1.IOC容器简介
(1) org.springframework.beans 与 org.springframework.context 这两个包是Spring IOC容器的基础,在org.springframework.beans中的BeanFactory接口提供了一种能够管理任何类型对象的机制(类似于一个工厂,里面放满了需要被管理的对象),而在org.springframework.context中的BeanFactory的子接口ApplicationContext则在其基础之上提供了更多特性(如AOP,Message resource,Event publication等)。总而言之,BeanFactory提供了一个容器的基本功能,而ApplicationContext可以看做是BeanFactory的扩展,它提供了更多企业级特性
(2) 一个普通的java对象,在交由Spring IOC容器实例化,配置,组装并管理之后,我们称其为bean。IOC容器需要通过XML,Java code等方式来获取有关对象的配置信息(也称为配置元数据),来完成bean的实例化动作。如下所示,我们通过XML的方式定义了一个bean的配置元数据,规定了其id,name和class的值,之后IOC会根据这些信息来构造一个bean并保存
<?xml version="1.0" encoding="UTF-8"?>
<beans ....>
<bean id="..." name="..." class="..."></bean>
</beans>
2.配置元数据
(1) 由上文可知,元数据的概念就是告诉Spring如何实例化、配置和组装的我们应用程序中的对象,如下图
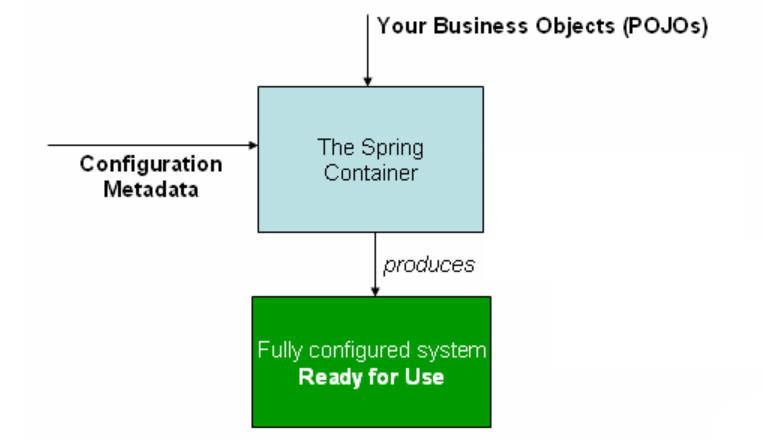
(2) 配置方式:基于xml的配置可用bean标签,基于java的配置用@Configuration和@Bean注解等
下面是一个基于XML配置的标准模板
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans
https://www.springframework.org/schema/beans/spring-beans.xsd">
<!-- 在xml中,所有的bean都必须放在beans这一顶级标签中,里面的这些bean标签对应于我们的系统中的实际对象 -->
<!-- bean标签中的id属性用来标识一个bean,其值不可重复,class用来指定这个bean的类类型(使用全限定类名) -->
<bean id="..." class="...">
<!-- 在bean标签内部来指定该bean的成员变量等 -->
</bean>
</beans>
3.实例化容器
(1) ApplicationContext接口就代表了IOC容器,如果想要构建它,则可根据实际需要来使用其某个具体的实现类,如ClassPathXmlApplicationContext或FileSystemXmlApplicationContext,它们的构造函数接收一个或多个资源路径,表示从各种外部资源(如XML)中加载配置元数据,如下
ApplicationContext ctx = new ClassPathXmlApplicationContext("boke/definition.xml");
其中boke/definition.xml配置文件中的内容如下所示
<beans ...>
<bean id="bId" class="cn.example.spring.boke.ExampleB"></bean>
<bean id="aId" name="aName" class="cn.example.spring.boke.ExampleA">
<!-- property标签用于bean中成员变量值的注入,name属性:指定JavaBean中的属性名,该属性要有其对应的setter方法,否则无法注入,ref属性:引用另一个bean的id,注入依赖 -->
<property name="exampleB" ref="bId"></property>
</bean>
</beans>
此外,如果是基于Java code的配置,还可以使用AnnotationConfigApplicationContext,其构造函数参数接受配置类或需要扫描的包路径,来加载配置元数据,如下所示
ApplicationContext ctx = new AnnotationConfigApplicationContext("cn.example.spring");
4.导入另一份xml中的配置元数据
(1) 通常来说,一个系统会被分为多个模块,某个模块都对应有一份单独的xml文件,因此,当我们需要向一个xml文件中导入另一个xml中的配置元数据时,可以使用import标签,如下所示
<beans ...>
<!-- import标签:导入其它的配置文件;该标签定义于beans标签内部,与bean标签平行 -->
<import resource="from.xml"></import>
<import resource="down/son.xml"></import>
</beans>
注意:采用的是相对于当前文件(在上面这个例子中为:definition.xml)的路径来导入其他的文件,上面这个例子中,文件结构为
--boke
|-definition.xml
|-from.xml
----down
|-son.xml
definition.xml和from.xml处于同一级目录boke下,而son.xml位于down目录下,该目录是boke目录的子目录。Spring不建议使用相对路径(如:classpath:../beans.xml),但可以使用绝对路径(如:file:C:/spring/boke/from.xml或classpath:/boke/from.xml)来导入其他的xml配置文件
5.使用容器
(1) 容器用来管理bean,使用容器一般情况就是获取它所保存的bean。在ApplicationContext中,提供了getBean()方法(不推荐使用,会对Spring的API产生强依赖)来获取容器中的bean,如下示例所示
//1.创建容器
ApplicationContext ctx = new ClassPathXmlApplicationContext("boke/definition.xml");
//2.从容器中获取需要bean
ExampleA a = ctx.getBean(ExampleA.class);
//3.使用这个bean
a.doSomething();
此外,还可将GenericApplicationContext与XmlBeanDefinitionReader结合使用,来解析xml中的bean配置元数据并生成对应的bean
//1.创建容器
GenericApplicationContext context = new GenericApplicationContext();
//2.将xml文件的解析工作委托给了xml阅读器XmlBeanDefinitionReader,它会解析xml配置文件,并将解析的bean配置元数据交给GenericApplicationContext
new XmlBeanDefinitionReader(context).loadBeanDefinitions("services.xml", "daos.xml");
//3.刷新容器,此时容器就会创建出对应的bean
context.refresh();
//4.获取bean
ExampleA a = context.getBean(ExampleA.class);
//5.使用这个bean
a.doSomething();
可见ClassPathXmlApplicationContext中已经包含了xml文件的解析工作
matlab打开matlab,用最简单的imread方法读取一个图像clcclearimg_h=imread('hua.jpg');返回一个数组(矩阵),往往是a*b*cunit8类型解释一下这个三维数组的意思,行数、数和层数,unit8:指数据类型,无符号八位整形,可理解为0~2^8的数三个层数分别代表RGB三个通道图像rgb最常用的是24-位实现方法,即RGB每个通道有256色阶(2^8)。基于这样的24-位RGB模型的色彩空间可以表现256×256×256≈1670万色当imshow传入了一个二维数组,它将以灰度方式绘制;可以把图像拆分为rgb三层,可以以灰度的方式观察它figure(1
目录前言滤波电路科普主要分类实际情况单位的概念常用评价参数函数型滤波器简单分析滤波电路构成低通滤波器RC低通滤波器RL低通滤波器高通滤波器RC高通滤波器RL高通滤波器部分摘自《LC滤波器设计与制作》,侵权删。前言最近需要学习放大电路和滤波电路,但是由于只在之前做音乐频谱分析仪的时候简单了解过一点点运放,所以也是相当从零开始学习了。滤波电路科普主要分类滤波器:主要是从不同频率的成分中提取出特定频率的信号。有源滤波器:由RC元件与运算放大器组成的滤波器。可滤除某一次或多次谐波,最普通易于采用的无源滤波器结构是将电感与电容串联,可对主要次谐波(3、5、7)构成低阻抗旁路。无源滤波器:无源滤波器,又称
最近在学习CAN,记录一下,也供大家参考交流。推荐几个我觉得很好的CAN学习,本文也是在看了他们的好文之后做的笔记首先是瑞萨的CAN入门,真的通透;秀!靠这篇我竟然2天理解了CAN协议!实战STM32F4CAN!原文链接:https://blog.csdn.net/XiaoXiaoPengBo/article/details/116206252CAN详解(小白教程)原文链接:https://blog.csdn.net/xwwwj/article/details/105372234一篇易懂的CAN通讯协议指南1一篇易懂的CAN通讯协议指南1-知乎(zhihu.com)视频推荐CAN总线个人知识总
深度学习部署:Windows安装pycocotools报错解决方法1.pycocotools库的简介2.pycocotools安装的坑3.解决办法更多Ai资讯:公主号AiCharm本系列是作者在跑一些深度学习实例时,遇到的各种各样的问题及解决办法,希望能够帮助到大家。ERROR:Commanderroredoutwithexitstatus1:'D:\Anaconda3\python.exe'-u-c'importsys,setuptools,tokenize;sys.argv[0]='"'"'C:\\Users\\46653\\AppData\\Local\\Temp\\pip-instal
基础版云数据库RDS的产品系列包括基础版、高可用版、集群版、三节点企业版,本文介绍基础版实例的相关信息。RDS基础版实例也称为单机版实例,只有单个数据库节点,计算与存储分离,性价比超高。说明RDS基础版实例只有一个数据库节点,没有备节点作为热备份,因此当该节点意外宕机或者执行重启实例、变更配置、版本升级等任务时,会出现较长时间的不可用。如果业务对数据库的可用性要求较高,不建议使用基础版实例,可选择其他系列(如高可用版),部分基础版实例也支持升级为高可用版。基础版与高可用版的对比拓扑图如下所示。优势 性能由于不提供备节点,主节点不会因为实时的数据库复制而产生额外的性能开销,因此基础版的性能相对于
我完全不是程序员,正在学习使用Ruby和Rails框架进行编程。我目前正在使用Ruby1.8.7和Rails3.0.3,但我想知道我是否应该升级到Ruby1.9,因为我真的没有任何升级的“遗留”成本。缺点是什么?我是否会遇到与普通gem的兼容性问题,或者甚至其他我不太了解甚至无法预料的问题? 最佳答案 你应该升级。不要坚持从1.8.7开始。如果您发现不支持1.9.2的gem,请避免使用它们(因为它们很可能不被维护)。如果您对gem是否兼容1.9.2有任何疑问,您可以在以下位置查看:http://www.railsplugins.or
Ruby有一些不错的文档生成器,例如Yard、rDoc,甚至Glyph。问题是Sphinx可以做网站、PDF、epub、LaTex等。它在重组文本中完成所有这些事情。在Ruby世界中有替代方案吗?也许是程序的组合?如果我也能使用Markdown就更好了。 最佳答案 自1.0版以来,Sphinx有了“域”的概念,它是从Python和/或C以外的语言标记代码实体(如方法调用、对象、函数等)的方法。有一个rubydomain,所以你可以只使用Sphinx本身。您唯一会缺少的(我认为)是Sphinx使用autodoc从源代码自动创建文档
如何学习ruby的正则表达式?(对于假人) 最佳答案 http://www.rubular.com/在Ruby中使用正则表达式时是一个很棒的工具,因为它可以立即将结果可视化。 关于ruby-我如何学习ruby的正则表达式?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/1881231/
我怀念ipython的一件事是它有一个?为特定功能挖掘文档的运算符。我知道ruby有一个类似的命令行工具,但是我在irb中调用它非常不方便。ruby/irb有类似的东西吗? 最佳答案 Pry是IPython的Ruby版本,它支持?命令来查找有关方法的文档,但语法略有不同:pry(main)>?File.dirnameFrom:file.cinRubyCore(CMethod):Numberoflines:6visibility:publicsignature:dirname()Returnsallcomponentsofthef
我正在尝试使用nokogirigem提取页面上的所有url及其链接文本,并将链接文本和url存储在散列中。FooBar我想回去{"Foo"=>"#foo","Bar"=>"#bar"} 最佳答案 这是一个单行:Hash[doc.xpath('//a[@href]').map{|link|[link.text.strip,link["href"]]}]#=>{"Foo"=>"#foo","Bar"=>"#bar"}拆分一点可以说更具可读性:h={}doc.xpath('//a[@href]').eachdo|link|h[link.t