可以无缝地支持多个生产者,不管客户端在使用单个主题还是多个主题。
支持多个消费者从一个单独的消息流上读取数据,而且消费者之间互不影响。
支持消费者非实时地读取消息,由于消息被提交到磁盘,根据设置的规则进行保存。当消费者发生异常时候,意外离线,由于有持久化的数据保证,可以实现联机后从上次中断的地方继续处理消息。
用户在开发阶段可以先试用单个broker,再扩展到包含3个broker的小型开发集群,然后随着数据量不断增长,部署到生产环境的集群可能包含上百个broker。
Kafka可以轻松处理巨大的消息流,在处理大量数据的同事,它还能保证亚秒级的消息延迟。
kafka更好的替换传统的消息系统,消息系统被用于各种场景(解耦数据生产者,缓存未处理的消息等),与大多数消息系统比较,kafka有更好的吞吐量,内置分区,副本和故障转移,这有利于处理大规模的消息。
根据我们的经验,消息往往用于较低的吞吐量,但需要低的端到端延迟,并需要提供强大的耐用性的保证。
在这一领域的kafka比得上传统的消息系统,如ActiveMQ或RabbitMQ等。
kafka原本的使用场景是用户的活动追踪,网站的活动(网页游览,搜索或其他用户的操作信息)发布到不同的话题中心,这些消息可实时处理,实时监测,也可加载到Hadoop或离线处理数据仓库。
kafka也常常用于监测数据。分布式应用程序生成的统计数据集中聚合。
许多人使用Kafka作为日志聚合解决方案的替代品。日志聚合通常从服务器中收集物理日志文件,并将它们放在中央位置(可能是文件服务器或HDFS)进行处理。Kafka抽象出文件的细节,并将日志或事件数据更清晰地抽象为消息流。这允许更低延迟的处理并更容易支持多个数据源和分布式数据消费。
kafka中消息处理一般包含多个阶段。其中原始输入数据是从kafka主题消费的,然后汇总,丰富,或者以其他的方式处理转化为新主题,例如,一个推荐新闻文章,文章内容可能从“articles”主题获取;然后进一步处理内容,得到一个处理后的新内容,最后推荐给用户。这种处理是基于单个主题的实时数据流。从0.10.0.0开始,轻量,但功能强大的流处理,就可以这样进行数据处理了。
除了Kafka Streams,还有Apache Storm和Apache Samza可选择。
事件采集是一种应用程序的设计风格,其中状态的变化根据时间的顺序记录下来,kafka支持这种非常大的存储日志数据的场景。
kafka可以作为一种分布式的外部日志,可帮助节点之间复制数据,并作为失败的节点来恢复数据重新同步,kafka的日志压缩功能很好的支持这种用法,这种用法类似于Apacha BookKeeper项目。
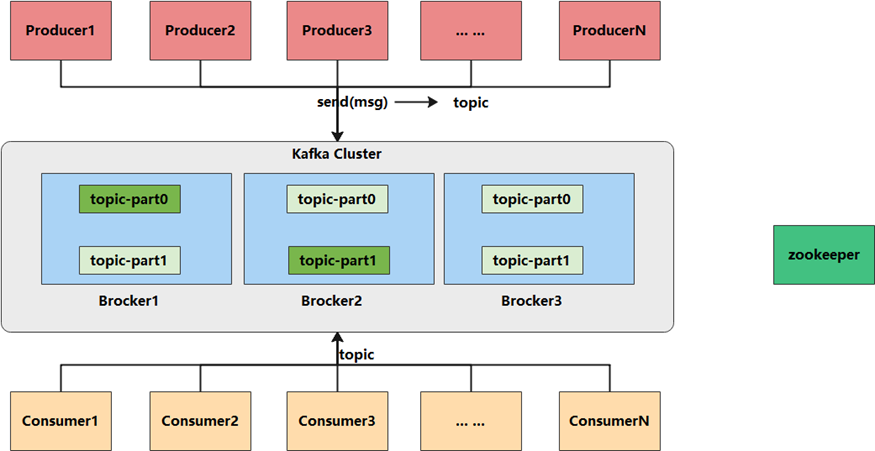
1.1 Producer产生消息,发送到Broker中
1.2 Leader状态的Broker接收消息,写入到相应topic中
1.3 Leader状态的Broker接收完毕以后,传给Follow状态的Broker作为副本备份
1.4 Consumer消费Broker中的消息
2.1 Producer:消息生产者,产生的消息将会被发送到某个topic
2.2 Consumer:消息消费者,消费的消息内容来自某个topic
2.3 Topic:消息根据topic进行归类,topic其本质是一个目录,即将同一主题消息归类到同一个目录
2.4 Broker:每一个kafka实例(或者说每台kafka服务器节点)就是一个broker,一个broker可以有多个topic
2.5 Zookeeper: Zookeeper集群不属于kafka内的组件,但kafka依赖 Zookeeper集群保存meta信息,所以在此做声明其重要性。
一个独立的Kafka服务器称为broker,broker接收来自生产者的消息,为消息设置偏移量,并提交消息到磁盘保存。broker为消费者提供服务,对读取分区的请求作出响应,返回已经提交到磁盘上的消息。根据特定的硬件及其性能特征,单个broker可以轻松处理数千个分区以及每秒百万级的消息量。
broker是集群的组成部分。每个集群都有一个broker同时充当了集群控制器的角色(自动从集群的活跃成员中选举出来)。控制器负责管理工作,包括将分区分配给broker和监控broker。在集群中,一个分区从属于一个broker,该broker被称为分区的首领。一个分区可以分配多个broker,这个时候会发生分区复制。这种复制机制为分区提供了消息冗余,如果一个broker失效,其他broker可以接管领导权。不过,相关的消费者和生产者都要重新连接到新的首领。
kafka只支持Topic
• 每个group中可以有多个consumer,每个consumer属于一个consumer group;通常情况下,一个group中会包含多个consumer,这样不仅可以提高topic中消息的并发消费能力,而且还能提高”故障容错”性,如果group中的某个consumer失效那么其消费的partitions将会由其它consumer自动接管。
• 对于Topic中的一条特定的消息,只会被订阅此Topic的每个group中的其中一个consumer消费,此消息不会发送给一个group的多个consumer;那么一个group中所有的consumer将会交错的消费整个Topic,每个group中consumer消息消费互相独立,我们可以认为一个group是一个”订阅”者。
• 在kafka中,一个partition中的消息只会被group中的一个consumer消费(同一时刻);
一个Topic中的每个partions,只会被一个”订阅者”中的一个consumer消费,不过一个consumer可以同时消费多个partitions中的消息。
• kafka的设计原理决定,对于一个topic,同一个group中不能有多于partitions个数的consumer同时消费,否则将意味着某些consumer将无法得到消息,而处于空闲状态。
kafka只能保证一个partition中的消息被某个consumer消费时是顺序的;事实上,从Topic角度来说,当有多个partitions时,****消息仍不是全局有序的。
• Producer客户端负责消息的分发
• kafka集群中的任何一个broker都可以向producer提供metadata信息,这些metadata中包含”集群中存活的servers列表”、“partitions leader**列表”等信息;
• 当producer获取到metadata信息之后, producer将会和Topic下所有partition leader保持socket连接;
• 消息由producer直接通过socket发送到broker,中间不会经过任何”路由层”。事实上,消息被路由到哪个partition上由producer客户端决定,比如可以采用”random””key-hash””轮询”等。
• 如果一个topic中有多个partitions,那么在producer端实现”消息均衡分发”**是必要的。
• 在producer端的配置文件中,开发者可以指定partition路由的方式。
• Producer消息发送的应答机制
设置发送数据是否需要服务端的反馈,有三个值0,1,-1
0: producer不会等待broker发送ack
1: 当leader接收到消息之后发送ack
2: 当所有的follower都同步消息成功后发送ack
request.required.acks=0
当一个group中,有consumer加入或者离开时,会触发partitions均衡.均衡的最终目的,是提升topic的并发消费能力,步骤如下:
假如topic1,具有如下partitions: P0,P1,P2,P3
加入group A 中,有如下consumer: C0,C1
首先根据partition索引号对partitions排序: P0,P1,P2,P3
根据consumer.id排序: C0,C1
计算倍数: M = [P0,P1,P2,P3].size / [C0,C1].size,本例值M=2(向上取整)
然后依次分配partitions: C0 = [P0,P1],C1=[P2,P3],即Ci = [P(i * M),P((i + 1) * M -1)]
本文由
传智教育博学谷教研团队发布。如果本文对您有帮助,欢迎
关注和点赞;如果您有任何建议也可留言评论或私信,您的支持是我坚持创作的动力。转载请注明出处!
假设我有模型Topics和Posts,其中Topichas_many:posts和Postbelongs_to:topic。此时我的数据库中已经有了一些东西。如果我进入Rails控制台并输入Topic.find(1).posts我相信我得到了一个CollectionProxy对象。=>#]>我可以对此调用.each以获得枚举器对象。=>#]:each>我对CollectionProxy如何处理.each感到困惑。我意识到它在某些时候是继承的,但我一直在阅读API文档,他们并没有说得很清楚CollectionProxy是从什么继承的,除非我遗漏了一些明显的东西。Thispage似乎并没有
我以为它们存储在cookie中-但不,检查cookie没有任何结果。session也不存储它们。那么,我在哪里可以找到它们?我需要这个来直接设置它们(而不是通过flashhash)。 最佳答案 它们存储在inyoursessionstore.自rails2.0以来的默认设置是cookie存储,但请检查config/initializers/session_store.rb以检查您是否使用默认设置以外的东西。 关于ruby-on-rails-闪存消息存储在哪里?,我们在StackOverf
这里还有一个新手问题:require'tasks/rails'我在每个Rails项目的根路径中的Rakefile中看到了这一行。我猜这行用于要求vendor/rails/railties/lib/tasks/rails.rb加载所有rake任务:$VERBOSE=nil#LoadRailsrakefileextensionsDir["#{File.dirname(__FILE__)}/*.rake"].each{|ext|loadext}#LoadanycustomrakefileextensionsDir["#{RAILS_ROOT}/lib/tasks/**/*.rake"].so
当你安装一个新包时,例如,'geminstallfb-graph',文件下载到哪里了? 最佳答案 使用此命令查找特定gem的安装位置:gemwhich例如:gemwhichfb-graph 关于ruby-on-rails-Rubygems-包在哪里下载?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/13200065/
在Rails中向整数类添加方法的最佳位置在哪里?我想添加一个to_meters和to_miles方法。 最佳答案 如果您决心使用数字(或整数等)类来进行单位转换,那么至少要在逻辑上做到这一点,并具有一些实际值(value)。首先,创建一个Unit类,用于存储单位类型(米、英尺、肘等)和创建时的值。然后向Numeric添加一堆方法,这些方法对应于单元可以具有的有效值:这些方法将返回一个单元对象,其类型记录为方法名称。Unit类将支持一组to_*方法,这些方法将转换为具有相应单位值的另一种单位类型。这样,您可以执行以下命令:>>x=47
我有时遇到过Array(value)、String(value)和Integer(value)形式的转换。在我看来,这些只是调用相应的value.to_a、value.to_s或value.to_i方法的语法糖。所以我想知道:这些是在哪里/如何定义的?我在对象、模块、类等中找不到它们是否有任何常见场景更适合使用这些而不是相应/底层的to_X方法?这些可以用于泛型强制转换吗?也就是说,我可以按照[Integer,String,Array].each{|klass|klass.do_generic_coercion(foo)}?(...不,我真的不想那样做;我知道我想要的类型,但我希望避免
这个问题说明了一切。例如,我有一台安装了ruby1.8.6的服务器。当我尝试sudogeminstallroo时,它给出了错误nokogirirequiresRubyversion>=1.8.7。所以,我想安装与Ruby1.8.6兼容的旧版本roo。但我不知道去哪里搜索。我知道RubyForge,但它也没有说明Ruby的兼容版本。 最佳答案 蛮力方法是获取一个git克隆,搜索它指定的Ruby版本的位置,然后使用gitblame甚至gitpickaxe来确定最后一个没有的版本'没有那个要求。
我有几个类仅由rake任务使用。我意识到rake任务通常存在于@lib/tasks/whatever.rake但我应该在哪里放置支持类?谢谢! 最佳答案 $RAILS_ROOT/lib或$RAILS_ROOT/lib/special_task/可能是最好的,因为它在默认加载路径中,您可以做一个简单的分别需要'my_task_helper'或require'special_task/helper'。 关于ruby-on-rails-RakeTask特定类(class)在哪里生活?(rail
我正在构建一个应该输出日志文件的rubygem。将日志文件存储在哪里是一个好习惯?我正在从我正在构建的Rails网站中提取此功能,我可以在那里简单地登录到log/目录。 最佳答案 理想情况下,使路径可配置(.rc文件、交换机、rails/rack配置等)。如果它是一个Rack中间件,添加在构造函数的参数中指定它的可能性。如果没有提供日志路径,回退到检测日志目录。(我依稀记得它是Rails中的config.paths['log'],但如果可以的话,请确保config在你的gem中使用之前确实指向某些东西在Rails之外使用。)如果
我发现许多Rails应用程序主要针对企业、社交网络类型的Web应用程序。我看到有人将Ruby与一些出色的OOPS语言(如Java和C#)进行了比较,但我确实发现很难获得一些数学密集型应用程序。非常感谢任何知识渊博的输入(指向示例程序的链接等),其中轻松显示了语言的用法,就像快速启动或显示该语言如何用于各种数学问题一样。 最佳答案 不幸的是,Ruby并没有在数学和科学计算领域涉足太多。目前,有一个名为SciRuby的pre-alpha库它试图为Ruby带来更多面向数学的功能。他们正试图构建一个NumPy/SciPy等价物。SciRub