I/O 的概念,从字义来理解就是输入输出。操作系统从上层到底层,各个层次之间均存在 I/O。比如,CPU 有 I/O,内存有 I/O, VMM 有 I/O, 底层磁盘上也有 I/O,这是广义上的 I/O。通常来讲,一个上层的 I/O 可能会产生针对磁盘的多个 I/O,也就是说,上层的 I/O 是稀疏的,下层的 I/O 是密集的。
磁盘的 I/O,顾名思义就是磁盘的输入输出。输入指的是对磁盘写入数据,输出指的是从磁盘读出数据。我们常见的磁盘类型有 ATA、SATA、FC、SCSI、SAS,如图1所示。这几种磁盘中,服务器常用的是 SAS 和 FC 磁盘,一些高端存储也使用 SSD 盘。每一种磁盘的性能是不一样的。

SAN(Storage Area Network, 存储区域网络)和NAS存储(Network Attached Storage,网络附加存储)一般都具备2个评价指标:IOPS和带宽(throughput),两个指标互相独立又相互关联。体现存储系统性能的最主要指标是IOPS。下面,将介绍一下这两个参数的含义。
IOPS (Input/Output Per Second)即每秒的输入输出量(或读写次数),是衡量磁盘性能的主要指标之一。IOPS是指单位时间内系统能处理的I/O请求数量,I/O请求通常为读或写数据操作请求。
随机读写频繁的应用,如OLTP(Online Transaction Processing),IOPS是关键衡量指标。
什么是 OLTP ?
OLTP 也称为面向交易的处理过程,其基本特征是前台接收的用户数据可以立即传送到计算中心进行处理,并在很短的时间内给出处理结果,是对用户操作快速响应的方式之一。
特征:
支持大量并发,实时性要求很高,交易确定性,并发性要求高并且严格的要求事务的完整、安全性。
另一个重要指标是数据吞吐量(Throughput),指单位时间内可以成功传输的数据数量。对于大量顺序读写的应用,如VOD(Video On Demand),则更关注吞吐量指标。
简而言之:
磁盘的 IOPS,也就是在一秒内,磁盘进行多少次 I/O 读写。
磁盘的吞吐量,也就是每秒磁盘 I/O 的流量,即磁盘写入加上读出的数据的大小。
在知乎上看到对 吞吐量的理解:
所谓“吞”就是吃进去,“吐”就是吐出来,这一进一出就是吞吐量。比如,一秒吃进去1M bit位,同时又吐出1M bit 位,那么吞吐量 = 1M bit / 秒。不是很明白这里为什么要除以2 ?
IOPS 与吞吐量的关系
每秒 I/O 吞吐量= IOPS* 平均 I/O SIZE。
IOPS可细分为如下几个指标:
Toatal IOPS,混合读写和顺序随机I``/O``负载情况下的磁盘IOPS,这个与实际I``/O``情况最为相符,大多数应用关注此指标。``Random Read IOPS,100%随机读负载情况下的IOPS。``Random Write IOPS,100%随机写负载情况下的IOPS。``Sequential Read IOPS,100%顺序读负载情况下的IOPS。``Sequential Write IOPS,100%顺序写负载情况下的IOPS。
IOPS 计算公式
对于磁盘来说一个完整的IO操作是这样进行的:
当控制器对磁盘发出一个IO操作命令的时候,磁盘的驱动臂(Actuator Arm)带读写磁头(Head)离开着陆区(Landing Zone,位于内圈没有数据的区域),移动到要操作的初始数据块所在的磁道(Track)的正上方,这个过程被称为寻址(Seeking),对应消耗的时间被称为寻址时间(Seek Time);
但是找到对应磁道还不能马上读取数据,这时候磁头要等到磁盘盘片(Platter)旋转到初始数据块所在的扇区(Sector)落在读写磁头正上方的之后才能开始读取数据,在这个等待盘片旋转到可操作扇区的过程中消耗的时间称为旋转延时(Rotational Delay);
接下来就随着盘片的旋转,磁头不断的读/写相应的数据块,直到完成这次IO所需要操作的全部数据,这个过程称为数据传送(Data Transfer),对应的时间称为传送时间(Transfer Time)。完成这三个步骤之后一次IO操作也就完成了。
寻址时间:考虑到被读写的数据可能在磁盘的任意一个磁道,既有可能在磁盘的最内圈(寻址时间最短),也可能在磁盘的最外圈(寻址时间最长),所以在计算中我们只考虑平均寻址时间,也就是磁盘参数中标明的那个平均寻址时间,这里就采用当前最多的10k rpm 硬盘的5ms。
旋转延时:和寻址一样,当磁头定位到磁道之后有可能正好在要读写扇区之上,这时候是不需要额外额延时就可以立刻读写到数据,但是最坏的情况确实要磁盘旋转整整一圈之后磁头才能读取到数据,所以这里我们也考虑的是平均旋转延时,对于10krpm的磁盘就是(60s/10k)*(1/2) = 2ms。
传送时间:磁盘参数提供我们的最大的传输速度,当然要达到这种速度是很有难度的,但是这个速度却是磁盘纯读写磁盘的速度,因此只要给定了单次 IO的大小,我们就知道磁盘需要花费多少时间在数据传送上,这个时间就是IO Chunk Size / Max Transfer Rate。
随机读写频繁的应用,如小文件存储(图片)、OLTP数据库、邮件服务器,关注随机读写性能,IOPS是关键衡量指标。
顺序读写频繁的应用,传输大量连续数据,如电视台的视频编辑,视频点播VOD(Video On Demand),关注连续读写性能。数据吞吐量是关键衡量指标。
IOPS和数据吞吐量适用于不同的场合:
读取10000个1KB文件,用时10秒 Throught(吞吐量)=1MB/s ,IOPS=1000 追求IOPS。
读取1个10MB文件,用时0.2秒 Throught(吞吐量)=50MB/s, IOPS=5 追求吞吐量。
个人理解:
如果要测试 IOPS 就需要定义小的 I/O size,如果要测试 吞吐量 则需要定义稍大的 I/O size,主要还是根据读写磁盘数据的大小而定。
常见磁盘平均物理寻道时间为:
7200转/分的STAT硬盘平均物理寻道时间是9ms``10000转/分的STAT硬盘平均物理寻道时间是6ms``15000转/分的SAS硬盘平均物理寻道时间是4ms
常见硬盘的旋转延迟时间为:
7200 rpm的磁盘平均旋转延迟大约为60*1000``/7200/2` `= 4.17ms``10000 rpm的磁盘平均旋转延迟大约为60*1000``/10000/2` `= 3ms,``15000 rpm的磁盘其平均旋转延迟约为60*1000``/15000/2` `= 2ms。
最大IOPS的理论计算方法:
IOPS = 1000 ms/ (寻道时间 + 旋转延迟)。可以忽略数据传输时间。``7200 rpm的磁盘IOPS = 1000 / (9 + 4.17) = 76 IOPS``10000 rpm的磁盘IOPS = 1000 / (6+ 3) = 111 IOPS``15000 rpm的磁盘IOPS = 1000 / (4 + 2) = 166 IOPS
影响测试的因素
实际测量中,IOPS数值会受到很多因素的影响,包括I/O负载特征(读写比例,顺序和随机,工作线程数,队列深度,数据记录大小)、系统配置、操作系统、磁盘驱动等等。因此对比测量磁盘IOPS时,必须在同样的测试基准下进行,即便如此也会产生一定的随机不确定性。
大多数的软件都是属于同步I/O软件,也就是说程序的一次I/O要等到上次I/O操作的完成后才进行,这样在硬盘中同时可能仅只有一个命令,也是无法发挥这个技术的优势,这时队列深度为1。
随着Intel的超线程技术的普及和应用环境的多任务化,以及异步I/O软件的大量涌现。这项技术可以被应用到了,实际队列深度的增加代表着性能的提高。
在测试时,队列深度为1是主要指标,大多数时候都参考1就可以。实际运行时队列深度也一般不会超过4.
IOPS可细分为如下几个指标:
数据量为n字节,队列深度为k时,随机读取的IOPS
数据量为n字节,队列深度为k时,随机写入的IOPS
由于条件有限,我这里就只能找到两个U 盘来进行测试, 主要是演示测试方式。
测试前提:
我们在进行测试时,都会分清楚
测试对象:要区分硬盘、SSD、RAID、SAN、云硬盘等,因为它们有不同的特点 测试指标:IOPS和MBPS(吞吐率),下面会具体阐述 测试工具:Linux下常用Fio、dd工具, Windows下常用IOMeter, 测试参数: IO大小,寻址空间,队列深度,读写模式,随机/顺序模式 测试方法:也就是测试步骤。
测试是为了对比,所以需要定性和定量。在宣布自己的测试结果时,需要说明这次测试的工具、参数、方法,以便于比较。
本次测试是采用vmware 虚拟磁盘 和 两块U 盘,测试工具为 dd 命令 和 fio
vmware 虚拟机 配合 u 盘进行测试:
第一块 U盘 设备为 ``/dev/sdf` `Apr 24 15:12:04 localhost kernel: usb 1-1: new high-speed USB device number 4 using ehci-pci``Apr 24 15:12:04 localhost kernel: usb 1-1: New USB device found, idVendor=058f, idProduct=6387, bcdDevice= 1.06``Apr 24 15:12:04 localhost kernel: usb 1-1: New USB device ``strings``: Mfr=1, Product=2, SerialNumber=3``Apr 24 15:12:04 localhost kernel: usb 1-1: Product: Mass Storage``Apr 24 15:12:04 localhost kernel: usb 1-1: Manufacturer: Generic``Apr 24 15:12:04 localhost kernel: usb 1-1: SerialNumber: BAAF2066``Apr 24 15:12:04 localhost kernel: usb-storage 1-1:1.0: USB Mass Storage device detected``Apr 24 15:12:04 localhost kernel: scsi host5: usb-storage 1-1:1.0``Apr 24 15:12:05 localhost kernel: scsi 5:0:0:0: Direct-Access Generic Flash Disk 8.07 PQ: 0 ANSI: 4``Apr 24 15:12:05 localhost kernel: sd 5:0:0:0: Attached scsi generic sg6 ``type` `0``Apr 24 15:12:05 localhost kernel: sd 5:0:0:0: [sdf] 15728640 512-byte logical blocks: (8.05 GB``/7``.50 GiB)``Apr 24 15:12:05 localhost kernel: sd 5:0:0:0: [sdf] Write Protect is off``Apr 24 15:12:05 localhost kernel: sd 5:0:0:0: [sdf] Write cache: disabled, ``read` `cache: enabled, doesn't support DPO or FUA``Apr 24 15:12:05 localhost kernel: sd 5:0:0:0: [sdf] Attached SCSI removable disk` `第二块 U盘 设备为 ``/dev/sdg` `Apr 24 15:12:30 localhost kernel: usb 1-2: new high-speed USB device number 5 using ehci-pci``Apr 24 15:12:31 localhost kernel: usb 1-2: New USB device found, idVendor=0951, idProduct=1666, bcdDevice= 1.10``Apr 24 15:12:31 localhost kernel: usb 1-2: New USB device ``strings``: Mfr=1, Product=2, SerialNumber=3``Apr 24 15:12:31 localhost kernel: usb 1-2: Product: DataTraveler 3.0``Apr 24 15:12:31 localhost kernel: usb 1-2: Manufacturer: Kingston``Apr 24 15:12:31 localhost kernel: usb 1-2: SerialNumber: 0015F284C2ADB031E955D50B``Apr 24 15:12:31 localhost kernel: usb-storage 1-2:1.0: USB Mass Storage device detected``Apr 24 15:12:31 localhost kernel: scsi host6: usb-storage 1-2:1.0``Apr 24 15:12:32 localhost kernel: scsi 6:0:0:0: Direct-Access Kingston DataTraveler 3.0 PMAP PQ: 0 ANSI: 6``Apr 24 15:12:32 localhost kernel: sd 6:0:0:0: Attached scsi generic sg7 ``type` `0``Apr 24 15:12:32 localhost kernel: sd 6:0:0:0: [sdg] 30277632 512-byte logical blocks: (15.5 GB``/14``.4 GiB)``Apr 24 15:12:32 localhost kernel: sd 6:0:0:0: [sdg] Write Protect is off``Apr 24 15:12:32 localhost kernel: sd 6:0:0:0: [sdg] Write cache: disabled, ``read` `cache: enabled, doesn't support DPO or FUA``Apr 24 15:12:32 localhost kernel: sd 6:0:0:0: [sdg] Attached SCSI removable disk` `第三块 虚拟磁盘设备为 ``/dev/sdb` `sdb 8:16 0 2T 0 disk
顺序读
工具:fio
测试命令:fio -name iops -rw=``read` `-bs=4k -runtime=10 -iodepth 1 -filename ``/dev/sdb` `-ioengine libaio -direct=1` `【第一块 U盘 ``/dev/sdf``】``read``: IOPS=316, BW=1267KiB``/s``【第二块 U盘 ``/dev/sdg``】``read``: IOPS=310, BW=1242KiB``/s``【第三块 盘 ``/dev/sdb``】``read``: IOPS=8274, BW=32.3MiB``/s
在对 4KB 数据包进行顺序读的情况下:
1 号U盘速度为 1.2MB/s,IOPS 为 316
2 号U盘速度为 1.2MB/S,IOPS 为 310
3 号虚拟磁盘为 32.3MB/S,IOPS 为 8274
结论:
在顺序读的测试下, U盘读取4K 以内的小文件,简直让人心疼。
随机读
工具:fio
测试命令:fio -name iops -rw=randread -bs=4k -runtime=10 -iodepth 1 -filename ``/dev/sdf` `-ioengine libaio -direct=1` `【第一块 U盘 ``/dev/sdf``】``read``: IOPS=195, BW=782KiB``/s``【第二块 U盘 ``/dev/sdg``】``read``: IOPS=317, BW=1270KiB``/s``【第三块 盘 ``/dev/sdb``】``read``: IOPS=6342, BW=24.8MiB``/s
在对 4KB 数据包进行随机读的情况下:
1 号U盘速度为 782KB/s,IOPS 为 195
2 号U盘速度为 1.3MB/S,IOPS 为 317
3 号虚拟磁盘为 24.8MB/S,IOPS 为 6342
结论:
在随机读的测试下,2号U盘性能超越了1号U盘,虚拟磁盘依然碾压。
顺序写
工具:fio
测试命令:fio -name iops -rw=write -bs=4k -runtime=10 -iodepth 1 -filename ``/dev/sdf` `-ioengine libaio -direct=1` `【第一块 U盘 ``/dev/sdf``】write: IOPS=119, BW=476KiB``/s``【第二块 U盘 ``/dev/sdg``】write: IOPS=284, BW=1138KiB``/s``【第三块 盘 ``/dev/sdb``】write: IOPS=9065, BW=35.4MiB``/s
在对 4KB 数据包进行顺序写的情况下:
1 号U盘速度为 476KB/s,IOPS 为 119
2 号U盘速度为 1.1MB/S,IOPS 为 284
3 号虚拟磁盘为 35.4MB/S,IOPS 为 9065
结论:
在顺序写的测试下,2号U盘脱颖而出,超越了第一块U盘有3倍,虚拟磁盘依然遥遥领先。
随机写
工具:fio
测试命令:fio -name iops -rw=randwrite -bs=4k -runtime=10 -iodepth 1 -filename ``/dev/sdf` `-ioengine libaio -direct=1` `【第一块 U盘 ``/dev/sdf``】write: IOPS=1, BW=7069B``/s``【第二块 U盘 ``/dev/sdg``】write: IOPS=164, BW=657KiB``/s``【第三块 盘 ``/dev/sdb``】write: IOPS=348, BW=1396KiB``/s
在对 4KB 数据包进行随机写的情况下:
1 号U盘速度为 7KB/s,IOPS 为 1
2 号U盘速度为 657KB/S,IOPS 为 164
3 号虚拟磁盘为 1396MB/S,IOPS 为 348
结论:
在随机写的测试下, 1号 U盘是被玩坏了吗? 2号U盘性能也是差强人意,毕竟是U盘,而3号虚拟磁盘的性能还是能够接受的。
顺序混合读写
工具:fio
测试命令:fio -name iops -rw=rw -bs=4k -runtime=10 -iodepth 1 -filename ``/dev/sdf` `-ioengine libaio -direct=1` `【第一块 U盘 ``/dev/sdf``】``read``: IOPS=55, BW=221KiB``/s` `write: IOPS=59, BW=240KiB``/s``【第二块 U盘 ``/dev/sdg``】``read``: IOPS=153, BW=612KiB``/s` `write: IOPS=160, BW=644KiB``/s``【第三块 盘 ``/dev/sdb``】``read``: IOPS=4426, BW=17.3MiB``/s` ` write: IOPS=4397, BW=17.2MiB``/s
在对 4KB 数据包进行顺序混合读写的情况下:
1 号U盘顺序读:IOPS=55, 吞吐量为:221KiB/s 顺序写 IOPS=59, 吞吐量为:240KiB/s
2 号U盘顺序读:IOPS=153, 吞吐量为:612KiB/s 顺序写 IOPS=160, 吞吐量为:644KiB/s
3 号虚拟磁盘读: IOPS=4426, 吞吐量为:17.3MiB/s 顺序写 IOPS=4397, 吞吐量为:17.2MiB/s
结论:
在顺序混合读写的测试下,性能对比排名:虚拟磁盘 > 2号U盘 > 1号U盘
随机混合读写
工具:fio
测试命令:fio -name iops -rw=randrw -bs=4k -runtime=10 -iodepth 1 -filename ``/dev/sdf` `-ioengine libaio -direct=1` `【第一块 U盘 ``/dev/sdf``】``read``: IOPS=88, BW=352KiB``/s` `write: IOPS=92, BW=369KiB``/s``【第二块 U盘 ``/dev/sdg``】``read``: IOPS=151, BW=608KiB``/s` `write: IOPS=159, BW=637KiB``/s``【第三块 盘 ``/dev/sdb``】``read``: IOPS=4586, BW=17.9MiB``/s` `write: IOPS=4558, BW=17.8MiB``/s
在对 4KB 数据包进行随机混合读写的情况下:
1 号U盘顺序读:IOPS=88, 吞吐量为:352KiB/s 顺序写 IOPS=92, 吞吐量为:369KiB/s
2 号U盘顺序读:IOPS=151, 吞吐量为:608KiB/s 顺序写 IOPS=159, 吞吐量为:637KiB/s
3 号虚拟磁盘读: IOPS=4586, 吞吐量为:17.9MiB/s 顺序写 IOPS=4558, 吞吐量为:17.8MiB/s
结论:
在顺序混合读写的测试下,性能对比排名:虚拟磁盘 > 2号U盘 > 1号U盘
总结:
以上测试,是根据 I/O SIZE = 4k 来进行测试的,对于小文件,应该重点关注的是磁盘的 IOPS 性能。抛开虚拟磁盘不说,两块U盘的IOPS 和 吞吐量已经非常清晰了,孰强孰弱也很容易分辨出来。
存储系统模型 为了更好的测试,我们需要先了解存储系统,块存储系统本质是一个排队模型,我们可以拿银行作为比喻。还记得你去银行办事时的流程吗?
去前台取单号
等待排在你之前的人办完业务
轮到你去某个柜台
柜台职员帮你办完手续1
柜台职员帮你办完手续2
柜台职员帮你办完手续3
办完业务,从柜台离开
如何评估银行的效率呢:
增加柜台数
降低服务时间
因此,排队系统或存储系统的优化方法是:
增加并行度
降低服务时间
在服务器中,这种模型是很常见的,比如web服务器。
硬盘测试
硬盘原理
我们应该如何测试SATA/SAS硬盘呢?
每个硬盘都有一个磁头(相当于银行的柜台),硬盘的工作方式是:
收到IO请求,得到地址和数据大小
移动磁头(寻址)
找到相应的磁道(寻址)
读取数据
传输数据
则磁盘的随机IO服务时间:
服务时间 = 寻道时间 + 旋转时间 + 传输时间
对于10000转速的SATA硬盘来说,一般寻道时间是7 ms,旋转时间是3 ms, 64KB的传输时间是 0.8 ms, 则SATA硬盘每秒可以进行随机IO操作是 1000/(7 + 3 + 0.8) = 93,所以我们估算SATA硬盘64KB随机写的IOPS是93。
我们在列出IOPS时,需要说明IO大小,寻址空间,读写模式,顺序/随机,队列深度。我们一般常用的IO大小是4KB,这是因为文件系统常用的块大小是4KB。
使用 dd 测试硬盘
虽然硬盘的性能是可以估算出来的,但是怎么才能让应用获得这些性能呢?对于测试工具来说,就是如何得到IOPS和MBPS峰值。我们先用dd测试一下磁盘的MBPS(吞吐量)。
dd测试
# dd if=/dev/zero of=/dev/sdb bs=4k count=100000 oflag=direct``100000+0 records ``in``100000+0 records out``409600000 bytes (410 MB) copied, 7.13428 s, 57.4 MB``/s
iostat 查看磁盘性能
执行命令:iostat -dxk ``/dev/sdb` `1``Device: rrqm``/s` `wrqm``/s` `r``/s` `w``/s` `rkB``/s` `wkB``/s` `avgrq-sz avgqu-sz await r_await w_await svctm %util``sdb 0.00 0.00 0.00 14264.00 0.00 57056.00 8.00 0.82 0.06 0.00 0.06 0.06 82.10
本次测试使用的是虚拟磁盘,使用 dd 测试这块虚拟磁盘的 MBPS 只有 57.4MB/S,通过 iostat 查看磁盘状态,发现磁盘利用率只有 82.10% 并没有达到 95% 以上,还有部分是空闲的。当 dd 在前一个 IO 响应之后,在准备发起下一个IO时,SATA 硬盘是空闲的。那么如何才能提高利用率,让磁盘不空闲呢?只有一个办法,那就是增加硬盘的队列深度。相对于CPU来说,硬盘属于慢速设备,所有操作系统会有给每个硬盘分配一个专门的队列用于缓冲IO请求。
什么是磁盘的队列深度?
在某个时刻,有N个inflight的IO请求,包括在队列中的IO请求、磁盘正在处理的IO请求。N就是队列深度。
加大硬盘队列深度就是让硬盘不断工作,减少硬盘的空闲时间。
加大队列深度 -> 提高利用率 -> 获得IOPS和MBPS峰值 -> 注意响应时间在可接受的范围内
增加队列深度的办法有很多:
使用异步IO,同时发起多个IO请求,相当于队列中有多个IO请求;
多线程发起同步IO请求,相当于队列中有多个IO请求;
增大应用IO大小,到达底层之后,会变成多个IO请求,相当于队列中有多个IO请求 队列深度增加了。
队列深度增加了,IO在队列的等待时间也会增加,导致IO响应时间变大,这需要权衡。让我们通过增加IO大小来增加dd的队列深度,看有没有效果:
# dd if=/dev/zero of=/dev/sdb bs=2M count=1000 oflag=direct``1000+0 records ``in``1000+0 records out``2097152000 bytes (2.1 GB) copied, 7.65746 s, 274 MB``/s` `iostat 查看``Device: rrqm``/s` `wrqm``/s` `r``/s` `w``/s` `rkB``/s` `wkB``/s` `avgrq-sz avgqu-sz await r_await w_await svctm %util``sdb 0.00 0.00 0.00 339.00 0.00 173568.00 1024.00 1.62 5.13 0.00 5.13 2.90 98.40
可以看到2MB的IO到达底层之后,会变成多个512KB的IO,平均队列长度为1.73,这个硬盘的利用率是99%,MBPS达到了207MB/s。(为什么会变成512KB的IO,你可以去使用Google去查一下内核参数 max_sectors_kb的意义和使用方法 )
也就是说增加队列深度,是可以测试出硬盘的峰值的。
使用 fio 测试硬盘
测试下SATA硬盘的4KB随机写的IOPS。使用工具:fio
测试命令及说明:
#fio -ioengine=libaio -bs=4k -direct=1 -thread -rw=randwrite -size=2000G -filename=/dev/sdb -name "vdisk 4k test" -iodepth=1 -runtime 10``简单介绍fio 的参数:``ioengine: 负载引擎,我们一般使用libaio,发起异步IO请求。``bs: IO大小``direct: 直写,绕过操作系统Cache。因为我们测试的是硬盘,而不是操作系统的Cache,所以设置为1。``rw: 读写模式,有顺序写write、顺序读``read``、随机写randwrite、随机读randread等。``size: 寻址空间,IO会落在 [0, size)这个区间的硬盘空间上。这是一个可以影响IOPS的参数。一般设置为硬盘的大小。``filename: 测试对象``iodepth: 队列深度,只有使用libaio时才有意义。这是一个可以影响IOPS的参数。``runtime: 测试时长
下面做两次测试,分别是 -iodepth = 1 和 -iodepth = 4 的情况:
-iodepth=1
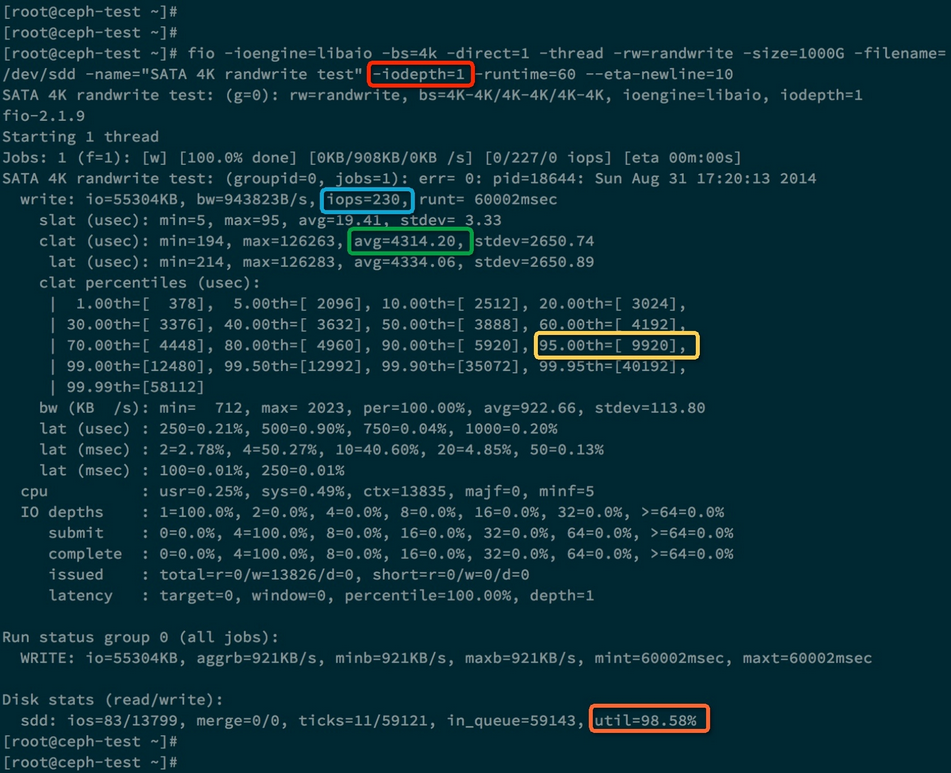
蓝色:IOPS = 230
绿色:每个IO请求平均耗时:4.3ms
黄色:95%的IO请求响应时间 小于 9.920ms
橙色:硬盘利用率达到 98.58%
-iodepth=4
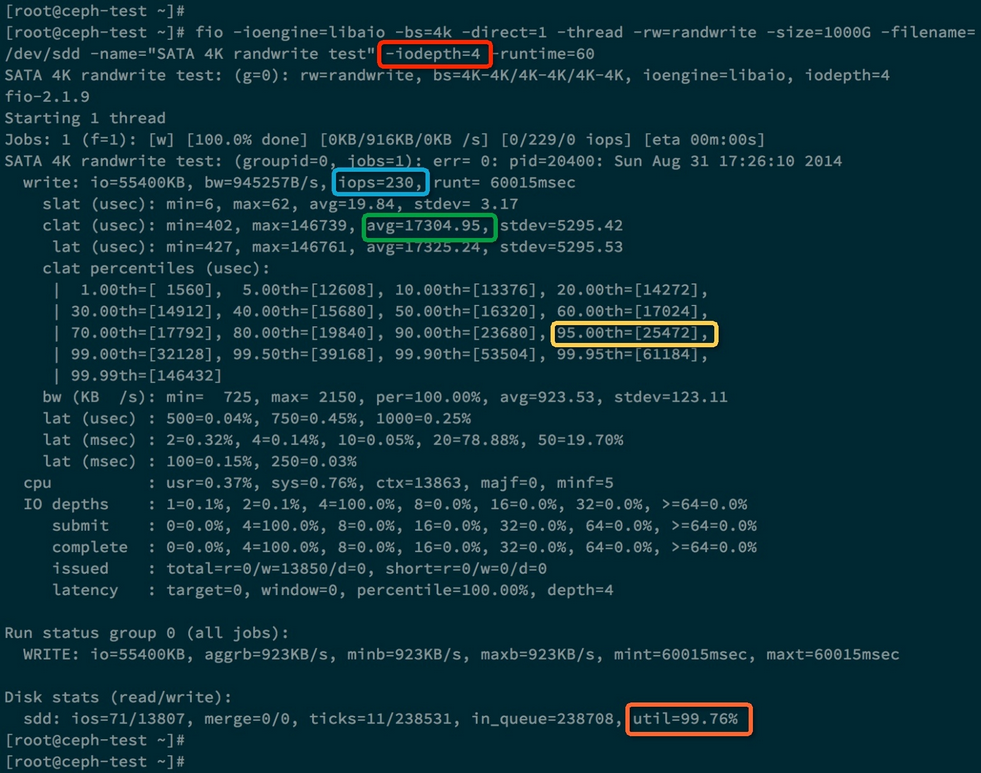
蓝色:IOPS = 230
绿色:每个IO请求平均耗时:17.3ms
黄色:95%的IO请求响应时间 小于 25.47ms
橙色:硬盘利用率达到 99.76%
对面两次测试数据,发现这次测试的IOPS没有提高,反而IO平均响应时间变大了,是17ms。
为什么这里提高队列深度没有作用呢,原因当队列深度为1时,硬盘的利用率已经达到了98%,说明硬盘已经没有多少空闲时间可以压榨了。而且响应时间为 4ms。 对于SATA硬盘,当增加队列深度时,并不会增加IOPS,只会增加响应时间。这是因为硬盘只有一个磁头,并行度是1, 所以当IO请求队列变长时,每个IO请求的等待时间都会变长,导致响应时间也变长。
最后,注意下
/sys/block/sdb/queue/max_sectors_kb
这个参数,通过 max_sectors_kb = 256 可以降低延迟,然后增加测试队列深度可以测试出磁盘的极限吞吐量,手里没有独立的磁盘,因此无法得到验证。
参考链接:
https://blog.51cto.com/wushank/1708168
我正在学习如何使用Nokogiri,根据这段代码我遇到了一些问题:require'rubygems'require'mechanize'post_agent=WWW::Mechanize.newpost_page=post_agent.get('http://www.vbulletin.org/forum/showthread.php?t=230708')puts"\nabsolutepathwithtbodygivesnil"putspost_page.parser.xpath('/html/body/div/div/div/div/div/table/tbody/tr/td/div
我有一个Ruby程序,它使用rubyzip压缩XML文件的目录树。gem。我的问题是文件开始变得很重,我想提高压缩级别,因为压缩时间不是问题。我在rubyzipdocumentation中找不到一种为创建的ZIP文件指定压缩级别的方法。有人知道如何更改此设置吗?是否有另一个允许指定压缩级别的Ruby库? 最佳答案 这是我通过查看rubyzip内部创建的代码。level=Zlib::BEST_COMPRESSIONZip::ZipOutputStream.open(zip_file)do|zip|Dir.glob("**/*")d
类classAprivatedeffooputs:fooendpublicdefbarputs:barendprivatedefzimputs:zimendprotecteddefdibputs:dibendendA的实例a=A.new测试a.foorescueputs:faila.barrescueputs:faila.zimrescueputs:faila.dibrescueputs:faila.gazrescueputs:fail测试输出failbarfailfailfail.发送测试[:foo,:bar,:zim,:dib,:gaz].each{|m|a.send(m)resc
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
假设我做了一个模块如下:m=Module.newdoclassCendend三个问题:除了对m的引用之外,还有什么方法可以访问C和m中的其他内容?我可以在创建匿名模块后为其命名吗(就像我输入“module...”一样)?如何在使用完匿名模块后将其删除,使其定义的常量不再存在? 最佳答案 三个答案:是的,使用ObjectSpace.此代码使c引用你的类(class)C不引用m:c=nilObjectSpace.each_object{|obj|c=objif(Class===objandobj.name=~/::C$/)}当然这取决于
我正在尝试使用ruby和Savon来使用网络服务。测试服务为http://www.webservicex.net/WS/WSDetails.aspx?WSID=9&CATID=2require'rubygems'require'savon'client=Savon::Client.new"http://www.webservicex.net/stockquote.asmx?WSDL"client.get_quotedo|soap|soap.body={:symbol=>"AAPL"}end返回SOAP异常。检查soap信封,在我看来soap请求没有正确的命名空间。任何人都可以建议我
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
我在我的项目目录中完成了compasscreate.和compassinitrails。几个问题:我已将我的.sass文件放在public/stylesheets中。这是放置它们的正确位置吗?当我运行compasswatch时,它不会自动编译这些.sass文件。我必须手动指定文件:compasswatchpublic/stylesheets/myfile.sass等。如何让它自动运行?文件ie.css、print.css和screen.css已放在stylesheets/compiled。如何在编译后不让它们重新出现的情况下删除它们?我自己编译的.sass文件编译成compiled/t
我想将html转换为纯文本。不过,我不想只删除标签,我想智能地保留尽可能多的格式。为插入换行符标签,检测段落并格式化它们等。输入非常简单,通常是格式良好的html(不是整个文档,只是一堆内容,通常没有anchor或图像)。我可以将几个正则表达式放在一起,让我达到80%,但我认为可能有一些现有的解决方案更智能。 最佳答案 首先,不要尝试为此使用正则表达式。很有可能你会想出一个脆弱/脆弱的解决方案,它会随着HTML的变化而崩溃,或者很难管理和维护。您可以使用Nokogiri快速解析HTML并提取文本:require'nokogiri'h
我想为Heroku构建一个Rails3应用程序。他们使用Postgres作为他们的数据库,所以我通过MacPorts安装了postgres9.0。现在我需要一个postgresgem并且共识是出于性能原因你想要pggem。但是我对我得到的错误感到非常困惑当我尝试在rvm下通过geminstall安装pg时。我已经非常明确地指定了所有postgres目录的位置可以找到但仍然无法完成安装:$envARCHFLAGS='-archx86_64'geminstallpg--\--with-pg-config=/opt/local/var/db/postgresql90/defaultdb/po