文章目录
NCNN是一个腾讯开源的优化到极致的高性能神经网络前向计算框架,可以把电脑端生成在深度学习模型移植到手机端,支持的模型非常多
NCNN官方的定义:NCNN是腾讯公司开源的一个专为手机端极致优化的高性能神经网络前向计算框架。NCNN从设计之初,就深刻考虑手机端的部署和使用,无需第三方依赖,跨平台,手机端CPU的速度快于目前所有已知的开源框架。基于NCNN,开发者能够将深度学习算法轻松移植到手机端高效执行,开发出人工智能APP,将AI带到你的指尖。
目前NCNN已经支持大部分的CNN网络,包括本文中用到的YOLOv5,
可以从这个网页上进行查看支持的具体平台
Releases · Tencent/ncnn · GitHub
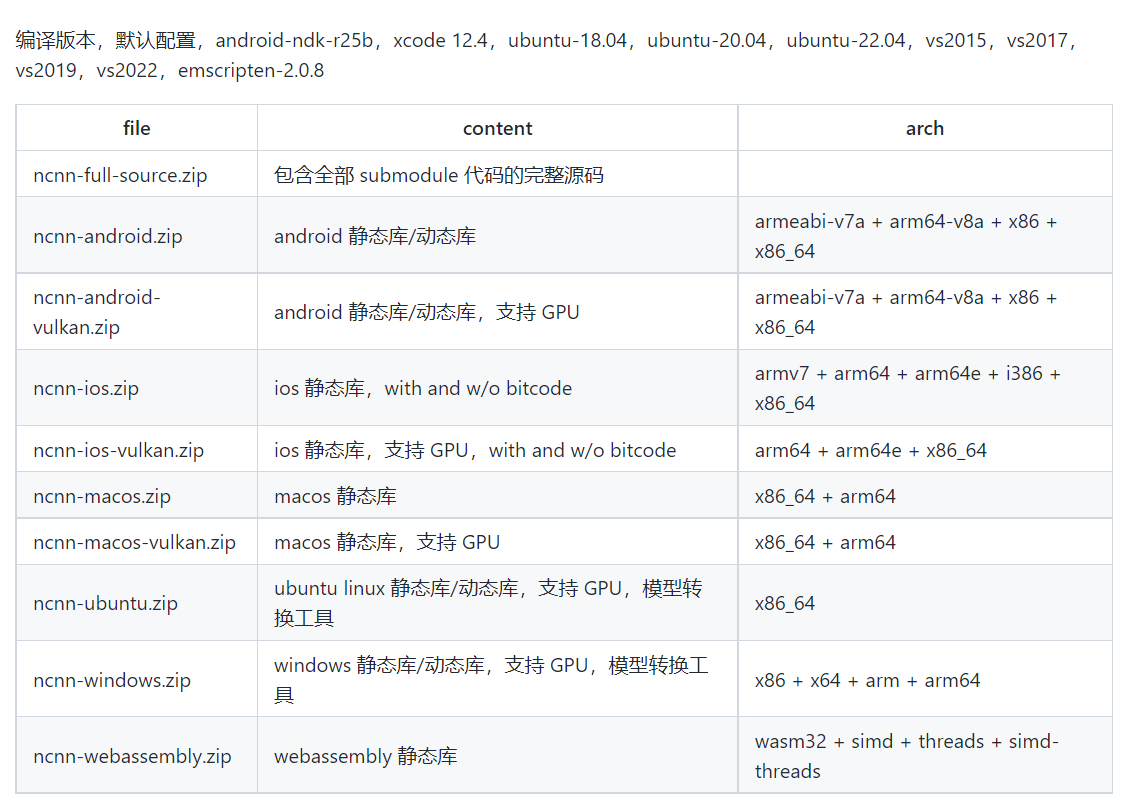
我们接下来主要以带加速的ncnn-android-vulkan.zip展开
GitHub nihui/ncnn-android-yolov5: The YOLOv5 object detection android example
这个百度上有很多对应的经验体,随便找一个教程,然后切换一下国内源,即可安装成功,这里不做赘述
这里需要说明一点,我们应该安装NDK、Cmake
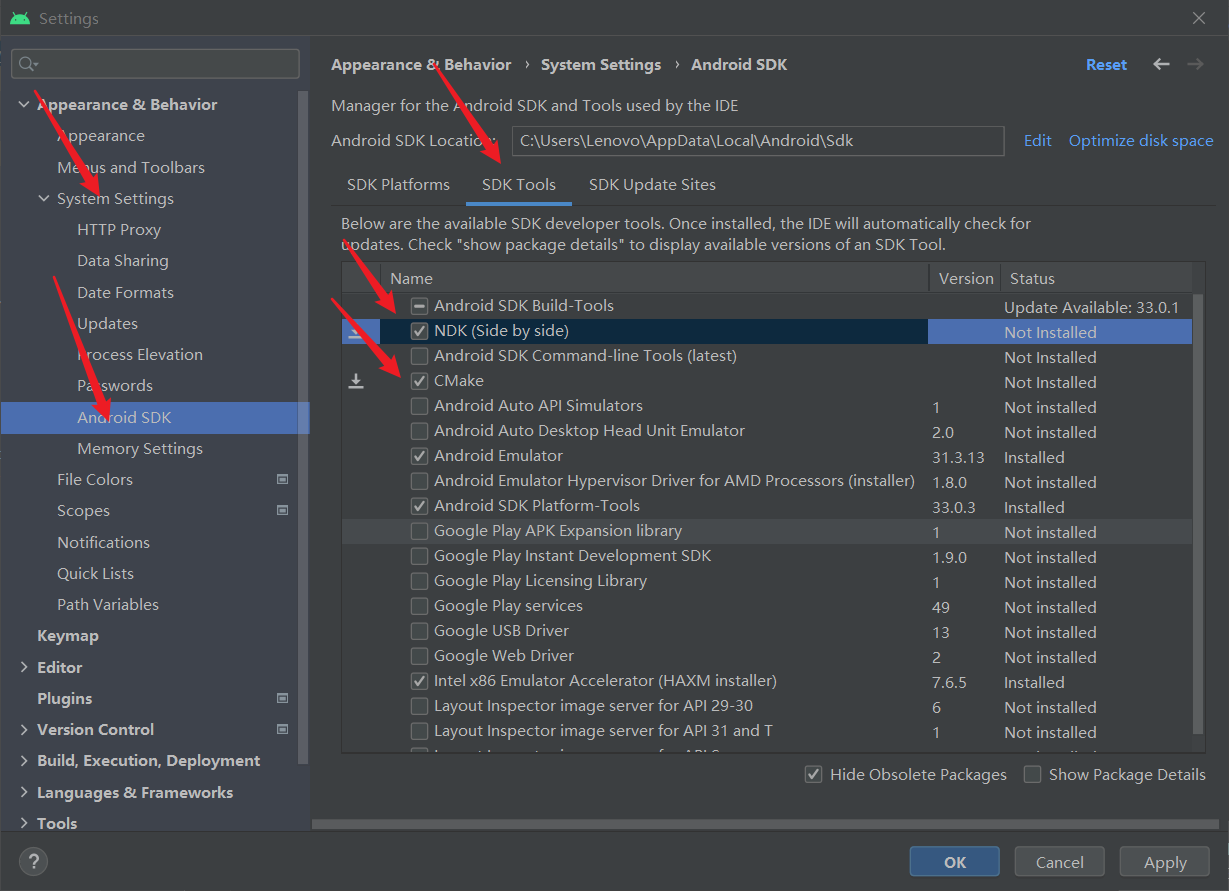

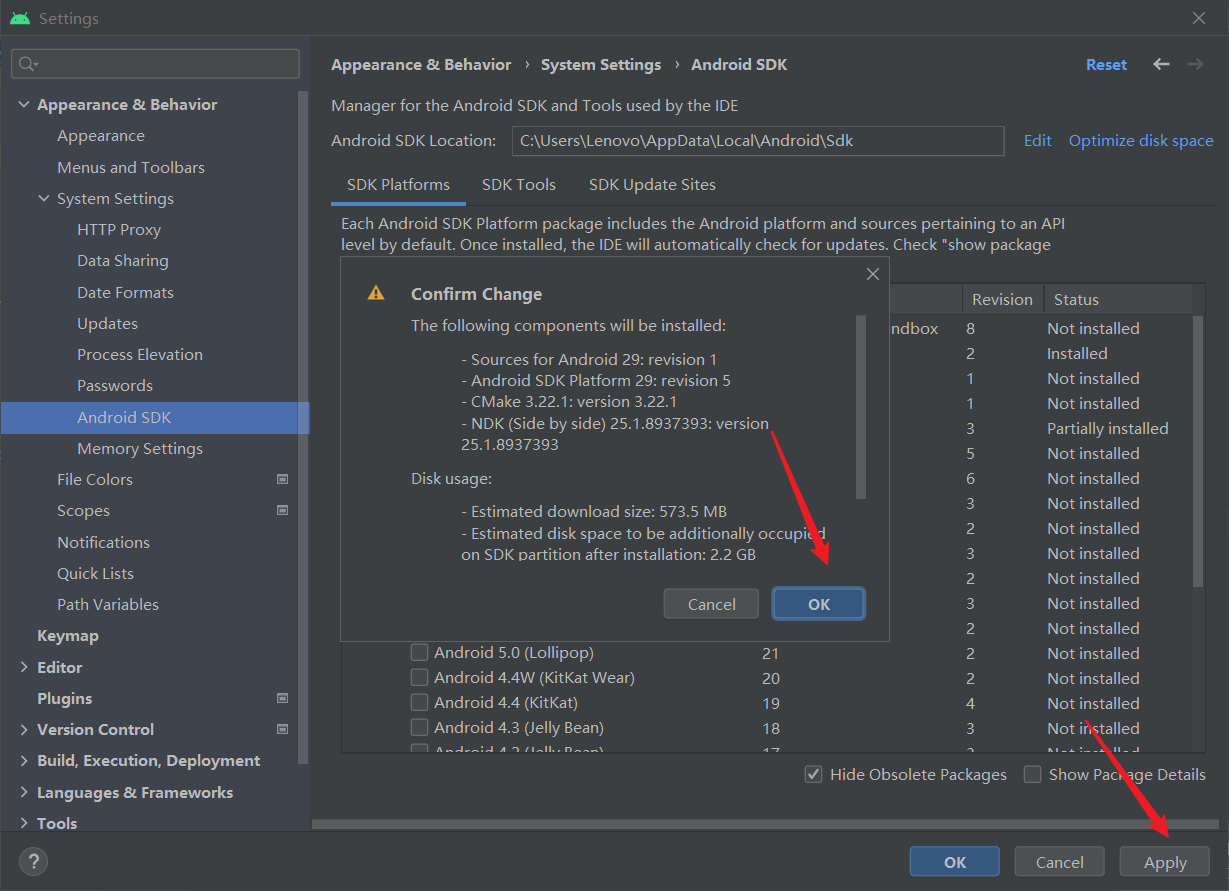
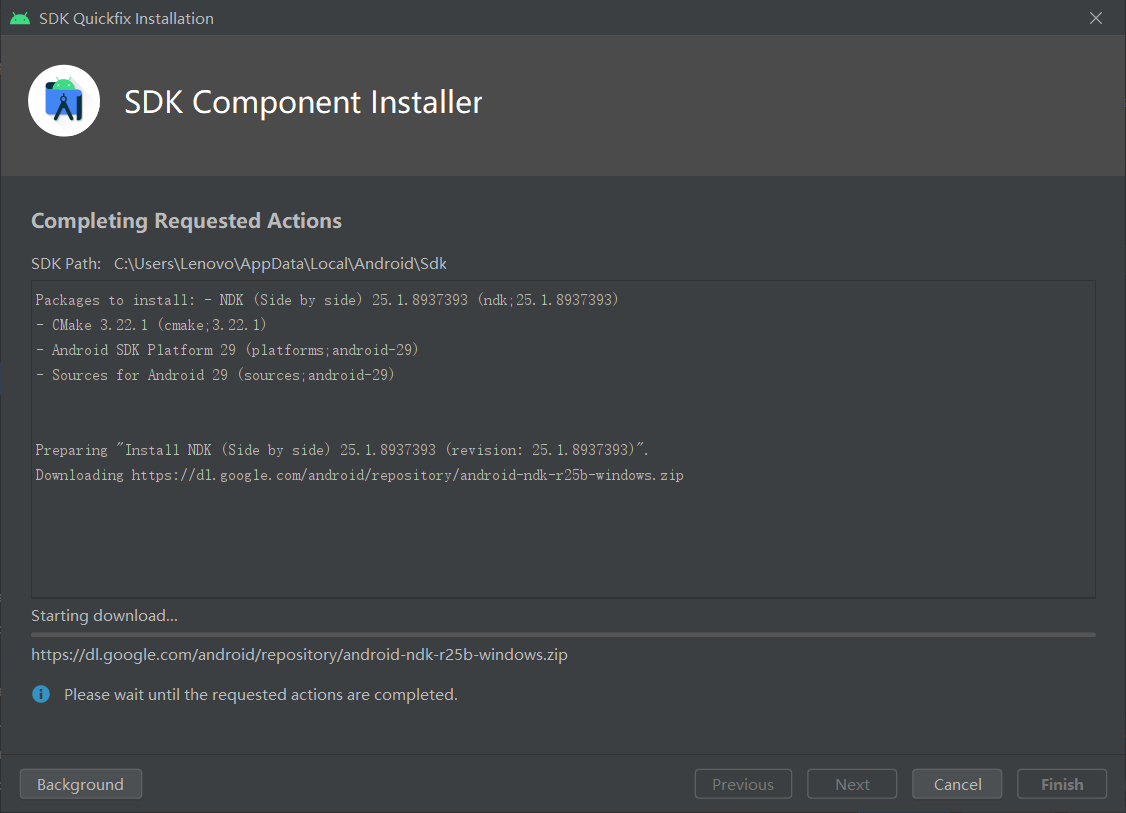

下载解压NCNN和ncnn-android-yolov5工程


用Android studio 打开这个ncnn-android-yolov5-master项目的build.gradle文件



set(ncnn_DIR ${CMAKE_SOURCE_DIR}/ncnn-20201218-android-vulkan/${ANDROID_ABI}/lib/cmake/ncnn)
set(ncnn_DIR ${CMAKE_SOURCE_DIR}/${ANDROID_ABI}/lib/cmake/ncnn)
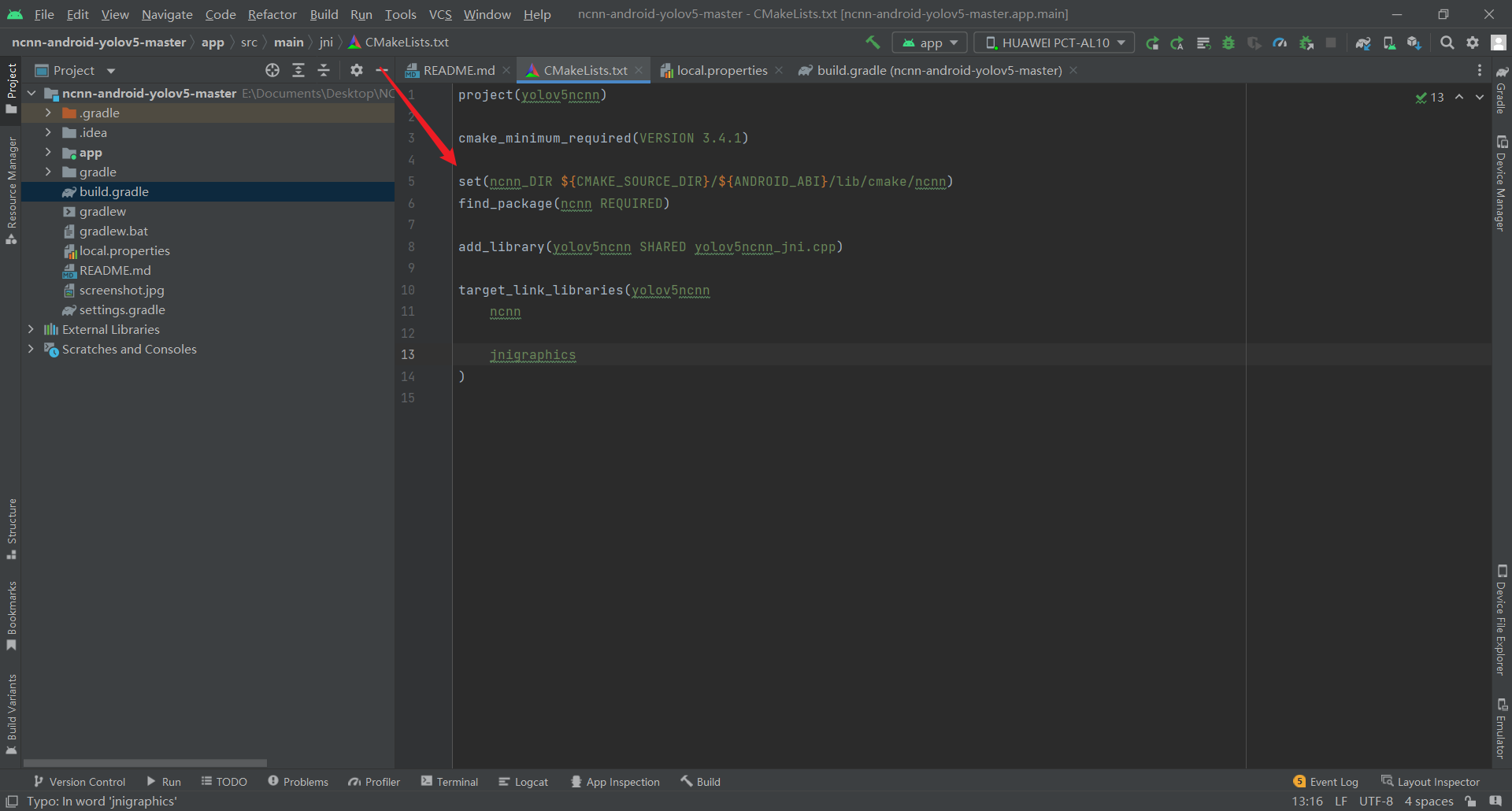

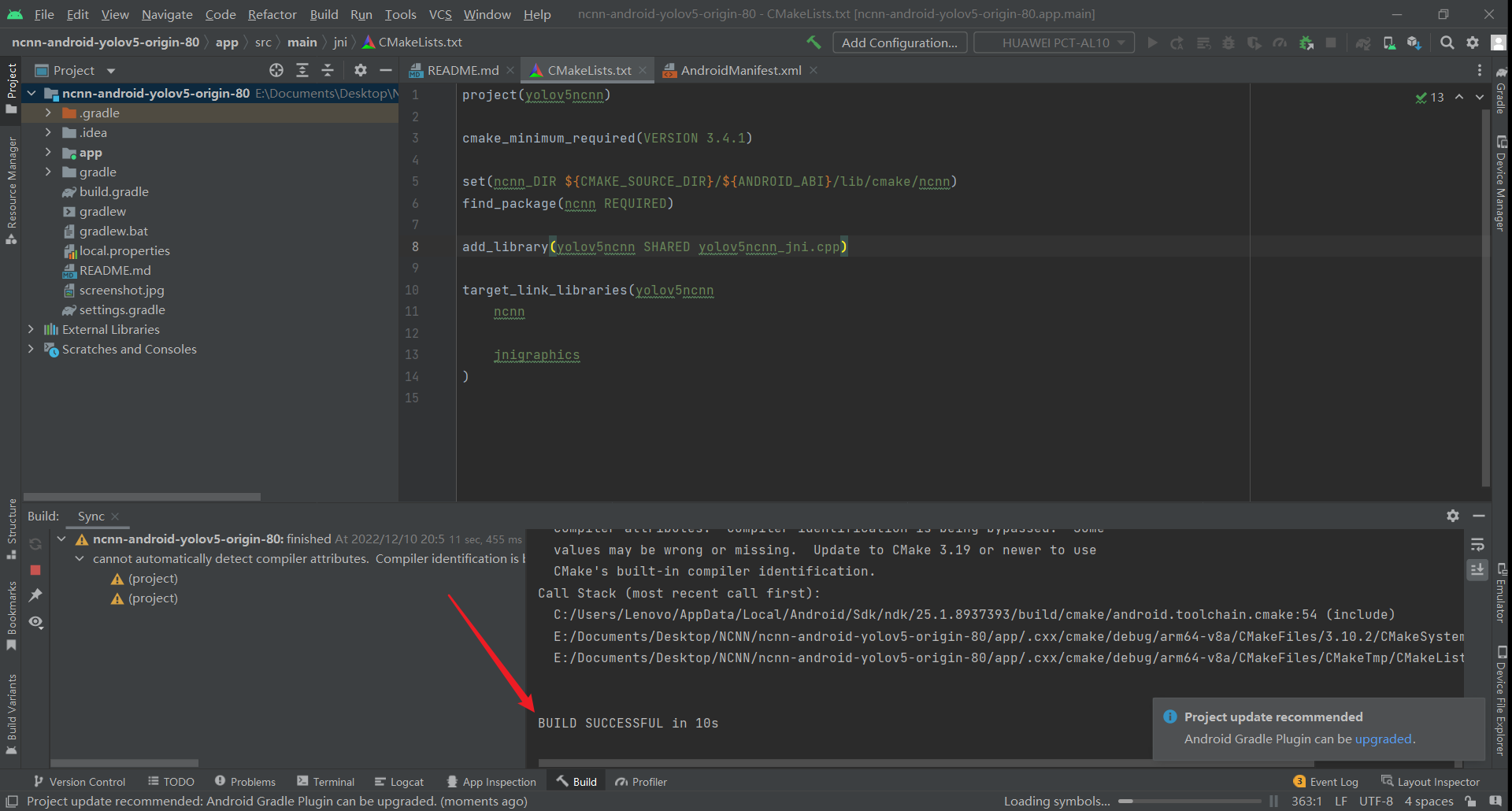
点击这个开始按钮即可


我们选择一张有物体的图片,点击识别

可以看到,已经可以用目标检测框把这个鼠标给框出来了

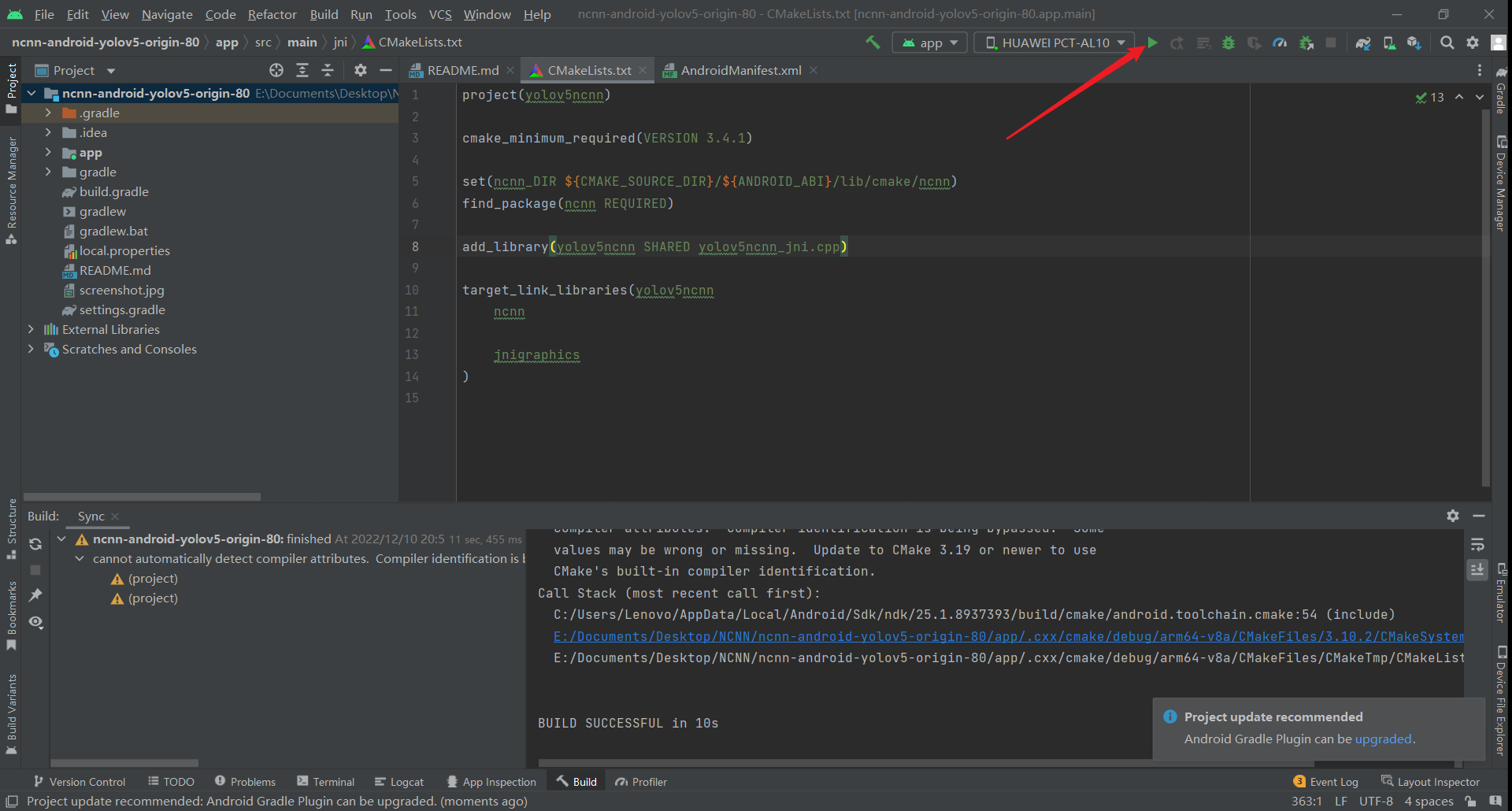
如果我们想查看手机识别的精确结果,可以点击这个run状态栏(需要注意,这个操作必须是手机通过数据线连接电脑才行)
这个时候再在手机端进行选图识别,电脑端就会打印出识别所用的精确时间

这里CPU识别一张图片用112毫秒,GPU识别一张图片需要201毫秒,这是什么鬼?可能是GPU模型比较大吧,导入的速度会慢一点,处理单张图片看不出来区别,处理视频的时候应该还是GPU更好。
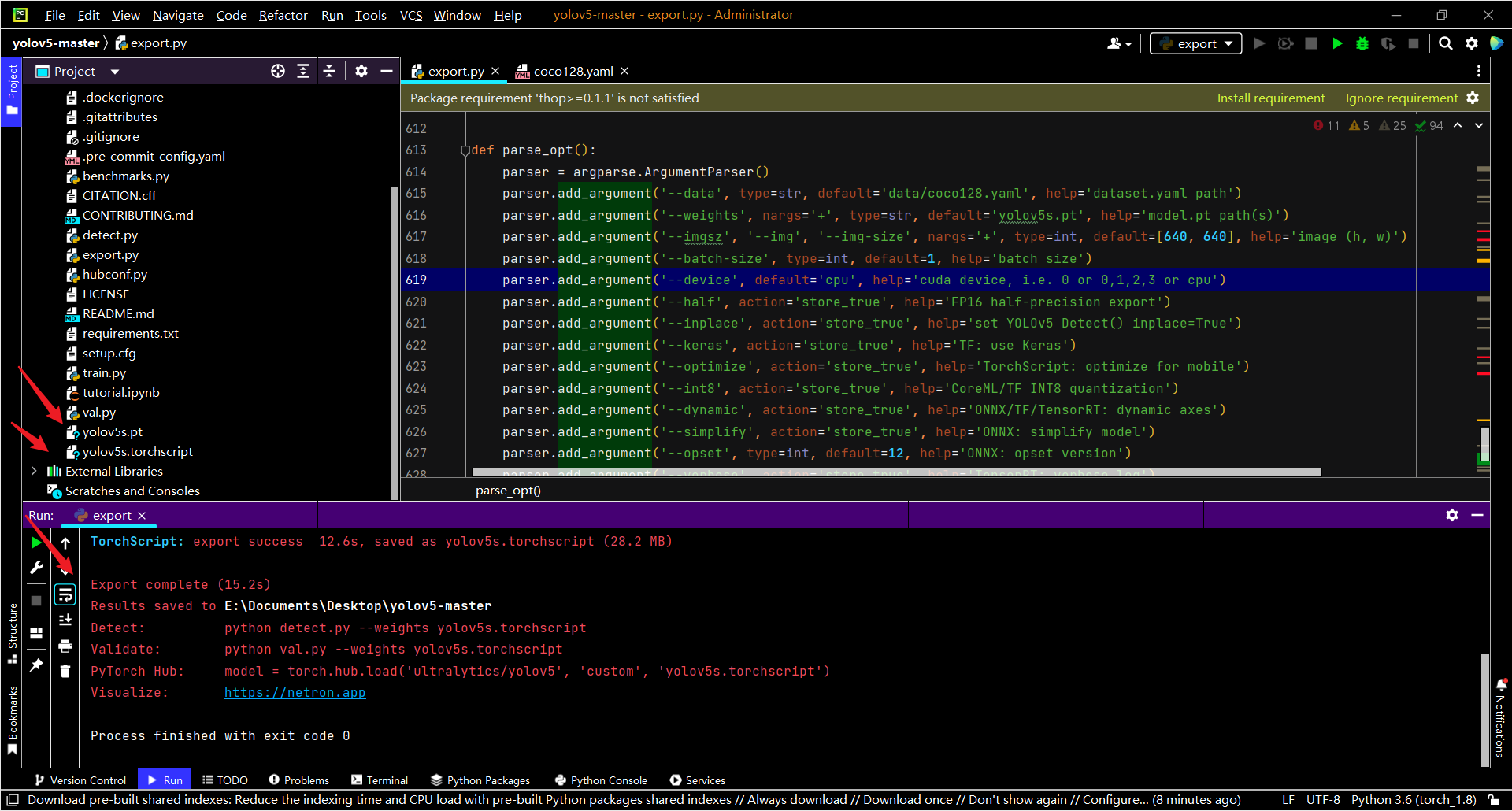
我们采用.pt ->onnx->ncnn的路线来转换自己训练的模型



export.py --weights weights/yolov5s.pt --include torchscript onnx
python export.py --train --weights weights/yolov5s.pt --include torchscript onnx
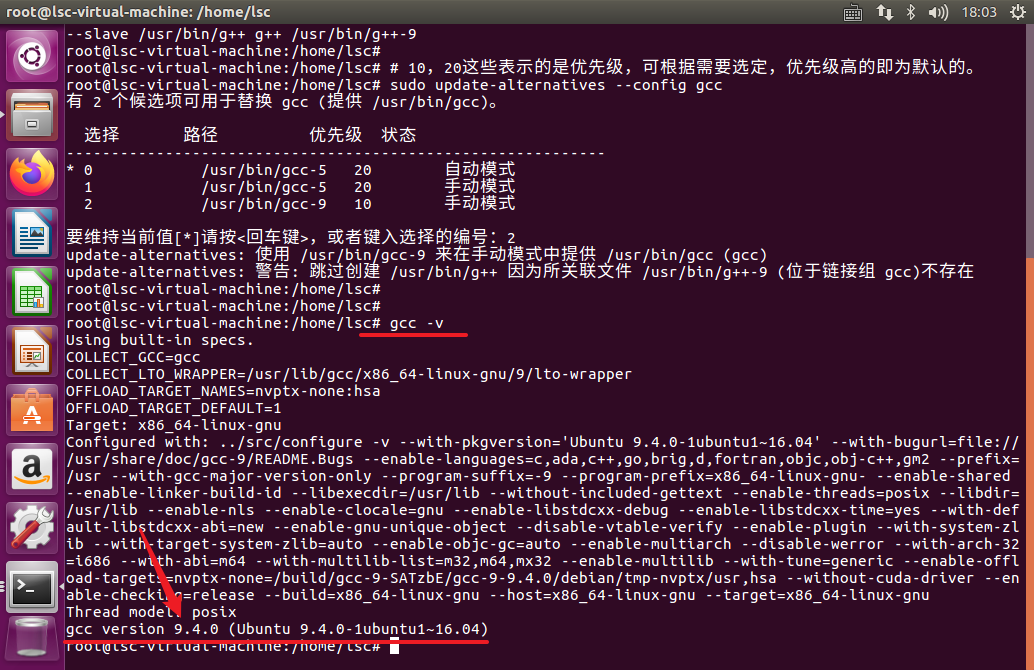
sudo apt install build-essential libopencv-dev cmake git
su
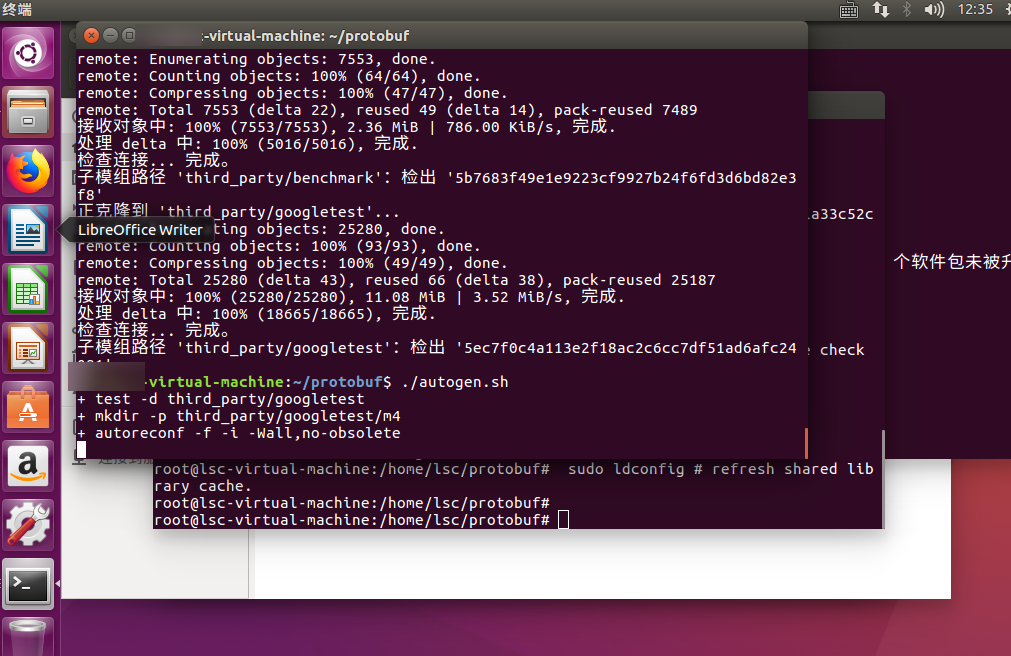
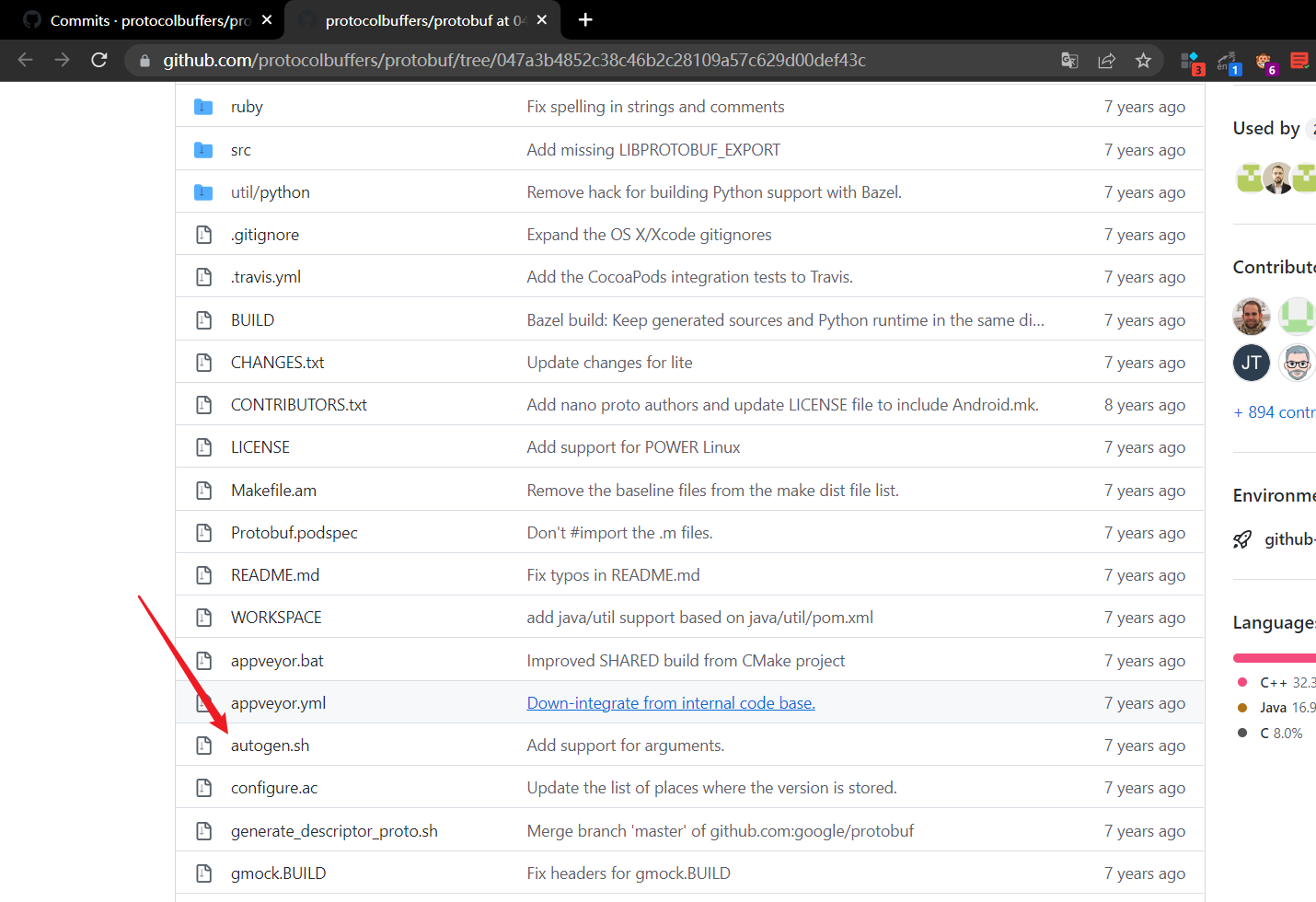
git clone -b v3.20.1-rc1 https://github.com/protocolbuffers/protobuf.git
cd protobuf
git submodule update --init --recursive
./autogen.sh
./configure
make
make install
sudo ldconfig
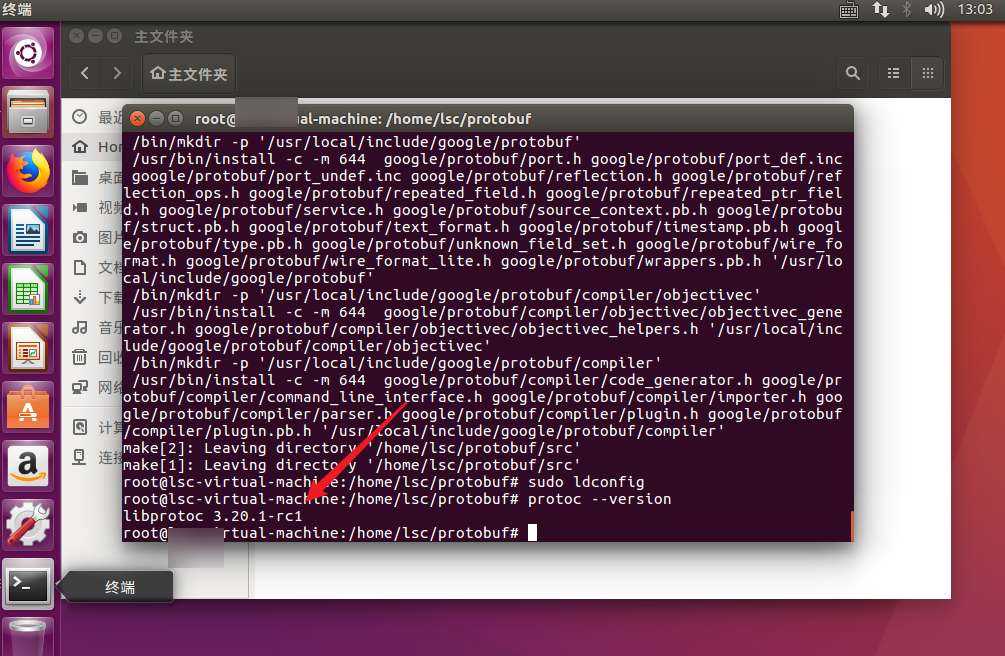
protoc --version
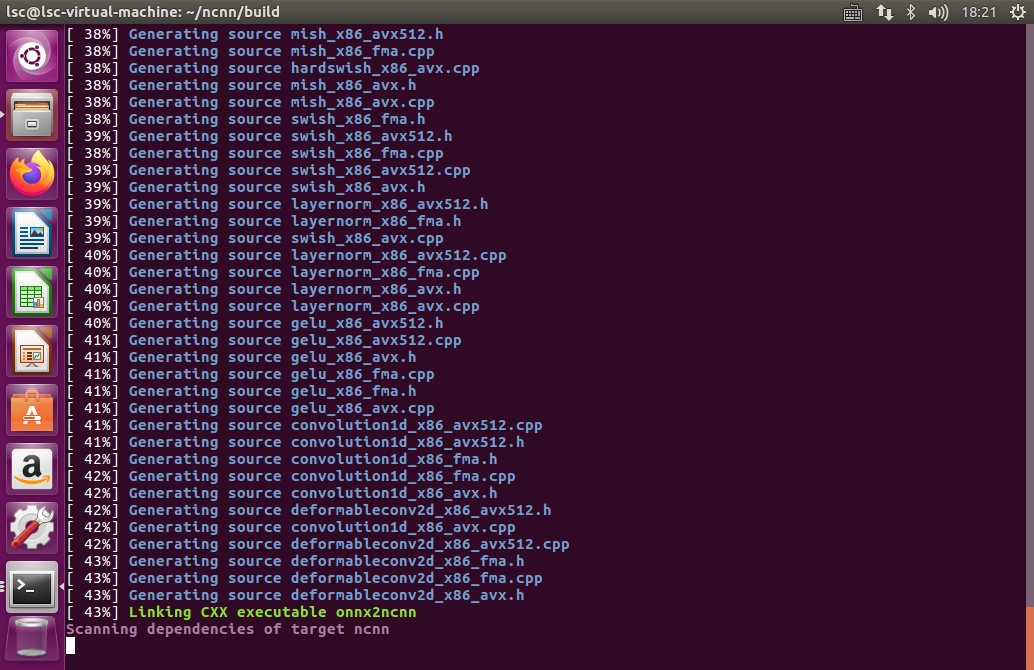
git clone https://github.com/Tencent/ncnn.git
cd ncnn
git submodule update --init
mkdir build
cd build
cmake ..
make -j8
make install



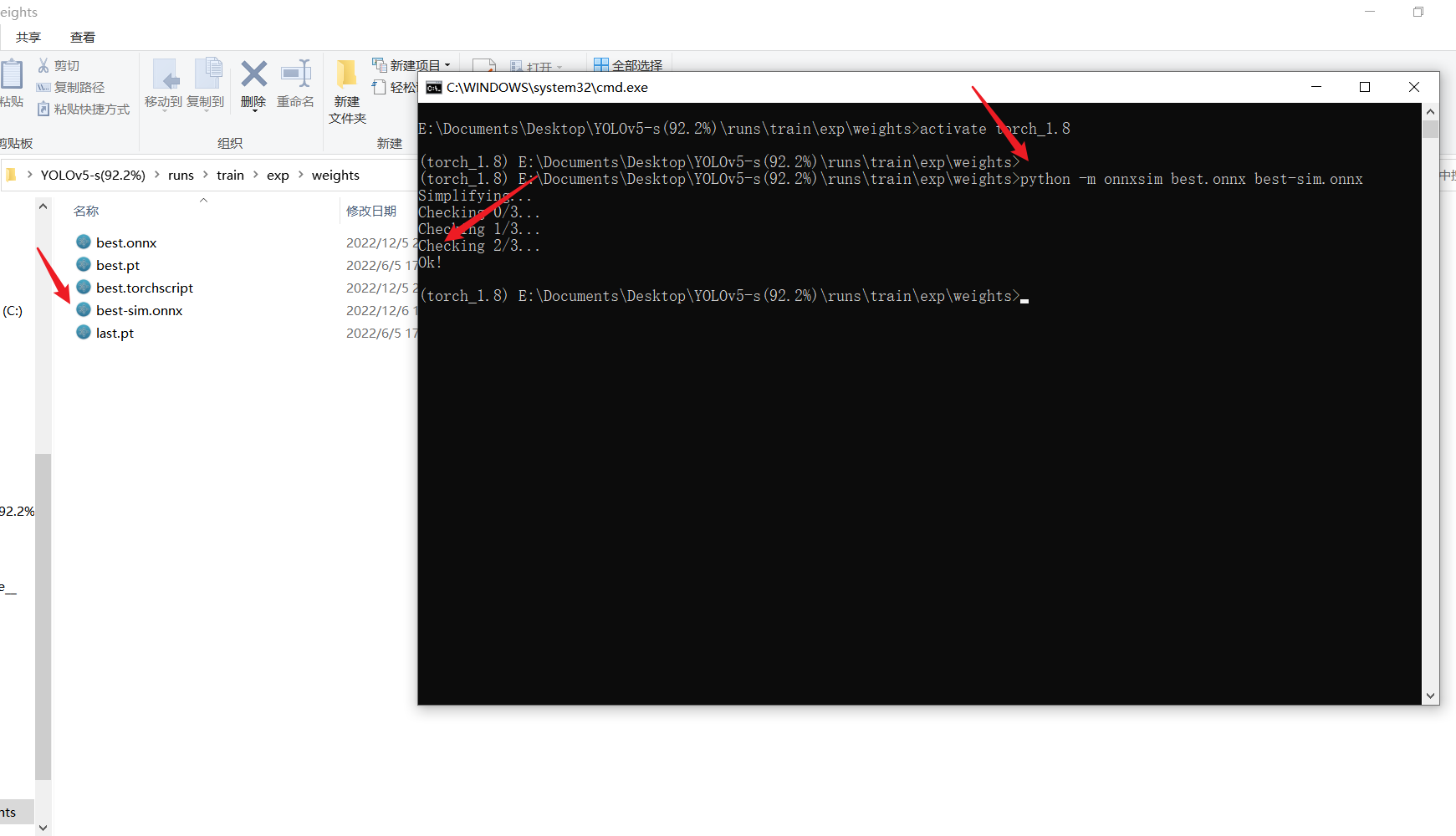
./onnx2ncnn best-sim.onnx yolov5s.param yolov5s.bin
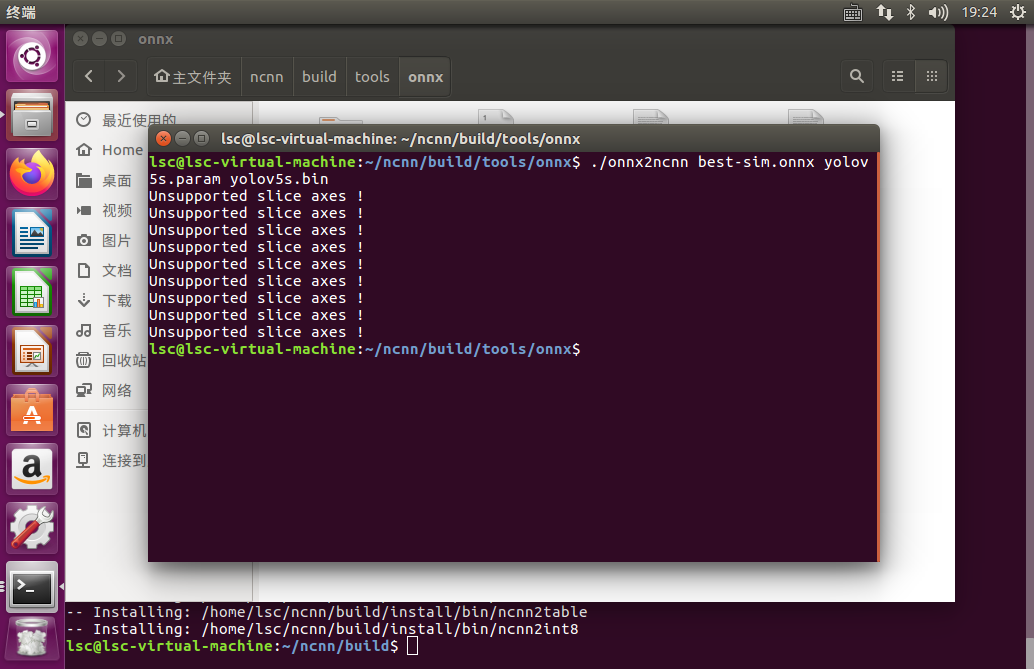

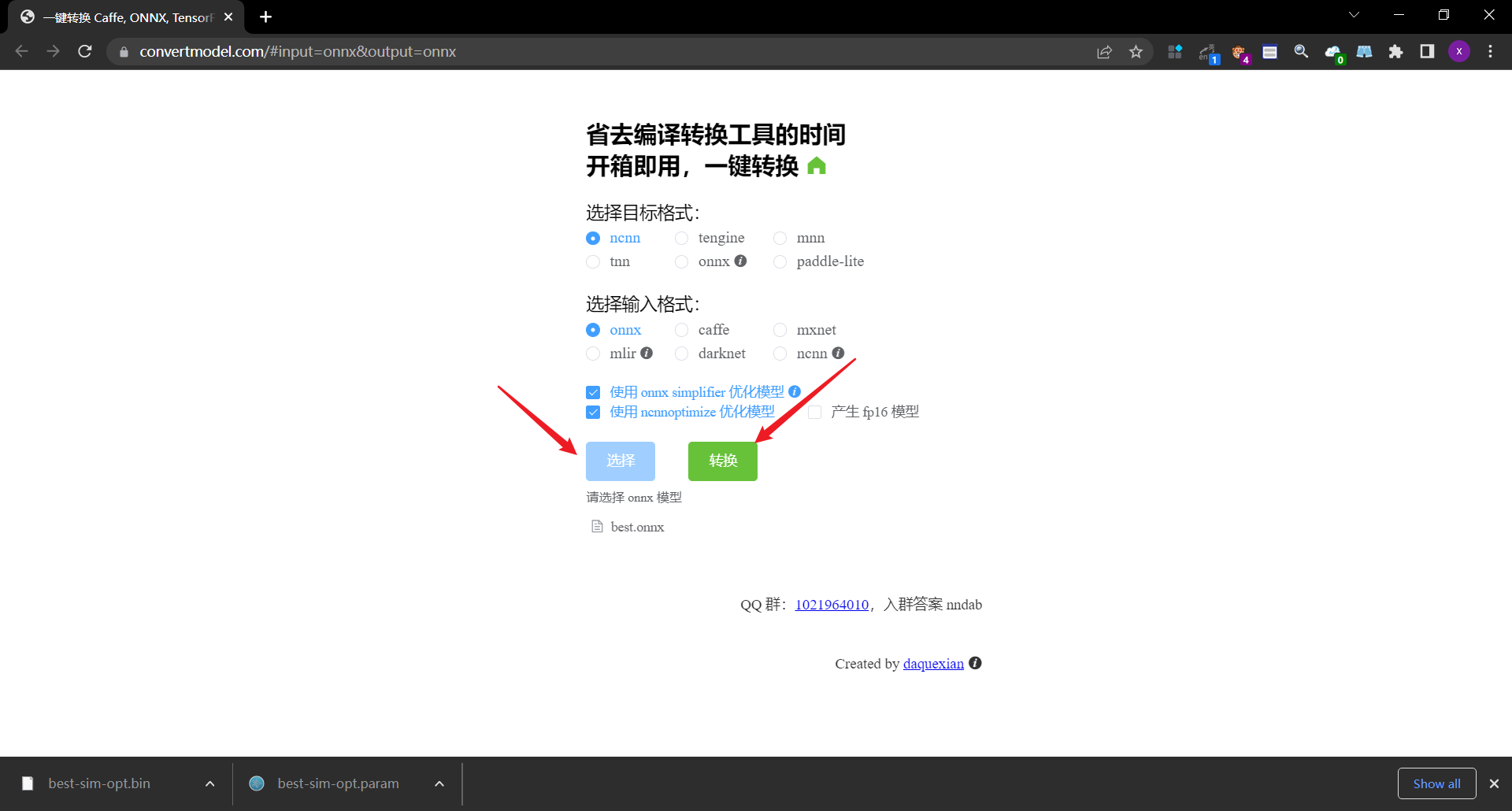
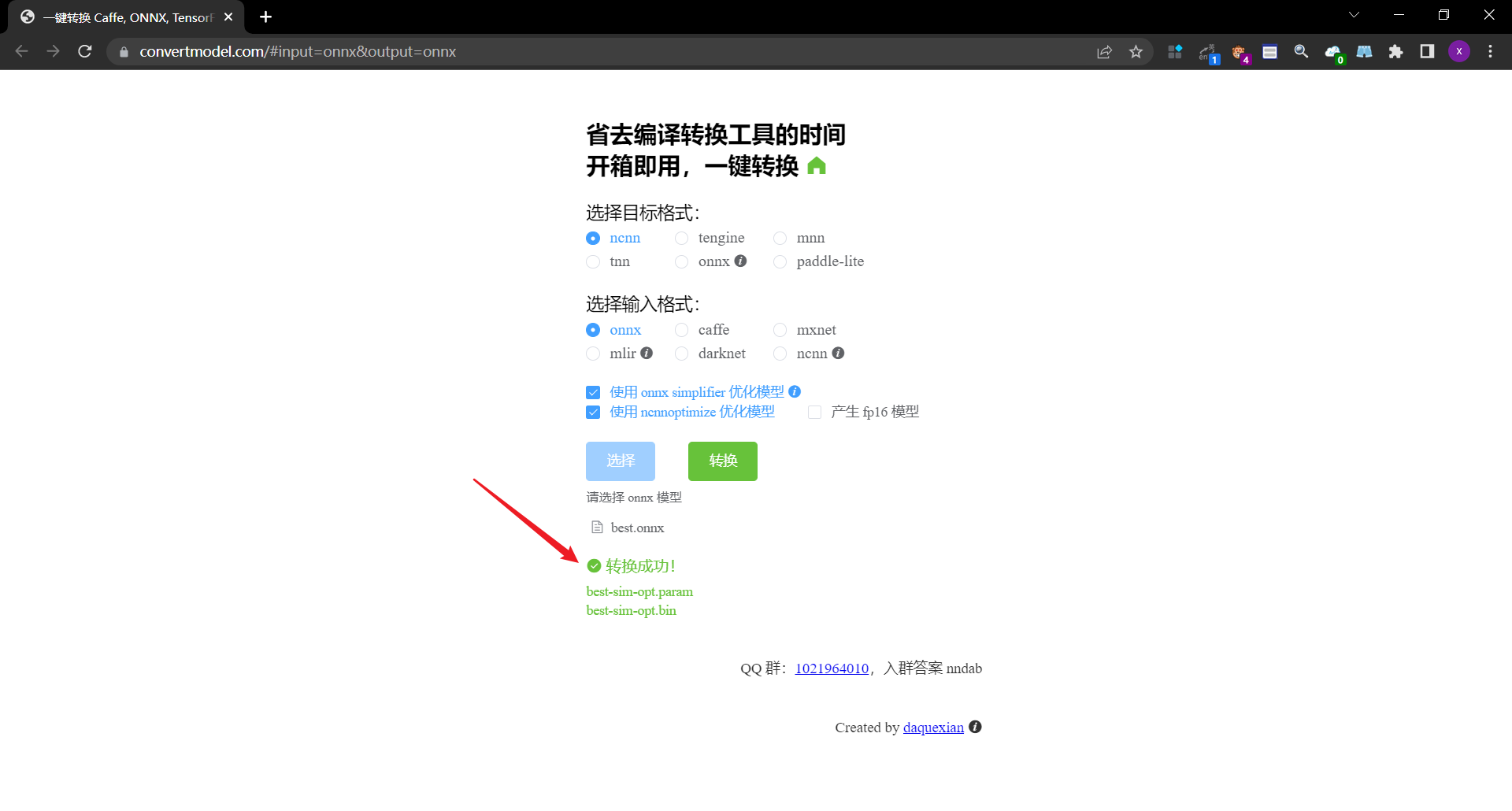
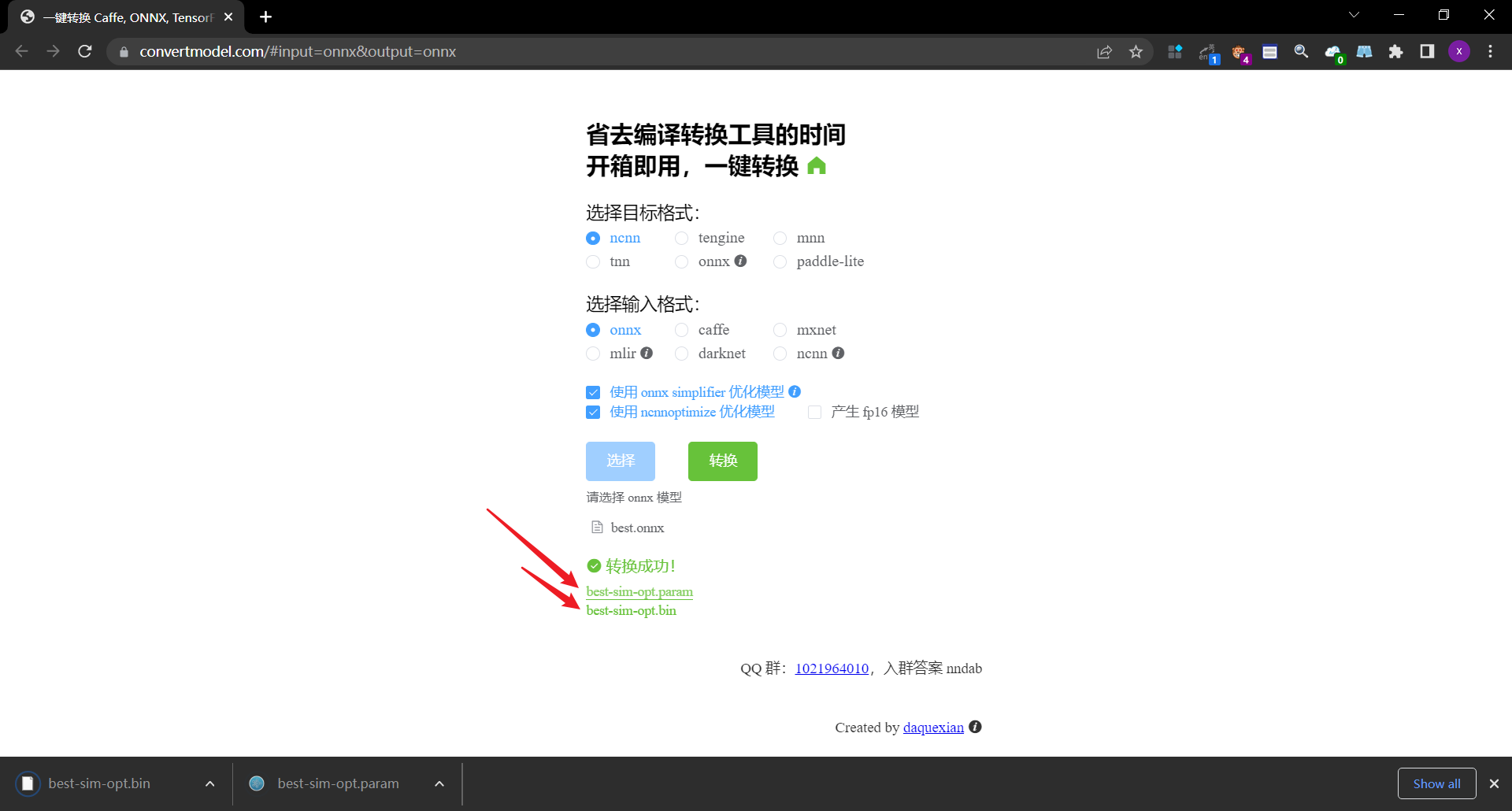
这种方式简直是我们做深度学习模型移植到安卓手机端的神器,整个过程里没有复杂的部署,也没有什么坑,有的只是人性化的操作界面,简单几个按钮就可以把整个流程给走完,节省好几个小时的时间,以及中间的无数大小坑,溢美之词不能再多了。
是在本地运行的,所以自己的模型是不会被泄露












连上手机,点击run按钮,编译安装调试

可以看到了手机端安装了对应的APP

点开


export.py --weights yolov5s.pt --include torchscript --train
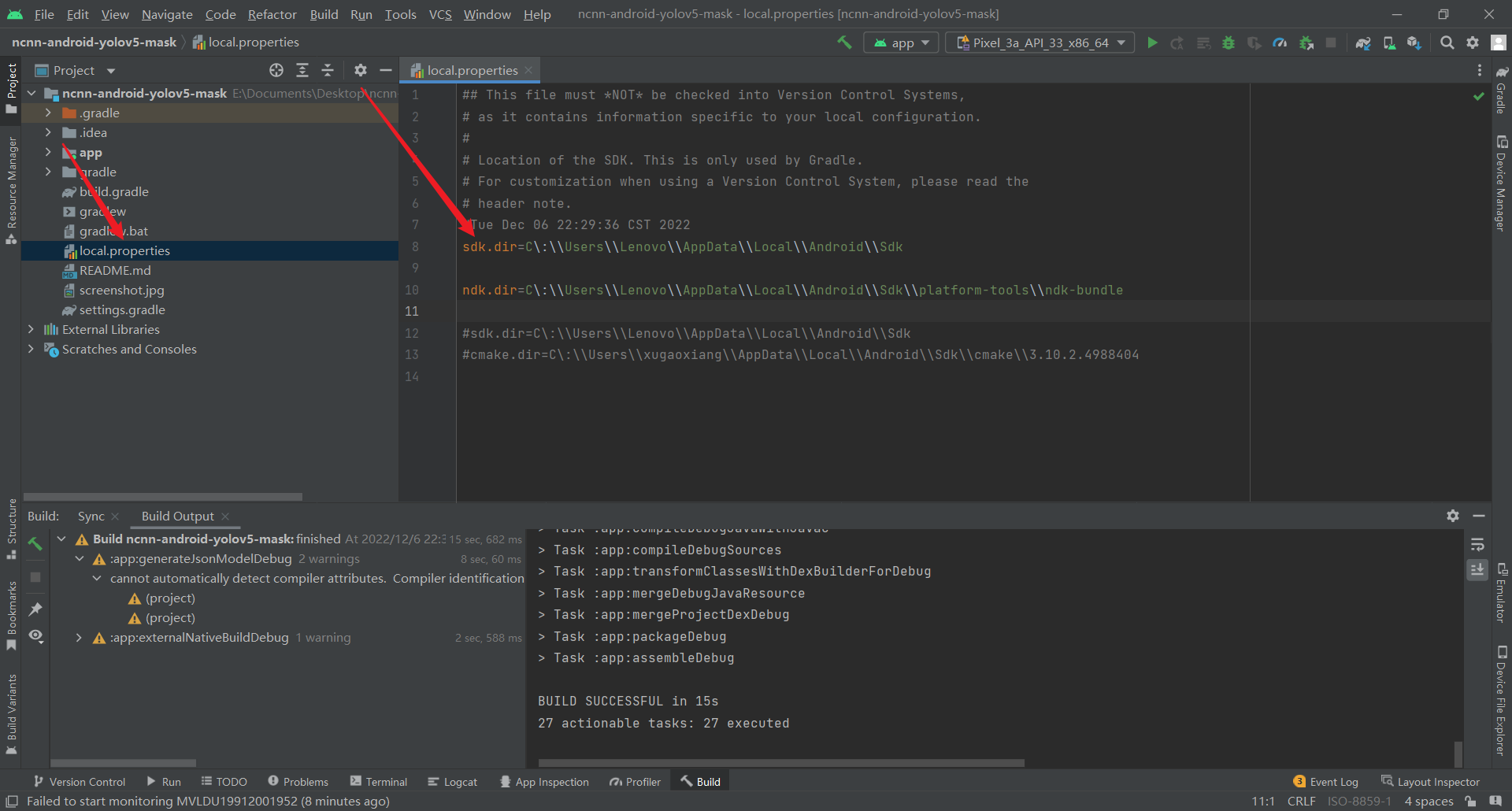
CMake ‘3.10.2’ was not found in PATH or by cmake.dir property.

点击下方的install即可

By not providing “Findncnn.cmake” in CMAKE_MODULE_PATH this project has asked CMake to find a package configuration file provided by “ncnn”, but CMake did not find one.
看一下自己ncnn-20221128-android-vulkan的代码是否放对了位置,需要放到ncnn-android-yolov5-master的\app\src\main\jni目录下
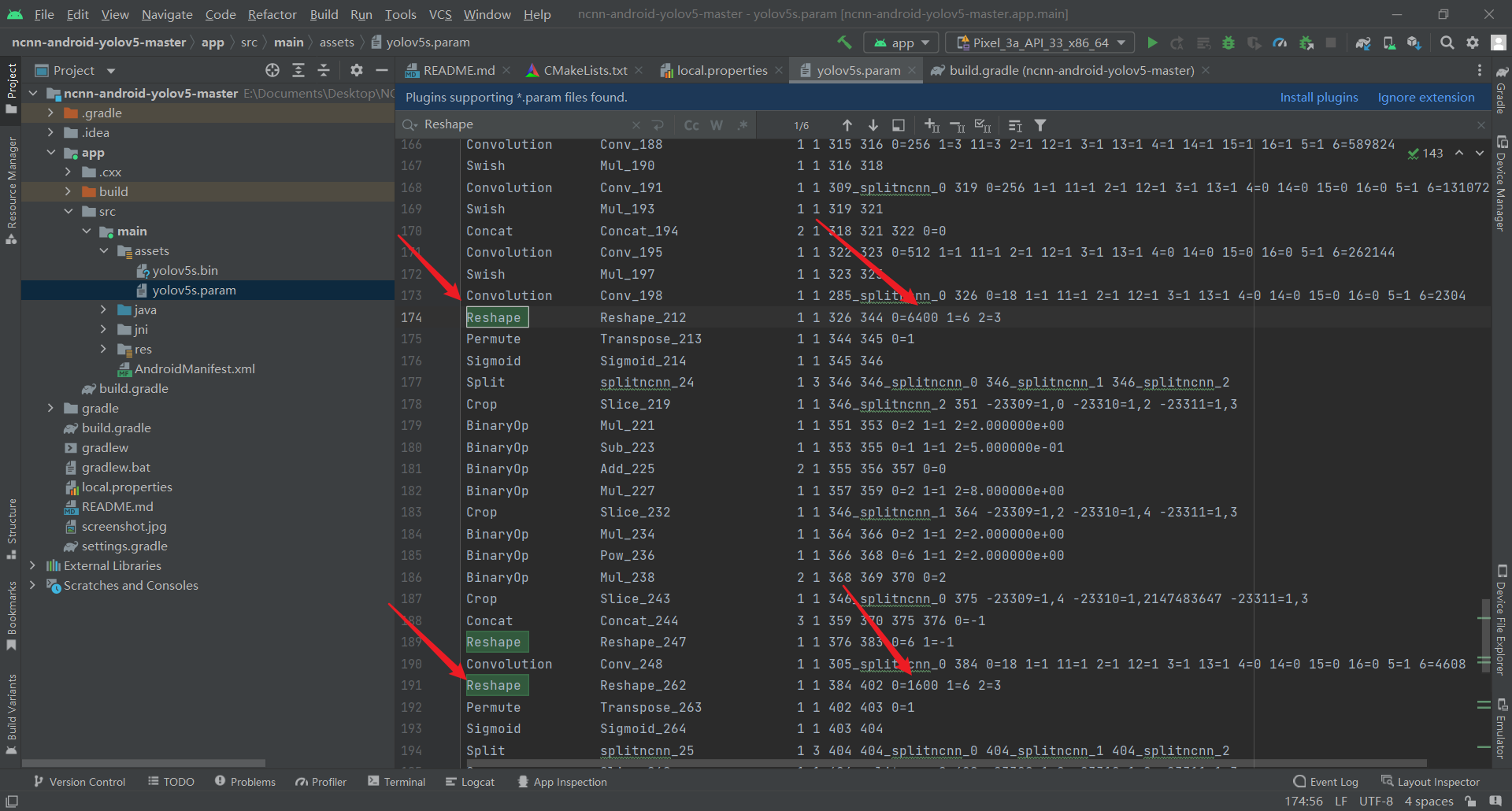
No toolchains found in the NDK toolchains folder for ABI with prefix:** arm-linux-androideabi**
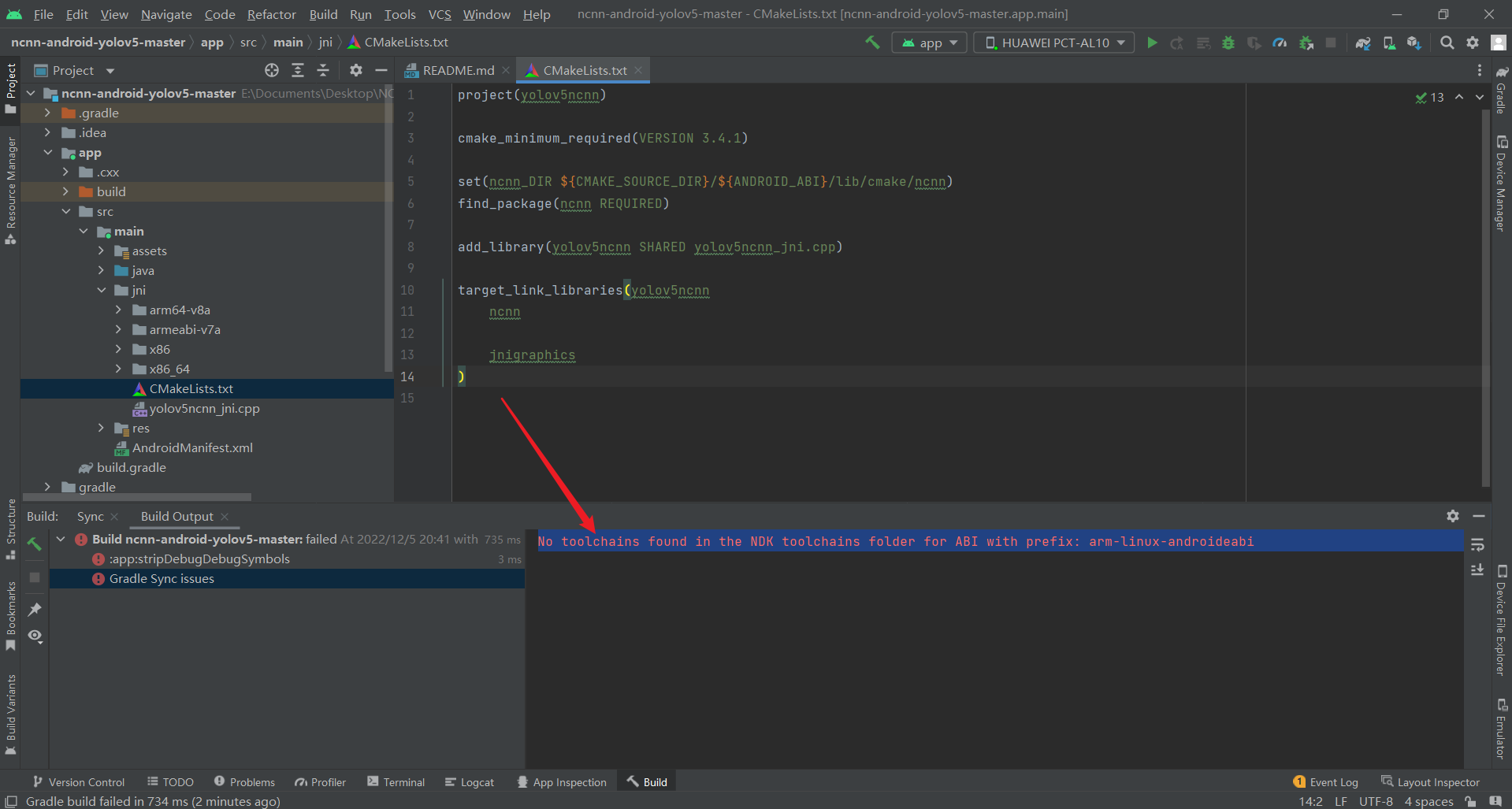
在ABI的NDK工具链文件夹中没有找到带有前缀:arm-linux-androideabi的工具链
原因分析:最新版ndk(version=25.1.8937393)的toolchains文件夹中无arm-linux-androideabi文件
解决办法
/ndk-bundle/toolchains


ndk.dir=C\:\\Users\\Lenovo\\AppData\\Local\\Android\\Sdk\\platform-tools\\ndk-bundle


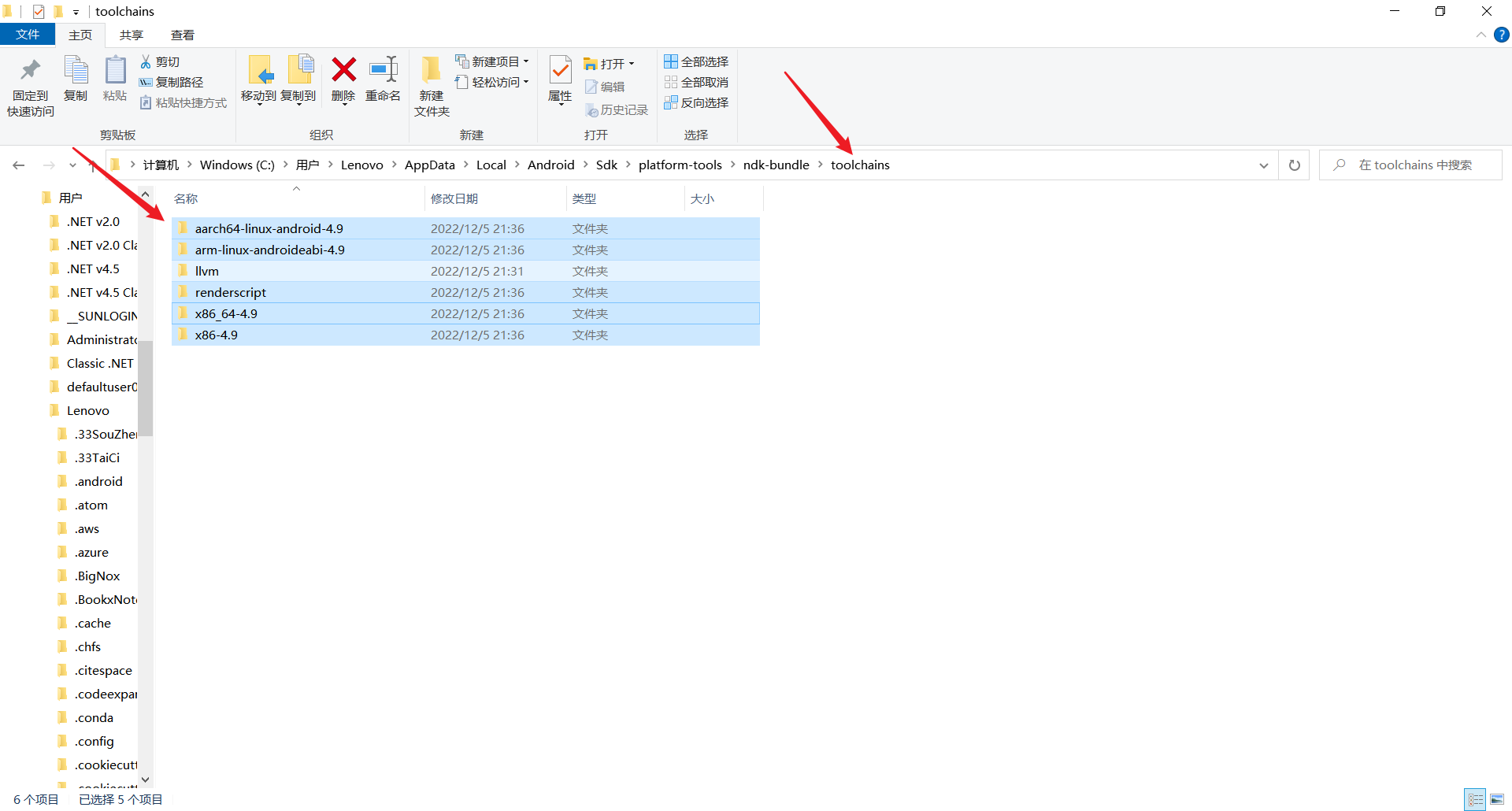
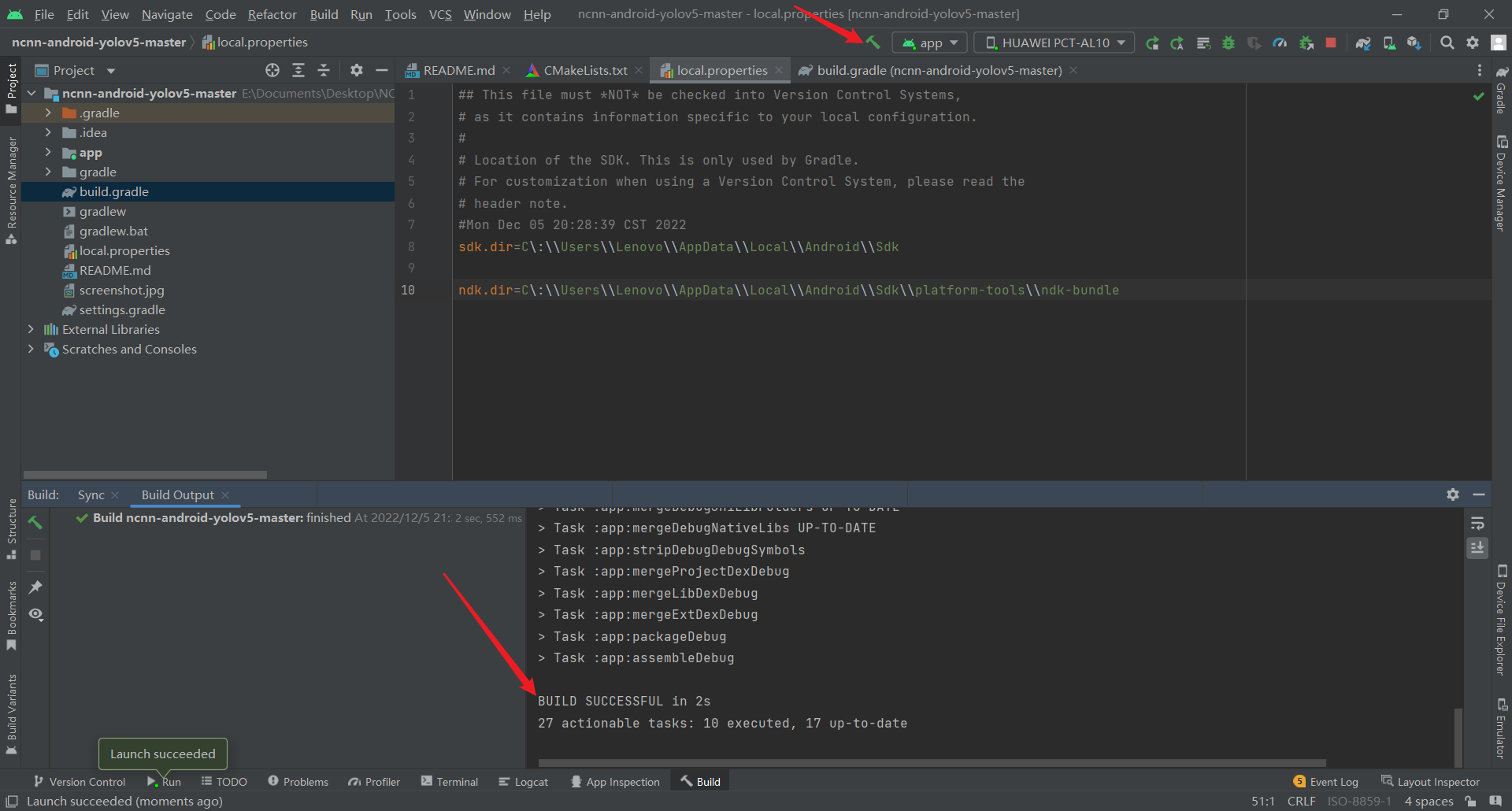
Update NDK version to 25.1.8937393 and sync project
这个很好理解嘛,也就是自己的NDK的版本太低了,下载最新版的NDK即可

Location specified by ndk.dir (C:\Users\Lenovo\AppData\Local\Android\Sdk\platform-tools\ndk-bundle) did not contain a valid NDK and and couldn’t be used
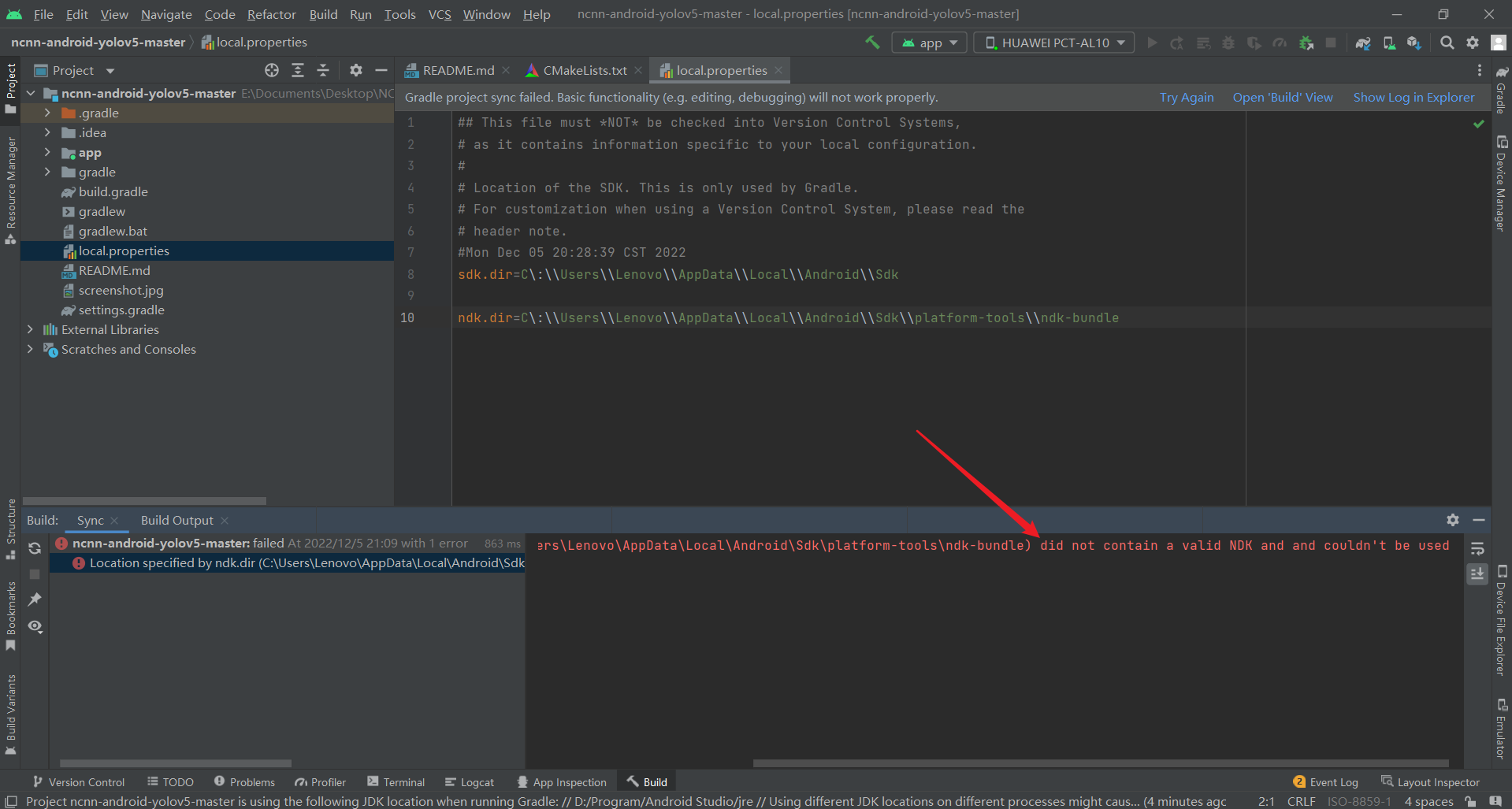
没有包含有效的NDK
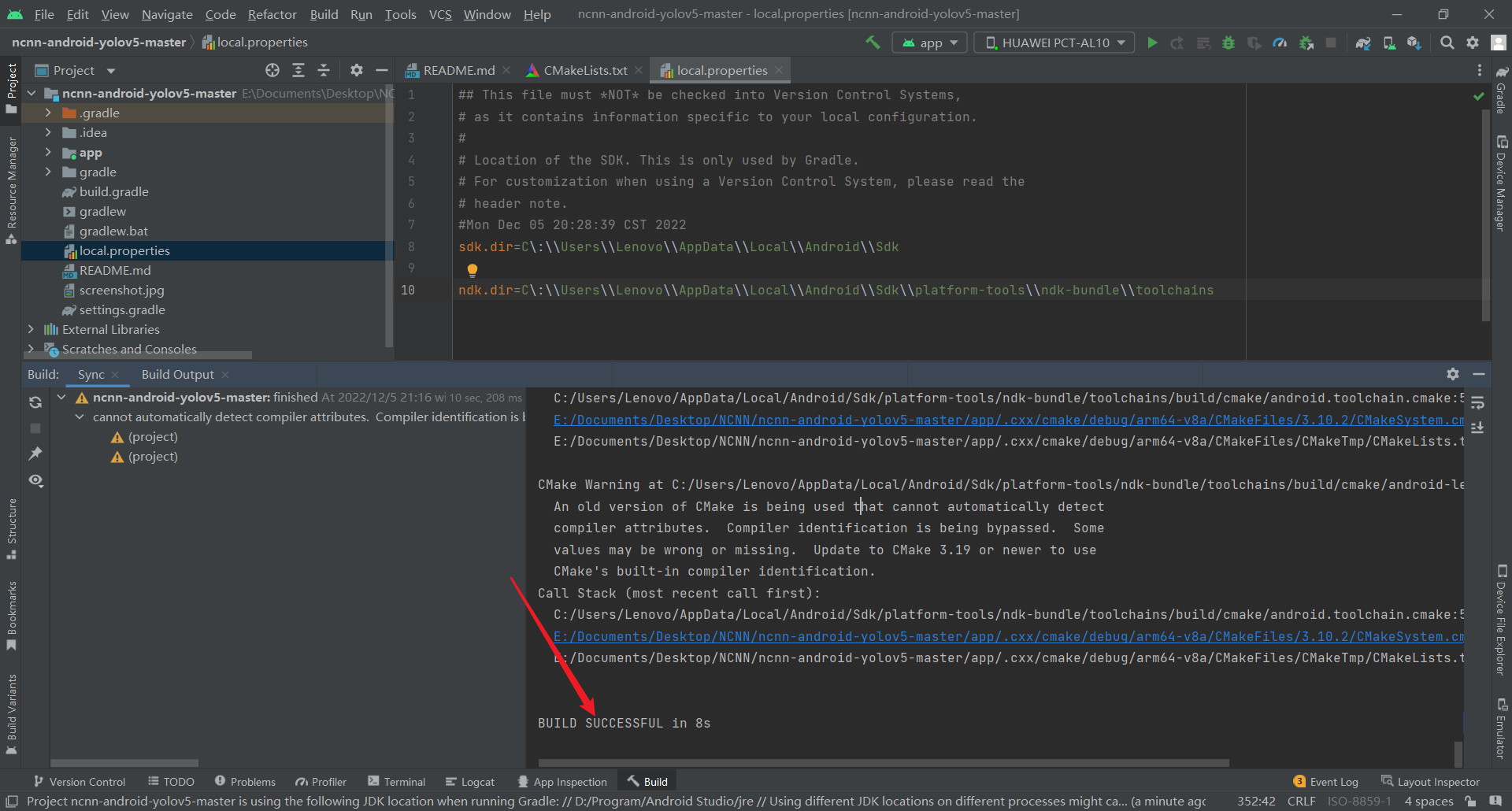
实际原因是NDK的路径不对
确保NDK的两个路径是正确的


这样之后再进行sync projec就可以正常了
OSError: [WinError 1455] 页面文件太小,无法完成操作。 #OSError
电脑上开的东西太多了,关掉一些就好了
或者设置虚拟内存

export.py --weights weights/yolov5s.pt --include torchscript onnx


git clone https://github.com/protocolbuffers/protobuf.git
cd protobuf
git submodule update --init --recursive
./autogen.sh
./configure
make
make install
sudo ldconfig
或者自己先手动把这个仓库下载下来,然后再进行安装
cd protobuf
git submodule update --init --recursive
./autogen.sh
./configure
make
make install
sudo ldconfig



sudo apt-get install autoconf automake libtool

git clone -b v3.20.1-rc1 https://github.com/protocolbuffers/protobuf.git


sudo ln -s /usr/bin/g++-5 /usr/bin/g++ -f

手机APP可以安装成功,也可以打开,但是点击识别的时候闪退

可以使用IDE调试,看一下到底报的是什么错误
A/libc: Fatal signal 11 (SIGSEGV), code 1 (SEGV_MAPERR), fault addr 0x0 in tid 28976 (cent.yolov5ncnn), pid 28976 (cent.yolov5ncnn)

这个问题,大概率还是修改Permute参数的时候不对,要相信自己,再照着前面的教程看一下,一定可以修改成功的。
此外,不要用虚拟机运行,直接用手机运行
使用自己的模型会报错,yolov5-5.0 · Issue #32 · nihui/ncnn-android-yolov5 · GitHub
不同版本的YOLOv5 修改的方式是不一样
请问如何使用自己训练和转换后的param和bin文件呢? · Issue #39 · nihui/ncnn-android-yolov5 · GitHub
YOLOv5 5.0 的修改方法参考这篇帖子
YOLOv5 6.0 的修改方法参考这篇帖子
手机APP无法通过APP文件安装

那还是通过Android Studio进行安装吧
不闪退,但是也无法识别
效果

调试yolov5ncnn_jni.cpp文件中的prob_threshold阈值,
将其改成0.01看能否出来框

如果可以出来框,那么表明就是阈值的问题,如果不能出来框的话,那就是其他地方的问题
换一张图试一下
有时候识别不出来,可能是因为图像中的物体不符合定义中的类别,再换一张图片,有可能就可以识别出来了
比如自己识别不出来这个口罩里,但是却可以识别出来这个男的


https://www.lanzoui.com/iWoBt0hzt9hi 访问码:24647
下载下来之后,需要更改一下自己的Android SDK路径
我正在学习如何使用Nokogiri,根据这段代码我遇到了一些问题:require'rubygems'require'mechanize'post_agent=WWW::Mechanize.newpost_page=post_agent.get('http://www.vbulletin.org/forum/showthread.php?t=230708')puts"\nabsolutepathwithtbodygivesnil"putspost_page.parser.xpath('/html/body/div/div/div/div/div/table/tbody/tr/td/div
我有一个Ruby程序,它使用rubyzip压缩XML文件的目录树。gem。我的问题是文件开始变得很重,我想提高压缩级别,因为压缩时间不是问题。我在rubyzipdocumentation中找不到一种为创建的ZIP文件指定压缩级别的方法。有人知道如何更改此设置吗?是否有另一个允许指定压缩级别的Ruby库? 最佳答案 这是我通过查看rubyzip内部创建的代码。level=Zlib::BEST_COMPRESSIONZip::ZipOutputStream.open(zip_file)do|zip|Dir.glob("**/*")d
类classAprivatedeffooputs:fooendpublicdefbarputs:barendprivatedefzimputs:zimendprotecteddefdibputs:dibendendA的实例a=A.new测试a.foorescueputs:faila.barrescueputs:faila.zimrescueputs:faila.dibrescueputs:faila.gazrescueputs:fail测试输出failbarfailfailfail.发送测试[:foo,:bar,:zim,:dib,:gaz].each{|m|a.send(m)resc
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
假设我做了一个模块如下:m=Module.newdoclassCendend三个问题:除了对m的引用之外,还有什么方法可以访问C和m中的其他内容?我可以在创建匿名模块后为其命名吗(就像我输入“module...”一样)?如何在使用完匿名模块后将其删除,使其定义的常量不再存在? 最佳答案 三个答案:是的,使用ObjectSpace.此代码使c引用你的类(class)C不引用m:c=nilObjectSpace.each_object{|obj|c=objif(Class===objandobj.name=~/::C$/)}当然这取决于
我正在尝试使用ruby和Savon来使用网络服务。测试服务为http://www.webservicex.net/WS/WSDetails.aspx?WSID=9&CATID=2require'rubygems'require'savon'client=Savon::Client.new"http://www.webservicex.net/stockquote.asmx?WSDL"client.get_quotedo|soap|soap.body={:symbol=>"AAPL"}end返回SOAP异常。检查soap信封,在我看来soap请求没有正确的命名空间。任何人都可以建议我
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
我有一个模型:classItem项目有一个属性“商店”基于存储的值,我希望Item对象对特定方法具有不同的行为。Rails中是否有针对此的通用设计模式?如果方法中没有大的if-else语句,这是如何干净利落地完成的? 最佳答案 通常通过Single-TableInheritance. 关于ruby-on-rails-Rails-子类化模型的设计模式是什么?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.co
我在我的项目目录中完成了compasscreate.和compassinitrails。几个问题:我已将我的.sass文件放在public/stylesheets中。这是放置它们的正确位置吗?当我运行compasswatch时,它不会自动编译这些.sass文件。我必须手动指定文件:compasswatchpublic/stylesheets/myfile.sass等。如何让它自动运行?文件ie.css、print.css和screen.css已放在stylesheets/compiled。如何在编译后不让它们重新出现的情况下删除它们?我自己编译的.sass文件编译成compiled/t
我想将html转换为纯文本。不过,我不想只删除标签,我想智能地保留尽可能多的格式。为插入换行符标签,检测段落并格式化它们等。输入非常简单,通常是格式良好的html(不是整个文档,只是一堆内容,通常没有anchor或图像)。我可以将几个正则表达式放在一起,让我达到80%,但我认为可能有一些现有的解决方案更智能。 最佳答案 首先,不要尝试为此使用正则表达式。很有可能你会想出一个脆弱/脆弱的解决方案,它会随着HTML的变化而崩溃,或者很难管理和维护。您可以使用Nokogiri快速解析HTML并提取文本:require'nokogiri'h