| ip地址 | 主机名 | 部署服务 |
| 192.168.121.140 | hadoop01 | NameNode,DataNode,JobHistoryServer |
| 192.168.121.141 | hadoop02 | DataNode |
| 192.168.121.142 | hadoop03 | DataNode,SecondaryNameNode |
| ip地址 | 主机名 | 部署服务 |
| 192.168.121.140 | hadoop01 | NodeManager |
| 192.168.121.141 | hadoop02 | ResourceManager,NodeManager |
| 192.168.121.142 | hadoop03 | NodeManager |
| ip地址 | 主机名 |
| 192.168.121.140 | hadoop01 |
| 192.168.121.141 | hadoop02 |
| 192.168.121.142 | hadoop03 |
# 此处修改主机名,3台机器的主机名需要都不同
[root@hadoop01 ~]# vim /etc/hostname
[root@hadoop01 ~]# cat /etc/hostname
hadoop01
[root@hadoop01 ~]# vim /etc/hosts
[root@hadoop01 ~]# cat /etc/hosts | grep hadoop*
192.168.121.140 hadoop01
192.168.121.141 hadoop02
192.168.121.142 hadoop03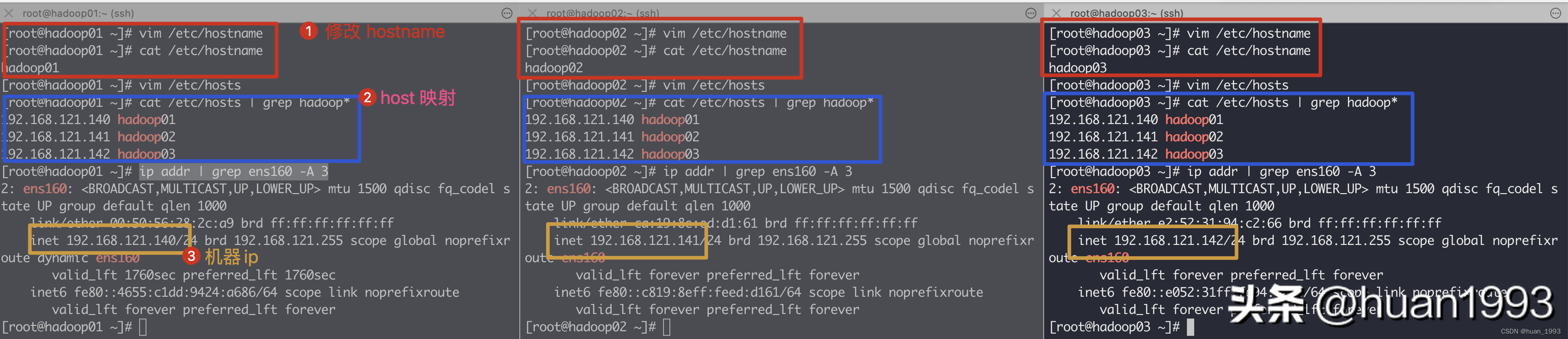 修改主机名和host映射
修改主机名和host映射# 将centos7的时区设置成上海
[root@hadoop01 ~]# ln -sf /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
# 安装ntp
[root@hadoop01 ~]# yum install ntp
已加载插件:fastestmirror
Loading mirror speeds from cached hostfile
base | 3.6 kB 00:00
extras | 2.9 kB 00:00
updates | 2.9 kB 00:00
软件包 ntp-4.2.6p5-29.el7.centos.2.aarch64 已安装并且是最新版本
无须任何处理
# 将ntp设置成缺省启动
[root@hadoop01 ~]# systemctl enable ntpd
# 重启ntp服务
[root@hadoop01 ~]# service ntpd restart
Redirecting to /bin/systemctl restart ntpd.service
# 对准时间
[root@hadoop01 ~]# ntpdate asia.pool.ntp.org
19 Feb 12:36:22 ntpdate[1904]: the NTP socket is in use, exiting
# 对准硬件时间和系统时间
[root@hadoop01 ~]# /sbin/hwclock --systohc
# 查看时间
[root@hadoop01 ~]# timedatectl
Local time: 日 2023-02-19 12:36:35 CST
Universal time: 日 2023-02-19 04:36:35 UTC
RTC time: 日 2023-02-19 04:36:35
Time zone: Asia/Shanghai (CST, +0800)
NTP enabled: yes
NTP synchronized: no
RTC in local TZ: no
DST active: n/a
# 开始自动时间和远程ntp时间进行同步
[root@hadoop01 ~]# timedatectl set-ntp true# 关闭防火墙
[root@hadoop01 ~]# systemctl stop firewalld
systemctl stop firewalld
# 关闭防火墙开机自启
[root@hadoop01 ~]# systemctl disable firewalld.service
Removed symlink /etc/systemd/system/multi-user.target.wants/firewalld.service.
Removed symlink /etc/systemd/system/dbus-org.fedoraproject.FirewallD1.service.
[root@hadoop01 ~]#[root@hadoop01 ~]# useradd hadoopdeploy
[root@hadoop01 ~]# passwd hadoopdeploy
更改用户 hadoopdeploy 的密码 。
新的 密码:
无效的密码: 密码包含用户名在某些地方
重新输入新的 密码:
passwd:所有的身份验证令牌已经成功更新。
[root@hadoop01 ~]# vim /etc/sudoers
[root@hadoop01 ~]# cat /etc/sudoers | grep hadoopdeploy
hadoopdeploy ALL=(ALL) NOPASSWD: ALL
[root@hadoop01 ~]# 新建hadoop部署用户
新建hadoop部署用户# 切换到 hadoopdeploy 用户
[root@hadoop01 ~]# su - hadoopdeploy
Last login: Sun Feb 19 13:05:43 CST 2023 on pts/0
# 生成公私钥对,下方的提示直接3个回车即可
[hadoopdeploy@hadoop01 ~]$ ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/home/hadoopdeploy/.ssh/id_rsa):
Created directory '/home/hadoopdeploy/.ssh'.
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /home/hadoopdeploy/.ssh/id_rsa.
Your public key has been saved in /home/hadoopdeploy/.ssh/id_rsa.pub.
The key fingerprint is:
SHA256:PFvgTUirtNLwzDIDs+SD0RIzMPt0y1km5B7rY16h1/E hadoopdeploy@hadoop01
The key's randomart image is:
+---[RSA 2048]----+
|B . . |
| B o . o |
|+ * * + + . |
| O B / = + |
|. = @ O S o |
| o * o * |
| = o o E |
| o + |
| . |
+----[SHA256]-----+
[hadoopdeploy@hadoop01 ~]$ ssh-copy-id hadoop01
...
[hadoopdeploy@hadoop01 ~]$ ssh-copy-id hadoop02
...
[hadoopdeploy@hadoop01 ~]$ ssh-copy-id hadoop03# 创建 /opt/bigdata 目录
[hadoopdeploy@hadoop01 ~]$ sudo mkdir /opt/bigdata
# 将 /opt/bigdata/ 目录及它下方所有的子目录的所属者和所属组都给 hadoopdeploy
[hadoopdeploy@hadoop01 ~]$ sudo chown -R hadoopdeploy:hadoopdeploy /opt/bigdata/
[hadoopdeploy@hadoop01 ~]$ ll /opt
total 0
drwxr-xr-x. 2 hadoopdeploy hadoopdeploy 6 Feb 19 13:15 bigdata# 进入目录
[hadoopdeploy@hadoop01 ~]$ cd /opt/bigdata/
# 下载
[hadoopdeploy@hadoop01 ~]$ https://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-3.3.4/hadoop-3.3.4.tar.gz
# 解压并压缩
[hadoopdeploy@hadoop01 bigdata]$ tar -zxvf hadoop-3.3.4.tar.gz && rm -rvf hadoop-3.3.4.tar.gz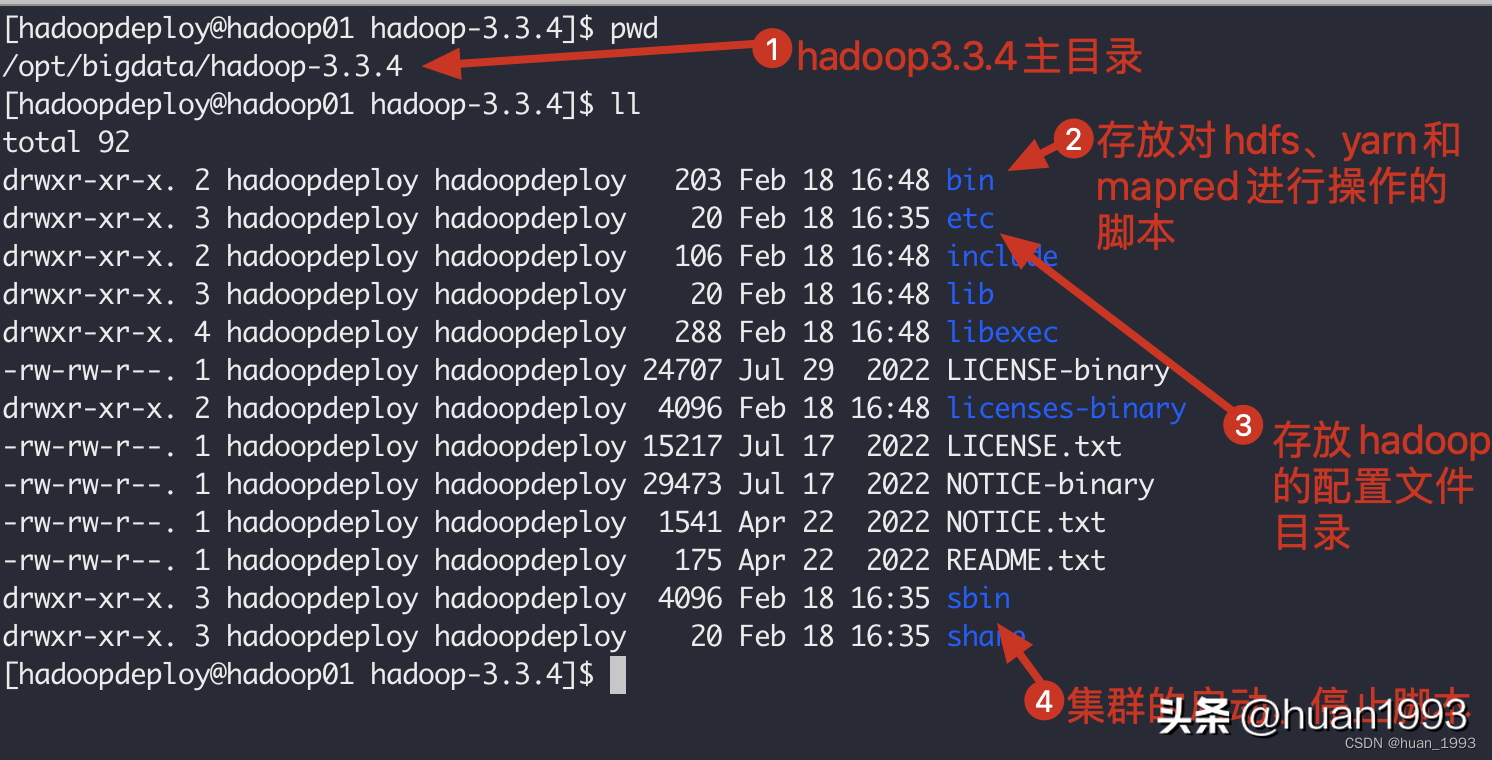 hadoop的目录结构
hadoop的目录结构# 进入hadoop目录
[hadoopdeploy@hadoop01 hadoop-3.3.4]$ cd /opt/bigdata/hadoop-3.3.4/
# 切换到root用户
[hadoopdeploy@hadoop01 hadoop-3.3.4]$ su - root
Password:
Last login: Sun Feb 19 13:06:41 CST 2023 on pts/0
[root@hadoop01 ~]# vim /etc/profile
# 查看hadoop环境变量配置
[root@hadoop01 ~]# tail -n 3 /etc/profile
# 配置HADOOP
export HADOOP_HOME=/opt/bigdata/hadoop-3.3.4/
export PATH=${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:$PATH
# 让环境变量生效
[root@hadoop01 ~]# source /etc/profile hadoop的配置文件
hadoop的配置文件# 切换到hadoopdeploy用户
[root@hadoop01 ~]# su - hadoopdeploy
Last login: Sun Feb 19 14:22:50 CST 2023 on pts/0
# 进入到hadoop的配置目录
[hadoopdeploy@hadoop01 ~]$ cd /opt/bigdata/hadoop-3.3.4/etc/hadoop/
[hadoopdeploy@hadoop01 hadoop]$ vim hadoop-env.sh
# 增加如下内容
export JAVA_HOME=/usr/local/jdk8
export HDFS_NAMENODE_USER=hadoopdeploy
export HDFS_DATANODE_USER=hadoopdeploy
export HDFS_SECONDARYNAMENODE_USER=hadoopdeploy
export YARN_RESOURCEMANAGER_USER=hadoopdeploy
export YARN_NODEMANAGER_USER=hadoopdeploy<configuration>
<!-- 指定NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop01:8020</value>
</property>
<!-- 指定hadoop数据的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/bigdata/hadoop-3.3.4/data</value>
</property>
<!-- 配置HDFS网页登录使用的静态用户为hadoopdeploy,如果不配置的话,当在hdfs页面点击删除时>看看结果 -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>hadoopdeploy</value>
</property>
<!-- 文件垃圾桶保存时间 -->
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
</configuration><configuration>
<!-- 配置2个副本 -->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<!-- nn web端访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop01:9870</value>
</property>
<!-- snn web端访问地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop03:9868</value>
</property>
</configuration><configuration>
<!-- Site specific YARN configuration properties -->
<!-- 指定ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop02</value>
</property>
<!-- 指定MR走shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 是否对容器实施物理内存限制 -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!-- 是否对容器实施虚拟内存限制 -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<!-- 设置 yarn 历史服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop02:19888/jobhistory/logs</value>
</property>
<!-- 开启日志聚集-->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 聚集日志保留的时间7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
</configuration><configuration>
<!-- 设置 MR 程序默认运行模式:yarn 集群模式,local 本地模式-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- MR 程序历史服务地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop01:10020</value>
</property>
<!-- MR 程序历史服务器 web 端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop01:19888</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
</configuration>hadoop01
hadoop02
hadoop03# 同步 hadoop 文件
[hadoopdeploy@hadoop01 hadoop]$ scp -r /opt/bigdata/hadoop-3.3.4/ hadoopdeploy@hadoop02:/opt/bigdata/hadoop-3.3.4
[hadoopdeploy@hadoop01 hadoop]$ scp -r /opt/bigdata/hadoop-3.3.4/ hadoopdeploy@hadoop03:/opt/bigdata/hadoop-3.3.4[hadoopdeploy@hadoop03 bigdata]$ su - root
Password:
Last login: Sun Feb 19 13:07:40 CST 2023 on pts/0
[root@hadoop03 ~]# vim /etc/profile
[root@hadoop03 ~]# tail -n 4 /etc/profile
# 配置HADOOP
export HADOOP_HOME=/opt/bigdata/hadoop-3.3.4/
export PATH=${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:$PATH
[root@hadoop03 ~]# source /etc/profile[hadoopdeploy@hadoop01 hadoop]$ hdfs namenode -format# HDFS 集群
[hadoopdeploy@hadoop01 hadoop]$ hdfs --daemon start namenode | datanode | secondarynamenode
# YARN 集群
[hadoopdeploy@hadoop01 hadoop]$ hdfs yarn --daemon start resourcemanager | nodemanager | proxyserver# 改脚本启动集群中的 NameNode、DataNode和SecondaryNameNode
[hadoopdeploy@hadoop01 hadoop]$ start-dfs.sh# 该脚本启动集群中的 ResourceManager 和 NodeManager 进程
[hadoopdeploy@hadoop02 hadoop]$ start-yarn.sh[hadoopdeploy@hadoop01 hadoop]$ mapred --daemon start historyserver 查看各个机器上启动的服务是否和我们规划的一致 查看各个机器上启动的服务是否和我们规划的一致可以看到是一致的。
查看各个机器上启动的服务是否和我们规划的一致 查看各个机器上启动的服务是否和我们规划的一致可以看到是一致的。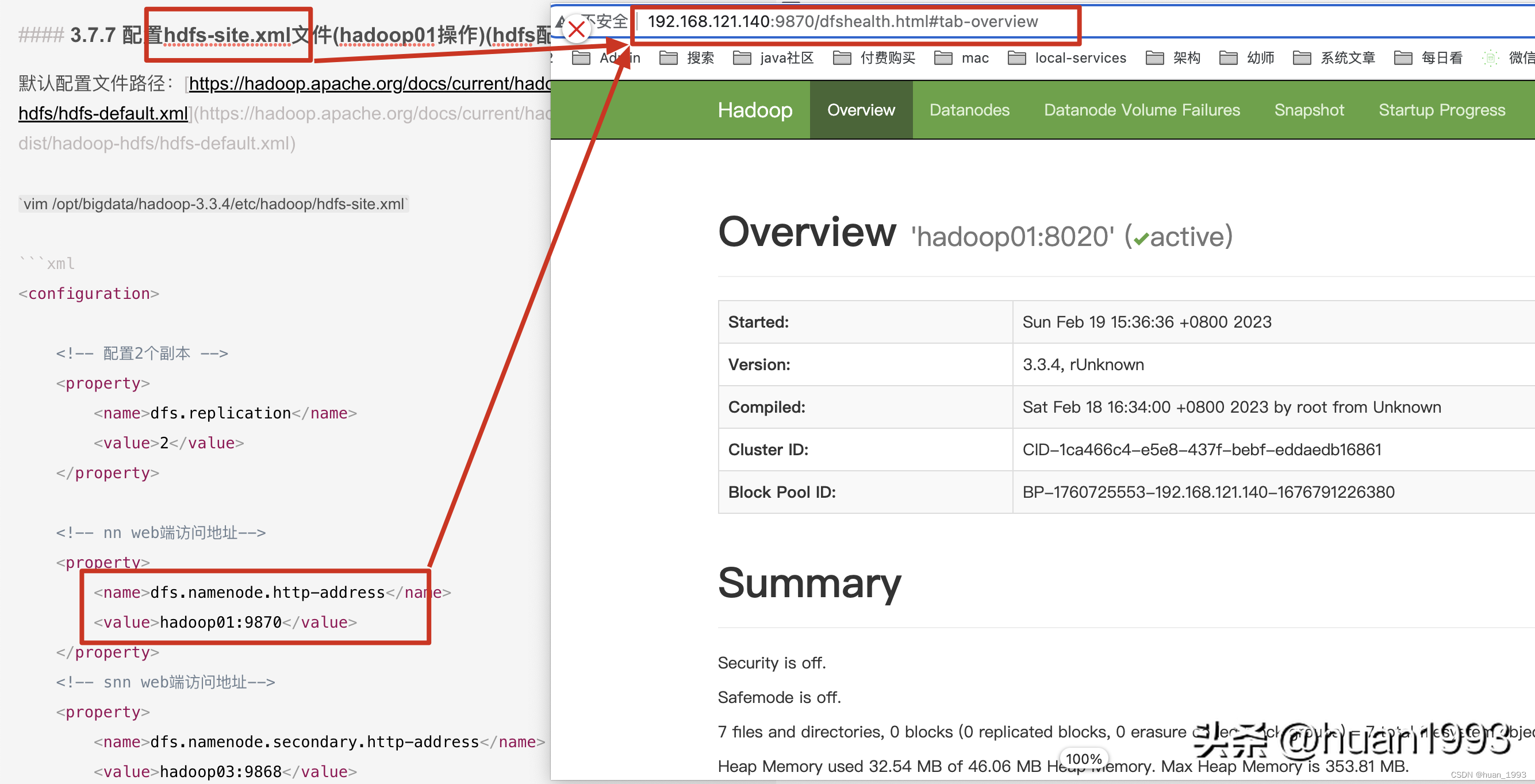 访问NameNode ui如果这个时候通过 hadoop fs 命令可以上传文件,但是在这个web界面上可以创建文件夹,但是上传文件报错,此处就需要在访问ui界面的这个电脑的hosts文件中,将部署hadoop的那几台的电脑的ip 和hostname 在本机上进行映射。
访问NameNode ui如果这个时候通过 hadoop fs 命令可以上传文件,但是在这个web界面上可以创建文件夹,但是上传文件报错,此处就需要在访问ui界面的这个电脑的hosts文件中,将部署hadoop的那几台的电脑的ip 和hostname 在本机上进行映射。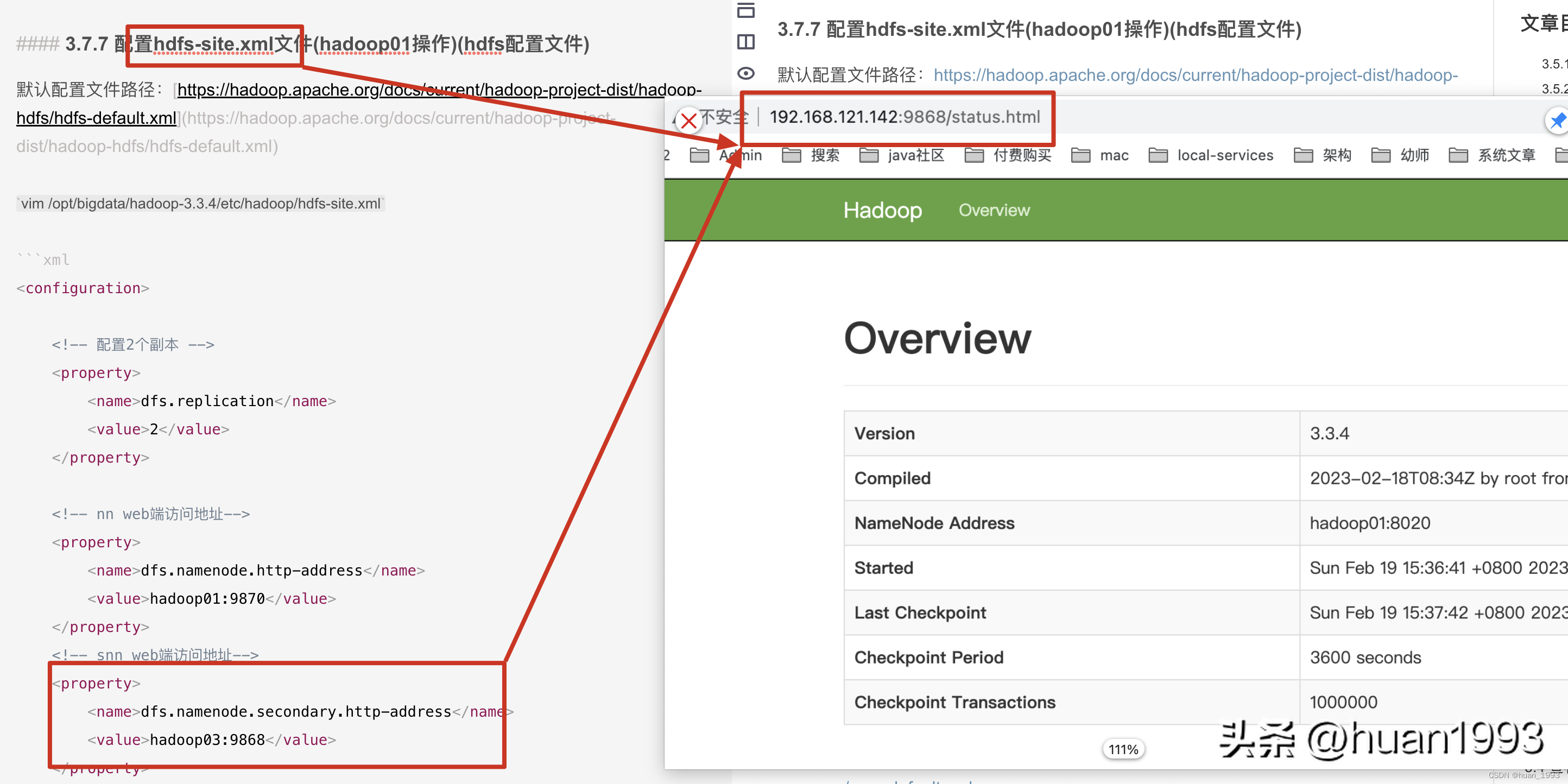 访问SecondaryNameNode ui
访问SecondaryNameNode ui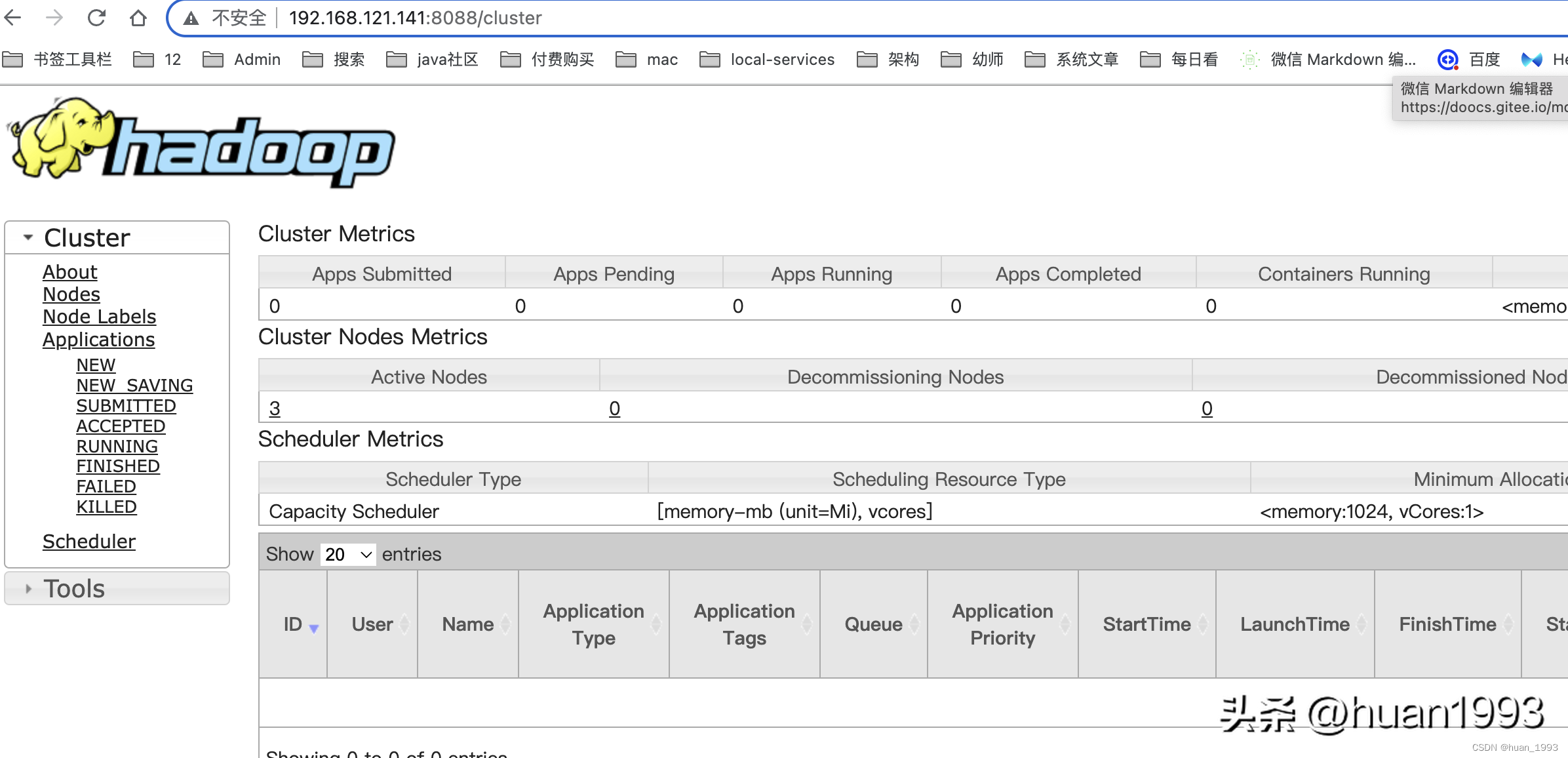 查看ResourceManager ui
查看ResourceManager ui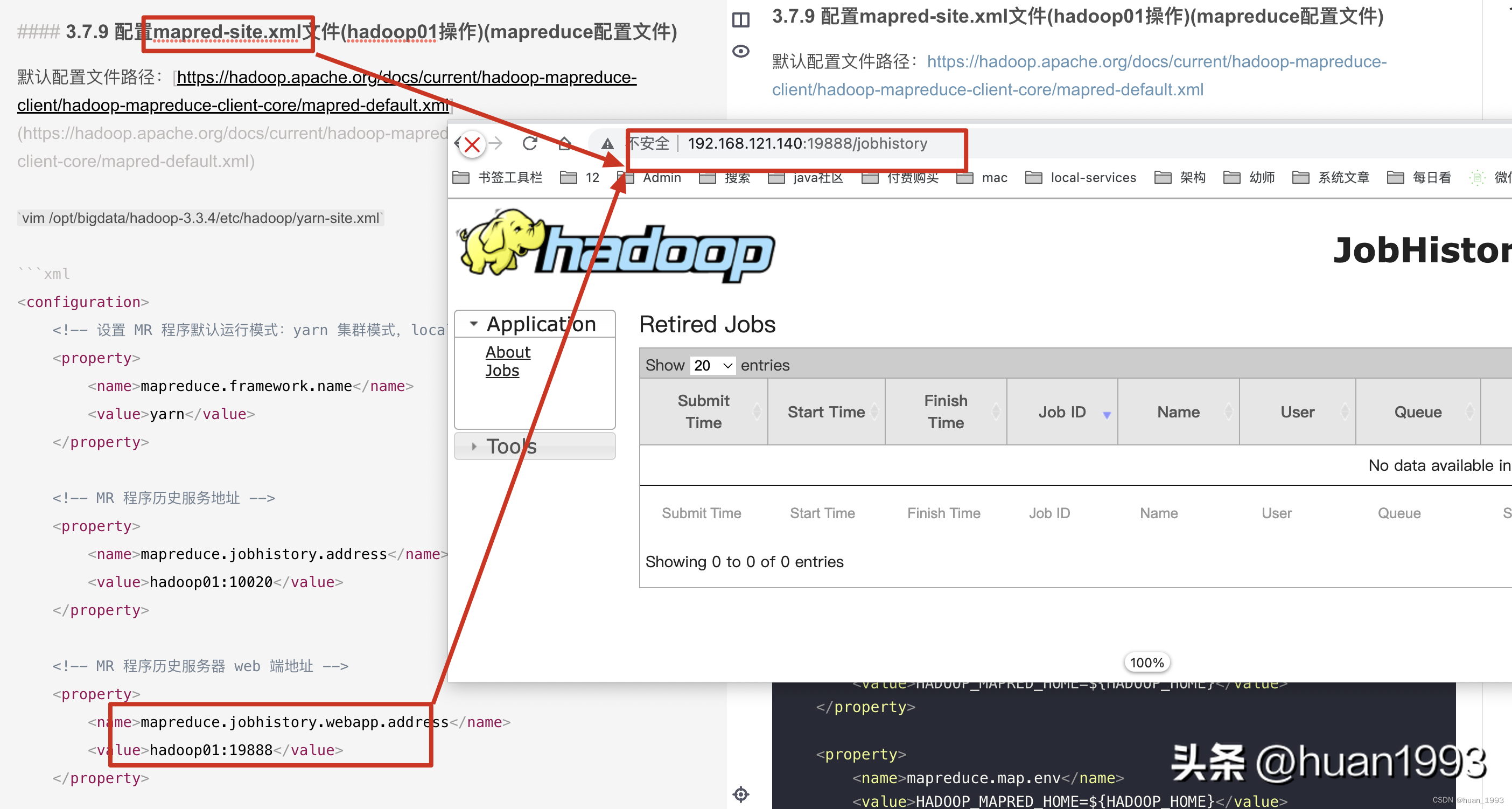 访问jobhistory
访问jobhistory我正在尝试在我的centos服务器上安装therubyracer,但遇到了麻烦。$geminstalltherubyracerBuildingnativeextensions.Thiscouldtakeawhile...ERROR:Errorinstallingtherubyracer:ERROR:Failedtobuildgemnativeextension./usr/local/rvm/rubies/ruby-1.9.3-p125/bin/rubyextconf.rbcheckingformain()in-lpthread...yescheckingforv8.h...no***e
我有一个涉及多台机器、消息队列和事务的问题。因此,例如用户点击网页,点击将消息发送到另一台机器,该机器将付款添加到用户的帐户。每秒可能有数千次点击。事务的所有方面都应该是容错的。我以前从未遇到过这样的事情,但一些阅读表明这是一个众所周知的问题。所以我的问题。我假设安全的方法是使用两阶段提交,但协议(protocol)是阻塞的,所以我不会获得所需的性能,我是否正确?我通常写Ruby,但似乎Redis之类的数据库和Rescue、RabbitMQ等消息队列系统对我的帮助不大——即使我实现某种两阶段提交,如果Redis崩溃,数据也会丢失,因为它本质上只是内存。所有这些让我开始关注erlang和
需求:要创建虚拟机,就需要给他提供一个虚拟的磁盘,我们就在/opt目录下创建一个10G大小的raw格式的虚拟磁盘CentOS-7-x86_64.raw命令格式:qemu-imgcreate-f磁盘格式磁盘名称磁盘大小qemu-imgcreate-f磁盘格式-o?1.创建磁盘qemu-imgcreate-fraw/opt/CentOS-7-x86_64.raw10G执行效果#ls/opt/CentOS-7-x86_64.raw2.安装虚拟机使用virt-install命令,基于我们提供的系统镜像和虚拟磁盘来创建一个虚拟机,另外在创建虚拟机之前,提前打开vnc客户端,在创建虚拟机的时候,通过vnc
1.1.1 YARN的介绍 为克服Hadoop1.0中HDFS和MapReduce存在的各种问题⽽提出的,针对Hadoop1.0中的MapReduce在扩展性和多框架⽀持⽅⾯的不⾜,提出了全新的资源管理框架YARN. ApacheYARN(YetanotherResourceNegotiator的缩写)是Hadoop集群的资源管理系统,负责为计算程序提供服务器计算资源,相当于⼀个分布式的操作系统平台,⽽MapReduce等计算程序则相当于运⾏于操作系统之上的应⽤程序。 YARN被引⼊Hadoop2,最初是为了改善MapReduce的实现,但是因为具有⾜够的通⽤性,同样可以⽀持其他的分布式计算模
我有一个启动DRb服务的脚本,然后生成处理程序对象并通过DRb.thread.join等待。我希望脚本一直运行直到被明确杀死,所以我添加了trap"INT"doDRb.stop_serviceend在Ruby1.8下成功停止DRb服务并退出,但在1.9下似乎死锁(在OSX10.6.7上)。对该进程进行采样显示在semaphore_wait_signal_trap中有几个线程在旋转。我假设我在调用stop_service时做错了什么,但我不确定是什么。谁能给我任何关于如何正确处理它的指示? 最佳答案 好的,我想我已经找到了解决方案。如
require'openssl'ifARGV.length==2pkcs12=OpenSSL::PKCS12.new(File.read(ARGV[0]),ARGV[1])ppkcs12.certificateelseputs"Usage:load_cert.rb"end运行它会在Windows上产生错误,但在Linux上不会。错误:OpenSSL::PKCS12::PKCS12Error:PKCS12_parse:macverifyfailurefrom(irb):21:ininitializefrom(irb):21:innewfrom(irb):21fromC:/Ruby192/
一、相关网址1、官网(可以下载,查看文章)https://skywalking.apache.org/downloads/2、github地址:(可提问题寻求帮助)https://github.com/apache/skywalking二、 实验环境操作系统 centos7.9先安装好 elasticsearch7.16.2操作系统安装好jdk8-17,实验机器jdk11java下载地址:https://www.oracle.com/java/technologies/downloads/#java8IP地址为192.168.24.160三、安装skywalking 1、下载skywalkin
目录1、yum安装mysql修改密码(1)在mysql里面修改(2)第二种方式,利用mysqladmin修改密码2、没有密码,登录mysql修改密码3、mysql的安全设置1、yum安装mysql在CentOS中默认安装有MariaDB(MySQL的一个分支),安装完成之后可以直接覆盖MariaDB。rpm-qa|grepmariadb查询是否安装了mariadbrpm-e--nodepsmariadb-libs-5.5.60-1.el7_5.x86_64卸载mariadwgethttp://dev.mysql.com/get/mysql57-community-release-el7-11.
Nginx安装1.官网下载Nginx2.使用XShell和Xftp将压缩包上传到Linux虚拟机中3.解压文件nginx-1.20.2.tar.gz4.配置nginx5.启动nginx6.拓展(修改端口和常用命令)(一)修改nginx端口(二)常用命令1.官网下载Nginxhttp://nginx.org/en/download.html这里我下载的是1.20.2版本,大家按需下载对应稳定版即可2.使用XShell和Xftp将压缩包上传到Linux虚拟机中没有XShell可以参考《Linux操作系统CentOS7连接XShell》3.解压文件nginx-1.20.2.tar.gz1)检查是否存
目录:一、简介二、HQL的执行流程三、索引四、索引案例五、Hive常用DDL操作六、Hive常用DML操作七、查询结果插入到表八、更新和删除操作九、查询结果写出到文件系统十、HiveCLI和Beeline命令行的基本使用十一、Hive配置一、简介Hive是一个构建在Hadoop之上的数据仓库,它可以将结构化的数据文件映射成表,并提供类SQL查询功能,用于查询的SQL语句会被转化为MapReduce作业,然后提交到Hadoop上运行。特点:简单、容易上手(提供了类似sql的查询语言hql),使得精通sql但是不了解Java编程的人也能很好地进行大数据分析;灵活性高,可以自定义用户函数(UDF)和