目录
1.皮尔逊相关系数(Pearson correlation)
2、斯皮尔曼相关系数(Spearman correlation)
为参加数学建模做准备!从相关性分析学起!
相关分析是指对两个或多个具备相关性的变量元素进行分析,从而衡量两个因素的的相关密切程度,相关性的元素之间需要存在一定的联系或者概率才可以进行相关性分析。
相关系数是反映两个变量之间线性相关程度的指标。
(还有一种Kendall相关系数暂不作了解)
以上两种系数是两个变量之间变化趋势的方向以及程度,取值范围为[-1, 1]。当接近1时,表示两者具有强烈的正相关性;当接近-1时,表示有强烈的的负相关性;而值接近0,则表示相关性很低。
斯皮尔曼相关系数和皮尔逊相关系数选择:
1.连续数据,正态分布,线性关系,使用pearson相关系数最为恰当,用spearman相关系数也可以, 就是效率没有pearson相关系数高。
2.上述三个条件均满足才能使用pearson相关系数,否则就用spearman相关系数。
3.定序数据之间也只用spearman相关系数,不能用pearson相关系数。
注:(1)定序数据是指仅仅反映观测对象等级、顺序关系的数据,是由定序尺度计量形成的,表现为类别,可以进行排序,属于品质数据。
例如,对成绩进行排名后,对排名进行数学运算就没有意义了。定序数据最重要的意义代表了一组数据中的逻辑顺序。
(2)斯皮尔曼相关系数的适用条件比皮尔逊相关系数要广,只要数据满足单调关系(例如线性函数、指数函数、对数函数等)就能够使用。
当两个变量都是正态连续变量,且两者之间呈线性关系时,则可以用Pearson来计算相关系数。取值范围[-1,1]。计算公式如下:

从形式上看即为概率论中所学的相关系数。
变量相关强度:
| 相关程度 | 极强相关 | 强相关 | 中等程度相关 | 弱相关 | 极弱相关或无相关 |
| 相关系数绝对值 | 0.8——1 | 0.6——0.8 | 0.4——0.6 | 0.2——0.4 | 0——0.2 |
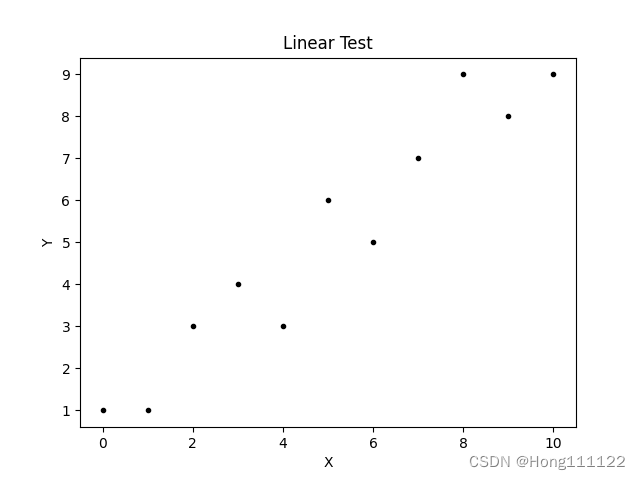
一般使用散点图进行线性检验:
import numpy as np
from matplotlib import pyplot as plt
def linear_test():
#为显示线性关系手动输入的数据
x = np.array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
y = np.array([1, 1, 3, 4, 3, 6, 5, 7, 9, 8, 9])
fig = plt.figure()
ax1 = fig.add_subplot(1, 1, 1)
ax1.set_title('Linear Test')
ax1.set_xlabel('X')
ax1.set_ylabel('Y')
ax1.scatter(x, y, c='k', marker='.')
plt.savefig('linear_test.png')
linear_test()
这里运用到scipy模块的kstest方法,具体代码如下:
def normal_test():
data = np.array([1, 2, 5, 4, 4, 6, 7, 3, 9, 5, 4, 7, 1, 2, 9])
u = data.mean()
std = data.std()
result = stats.kstest(data, 'norm', (u, std))
print(result)结果:KstestResult(statistic=0.12726344134326134, pvalue=0.9427504251048978)
结果返回两个值:statistic → D值,pvalue → P值
H0:样本符合
H1:样本不符合
p值>0.05则接受H0,该数据为正态分布。
若以上验证均成功则采取皮尔逊相关系数进行相关性分析:
import pandas as pd
# 读取数据
df = pd.read_excel('spearman_data.xlsx')
df = pd.DataFrame(df)
# print(df)
# 生成相关性矩阵
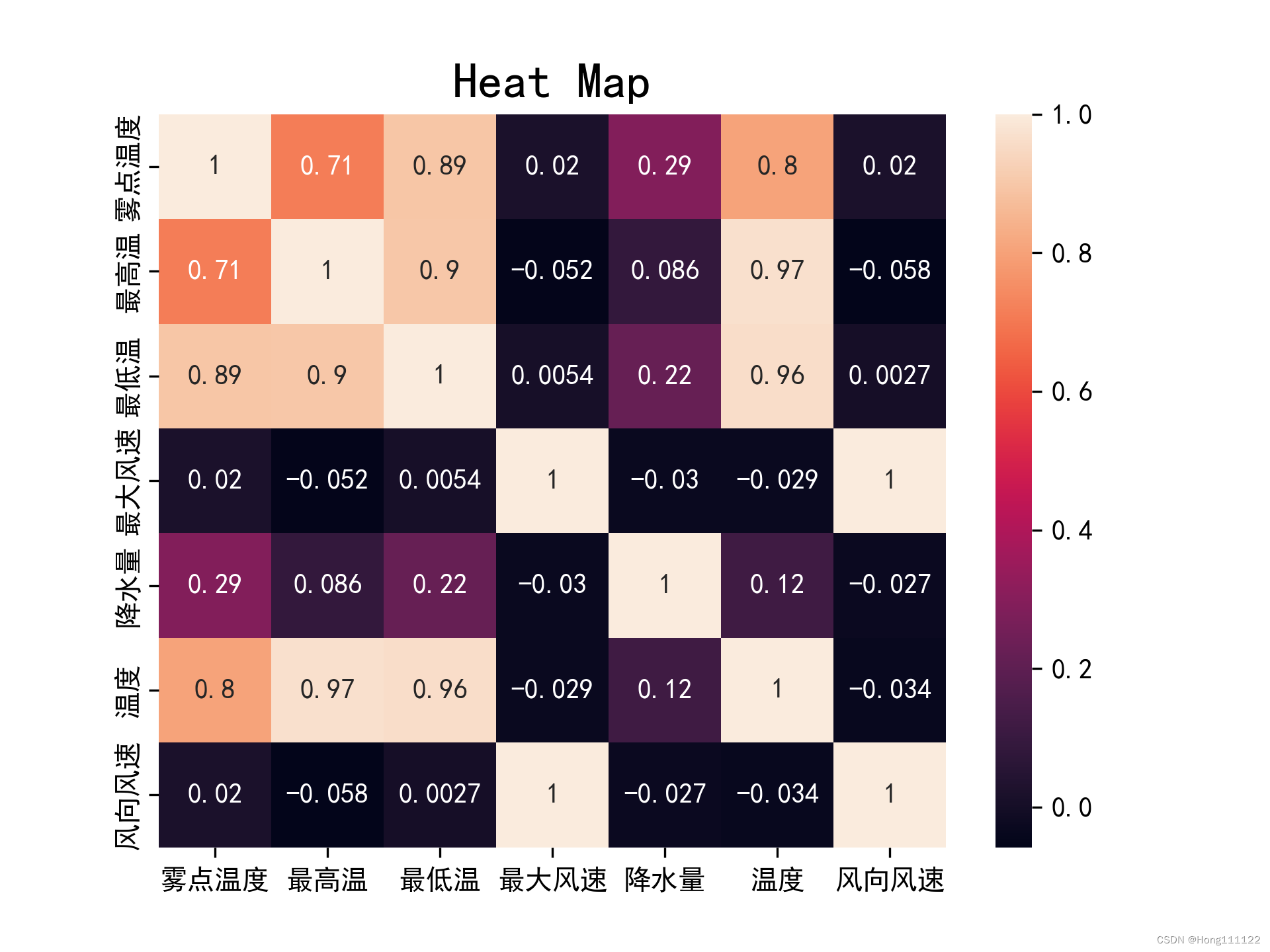
rho = df.corr(method='pearson')
print(rho)
对生成的相关系数矩阵进行可视化操作(生成热力图):
def heatmapplot():
plt.rcParams['font.family'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
sns.heatmap(rho, annot=True)
plt.title('Heat Map', fontsize=18)
plt.savefig('heatmap1.png', dpi=300)
秩相关系数(Coefficient of Rank Correlation),又称等级相关系数,反映的是两个随机变量的变化趋势方向和强度之间的关联,是将两个随机变量的样本值按数据的大小顺序排列位次,以各要素样本值的位次代替实际数据而求得的一种统计量。它是反映等级相关程度的统计分析指标,常用的等级相关分析方法有Spearman相关系数和Kendall秩相关系数等。主要用于数据分析。斯皮尔曼相关系数被定义成等级变量之间的皮尔逊相关系数。
较为常用简单的计算公式如下所示:
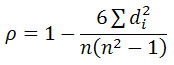
使用python求解与上文类似(metho = ‘spearman’)
两种相关系数的热力图对比:
pearson:
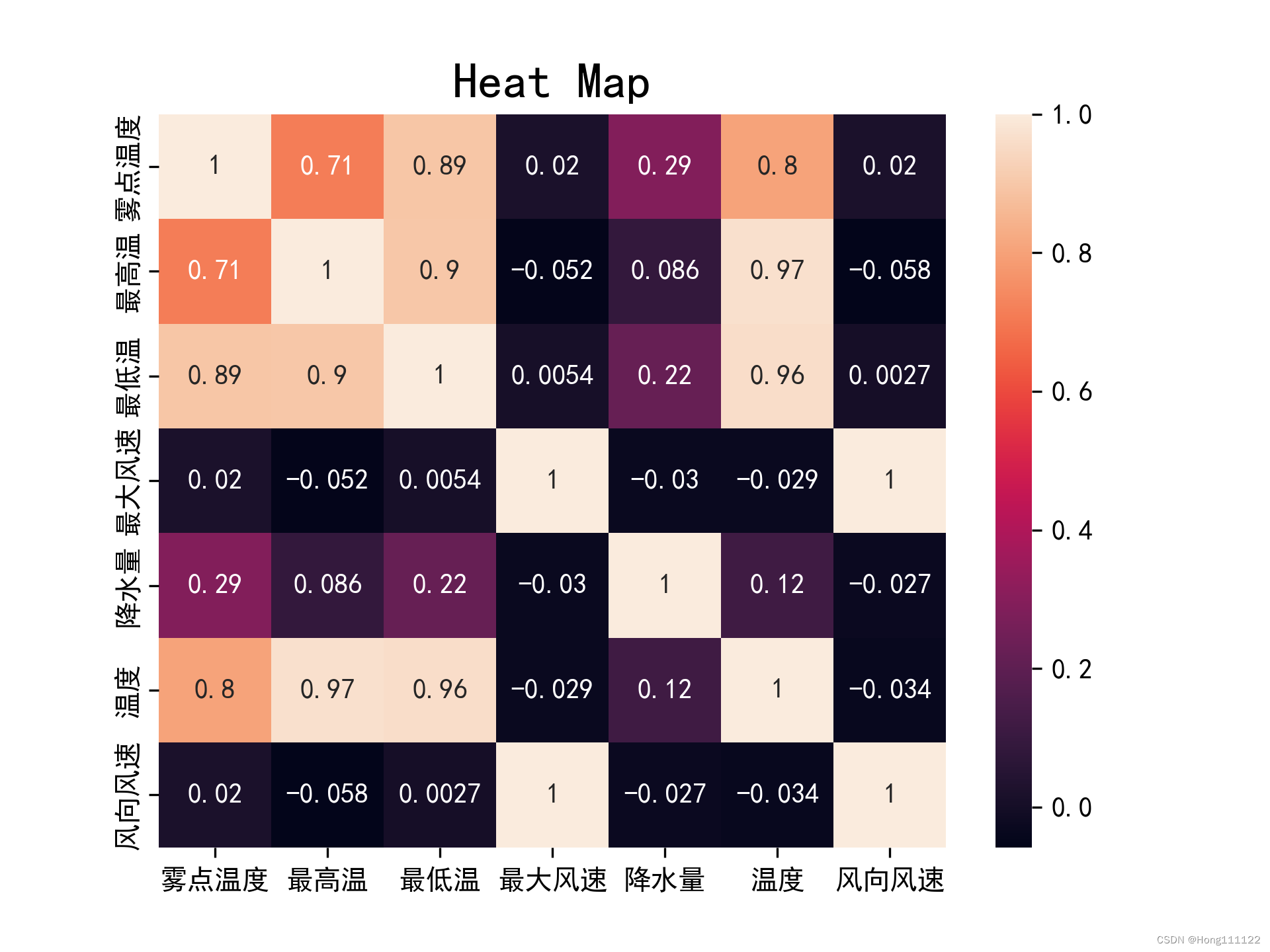
spearman:
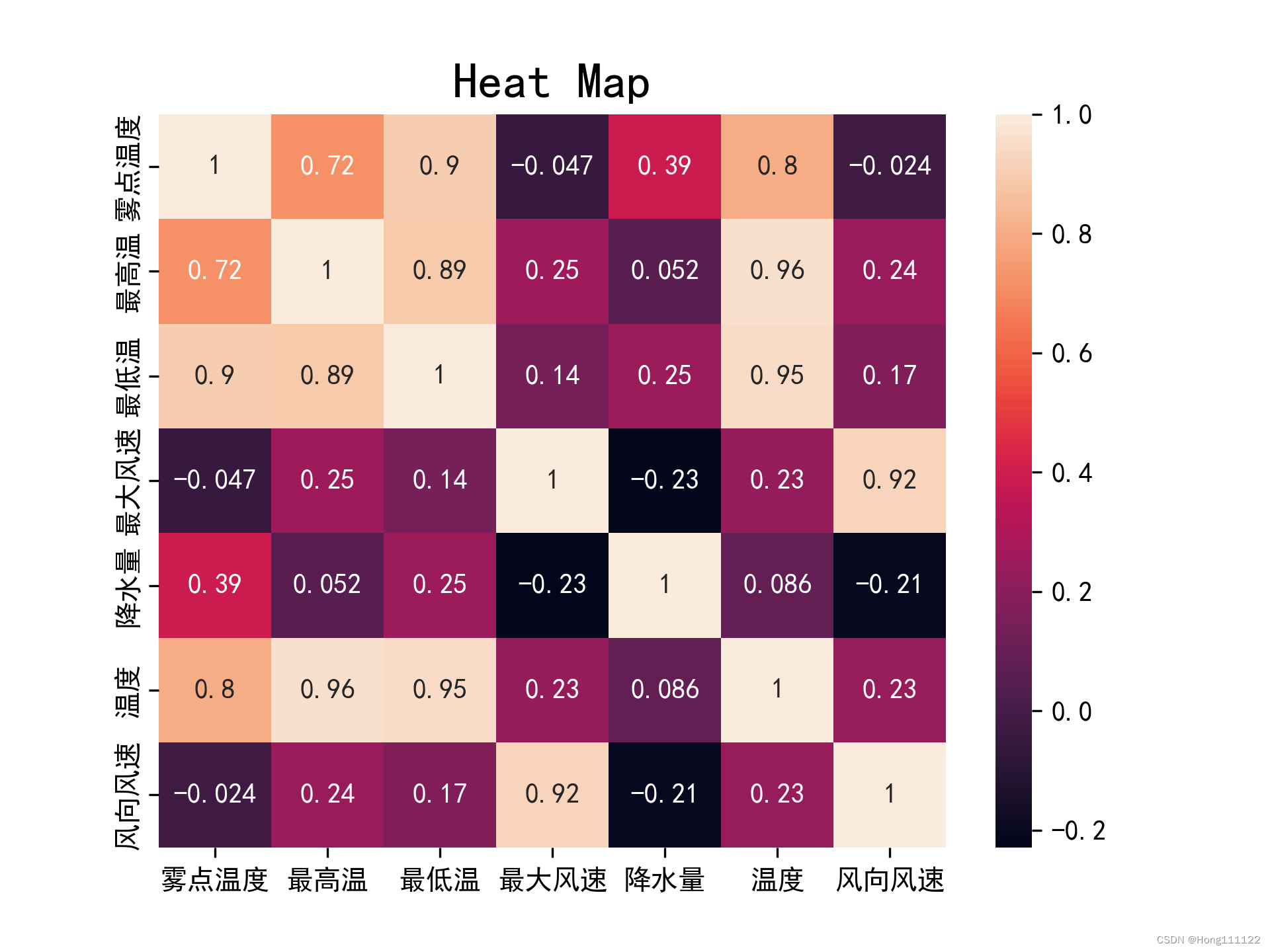
可见,对于同组数据,在满足了正态和线性检验的条件下,Pearson所得结果相对于Spearman会更加的精确和严格。
第一次写学习笔记若有错误希望大佬赐教!
球球各位点个赞。
先行发布,之后会在补充显著性检验等内容。
我正在尝试从Postgresql表(table1)中获取数据,该表由另一个相关表(property)的字段(table2)过滤。在纯SQL中,我会这样编写查询:SELECT*FROMtable1JOINtable2USING(table2_id)WHEREtable2.propertyLIKE'query%'这工作正常:scope:my_scope,->(query){includes(:table2).where("table2.property":query)}但我真正需要的是使用LIKE运算符进行过滤,而不是严格相等。然而,这是行不通的:scope:my_scope,->(que
我正在尝试按Rails相关模型中的字段进行排序。我研究的所有解决方案都没有解决如果相关模型被另一个参数过滤?元素模型classItem相关模型:classPriority我正在使用where子句检索项目:@items=Item.where('company_id=?andapproved=?',@company.id,true).all我需要按相关表格中的“位置”列进行排序。问题在于,在优先级模型中,一个项目可能会被多家公司列出。因此,这些职位取决于他们拥有的company_id。当我显示项目时,它是针对一个公司的,按公司内的职位排序。完成此任务的正确方法是什么?感谢您的帮助。PS-我
假设您有一个可执行文件foo.rb,其库bar.rb的布局如下:/bin/foo.rb/lib/bar.rb在foo.rb的header中放置以下要求以在bar.rb中引入功能:requireFile.dirname(__FILE__)+"../lib/bar.rb"只要对foo.rb的所有调用都是直接的,这就可以正常工作。如果你把$HOME/project和符号链接(symboliclink)foo.rb放入$HOME/usr/bin,然后__FILE__解析为$HOME/usr/bin/foo.rb,因此无法找到bar.rb关于foo.rb的目录名.我意识到像rubygems这
术语中文解释Ability原子化服务帮助用户完成任务的原子化服务,和用户的意图进行关联。Fulfillment服务履行通过图标,卡片,语音等形式呈现用户意图。开发者通过接口的方式,处理用户意图,返回内容。Intent意图用于表达用户想要达成的目标或完成的任务。HUAWEIAssistant智能助手“无微不智”的个人助手,通过不断的学习用户的使用习惯,不断的为用户提供贴心的精准的便捷的个性化服务。AISearch全局搜索用户可快速搜索关键词,与之匹配的原子化服务则会出现在搜索结果中。SmartService智慧服务用户订阅原子化服务,在到达特定触发条件(时间、地点、事件)后,卡片推送至用户智能助
目录H2数据库入门以及实际开发时的使用1.H2数据库的初识1.1H2数据库介绍1.2为什么要使用嵌入式数据库?1.3嵌入式数据库对比1.3.1性能对比1.4技术选型思考2.H2数据库实战2.1H2数据库下载搭建以及部署2.1.1H2数据库的下载2.1.2数据库启动2.1.2.1windows系统可以在bin目录下执行h2.bat2.1.2.2同理可以通过cmd直接使用命令进行启动:2.1.2.3启动后控制台页面:2.1.3spring整合H2数据库2.1.3.1引入依赖文件2.1.4数据库通过file模式实际保存数据的位置2.2H2数据库操作2.2.1Mysql兼容模式2.2.2Mysql模式
这个错误已经有好几个月了,在这里:http://www.ruby-forum.com/topic/1094002其中显示代码更改的两个链接:https://github.com/godfat/ruby/commit/f4e0e8f781b05c767ad2472a43a4ed0727a75708https://github.com/godfat/ruby/commit/c7a6cf975d88828c2ed27d253f41c480f9b66ad6我有Ruby1.9.2和rvm。我会把这些更改粘贴到适当的文件中,但我不知道如何粘贴。这在几天前就奏效了。我不能像这样执行RubyonRai
我对相关搜索有疑问。以下请求的结果很奇怪:Candidate.search('martin',fields:[:first_name,:last_name],match::word_start,misspellings:false).map(&:name)["KautzerMartina","FunkMartin","JaskolskiMartin","GutmannMartine","WiegandMartina","SchuellerMartin","DooleyMartin","StiedemannMartine","BartellMartina","GerlachMartine
我是Rails的新手。当我启动我的应用程序时,我不断看到这些弃用警告:DEPRECATIONWARNING:refisdeprecatedandwillberemovedfromRails3.2.(calledfromatD:/dev/AquaticKodiak/config/application.rb:12)DEPRECATIONWARNING:newisdeprecatedandwillberemovedfromRails3.2.(calledfromatD:/dev/AquaticKodiak/config/application.rb:12)好的,第12行是什么?这个:Bun
有没有办法得到Fakergem生成“相关的”城市和国家/地区代码值?例如,加利福尼亚州温哥华明尼苏达州明尼阿波利斯我这样做:FactoryGirl.definedofactory:locationdo...city{Faker::Address.city}country_code{['US','CA'].sample}...endend但不能保证city实际位于country_code。我会满足于这样的事情:postal_code{Faker::Address.postcode(['US','CA'].sample)}然后我可以对其进行地理编码以获得其他值。
第一个:如何创建一个不会立即启动的线程。如果我在没有block的情况下使用initialize,则会引发异常。如何将Thread子类化,以便我可以添加一些自定义属性,但保留与Thread基类相同的功能?我也不想为此使用initialize(&block)方法。为了更好地说明这一点:第一个问题:x=Thread.newx.run={#thisshouldhappeninsidethethread}x.start#iwanttomanuallystartthethread对于第二个:x=MyThread.newx.my_attribute=some_valuex.run={#thissho