python中使用redis进行模糊查询,可以使用scan()命令模糊匹配key。
keys命令:简单粗暴,但是由于Redis是单线程,keys命令是以阻塞的方式执行的,keys是以遍历的方式实现的复杂度是 O(n),Redis库中的key越多,查找实现代价越大,产生的阻塞时间越长。
scan命令: 以非阻塞的方式实现key值的查找,绝大多数情况下是可以替代keys命令的,可选性更强。
SCAN cursor [MATCH pattern] [COUNT count]
SCAN 命令用于迭代当前数据库中的数据库键。
SSCAN 命令用于迭代集合键中的元素。
HSCAN 命令用于迭代哈希键中的键值对。
ZSCAN 命令用于迭代有序集合中的元素(包括元素成员和元素分值)。
SCAN cursor [MATCH pattern] [COUNT count]参数解释:
注意 :Count 参数越大,Redis 阻塞时间也会越长,需要取舍。开始不知道直接设置了Integer.MAX_VALUE 结果上线直接凉凉堵塞死。并且返回的值中会存在重复的key 且是无序的 所以要注意去重。
Redis中keys命令进行获取key值,具体命令格式:keys pattern
redis中允许模糊查询的有3个通配符,分别是:*,?,[]
其中:
优点:同样是O(N)复杂度的scan命令,支持通配查找,scan命令或者其他的scan如SSCAN ,HSCAN,ZSCAN命令,可以不用阻塞主线程,并支持游标按批次迭代返回数据,所以是比较理想的选择。keys相比scan命令优点是,keys是一次返回,而scan是需要迭代多次返回。
缺点:返回的数据有可能重复,需要我们在业务层按需要去重,scan命令的游标从0开始,也从0结束,每次返回的数据,都会返回下一次游标应该传的值,我们根据这个值,再去进行下一次的访问,如果返回的数据为空,并不代表没有数据了,只有游标返回的值是0的情况下代表结束。
from redis import StrictRedis
try:
s = StrictRedis.from_url('redis://192.168.124.49/1')
for i in range(100):
s.set(f"name_{i}", f"dgw_{i}")
except Exception as e:
print(e)
示例代码1: 【直接使用keys()方法】
from redis import StrictRedis
try:
s = StrictRedis.from_url('redis://192.168.124.49/1')
keys = s.keys()
print(keys)
print(len(keys))
except Exception as e:
print(e)

示例代码2: 【根据键遍历查询所有的值】
from redis import StrictRedis
try:
s = StrictRedis.from_url('redis://192.168.124.49/1')
for i in range(100):
ret = s.get(f"name_{i}")
print(ret)
except Exception as e:
print(e)

示例代码3:【使用scan()方法】
from redis import StrictRedis
try:
s = StrictRedis.from_url('redis://192.168.124.49/1')
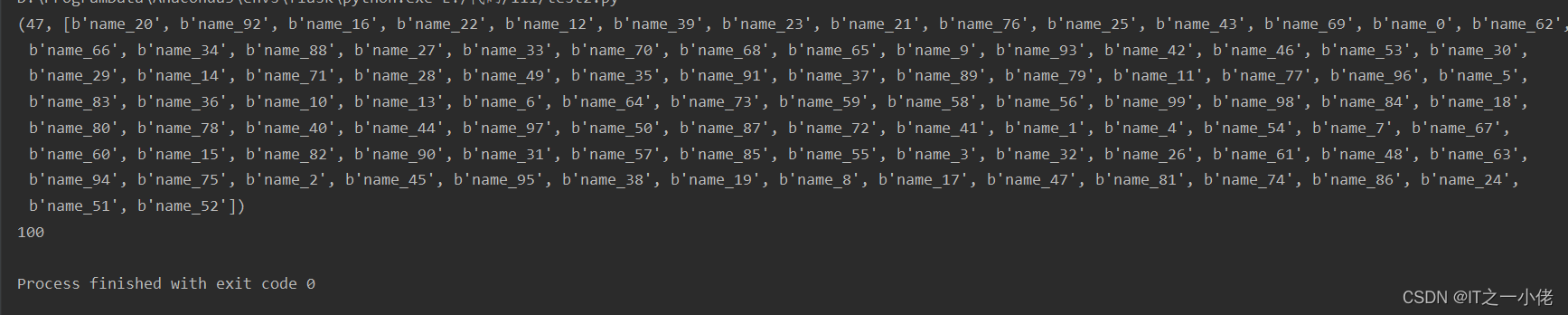
keys = s.scan(count=100) # 返回的是一个元组,默认count返回是10个
# scan中count:向Redis提供有关每批要返回的密钥数的提示,此处要注意返回的数量
print(keys)
print(len(keys[1]))
except Exception as e:
print(e)
示例代码4:【使用scan_iter()迭代方法】
from redis import StrictRedis
try:
s = StrictRedis.from_url('redis://192.168.124.49/1')
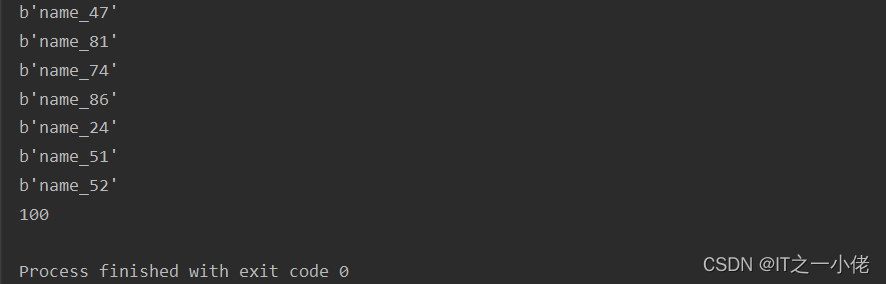
keys = s.scan_iter() # 返回的是一个迭代器
count = 0
for key in keys:
print(key)
count += 1
print(count)
except Exception as e:
print(e)
示例代码1: 【直接使用keys(),不建议这样使用】
from redis import StrictRedis
try:
s = StrictRedis.from_url('redis://192.168.124.49/1')
keys = s.keys(pattern="name_6*")
print(keys)
print(len(keys))
except Exception as e:
print(e)

from redis import StrictRedis
try:
s = StrictRedis.from_url('redis://192.168.124.49/1')
# keys = s.scan(match="name_6*") # 注意:本人测试这种写法(没有加count)没有返回数据
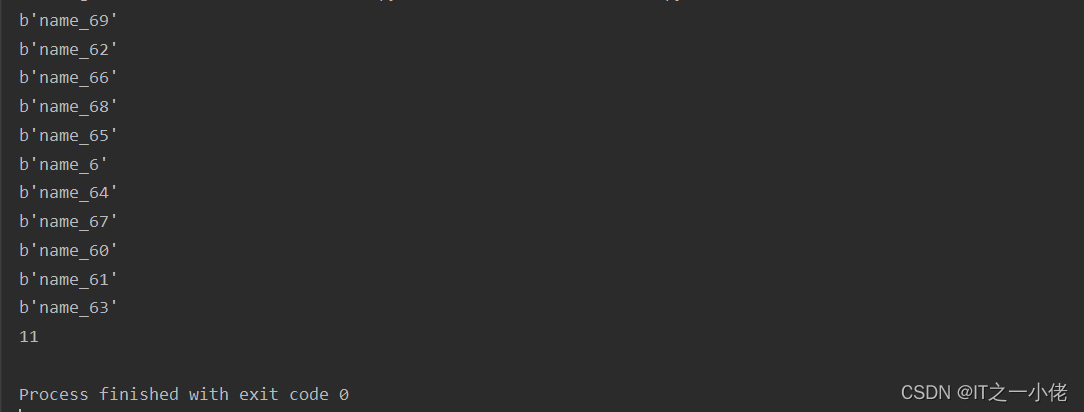
keys = s.scan(match="name_6*", count=100)
print(keys)
print(len(keys[1]))
except Exception as e:
print(e)

示例代码3: 【使用scan_iter()迭代方法】
from redis import StrictRedis
try:
s = StrictRedis.from_url('redis://192.168.124.49/1')
keys = s.scan_iter(match="name_6*")
count = 0
for key in keys:
print(key)
count += 1
print(count)
except Exception as e:
print(e)
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
在控制台中反复尝试之后,我想到了这种方法,可以按发生日期对类似activerecord的(Mongoid)对象进行分组。我不确定这是完成此任务的最佳方法,但它确实有效。有没有人有更好的建议,或者这是一个很好的方法?#eventsisanarrayofactiverecord-likeobjectsthatincludeatimeattributeevents.map{|event|#converteventsarrayintoanarrayofhasheswiththedayofthemonthandtheevent{:number=>event.time.day,:event=>ev
我正在用Ruby编写一个简单的程序来检查域列表是否被占用。基本上它循环遍历列表,并使用以下函数进行检查。require'rubygems'require'whois'defcheck_domain(domain)c=Whois::Client.newc.query("google.com").available?end程序不断出错(即使我在google.com中进行硬编码),并打印以下消息。鉴于该程序非常简单,我已经没有什么想法了-有什么建议吗?/Library/Ruby/Gems/1.8/gems/whois-2.0.2/lib/whois/server/adapters/base.
我正在编写一个包含C扩展的gem。通常当我写一个gem时,我会遵循TDD的过程,我会写一个失败的规范,然后处理代码直到它通过,等等......在“ext/mygem/mygem.c”中我的C扩展和在gemspec的“扩展”中配置的有效extconf.rb,如何运行我的规范并仍然加载我的C扩展?当我更改C代码时,我需要采取哪些步骤来重新编译代码?这可能是个愚蠢的问题,但是从我的gem的开发源代码树中输入“bundleinstall”不会构建任何native扩展。当我手动运行rubyext/mygem/extconf.rb时,我确实得到了一个Makefile(在整个项目的根目录中),然后当
这是一道面试题,我没有答对,但还是很好奇怎么解。你有N个人的大家庭,分别是1,2,3,...,N岁。你想给你的大家庭拍张照片。所有的家庭成员都排成一排。“我是家里的friend,建议家庭成员安排如下:”1岁的家庭成员坐在这一排的最左边。每两个坐在一起的家庭成员的年龄相差不得超过2岁。输入:整数N,1≤N≤55。输出:摄影师可以拍摄的照片数量。示例->输入:4,输出:4符合条件的数组:[1,2,3,4][1,2,4,3][1,3,2,4][1,3,4,2]另一个例子:输入:5输出:6符合条件的数组:[1,2,3,4,5][1,2,3,5,4][1,2,4,3,5][1,2,4,5,3][
我知道我可以指定某些字段来使用pluck查询数据库。ids=Item.where('due_at但是我想知道,是否有一种方法可以指定我想避免从数据库查询的某些字段。某种反拔?posts=Post.where(published:true).do_not_lookup(:enormous_field) 最佳答案 Model#attribute_names应该返回列/属性数组。您可以排除其中一些并传递给pluck或select方法。像这样:posts=Post.where(published:true).select(Post.attr
我已经构建了一些serverspec代码来在多个主机上运行一组测试。问题是当任何测试失败时,测试会在当前主机停止。即使测试失败,我也希望它继续在所有主机上运行。Rakefile:namespace:specdotask:all=>hosts.map{|h|'spec:'+h.split('.')[0]}hosts.eachdo|host|begindesc"Runserverspecto#{host}"RSpec::Core::RakeTask.new(host)do|t|ENV['TARGET_HOST']=hostt.pattern="spec/cfengine3/*_spec.r
我们的git存储库中目前有一个Gemfile。但是,有一个gem我只在我的环境中本地使用(我的团队不使用它)。为了使用它,我必须将它添加到我们的Gemfile中,但每次我checkout到我们的master/dev主分支时,由于与跟踪的gemfile冲突,我必须删除它。我想要的是类似Gemfile.local的东西,它将继承从Gemfile导入的gems,但也允许在那里导入新的gems以供使用只有我的机器。此文件将在.gitignore中被忽略。这可能吗? 最佳答案 设置BUNDLE_GEMFILE环境变量:BUNDLE_GEMFI
这似乎非常适得其反,因为太多的gem会在window上破裂。我一直在处理很多mysql和ruby-mysqlgem问题(gem本身发生段错误,一个名为UnixSocket的类显然在Windows机器上不能正常工作,等等)。我只是在浪费时间吗?我应该转向不同的脚本语言吗? 最佳答案 我在Windows上使用Ruby的经验很少,但是当我开始使用Ruby时,我是在Windows上,我的总体印象是它不是Windows原生系统。因此,在主要使用Windows多年之后,开始使用Ruby促使我切换回原来的系统Unix,这次是Linux。Rub