又称多表查询,当查询的字段涉及多个表的时候,就要用到连接查询
分类:
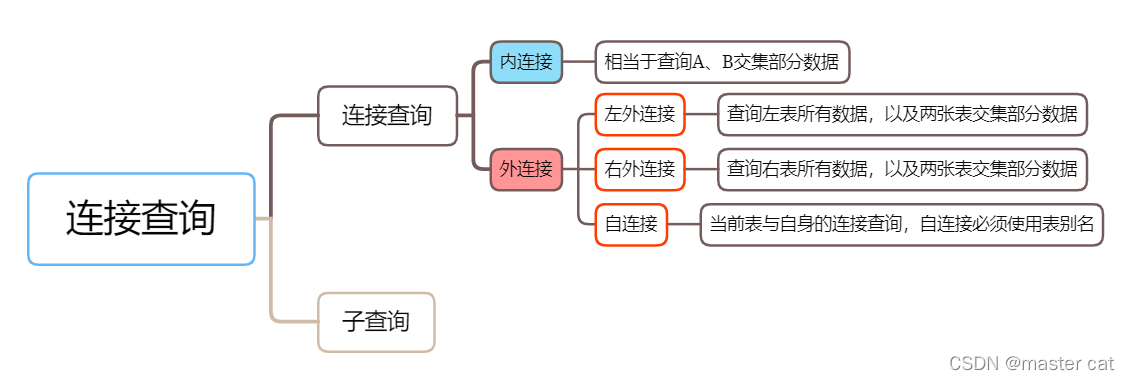
为表起别名:
查询A、B 交集部分数据
语法:
隐式内连接
select 字段列表 from 表1,表2 where 筛选条件 ;
显式内连接
select 字段列表 from 表1 【inner】 join 表2 on 连接条件 ... ;
查询每一个员工的姓名 , 及关联的部门的名称
表结构: emp , dept
连接条件: emp.dept_id = dept.id
select emp.name , dept.name from emp , dept where emp.dept_id = dept.id ;
若果有员工没有部门,则不会显示
select e.name, d.name
from emp as e
join dept as d
on e.dept_id = d.id;
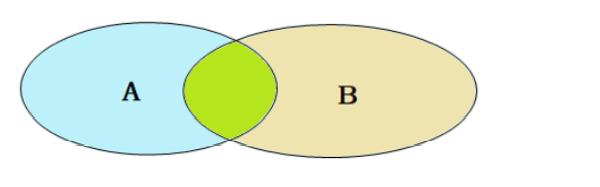
左外连接相当于查询表A(左表)的所有数据和中间绿色的交集部分的数据。
表1的位置为左表,表2的位置为右表
select 字段列表
from 表1
left 【outer】 join 表2
on 条件...
select 字段列表
from 表1
right 【outer】 join 表2
on 条件...
想把右外连接改成左外连接,并且查询结果不改变,可以把right改为left,并且把表1和表2的位置调换
例题:
select e.*, d.name
from emp as e
left outer join dept as d
on e.dept_id = d.id
表结构: emp, dept
连接条件: emp.dept_id = dept.id
(右外连接)
select d.*, e.*
from emp e # 左表
right outer join dept as d # 右表
on e.dept_id = d.id;
将右外改为左外
select d.*, e.*
from dept as d
left outer join emp as e
on e.dept_id = d.id;
自连接查询,顾名思义,就是自己连接自己,也就是把一张表连接查询多次。
select 字段列表
from 表1 as 别名1
join 表1 as 别名2
on 条件....
注意:自连接表一定要起别名
对于自连接查询,可以是内连接查询,也可以是外连接查询。
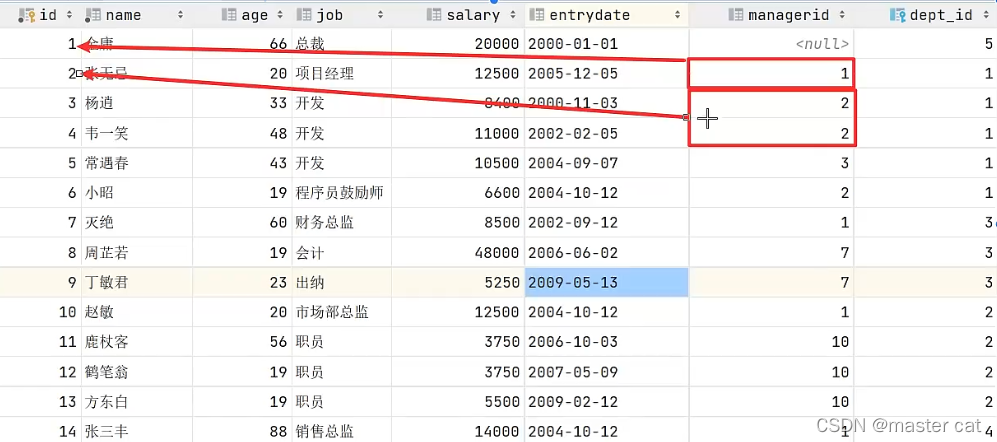
普通员工和领导其实都属于员工,都在员工表当中,每个员工又有一项manager_id记录这他的领导的id值
用内连接
select a.name , b.name
from emp as a , emp as b
where a.managerid = b.id;
select a.name as '员工', b.name as '领导'
from emp as a
left join emp as b
on a.managerid = b.id;
select g_name,b_name from boy,beartywhere girl.boufriend_id = boy.id 会用第一个表中的每一行和第二个表中的每一行进行逐个匹配,然后进行筛选,如果匹配会筛选出来
可以自由调换表的顺序
select last_name,department_namefrom employees,departmentwhere employees.'department_id',department.'department_id' 当语句中经常出表名作用域的时候,每条语句就会很长,为精简语句
select e.last_name,e.job_id,j.job_title from employees as e , job as j where e.'job_id'= j.job_id查询有奖金的员工名、部门名
select last_name,department_name
from employees as e , department as d
where e.'department_id' = d.'department_id'
and e.'commission_pct'is not null 已经有一个where筛选了不能再用where,用and
查询城市名中第二个字符为o的部门名和城市名
select department_name,city
from department as d,location as l
where d.'location_id' = l.'location_id'
and city like '_o%'
查询每个城市的部门个数
select count(*) as 个数 , city
from department as d = location as l
group by city
查询有奖金的每个部门的部门名,和部门的领导编号和该部门的最低工资标准
select department_name , manager_id,min(salary)
from employees as e , department as d
where e.'department_id' = d.'department_id'
and commission_pct is not null
group by department_name,d,manager_id ;
select job_title , count(*) from employees as e , job as j where e.'job_id'= j.job_idgroup by job_titleorder by count(*) desc select last_name,department_name,cityfrom employees as e , department as d , location as lwhere e.'department_id' = d.'department_id' and d.'location_id' = l.'location_id'也就是把上面的等于号换成了不等于(大于、小于、不等)
select salary,grade_levelfrom employees e,job_frades gwhere salary between g.'lowest_sal' and g.'higthest_sal'and g.'lowest_sal'='A';只查看等级为A的把原来这一张表当做多张表来使用,由表中的数据找到另一个数据,再由找到的数据回过头来找另一个数据,可以这样往复下去
select e.employee_id,e.last_name,m.employee_id,m.last_namefrom employees.e,employees.me代表员工表,m代表领导表。其实都在一张表里,重命名来避免冲突where e.'manager_id' = m.'employees_id'语法:
select 查寻列表
from 表1 as 别名 【连接类型】
join 表2 as 别名
on【连接条件】
【where 筛选条件】
【group by 分组】
【having 筛选条件】
【order by 排序列表】
查询员工名,部门名
select last_name,department_name
from department d
innner join demployees as e
on e.'department_id' = d.'department_id'
查询名字中包含e的员工名和工种名(添加了筛选条件)
select last_name,job_id
from employees as e
inner join as j
on e.'job_id' = j.'job_id'
where e.'last_name' like '%e%' ;
查询部门个数>3的城市名和部门个数(添加分组、筛选条件)
select city,count(*) as 部门个数
from departments as d
inner hoin locations as l
on d.'location_id' = l.'location_id'
group by city
having count(*)>3
查询哪个部门的员工个数>3的部门名和员工个数,并按个数降序
select count(*) , department_id
from employees as e
inner hoin departments as d
on e.'department_id' = d.'department_id'
group by department_name
having count(*)>3
order by count(*) desc
查询员工的工资级别
select salary,grade_level
from employees as e
join job_grades as g
on e.'salary' between g.'lowest_sal' and g.'hightest_sal' ;
查询每个工资级别的个数,并按照级别降序。
select count(*),grade_level
from employees as e
join job_grades as g
on e.'salary' between g.'lowest_sal' and g.'hightest_sal'
having count(*)>20
order by grade_lecel desc
把原来这一张表当做多张表来使用,由表中的数据找到另一个数据,再由找到的数据回过头来找另一个数据,可以这样往复下去
select m.employee_id,m.last_namefrom employees as e e代表员工表,m代表领导表。其实都在一张表里,重命名来避免冲突join employees as mon e.'manager_id' = m.'employees_id'用于查询主表的时候,主表中没有,但是附表中,主表通过外连接附表来查询数据
特点:
外连接查询结果为主表中的所有数据。
如果主表中有与之匹配的显示匹配值。
表中没有与之匹配的显示null
外连接查询结果=内连接结果+主表中有而从表中没有的数据
左外连接,left join左边的是主表
右外连接,right join右边的是主表。
左外和右外交换两个表的顺序可以实现同样的效果。
查询男朋友 不在男神表的的女神名
左外连接
SELECT b.*,bo.*
FROM boys bo
LEFT OUTER JOIN beauty b
ON b.'boyfriend_id' = bo.'id'
WHERE b.'id' IS NULL;
查询哪个部门没有员工
SELECT d.*,e.employee_idFROM departments dLEFT OUTER JOIN employees eON d.'department_id' = e.'department_id'WHERE e.'employee_id' IS NULL;SELECT d.*,e.employee_idFROM employees eRIGHT OUTER JOIN departments dON d.'department_id' = e.'department_id'WHERE e.'employee_id' IS NULL;全外
USE girls;
SELECT b.*,bo.*
FROM beauty b
FULL OUTER JOIN boys bo
ON b.'boyfriend_id' = bo.id;
SELECT b.*,bo.*
FROM beauty b
CROSS JOIN boys bo;
功能:sql99支持的较多
可读性:sql99实现连接条件和筛选条件的分离,可读性较高
我正在用Ruby编写一个简单的程序来检查域列表是否被占用。基本上它循环遍历列表,并使用以下函数进行检查。require'rubygems'require'whois'defcheck_domain(domain)c=Whois::Client.newc.query("google.com").available?end程序不断出错(即使我在google.com中进行硬编码),并打印以下消息。鉴于该程序非常简单,我已经没有什么想法了-有什么建议吗?/Library/Ruby/Gems/1.8/gems/whois-2.0.2/lib/whois/server/adapters/base.
我正在使用Sequel构建一个愿望list系统。我有一个wishlists和itemstable和一个items_wishlists连接表(该名称是续集选择的名称)。items_wishlists表还有一个用于facebookid的额外列(因此我可以存储opengraph操作),这是一个NOTNULL列。我还有Wishlist和Item具有续集many_to_many关联的模型已建立。Wishlist类也有:selectmany_to_many关联的选项设置为select:[:items.*,:items_wishlists__facebook_action_id].有没有一种方法可以
我知道我可以指定某些字段来使用pluck查询数据库。ids=Item.where('due_at但是我想知道,是否有一种方法可以指定我想避免从数据库查询的某些字段。某种反拔?posts=Post.where(published:true).do_not_lookup(:enormous_field) 最佳答案 Model#attribute_names应该返回列/属性数组。您可以排除其中一些并传递给pluck或select方法。像这样:posts=Post.where(published:true).select(Post.attr
我使用的是Firefox版本36.0.1和Selenium-Webdrivergem版本2.45.0。我能够创建Firefox实例,但无法使用脚本继续进行进一步的操作无法在60秒内获得稳定的Firefox连接(127.0.0.1:7055)错误。有人能帮帮我吗? 最佳答案 我遇到了同样的问题。降级到firefoxv33后一切正常。您可以找到旧版本here 关于ruby-无法在60秒内获得稳定的Firefox连接(127.0.0.1:7055),我们在StackOverflow上找到一个类
文章目录一、概述简介原理模块二、配置Mysql使用版本环境要求1.操作系统2.mysql要求三、配置canal-server离线下载在线下载上传解压修改配置单机配置集群配置分库分表配置1.修改全局配置2.实例配置垂直分库水平分库3.修改group-instance.xml4.启动监听四、配置canal-adapter1修改启动配置2配置映射文件3启动ES数据同步查询所有订阅同步数据同步开关启动4.验证五、配置canal-admin一、概述简介canal是Alibaba旗下的一款开源项目,Java开发。基于数据库增量日志解析,提供增量数据订阅&消费。Git地址:https://github.co
我正在尝试查询我的Rails数据库(Postgres)中的购买表,我想查询时间范围。例如,我想知道在所有日期的下午2点到3点之间进行了多少次购买。此表中有一个created_at列,但我不知道如何在不搜索特定日期的情况下完成此操作。我试过:Purchases.where("created_atBETWEEN?and?",Time.now-1.hour,Time.now)但这最终只会搜索今天与那些时间的日期。 最佳答案 您需要使用PostgreSQL'sdate_part/extractfunction从created_at中提取小时
require"socket"server="irc.rizon.net"port="6667"nick="RubyIRCBot"channel="#0x40"s=TCPSocket.open(server,port)s.print("USERTesting",0)s.print("NICK#{nick}",0)s.print("JOIN#{channel}",0)这个IRC机器人没有连接到IRC服务器,我做错了什么? 最佳答案 失败并显示此消息::irc.shakeababy.net461*USER:Notenoughparame
考虑一下:现在这些情况:#output:http://domain.com/?foo=1&bar=2#output:http://domain.com/?foo=1&bar=2#output:http://domain.com/?foo=1&bar=2#output:http://domain.com/?foo=1&bar=2我需要用其他字符串输出URL。我如何保证&符号不会被转义?由于我无法控制的原因,我无法发送&。求助!把我的头发拉到这里:\编辑:为了澄清,我实际上有一个像这样的数组:@images=[{:id=>"fooid",:url=>"http://
我看到其他人也遇到过类似的问题,但没有一个解决方案对我有用。0.3.14gem与其他gem文件一起存在。我已经完全按照此处指示完成了所有操作:https://github.com/brianmario/mysql2.我仍然得到以下信息。我不知道为什么安装程序指示它找不到include目录,因为我已经检查过它存在。thread.h文件存在,但不在ruby目录中。相反,它在这里:C:\RailsInstaller\DevKit\lib\perl5\5.8\msys\CORE\我正在运行Windows7并尝试在Aptana3中构建我的Rails项目。我的Ruby是1.9.3。$gemin
我有一个super简单的脚本,它几乎包含了FayeWebSocketGitHub页面上用于处理关闭连接的内容:ws=Faye::WebSocket::Client.new(url,nil,:headers=>headers)ws.on:opendo|event|p[:open]#sendpingcommand#sendtestcommand#ws.send({command:'test'}.to_json)endws.on:messagedo|event|#hereistheentrypointfordatacomingfromtheserver.pJSON.parse(event.d