文章目录
标准化方法是一种最为常见的量纲化处理方式
最常见的标准化方法就是Z标准化,也是SPSS中最为常用的标准化方法,spss默认的标准化方法就是z-score标准化。也叫标准差标准化,这种方法给予原始数据的均值(mean)和标准差(standard deviation)进行数据的标准化。
z-score标准化是将数据按比例缩放,使之落入一个特定区间。
示例:pandas 是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的。
标准差(Standard Deviation) ,数学术语,是离均差平方的算术平均数(即:方差)的算术平方根,用σ表示。标准差也被称为标准偏差,或者实验标准差,在概率统计中最常使用作为统计分布程度上的测量依据。
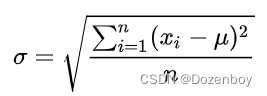
z-score normalization后,所有特征的均值为0,标准差为1。
要实现z-score normalization,调整输入值如下公式所示:
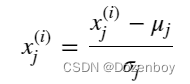
其中j选择X矩阵中的一个特征或一列。μj为特征(j)所有值的均值,σj为特征(j)的标准差。
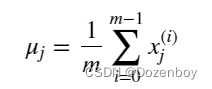
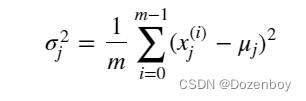
代码如下(示例):
def zscore_normalize_features(X):
"""
X (ndarray): Shape (m,n) input data, m examples, n features
X_norm (ndarray): Shape (m,n) input normalized by column
mu (ndarray): Shape (n,) mean of each feature
sigma (ndarray): Shape (n,) standard deviation of each feature
"""
# find the mean of each column/feature
mu = np.mean(X, axis=0) # mu will have shape (n,)
# find the standard deviation of each column/feature
sigma = np.std(X, axis=0) # sigma will have shape (n,)
# element-wise, subtract mu for that column from each example, divide by std for that column
X_norm = (X - mu) / sigma
return (X_norm, mu, sigma)
#check our work
#from sklearn.preprocessing import scale
#scale(X_orig, axis=0, with_mean=True, with_std=True, copy=True)
代码来源于吴恩达老师机器学习
提示:这里对文章进行总结:
例如:以上就是今天要讲的内容,本文仅仅简单介绍了pandas的使用,而pandas提供了大量能使我们快速便捷地处理数据的函数和方法。
我想使用spawn(针对多个并发子进程)在Ruby中执行一个外部进程,并将标准输出或标准错误收集到一个字符串中,其方式类似于使用Python的子进程Popen.communicate()可以完成的操作。我尝试将:out/:err重定向到一个新的StringIO对象,但这会生成一个ArgumentError,并且临时重新定义$stdxxx会混淆子进程的输出。 最佳答案 如果你不喜欢popen,这是我的方法:r,w=IO.pipepid=Process.spawn(command,:out=>w,:err=>[:child,:out])
我正在尝试找到一种方法来规范化字符串以将其作为文件名传递。到目前为止我有这个:my_string.mb_chars.normalize(:kd).gsub(/[^\x00-\x7F]/n,'').downcase.gsub(/[^a-z]/,'_')但第一个问题:-字符。我猜这个方法还有更多问题。我不控制名称,名称字符串可以有重音符、空格和特殊字符。我想删除所有这些,用相应的字母('é'=>'e')替换重音符号,并将其余的替换为'_'字符。名字是这样的:“Prélèvements-常规”“健康证”...我希望它们像一个没有空格/特殊字符的文件名:“prelevements_routin
我经常迷上ruby的一件事是递归模式。例如,假设我有一个数组,它可能包含无限深度的数组作为元素。所以,例如:my_array=[1,[2,3,[4,5,[6,7]]]]我想创建一个方法,可以将数组展平为[1,2,3,4,5,6,7]。我知道.flatten可以完成这项工作,但这个问题是作为我经常遇到的递归问题的一个例子-因此我试图找到一个更可重用的解决方案。简而言之-我猜这种事情有一个标准模式,但我想不出任何特别优雅的东西。任何想法表示赞赏 最佳答案 递归是一种方法,它不依赖于语言。您在编写算法时要考虑两种情况:再次调用函数的情
我正在使用ruby标准记录器,我想要每天轮换一次,所以在我的代码中我有:Logger.new("#{$ROOT_PATH}/log/errors.log",'daily')它运行完美,但它创建了两个文件errors.log.20130217和errors.log.20130217.1。如何强制它每天只创建一个文件? 最佳答案 您的代码对于长时间运行的应用程序是正确的。发生的事情是您在给定的一天多次运行代码。第一次运行时,Ruby会创建一个日志文件“errors.log”。当日期改变时,Ruby将文件重命名为“errors.log
如何获取外部命令的输出并从中提取值?我有这样的东西:stdin,stdout,stderr,wait_thr=Open3.popen3("#{path}/foobar",configfile)if/exit0/=~wait_thr.value.to_srunlog.puts("Foobarexitednormally.\n")puts"Testcompleted."someoutputvalue=stdout.read("TX.*\s+(\d+)\s+")puts"Outputvalue:"+someoutputvalueend我没有在标准输出上使用正确的方法,因为Ruby告诉我它不能
我遇到了同样的问题here对于python,但对于ruby。我需要输出这样一个小数字:0.00001,而不是1e-5。有关我的特定问题的更多信息,我正在使用f.write("Mynumber:"+small_number.to_s+"\n")输出到一个文件对于我的问题,准确性不是什么大问题,所以只做一个if语句来检查是否small_number那么更通用的方法是什么? 最佳答案 f.printf"Mynumber:%.5f\n",small_number您可以将.5(小数点右侧5位数字)替换为您喜欢的任何特定格式大小,例如,%8
我有一个正在HerokuCedar堆栈上部署的Rails3.2应用程序。这意味着应用程序本身负责为其静态Assets提供服务。我希望对这些Assets进行gzip压缩,所以我在production.rb的中间件堆栈中插入了Rack::Deflater:middleware.insert_after('Rack::Cache',Rack::Deflater)...curl告诉我这与宣传的一样有效。但是,由于Heroku将全力运行rakeassets:precompile,生成一堆预gzipAssets,我很想使用它们(而不是让Rack::Deflater再次完成所有工作)。我已经看到使用
我是Ruby分析的新手,看起来像ruby-prof是一个受欢迎的选择。我刚刚安装了gem并调用了我的程序:ruby-prof./my-prog.rb但是,输出非常冗长,因为包含所有Ruby核心和标准库方法以及其他gem的分析数据。例如,前三行是:8.790.0110.0100.0000.0013343*String#%7.280.0780.0090.0000.0692068*Array#each4.930.0380.0060.0000.0321098*Array#map这对我来说不是什么有用的信息,因为我已经知道我的程序经常处理字符串和数组,并且大概已经对这些类进行了优化。我只关心我代
我正在阅读我的ruby书。查看下面的代码,moduleDestroydefdestroy(anyObject)@anyObject=anyObjectputs"Iwilldestroytheobject:#{anyObject}"endendclassUserincludeDestroyattr_accessor:name,:emaildefinitialize(name,email)@name=name@email=emailendendmy_info=User.new("Bob","Bob@example.com")puts"Soyournameis:#{my_info.name}
Mongoid::Paranoia向生成标准的模型添加默认范围#{"$exists"=>false}},options:{},class:Line,embedded:false>我可以使用生成的Model.deleted找到已删除的文档,#{"$exists"=>true}},options:{},class:Line,embedded:false>我如何覆盖它以便我可以搜索已删除和未删除的文档。PSModel.unscoped不起作用 最佳答案 试试这个(它是一种hack):classUserincludeMongoid::Doc