目录
提出了一种 高效 异步 的联邦学习机制EAFLM
(Efficient Asynchronous Fedrated Learning Mechanism)
其中:
高效的实现目标主要是实现通信压缩,文章在前人Chen等人提出的LAG自适应压缩的工作基础上,提出了一种阈值自适应的压缩算法。文章中的通信压缩属于“通信稀疏化”的范畴。
异步方面的工作是实现了各个边缘设备真正的异步训练,允许节点在任何学习过程中加入或退出联邦学习。提出了双重权重的方法以解决异步学习带来的性能降低问题。
联邦学习机制
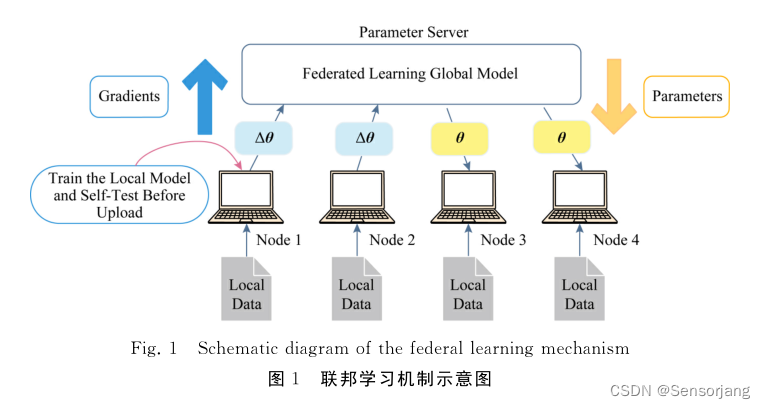
EAFLM机制框架示意图
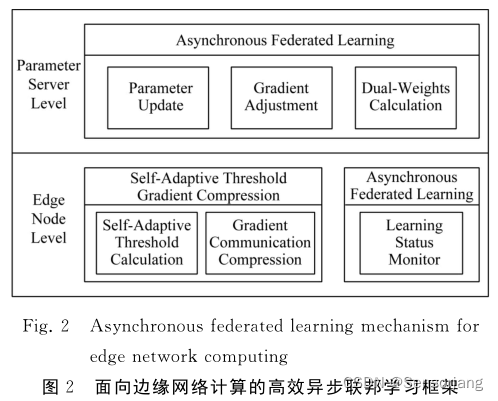
其中:
自适应阈值梯度压缩模块包含:自适应阈值计算子模块、梯度通信压缩子模块
异步联邦学习模块 横跨参数服务器Level和边缘节点Level,其包含:位于边缘节点上的 学习状态监控子模块 和 位于参数服务器上的 双重权重计算子模块、梯度修正子模块、参数更新子模块。

第k轮参数服务器(更新后)的参数
节点i基于第k轮的参数计算出的k轮的梯度
M中所有节点在k轮计算出的梯度总和
所有边缘节点的集合M
M中总的元素个数
所有节点的样本总数
节点i的样本总数
节点i当前纪元的样本权重
节点i当前纪元的参数权重
文章提出的通信压缩方法属于“通信稀疏化”的范畴,基于Chen等人提出的LAG自适应压缩的工作基础之上。
首先定义在某一轮次中,与参数服务器发生通信的节点为“勤奋节点hard work”,而被忽略的节点为“懒惰节点lazy”,记勤奋节点集合MˇH,懒惰节点集合MˇL,因此
M=MˇL+MˇH
梯度可以表示为: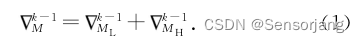
懒惰节点集合MˇL满足: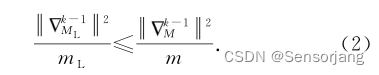
设置更新参数的优化算法为 梯度下降算法gradient descent,即: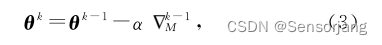
(其中α为学习率)
(3)带入(2):
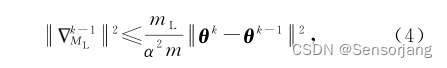
其中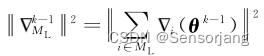
,由均值不等式【
a 2+ b2 >= (a+b)2 / 2
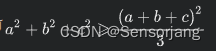
】
得,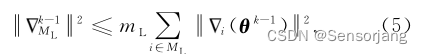

(理解:(5)是经过均值不等式推导,因此右侧部分是大于左侧 ||·||2 部分这是必然成立的,而(4)是定义推导而出的“定义为lazy节点的条件式”,因此 (4)右侧 >= (5)右侧 如果成立,(4)右侧 >=左侧部分 则必然成立。然后(4)右侧 >= (5)右侧等式的基础上两边各除以(MˇL)2 可得(6)。因此满足(6)一定可以满足(2)。)
由于集合 MˇL的总数无法事先获取, 所以为了简化问题, 我们引入比例系数β来衡量集合MˇL的节点总数, 即mˇL=βm。(比例系数其实就是所有节点中lazy节点数量所占的比例) 整理式(6) 可得:
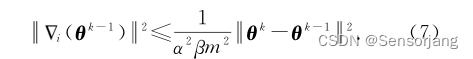
而因为通常难以获得θk-θk-1,且学习过程中的参数逐渐趋于平滑,因此取近似:

(D=1 即说明,θk-θk-1 取上一轮(k-1轮)的参数差异)
此时式(7)变为:
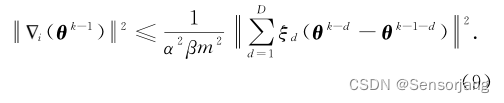
此时,本式作为节点设备在上传梯度之前进行梯度检查的自检表达式。
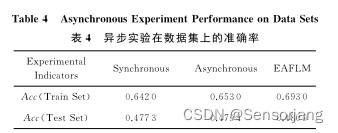
异步联邦学习可能有很多因素导致:加入学习的时间、节点的算力不同、梯度压缩、外部因素 等
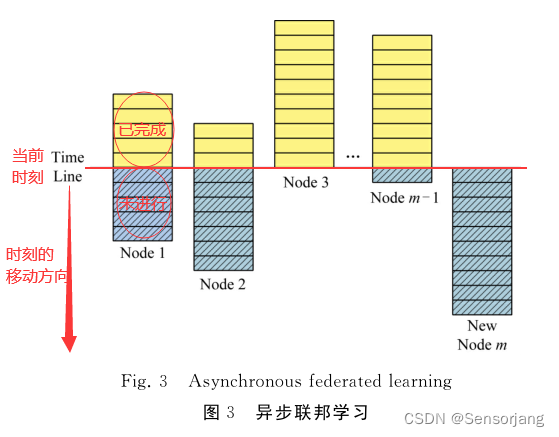
权重分为两个权重:样本权重、参数权重
①样本权重:
②参数权重:受梯度的目标参数与当前全参数数据在时间上的相近程度所影响
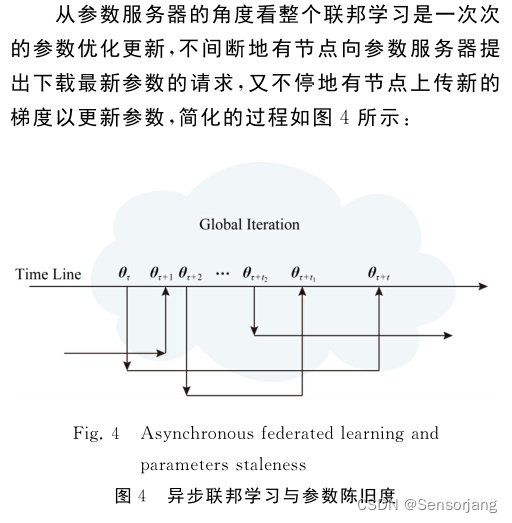
定义优化过程中的 陈旧度
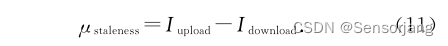
进一步定义参数权重:

在使用边缘节点提交的梯度对全局模型优化之前,需要对梯度进行 双重权重修正,在此之后才可继续参与全局模型的优化:

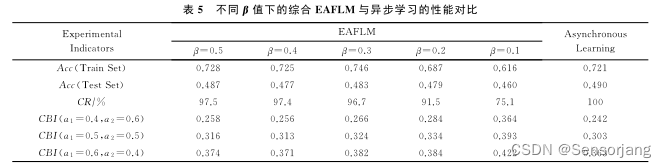
在前面的文章可以知道,对于本文的实验,参数权重中的数值α取0.9,阈值自适应梯度压缩中的D取1。
实验配置:
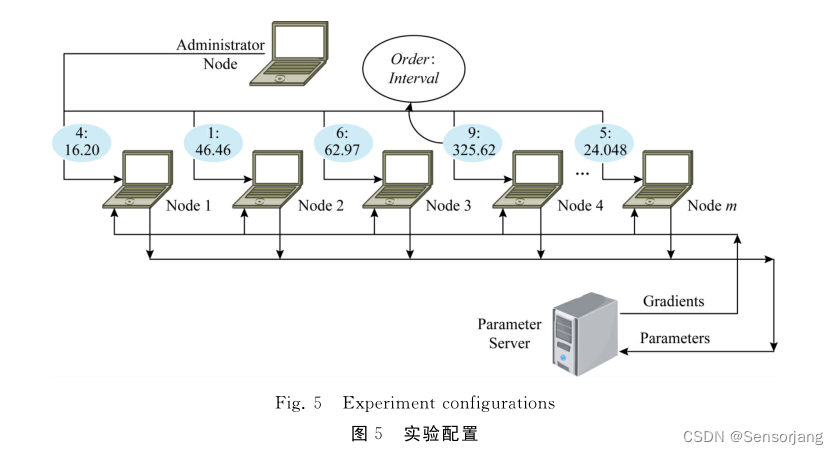
评价指标:
准确率Acc(指Top-1 Accuracy):越高越好
压缩率CR:越低压缩程度越强
压缩平衡指数CBI:
实验结果:
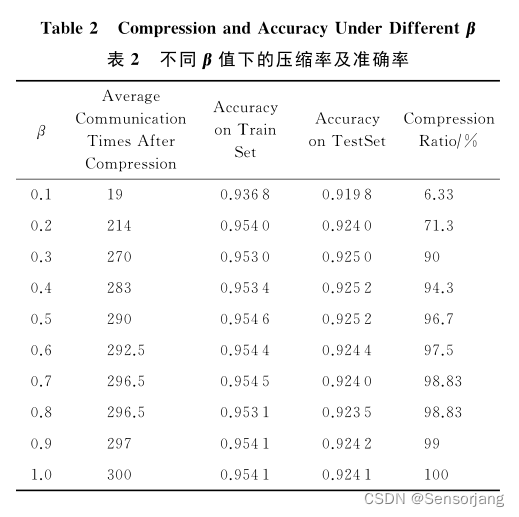
(β是前文中的比例系数,其实就是所有节点中lazy节点数量所占的比例)
图表: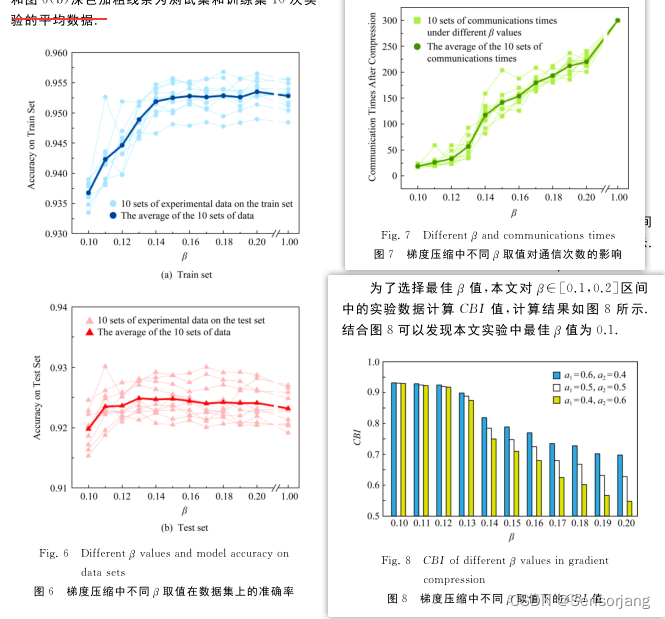
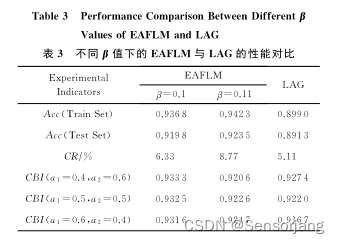
EAFLM与LAG性能对比:
exe应该在我打开页面时运行。异步进程需要运行。有什么方法可以在ruby中使用两个参数异步运行exe吗?我已经尝试过ruby命令-system()、exec()但它正在等待过程完成。我需要用参数启动exe,无需等待进程完成是否有任何rubygems会支持我的问题? 最佳答案 您可以使用Process.spawn和Process.wait2:pid=Process.spawn'your.exe','--option'#Later...pid,status=Process.wait2pid您的程序将作为解释器的子进程执行。除
这里是Ruby新手。完成一些练习后碰壁了。练习:计算一系列成绩的字母等级创建一个方法get_grade来接受测试分数数组。数组中的每个分数应介于0和100之间,其中100是最大分数。计算平均分并将字母等级作为字符串返回,即“A”、“B”、“C”、“D”、“E”或“F”。我一直返回错误:avg.rb:1:syntaxerror,unexpectedtLBRACK,expecting')'defget_grade([100,90,80])^avg.rb:1:syntaxerror,unexpected')',expecting$end这是我目前所拥有的。我想坚持使用下面的方法或.join,
目录前言滤波电路科普主要分类实际情况单位的概念常用评价参数函数型滤波器简单分析滤波电路构成低通滤波器RC低通滤波器RL低通滤波器高通滤波器RC高通滤波器RL高通滤波器部分摘自《LC滤波器设计与制作》,侵权删。前言最近需要学习放大电路和滤波电路,但是由于只在之前做音乐频谱分析仪的时候简单了解过一点点运放,所以也是相当从零开始学习了。滤波电路科普主要分类滤波器:主要是从不同频率的成分中提取出特定频率的信号。有源滤波器:由RC元件与运算放大器组成的滤波器。可滤除某一次或多次谐波,最普通易于采用的无源滤波器结构是将电感与电容串联,可对主要次谐波(3、5、7)构成低阻抗旁路。无源滤波器:无源滤波器,又称
最近在学习CAN,记录一下,也供大家参考交流。推荐几个我觉得很好的CAN学习,本文也是在看了他们的好文之后做的笔记首先是瑞萨的CAN入门,真的通透;秀!靠这篇我竟然2天理解了CAN协议!实战STM32F4CAN!原文链接:https://blog.csdn.net/XiaoXiaoPengBo/article/details/116206252CAN详解(小白教程)原文链接:https://blog.csdn.net/xwwwj/article/details/105372234一篇易懂的CAN通讯协议指南1一篇易懂的CAN通讯协议指南1-知乎(zhihu.com)视频推荐CAN总线个人知识总
深度学习部署:Windows安装pycocotools报错解决方法1.pycocotools库的简介2.pycocotools安装的坑3.解决办法更多Ai资讯:公主号AiCharm本系列是作者在跑一些深度学习实例时,遇到的各种各样的问题及解决办法,希望能够帮助到大家。ERROR:Commanderroredoutwithexitstatus1:'D:\Anaconda3\python.exe'-u-c'importsys,setuptools,tokenize;sys.argv[0]='"'"'C:\\Users\\46653\\AppData\\Local\\Temp\\pip-instal
项目介绍随着我国经济迅速发展,人们对手机的需求越来越大,各种手机软件也都在被广泛应用,但是对于手机进行数据信息管理,对于手机的各种软件也是备受用户的喜爱小学生兴趣延时班预约小程序的设计与开发被用户普遍使用,为方便用户能够可以随时进行小学生兴趣延时班预约小程序的设计与开发的数据信息管理,特开发了小程序的设计与开发的管理系统。小学生兴趣延时班预约小程序的设计与开发的开发利用现有的成熟技术参考,以源代码为模板,分析功能调整与小学生兴趣延时班预约小程序的设计与开发的实际需求相结合,讨论了小学生兴趣延时班预约小程序的设计与开发的使用。开发环境开发说明:前端使用微信微信小程序开发工具:后端使用ssm:VU
我对如何计算通过{%assignvar=0%}赋值的变量加一完全感到困惑。这应该是最简单的任务。到目前为止,这是我尝试过的:{%assignamount=0%}{%forvariantinproduct.variants%}{%assignamount=amount+1%}{%endfor%}Amount:{{amount}}结果总是0。也许我忽略了一些明显的东西。也许有更好的方法。我想要存档的只是获取运行的迭代次数。 最佳答案 因为{{incrementamount}}将输出您的变量值并且不会影响{%assign%}定义的变量,我
在我做的一些网络开发中,我有多个操作开始,比如对外部API的GET请求,我希望它们同时开始,因为一个不依赖另一个的结果。我希望事情能够在后台运行。我找到了concurrent-rubylibrary这似乎运作良好。通过将其混合到您创建的类中,该类的方法具有在后台线程上运行的异步版本。这导致我编写如下代码,其中FirstAsyncWorker和SecondAsyncWorker是我编写的类,我在其中混合了Concurrent::Async模块,并编写了一个名为“work”的方法来发送HTTP请求:defindexop1_result=FirstAsyncWorker.new.async.
我最喜欢的Google文档功能之一是它会在我工作时不断自动保存我的文档版本。这意味着即使我在进行关键更改之前忘记在某个点进行保存,也很有可能会自动创建一个保存点。至少,我可以将文档恢复到错误更改之前的状态,并从该点继续工作。对于在MacOS(或UNIX)上运行的Ruby编码器,是否有具有等效功能的工具?例如,一个工具会每隔几分钟自动将Gitcheckin我的本地存储库以获取我正在处理的文件。也许我有点偏执,但这点小保险可以让我在日常工作中安心。 最佳答案 虚拟机有些人可能讨厌我对此的回应,但我在编码时经常使用VIM,它具有自动保存功
给定一个nxmbool数组:[[true,true,false],[false,true,true],[false,true,true]]有什么简单的方法可以返回“该列中有多少个true?”结果应该是[1,3,2] 最佳答案 使用转置得到一个数组,其中每个子数组代表一列,然后将每一列映射到其中的true数:arr.transpose.map{|subarr|subarr.count(true)}这是一个带有inject的版本,应该在1.8.6上运行,没有任何依赖:arr.transpose.map{|subarr|subarr.in