemplate.createCollection("users");//参数: 创建集合名称
}
注意:创建集合不能存在,存在报错
删除集合
@Test
public void testDeleteCollection(){
mongoTemplate.dropCollection("users");
}
测试类
/**
* 对集合的操作
*/
public class MongoTemplateTests extends SpringbootMongodbDemoApplicationTests{
private final MongoTemplate mongoTemplate;
// 构造注入
@Autowired
public MongoTemplateTests(MongoTemplate mongoTemplate) {
this.mongoTemplate = mongoTemplate;
}
// 1. 创建集合
@Test
public void testCreateCollection(){
// 判断集合是否存在
boolean exists = mongoTemplate.collectionExists("products");
if(!exists){ // 集合不存在的话再创建
mongoTemplate.createCollection("products"); // 创建名为products的集合
// 注: 创建在哪个库中呢? 配置文件之前已经配置好了,所以我们无须关心
}
}
// 2. 删除集合
@Test
public void testDeleteCollection(){
mongoTemplate.dropCollection("products"); // 删除名为 products 的集合
// 注: 删除哪个库的集合呢? 配置文件中之前已经配置好了使用哪个库,所以我们无须关心
}
}
mongTemplate在设计的时候是面向对象开发的
@Document
value 或 collection )用来指定操作的集合(value和collection写一个就行了,写集合的名字.)@Id
@Field
name 或 value )用来指定在文档中 key 的名称,默认为成员变量名@Transient
User 实体类
@Document("users") // 加上这个注解表示这个类的实例可以转化为mongo中的一条文档,里面的参数表示这个文档日后放入哪个集合
public class User {
@Id // 将这个类的id映射为文档的_id
private Integer id;
@Field("username") // 里面参数表示将这个字段映射为文档中字段的名字
private String name;
@Field // 不写参数表明映射的对应文档中的字段名为属性名
private Double salary;
@Field
private Date birthday;
// get、set、toString、构造方法······
}
添加
insert 方法 和 save 方法 都可以添加文档
private final MongoTemplate mongoTemplate;
// 文档添加操作
@Test
public void testCreateDocument(){
// 存储单条文档
//User user = new User(2, "剑神李淳罡", 2800.1, new Date());
//mongoTemplate.save(user); // save方法在_id存在时更新数据
//mongoTemplate.insert(user); // insert方法在_id存在时会报'主键冲突'错误
// 批处理存储文档
List<User> users = Arrays.asList(new User(5, "姜泥", 2800.1, new Date()), new User(6, "红薯", 2800.1, new Date()));
mongoTemplate.insert(users, User.class); // 参数1:批量数据的集合 参数2:明确集合中成员的类型(其实是为了读取注解,放入哪个集合)
}
insert报DuplicateKeyException提示主键重复;save会对已存在的数据进行更新。insert可以一次性插入整个数据,效率较高;save不能批量插入数据,只能一条一条的放数据。查询
Criteria
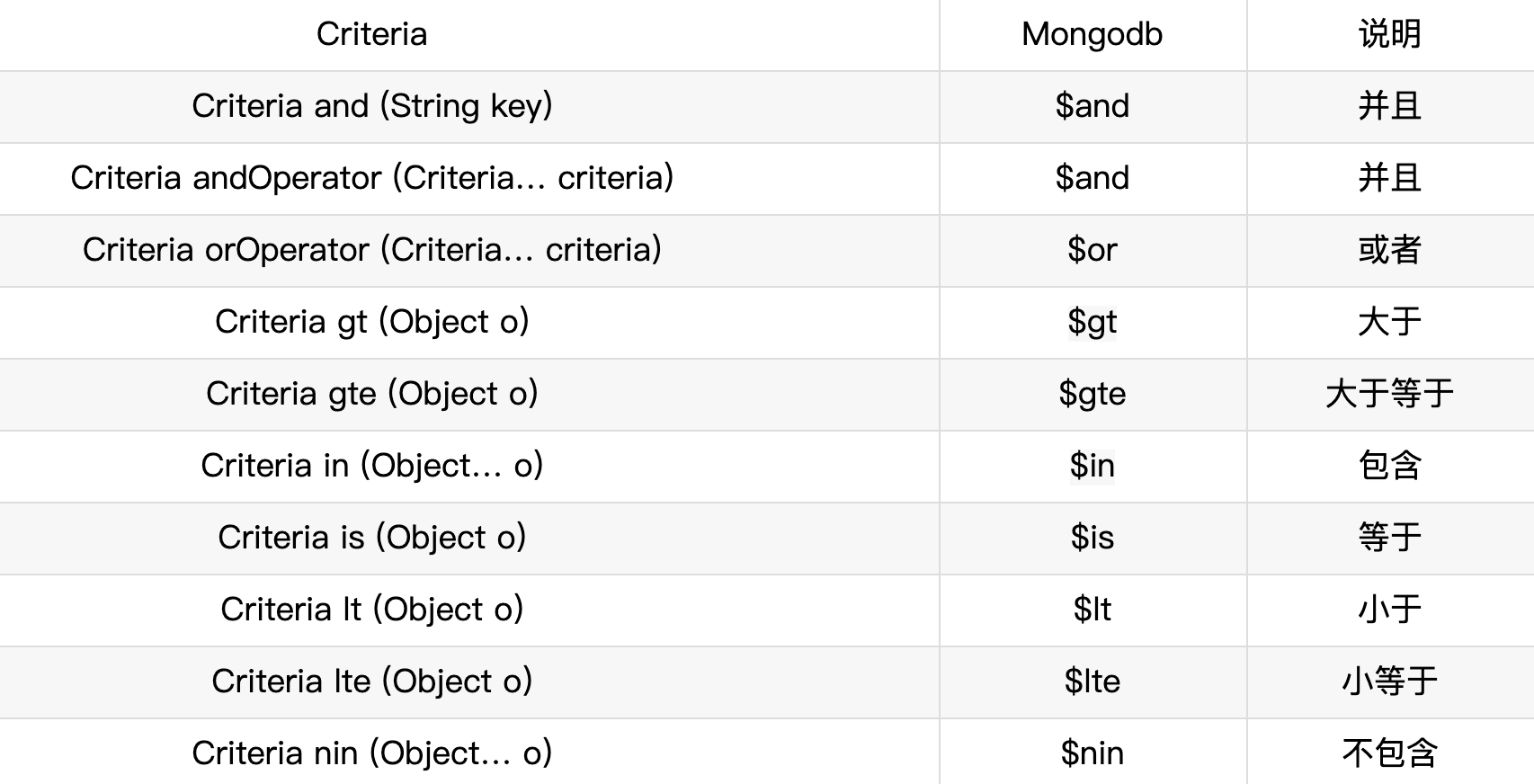
常见查询
@Test
public void testQuery(){
//基于 id 查询
template.findById("1",User.class);
//查询所有
template.findAll(User.class);
template.find(new Query(),User.class);
//等值查询
template.find(Query.query(Criteria.where("name").is("编程不良人")),
User.class);
// > gt < lt >= gte <= lte
template.find(Query.query(Criteria.where("age").lt(25)),
User.class);
template.find(Query.query(Criteria.where("age").gt(25)),
User.class);
template.find(Query.query(Criteria.where("age").lte(25)),
User.class);
template.find(Query.query(Criteria.where("age").gte(25)),
User.class);
//and
template.find(Query.query(Criteria.where("name").is("编程不良人")
.and("age").is(23)),User.class);
//or
Criteria criteria = new Criteria()
.orOperator(Criteria.where("name").is("编程不良人_1"),
Criteria.where("name").is("编程不良人_2"));
template.find(Query.query(criteria), User.class);
//and or
Criteria criteria1 = new Criteria()
.and("age").is(23)
.orOperator(
Criteria.where("name").is("编程不良人_1"),
Criteria.where("name").is("编程不良人_2"));
template.find(Query.query(criteria1), User.class);
//sort 排序
Query query = new Query();
query.with(Sort.by(Sort.Order.desc("age")));//desc 降序 asc 升序
template.find(query, User.class);
//skip limit 分页
Query queryPage = new Query();
queryPage.with(Sort.by(Sort.Order.desc("age")))//desc 降序 asc 升序
.skip(0) //起始条数
.limit(4); //每页显示记录数
template.find(queryPage, User.class);
//count 总条数
template.count(new Query(), User.class);
//distinct 去重
//参数 1:查询条件 参数 2: 去重字段 参数 3: 操作集合 参数 4: 返回类型
template.findDistinct(new Query(), "name",
User.class, String.class);
//使用 json 字符串方式查询
Query query = new BasicQuery(
"{$or:[{name:'编程不良人'},{name:'徐凤年'}]}",
"{name:0}");
template.find(query, User.class);
}
更新
@Test
public void testUpdate() {
//1.更新条件
Query query = Query.query(Criteria.where("username").is("编程不良人"));
//2.更新内容
Update update = new Update();
update.setOnInsert("id", 10); // 当要更新的文档不存在时,设置更新插入操作插入文档的_id
update.set("salary", 4000.1);
//只更新符合条件的第一条数据
mongoTemplate.updateFirst(query, update, User.class);
//多条更新
mongoTemplate.updateMulti(query, update, User.class);
//更新插入(要更新的条件文档没查到,把新数据插入)
mongoTemplate.upsert(query, update, User.class);
//返回值均为 updateResult
//System.out.println("匹配条数:" + updateResult.getMatchedCount());
//System.out.println("修改条数:" + updateResult.getModifiedCount());
//System.out.println("插入id_:" + updateResult.getUpsertedId());
}
删除
@Test
public void testDelete(){
//删除所有
mongoTemplate.remove(new Query(),User.class);
//条件删除
mongoTemplate.remove(
Query.query(Criteria.where("name").is("编程不良人")),
User.class
);
}
https://docs.mongodb.com/manual/replication/
MongoDB 副本集(Replica Set)是有自动故障恢复功能的主从集群,有一个Primary节点和一个或多个Secondary节点组成。副本集没有固定的主节点,当主节点发生故障时整个集群会选举一个主节点为系统提供服务以保证系统的高可用。副本集缺点: 由于对于提供服务的只有主节点, 所以存在单节点并发压力问题以及单节点物理存储空间限制问题.
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LOBxL0Ef-1664354191051)(https://img2022.cnblogs.com/blog/2204449/202209/2204449-20220928161939527-703084251.svg)]
自动故障转移机制: 当主节点未与集合的其他成员通信超过配置的选举超时时间(默认为 10 秒)时,合格的辅助节点将调用选举以将自己提名为新的主节点。集群尝试完成新主节点的选举并恢复正常操作。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2oTfpgHL-1664354191053)(https://img2022.cnblogs.com/blog/2204449/202209/2204449-20220928161939072-156081784.svg)]
因为没有那么多的服务器,所以我们在一台机器上模拟一下副本集群的搭建。
创建数据目录
# 进入 mongodb/bin 目录
- cd mongodb/bin
# 在安装目录中创建
- mkdir -p ../repl/data1
- mkdir -p ../repl/data2
- mkdir -p ../repl/data3
搭建副本集
# 启动
$ ./mongod --port 27017 --dbpath ../repl/data1 --bind_ip 0.0.0.0 --replSet myreplace/[192.168.204.139:27018,192.168.204.139:27019]
$ ./mongod --port 27018 --dbpath ../repl/data2 --bind_ip 0.0.0.0 --replSet myreplace/[192.168.204.139:27019,192.168.204.139:27017]
$ ./mongod --port 27019 --dbpath ../repl/data3 --bind_ip 0.0.0.0 --replSet myreplace/[192.168.204.139:27017,192.168.204.139:27018]
注意: --replSet 副本集 myreplace 副本集名称/集群中其他节点的主机和端口
一个副本集的多个mongodb节点的名字必须是一致的.
./mongo --port 27017
use admin
初始化副本集
> var config = {
_id:"myreplace",
members:[
{_id:0,host:"192.168.204.139:27017"},
{_id:1,host:"192.168.204.139:27018"},
{_id:2,host:"192.168.204.139:27019"}]
}
> rs.initiate(config) //初始化配置
设置客户端临时可以访问(设置从节点可以查看主节点的内容)
# 在从节点客户端上执行下面的代码
> rs.slaveOk();
或
> rs.secondaryOk();
Navicat如何连接
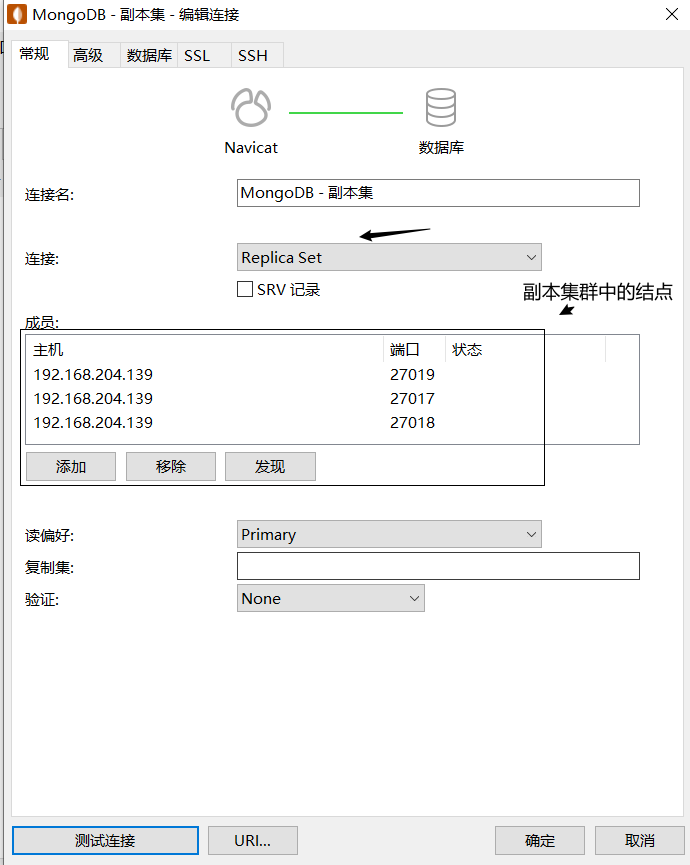
springboot如何连接
配置文件 application.properties
# 连接MongoDB的副本集群 写上全部结点的ip和端口 replSet用来写集群的名字
spring.data.mongodb.uri=mongodb://192.168.204.139:27017,192.168.204.139:27018,192.168.204.139:27019/baizhi?replicaSet=myreplace
https://docs.mongodb.com/manual/sharding/
分片(sharding)是指将数据拆分,将其分散存在不同机器的过程,有时也用分区(partitioning)来表示这个概念,将数据分散在不同的机器上,不需要功能强大的大型计算机就能存储更多的数据,处理更大的负载。
分片目的是通过分片能够增加更多机器来应对不断的增加负载和数据,还不影响应用运行。
MongoDB支持自动分片,可以摆脱手动分片的管理困扰,集群自动切分数据做负载均衡。MongoDB分片的基本思想就是将集合拆分成多个块,这些快分散在若干个片里,每个片只负责总数据的一部分,应用程序不必知道哪些片对应哪些数据,甚至不需要知道数据拆分了,所以在分片之前会运行一个路由进程,mongos进程,这个路由器知道所有的数据存放位置,应用只需要直接与mongos交互即可。mongos自动将请求转到相应的片上获取数据,从应用角度看分不分片没有什么区别。
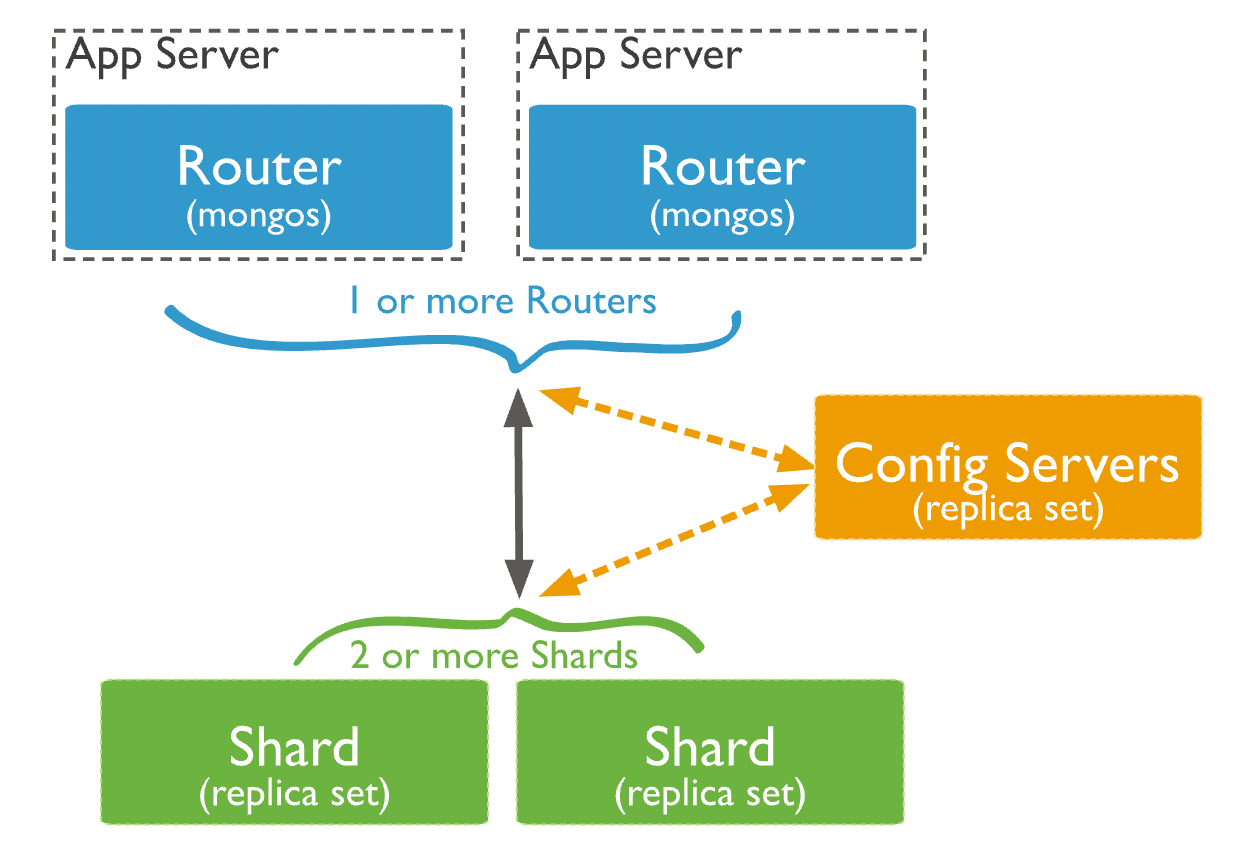
Shard: 用于存储实际的数据块,实际生产环境中一个shard server角色可由几台机器组个一个replica set承担,防止主机单点故障
Config Server:mongod实例,存储了整个 ClusterMetadata。
Query Routers: 前端路由,客户端由此接入,且让整个集群看上去像单一数据库,前端应用可以透明使用。
Shard Key: 片键,设置分片时需要在集合中选一个键,用该键的值作为拆分数据的依据,这个片键称之为(shard key),片键的选取很重要,片键的选取决定了数据散列是否均匀。
# 1.集群规划
- Shard Server 1:27017
- Shard Repl 1:27018
- Shard Server 2:27019
- Shard Repl 2:27020
- Shard Server 3:27021
- Shard Repl 3:27022
- Config Server :27023
- Config Server :27024
- Config Server :27025
- Route Process :27026
# 2.进入安装的 bin 目录创建数据目录
- mkdir -p ../cluster/shard/s0
- mkdir -p ../cluster/shard/s0-repl
- mkdir -p ../cluster/shard/s1
- mkdir -p ../cluster/shard/s1-repl
- mkdir -p ../cluster/shard/s2
- mkdir -p ../cluster/shard/s2-repl
- mkdir -p ../cluster/shard/config1
- mkdir -p ../cluster/shard/config2
- mkdir -p ../cluster/shard/config3
# 3.启动4个 shard服务
# 启动 s0、r0
> ./mongod --port 27017 --dbpath ../cluster/shard/s0 --bind_ip 0.0.0.0 --shardsvr --replSet r0/192.168.204.140:27018
> ./mongod --port 27018 --dbpath ../cluster/shard/s0-repl --bind_ip 0.0.0.0 --shardsvr --replSet r0/192.168.204.140:27017
-- 1.登录任意节点
-- 2. use admin
-- 3. 执行
config = { _id:"r0", members:[
{_id:0,host:"192.168.204.140:27017"},
{_id:1,host:"192.168.204.140:27018"},
]
}
rs.initiate(config);//初始化
# 启动 s1、r1
> ./mongod --port 27019 --dbpath ../cluster/shard/s1 --bind_ip 0.0.0.0 --shardsvr --replSet r1/192.168.204.140:27020
> ./mongod --port 27020 --dbpath ../cluster/shard/s1-repl --bind_ip 0.0.0.0 --shardsvr --replSet r1/192.168.204.140:27019
-- 1.登录任意节点
-- 2. use admin
-- 3. 执行
config = { _id:"r1", members:[
{_id:0,host:"192.168.204.140:27019"},
{_id:1,host:"192.168.204.140:27020"},
]
}
rs.initiate(config);//初始化
# 启动 s2、r2
> ./mongod --port 27021 --dbpath ../cluster/shard/s2 --bind_ip 0.0.0.0 --shardsvr --replSet r2/192.168.204.140:27022
> ./mongod --port 27022 --dbpath ../cluster/shard/s2-repl --bind_ip 0.0.0.0 --shardsvr --replSet r2/192.168.204.140:27021
-- 1.登录任意节点
-- 2. use admin
-- 3. 执行
config = { _id:"r2", members:[
{_id:0,host:"192.168.204.140:27021"},
{_id:1,host:"192.168.204.140:27022"},
]
}
rs.initiate(config);//初始化
# 4.启动3个config服务
> ./mongod --port 27023 --dbpath ../cluster/shard/config1 --bind_ip 0.0.0.0 --replSet config/[192.168.204.140:27024,192.168.204.140:27025] --configsvr
> ./mongod --port 27024 --dbpath ../cluster/shard/config2 --bind_ip 0.0.0.0 --replSet config/[192.168.204.140:27023,192.168.204.140:27025] --configsvr
> ./mongod --port 27025 --dbpath ../cluster/shard/config3 --bind_ip 0.0.0.0 --replSet config/[192.168.204.140:27023,192.168.204.140:27024] --configsvr
# 5.初始化 config server 副本集
- `登录任意节点 congfig server`
> 1.use admin
> 2.在admin中执行
config = {
_id:"config",
configsvr: true,
members:[
{_id:0,host:"192.168.204.140:27023"},
{_id:1,host:"192.168.204.140:27024"},
{_id:2,host:"192.168.204.140:27025"}
]
}
> 3.rs.initiate(config); //初始化副本集配置
# 6.启动 mongos 路由服务
> ./mongos --port 27026 --configdb config/192.168.204.140:27023,192.168.204.140:27024,192.168.204.140:27025 --bind_ip 0.0.0.0
# 7.登录 mongos 服务
> 1.登录 mongo --port 27026
> 2.use admin
> 3.添加分片信息
db.runCommand({ addshard:"r0/192.168.204.140:27017,192.168.204.140:27018",
"allowLocal":true });
db.runCommand({ addshard:"r1/192.168.204.140:27019,192.168.204.140:27020",
"allowLocal":true });
db.runCommand({ addshard:"r2/192.168.204.140:27021,192.168.204.140:27022",
"allowLocal":true });
> 4.指定分片的数据库
db.runCommand({ enablesharding:"baizhi" });
> 5.设置库的片键信息
db.runCommand({ shardcollection: "baizhi.users", key: { _id:1}});
db.runCommand({ shardcollection: "baizhi.emps", key: { _id: "hashed"}})
我正在使用的第三方API的文档状态:"[O]urAPIonlyacceptspaddedBase64encodedstrings."什么是“填充的Base64编码字符串”以及如何在Ruby中生成它们。下面的代码是我第一次尝试创建转换为Base64的JSON格式数据。xa=Base64.encode64(a.to_json) 最佳答案 他们说的padding其实就是Base64本身的一部分。它是末尾的“=”和“==”。Base64将3个字节的数据包编码为4个编码字符。所以如果你的输入数据有长度n和n%3=1=>"=="末尾用于填充n%
在应用开发中,有时候我们需要获取系统的设备信息,用于数据上报和行为分析。那在鸿蒙系统中,我们应该怎么去获取设备的系统信息呢,比如说获取手机的系统版本号、手机的制造商、手机型号等数据。1、获取方式这里分为两种情况,一种是设备信息的获取,一种是系统信息的获取。1.1、获取设备信息获取设备信息,鸿蒙的SDK包为我们提供了DeviceInfo类,通过该类的一些静态方法,可以获取设备信息,DeviceInfo类的包路径为:ohos.system.DeviceInfo.具体的方法如下:ModifierandTypeMethodDescriptionstatic StringgetAbiList()Obt
作为新的阿里云用户,您可以50免费试用多种优惠,价值高达1,700美元(或8,500美元)。这将让您了解和体验阿里云平台上提供的一系列产品和服务。如果您以个人身份注册免费试用,您将获得价值1,700美元的优惠。但是,如果您是注册公司,您可以选择企业免费试用,提交基本信息通过企业实名注册验证,即可开始价值$8,500的免费试用!本教程介绍了如何设置您的帐户并使用您的免费试用版。关于免费试用在我们开始此试用之前,您还必须遵守以下条款和条件才能访问您的免费试用:只有在一年内创建的账户才有资格获得阿里云免费试用。通过此免费试用优惠,用户可以免费试用免费试用活动页面上列出的每种产品一次。如果您有多个帐
我的ruby脚本从命令行参数获取某些输入。它检查是否缺少任何命令行参数,然后提示用户输入。但是我无法使用gets从用户那里获得输入。示例代码:test.rbname=""ARGV.eachdo|a|ifa.include?('-n')name=aputs"Argument:#{a}"endendifname==""puts"entername:"name=getsputsnameend运行脚本:rubytest.rbraghav-k错误结果:test.rb:6:in`gets':Nosuchfileordirectory-raghav-k(Errno::ENOENT)fromtes
开门见山|拉取镜像dockerpullelasticsearch:7.16.1|配置存放的目录#存放配置文件的文件夹mkdir-p/opt/docker/elasticsearch/node-1/config#存放数据的文件夹mkdir-p/opt/docker/elasticsearch/node-1/data#存放运行日志的文件夹mkdir-p/opt/docker/elasticsearch/node-1/log#存放IK分词插件的文件夹mkdir-p/opt/docker/elasticsearch/node-1/plugins若你使用了moba,直接右键新建即可如上图所示依次类推创建
文章目录概念索引相关操作创建索引更新副本查看索引删除索引索引的打开与关闭收缩索引索引别名查询索引别名文档相关操作新建文档查询文档更新文档删除文档映射相关操作查询文档映射创建静态映射创建索引并添加映射概念es中有三个概念要清楚,分别为索引、映射和文档(不用死记硬背,大概有个印象就可以)索引可理解为MySQL数据库;映射可理解为MySQL的表结构;文档可理解为MySQL表中的每行数据静态映射和动态映射上面已经介绍了,映射可理解为MySQL的表结构,在MySQL中,向表中插入数据是需要先创建表结构的;但在es中不必这样,可以直接插入文档,es可以根据插入的文档(数据),动态的创建映射(表结构),这就
FPGA时钟和时钟域时钟树所谓时钟树为FPGA内部资源,分:全局时钟树,区域时钟树,IO时钟树原则上优先使用全局时钟树,在GT接口上使用IO时钟树,一般工具也会对GT时钟加以限制;时钟树使用方式正确的物理连接FPGA会由物理管脚专门用于全局时钟设置,通过查询数据手册可以在PCB设计阶段进行确认,当外部时钟接入此管脚时,工具会自动占有全局时钟树资源,当接入普通信号时不会分配时钟树资源;恰当的代码描述原语的使用,即BUFG的使用,可以将PLL的输出等内部时钟进行全局时钟资源的分配;IO时钟资源需要参考相应接口手册,以ultrascale的GTH为例,其JESD204的时钟方案针对不同的子类会由不同
如果您希望在Spring中启用定时任务功能,则需要在主类上添加 @EnableScheduling 注解。这样Spring才会扫描 @Scheduled 注解并执行定时任务。在大多数情况下,只需要在主类上添加 @EnableScheduling 注解即可,不需要在Service层或其他类中再次添加。以下是一个示例,演示如何在SpringBoot中启用定时任务功能:@SpringBootApplication@EnableSchedulingpublicclassApplication{publicstaticvoidmain(String[]args){SpringApplication.ru
软件特点部署后能通过浏览器查看线上日志。支持Linux、Windows服务器。采用随机读取的方式,支持大文件的读取。支持实时打印新增的日志(类终端)。支持日志搜索。使用手册基本页面配置路径配置日志所在的目录,配置后按回车键生效,下拉框选择日志名称。选择日志后点击生效,即可加载日志。windows路径E:\java\project\log-view\logslinux路径/usr/local/XX历史模式历史模式下,不会读取新增的日志。针对历史文件可以分页读取,配置分页大小、跳转。历史模式下,支持根据关键词搜索。目前搜索引擎使用的是jdk自带类库,搜索速度相对较低,优点是比较简单。2G日志全文搜
1.依赖导入org.springframework.bootspring-boot-starter-weborg.springframework.bootspring-boot-starter-validation2.validation常用注解@Null被注释的元素必须为null@NotNull被注释的元素不能为null,可以为空字符串@AssertTrue被注释的元素必须为true@AssertFalse被注释的元素必须为false@Min(value)被注释的元素必须是一个数字,其值必须大于等于指定的最小值@Max(value)被注释的元素必须是一个数字,其值必须小于等于指定的最大值@D