文章目录
本篇博客是根据【狂神说Java】SpringBoot最新教程IDEA版通俗易懂 整理的学习笔记,若文章中出现相关问题,请指出!
所有博客文件目录索引:博客目录索引(持续更新)
安装mysql5.7(或者其他):mysql5.7安装教程
IDEA右边点击Database—+号—选择mysql

填写对应信息

点击测试,可能会出现错误,见下方
出现下方描述即为测试成功!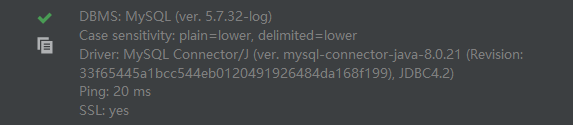
接下来我们在schema中选择对应数据库即可。
错误①
Server returns invalid timezone. Go to 'Advanced' tab and set 'serverTimezone' prope
原因:MySQL驱动jar中的默认时区是UTC
解决方案:在上面的Advanced选项里,填写对应的时区值为Asia/Shanghai

重新连接即可!!!
对于数据访问层,无论是SQL(关系型数据库)还是NOSQL(非关系型数据库),springboot底层都是采用Spring Data的方式进行统一处理。
创建一个springboot项目,启动器选择如下
application.yaml配置:
spring:
datasource:
username: root
password: 123456
# 若是时区报错则添加参数:serverTimezone=Asia/Shanghai&
url: jdbc:mysql://localhost:3306/mybatis?useUnicode=true&characterEncoding=utf-8
# 使用com.mysql.jdbc.Driver测试datasource.getClass()表示过时,可使用com.mysql.cj.jdbc.Driver
driver-class-name: com.mysql.cj.jdbc.Driver
JDBCController:简单测试增删改查
package com.changlu.controller;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.jdbc.core.JdbcTemplate;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.List;
import java.util.Map;
/**
* @ClassName JDBCController
* @Author ChangLu
* @Date 2021/1/4 16:06
*/
@RestController
public class JDBCController {
@Autowired
private JdbcTemplate jdbcTemplate;
//查询数据库的所有信息(查)
//没有实体类,数据库中的信息如何获取? springboot已经直接封装好了
@RequestMapping("/userList")
public List<Map<String,Object>> userList(){
String sql = "select * from user";
//queryForList()方法放入指定查询sql语句即可查询
List<Map<String, Object>> maps = jdbcTemplate.queryForList(sql);
return maps;
}
//增加一条记录(增)
@RequestMapping("/addUser")
public String update(){
String sql = "insert into user(name,pwd,perms) values('林儿','987654','user:add')";
jdbcTemplate.update(sql);
return "addUser success!";
}
//根据指定id来修改数据库的信息(改)
@RequestMapping("/updateUser/{id}")
public String update(@PathVariable("id")Integer id){
String sql = "update mybatis.user set name=?,pwd=? where id="+id;
//需要封装属性
Object[] objects = new Object[2];
objects[0] = "林林";
objects[1] = "99999";
jdbcTemplate.update(sql,objects);
return "updateUser success!";
}
//根据id来删除指定记录(删)
@RequestMapping("/delUser/{id}")
public String delUser(@PathVariable("id")Integer id){
String sql = "delete from mybatis.user where id=?";
jdbcTemplate.update(sql,id);
return "delUser success!";
}
}
启动项目之后,在浏览器中进行请求测试,如下进行增删改查:
http://localhost:8080/userList
http://localhost:8080/addUser
http://localhost:8080/updateUser/4
http://localhost:8080/delUser/4
yaml配置
通过点击yaml配置的数据,我们跳转到DataSourceProperties类中
根据其推测查看一下DataSourceAutoConfiguration这个自动配置类,果然在自动装配时绑定了对应配置类,接着只需通过yaml进行配置
@Configuration(proxyBeanMethods = false)
@ConditionalOnClass({ DataSource.class, EmbeddedDatabaseType.class })
@ConditionalOnMissingBean(type = "io.r2dbc.spi.ConnectionFactory")
@EnableConfigurationProperties(DataSourceProperties.class)
@Import({ DataSourcePoolMetadataProvidersConfiguration.class, DataSourceInitializationConfiguration.class })
public class DataSourceAutoConfiguration {
...
}
Controller分析
这里使用的是JdbcTemplate这个模板类,我们直接通过使用@Autowired获取到bean对象,为什么可以直接获取到呢?
看一下JdbcTemplateConfiguration这个配置类,看到@Bean我们就知道到该模板类是一个javaConfig
@Configuration(proxyBeanMethods = false)
@ConditionalOnMissingBean(JdbcOperations.class)
class JdbcTemplateConfiguration {
@Bean
@Primary
JdbcTemplate jdbcTemplate(DataSource dataSource, JdbcProperties properties) {
JdbcTemplate jdbcTemplate = new JdbcTemplate(dataSource);
JdbcProperties.Template template = properties.getTemplate();
...
}
再看该自动装配类JdbcTemplateAutoConfiguration,其中就使用@Import引进了上面的配置类
@Configuration(proxyBeanMethods = false)
@ConditionalOnClass({ DataSource.class, JdbcTemplate.class })
@ConditionalOnSingleCandidate(DataSource.class)
@AutoConfigureAfter(DataSourceAutoConfiguration.class)
@EnableConfigurationProperties(JdbcProperties.class)
//看这里进行了引入
@Import({ JdbcTemplateConfiguration.class, NamedParameterJdbcTemplateConfiguration.class })
public class JdbcTemplateAutoConfiguration {
}
看完了源码,我们回到JdbcTemplate上,其实该模板类的底层封装了JDBC的操作,使用了Statement以及JDBCUtils来进行数据库的操作。查询使用queryForList(),其他直接就使用update()。
可以查阅文章:jdbcTemplate源码解析
前提介绍
Druid是阿里巴巴开源平台上一个数据库连接池的实现,结合了C3P0、DBCP、PROXOOL等DB池的优点,同时加入了日志监控。
Druid可以很好的监控DB池连接和SQL执行的情况,天生就是针对监控而生的DB连接池。
使用说明
pom.xml引入依赖:
<!--引入Druid的starter启动器-->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.1.10</version>
</dependency>
<!--引入log4j-->
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
yaml配置文件中修改type类型为Druid,以及添加一些额外配置:
spring:
datasource:
username: root
password: 123456
# 若是时区报错则添加参数:serverTimezone=Asia/Shanghai&
url: jdbc:mysql://localhost:3306/mybatis?useUnicode=true&characterEncoding=utf-8
# 使用com.mysql.jdbc.Driver测试datasource.getClass()表示过时,可使用com.mysql.cj.jdbc.Driver
driver-class-name: com.mysql.cj.jdbc.Driver
# 更改Druid类型即可
type: com.alibaba.druid.pool.DruidDataSource
#SpringBoot默认是不注入这些的,需要自己绑定
#druid数据源专有配置
initialSize: 5
minIdle: 5
maxActive: 20
maxWait: 60000
timeBetweenEvictionRunsMillis: 60000
minEvictableIdleTimeMillis: 300000
validationQuery: SELECT 1 FROM DUAL
testWhileIdle: true
testOnBorrow: false
testOnReturn: false
poolPreparedStatements: true
#配置监控统计拦截的filters,stat:监控统计、log4j:日志记录、wall:防御sql注入
#如果允许报错,java.lang.ClassNotFoundException: org.apache.Log4j.Properity
#则导入log4j 依赖就行
filters: stat,wall,log4j
maxPoolPreparedStatementPerConnectionSize: 20
useGlobalDataSourceStat: true
connectionProperties: druid.stat.mergeSql=true;druid.stat.slowSqlMillis=500
编写自定义配置类DruidConfig:
@Configuration
public class DruidConfig {
@ConfigurationProperties(prefix = "spring.datasource")
@Bean
public DataSource druidDataSource(){
return new DruidDataSource();
}
//后台监控 web.xml
//springboot内置了servlet,没有web.xml,所以使用ServletRegistrationBean
@Bean
public ServletRegistrationBean statViewServlet(){
ServletRegistrationBean<StatViewServlet> bean = new ServletRegistrationBean<>(new StatViewServlet(), "/druid/*");
//增加配置
Map<String, String> initParameters = new HashMap<>();
//固定为loginUsername以及loginPassword
initParameters.put("loginUsername","admin");
initParameters.put("loginPassword","123456");
//默认就是允许所有访问
initParameters.put("allow","");
//禁止谁能访问 initParameters.put("changlu","192.168.11.123");
//后台需要有人登陆,账号密码配置
bean.setInitParameters(initParameters);
return bean;
}
//filter
@Bean
public FilterRegistrationBean webStatFilter(){
FilterRegistrationBean<Filter> bean = new FilterRegistrationBean<>();
bean.setFilter(new WebStatFilter());
//过滤请求
HashMap<String,String> initParameters = new HashMap<>();
//指定内容不进行统计
initParameters.put("exclusions","*.js,*.css,/druid/*");
bean.setInitParameters(initParameters);
return bean;
}
}
测试:访问http://localhost:9999/druid/index.html即可
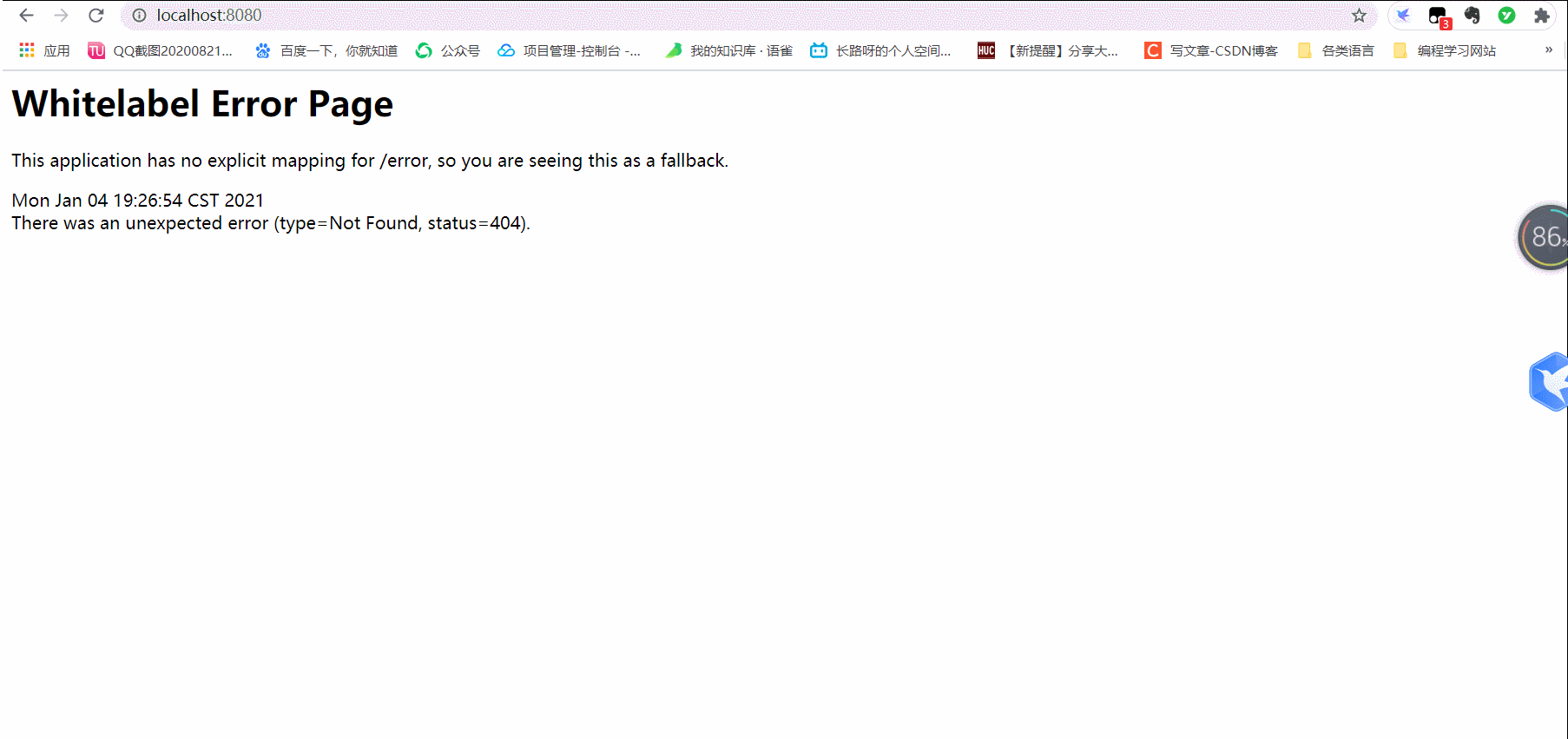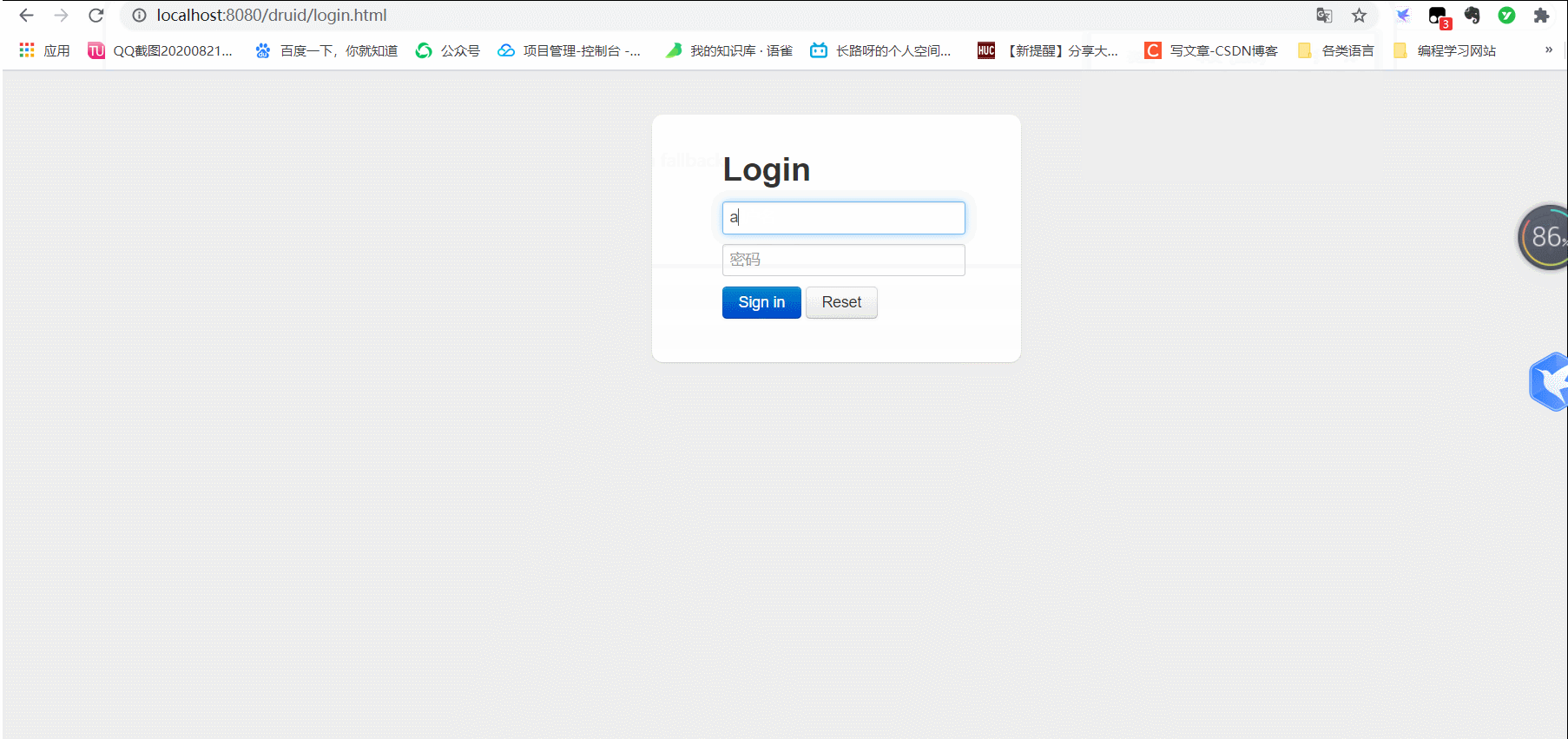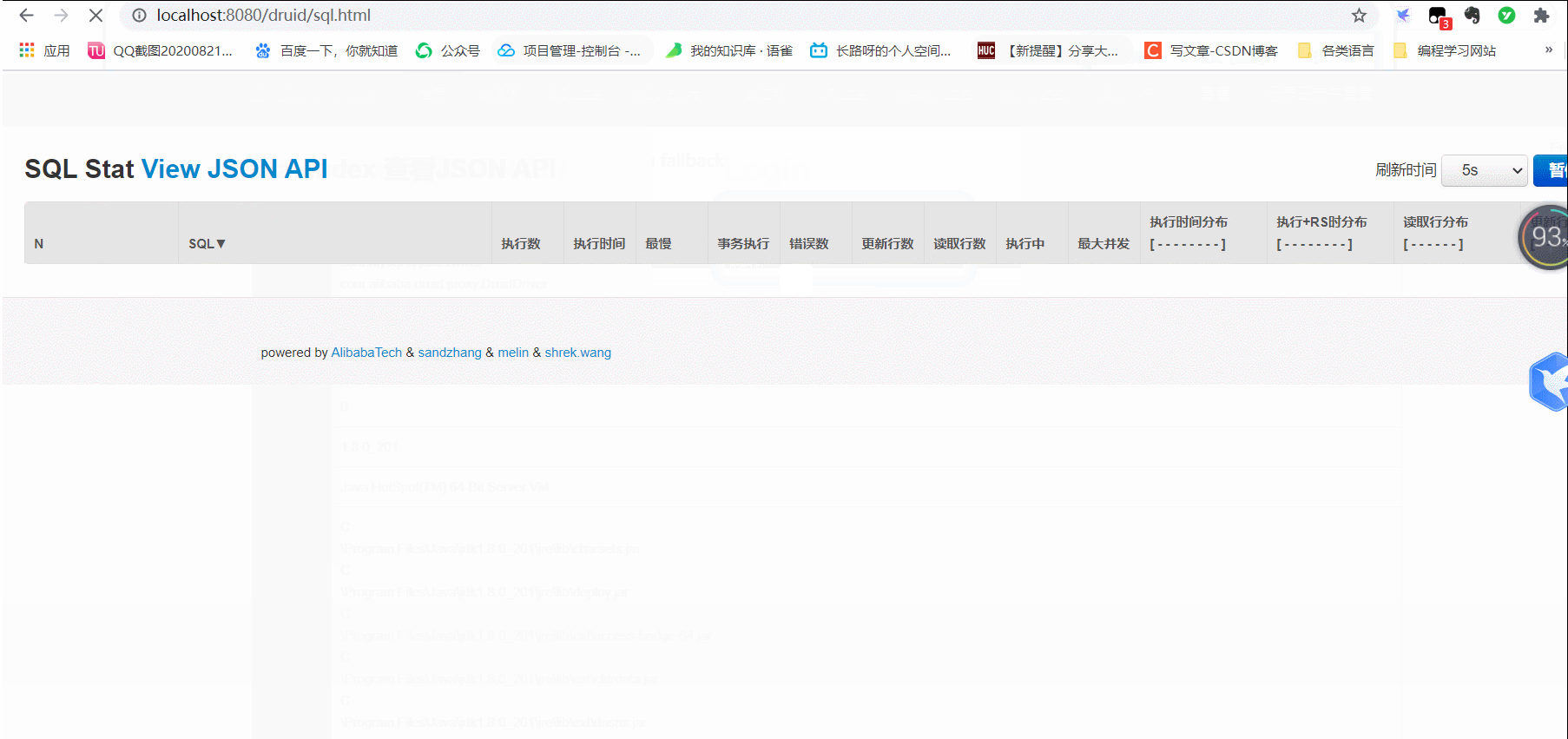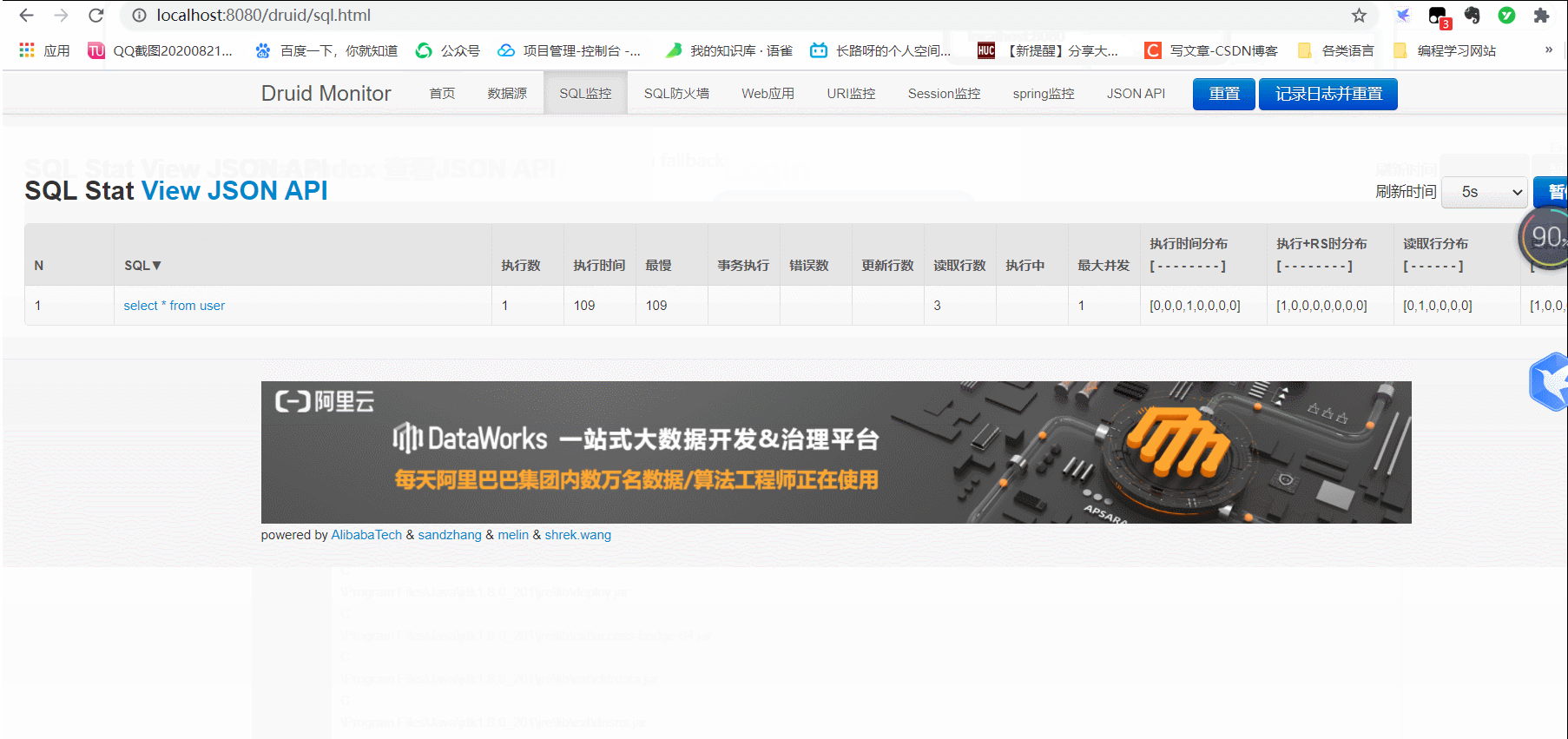
spingboot整合JPA,依赖于Hibernate,见资料区springboot-jpa
【1】引入jpa依赖以及mysql的驱动
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>
【2】配置数据源以及jpa
spring:
datasource:
username: root
password: 123456
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/mybatis?setTimezone=UTC&useUnicode=true&characterEncoding=utf-8
jpa:
hibernate:
ddl-auto: update # 连接数据库时会与其进行比对,自动更新数据库的表结构(生产环境确定了之后改为none)
show-sql: true # 控制台显示SQL
【3】编写实体类,需要对应数据库中的字段名称
@Data
@AllArgsConstructor
@NoArgsConstructor
@Entity //声明类为实体或表
public class User {
@Id //指定的类的属性,用于识别(一个表中的主键)
@GeneratedValue //提供了主键的生成策略
private Integer id;
private String name;
private String pwd;
private String perms;
}
【4】编写dao接口
//第一个参数是指定的实体类
//第二个参数是对应实体类的主键
@Repository
public interface UserDao extends JpaRepository<User,Integer> {
//方式二:解析方法名创建查询
User findByName(String name);
//方式三:自定义方法查询
@Query("from User u where u.name=:name")
User findUser(@Param("name")String name);
}
通过继承JpaRepository,并赋予两个泛型,即可使用其父类方法进行简单的CRUD,继承的方法如下:
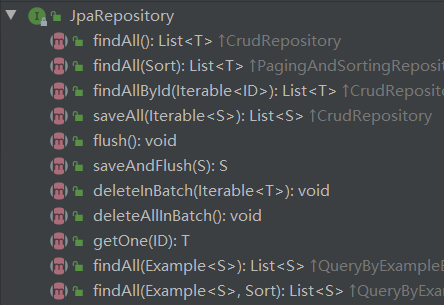
最后通过通过调用测试即可!!!
分页查询
//service层
@Override
public Page<Type> listType(Pageable pageable) {
return repository.findAll(pageable);
}
[2] JPA常用查询(实用)
[3] springboot操作数据库时找不到findOne(id:1)方法
findById(id).get():找不到会报异常findById(id).orElse(null)来返回,若是查找不到返回null,推荐使用[4] Spring Data JPA的自动更新,为什么会自动更新?如何避免自动更新?
[5] springdata jpa:@Query的nativeQuery属性的作用
我是长路,感谢你的耐心阅读。如有问题请指出,我会积极采纳!
欢迎关注我的公众号【长路Java】,分享Java学习文章及相关资料
Q群:851968786 我们可以一起探讨学习
注明:转载可,需要附带上文章链接
我试图获取一个长度在1到10之间的字符串,并输出将字符串分解为大小为1、2或3的连续子字符串的所有可能方式。例如:输入:123456将整数分割成单个字符,然后继续查找组合。该代码将返回以下所有数组。[1,2,3,4,5,6][12,3,4,5,6][1,23,4,5,6][1,2,34,5,6][1,2,3,45,6][1,2,3,4,56][12,34,5,6][12,3,45,6][12,3,4,56][1,23,45,6][1,2,34,56][1,23,4,56][12,34,56][123,4,5,6][1,234,5,6][1,2,345,6][1,2,3,456][123
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
我正在使用Sequel构建一个愿望list系统。我有一个wishlists和itemstable和一个items_wishlists连接表(该名称是续集选择的名称)。items_wishlists表还有一个用于facebookid的额外列(因此我可以存储opengraph操作),这是一个NOTNULL列。我还有Wishlist和Item具有续集many_to_many关联的模型已建立。Wishlist类也有:selectmany_to_many关联的选项设置为select:[:items.*,:items_wishlists__facebook_action_id].有没有一种方法可以
我使用的是Firefox版本36.0.1和Selenium-Webdrivergem版本2.45.0。我能够创建Firefox实例,但无法使用脚本继续进行进一步的操作无法在60秒内获得稳定的Firefox连接(127.0.0.1:7055)错误。有人能帮帮我吗? 最佳答案 我遇到了同样的问题。降级到firefoxv33后一切正常。您可以找到旧版本here 关于ruby-无法在60秒内获得稳定的Firefox连接(127.0.0.1:7055),我们在StackOverflow上找到一个类
有时我需要处理键/值数据。我不喜欢使用数组,因为它们在大小上没有限制(很容易不小心添加超过2个项目,而且您最终需要稍后验证大小)。此外,0和1的索引变成了魔数(MagicNumber),并且在传达含义方面做得很差(“当我说0时,我的意思是head...”)。散列也不合适,因为可能会不小心添加额外的条目。我写了下面的类来解决这个问题:classPairattr_accessor:head,:taildefinitialize(h,t)@head,@tail=h,tendend它工作得很好并且解决了问题,但我很想知道:Ruby标准库是否已经带有这样一个类? 最佳
question的一些答案关于redirect_to让我想到了其他一些问题。基本上,我正在使用Rails2.1编写博客应用程序。我一直在尝试自己完成大部分工作(因为我对Rails有所了解),但在需要时会引用Internet上的教程和引用资料。我设法让一个简单的博客正常运行,然后我尝试添加评论。靠我自己,我设法让它进入了可以从script/console添加评论的阶段,但我无法让表单正常工作。我遵循的其中一个教程建议在帖子Controller中创建一个“评论”操作,以添加评论。我的问题是:这是“标准”方式吗?我的另一个问题的答案之一似乎暗示应该有一个CommentsController参
是否可以为特定(或所有)项目使用多个布局?例如,我有几个项目,我想对其应用两种不同的布局。一个是绿色的,一个是蓝色的(但是)。我想将它们编译到我的输出目录中的两个不同文件夹中(例如v1和v2)。我一直在玩弄规则和编译block,但我不知道这是怎么回事。因为,每个项目在编译过程中只编译一次,我不能告诉nanoc第一次用layout1编译,第二次用layout2编译。我试过这样的东西,但它导致输出文件损坏。compile'*'doifitem.binary?#don’tfilterbinaryitemselsefilter:erblayout'layout1'layout'layout2'
我正在尝试使用Curbgem执行以下POST以解析云curl-XPOST\-H"X-Parse-Application-Id:PARSE_APP_ID"\-H"X-Parse-REST-API-Key:PARSE_API_KEY"\-H"Content-Type:image/jpeg"\--data-binary'@myPicture.jpg'\https://api.parse.com/1/files/pic.jpg用这个:curl=Curl::Easy.new("https://api.parse.com/1/files/lion.jpg")curl.multipart_form_
无论您是想搭建桌面端、WEB端或者移动端APP应用,HOOPSPlatform组件都可以为您提供弹性的3D集成架构,同时,由工业领域3D技术专家组成的HOOPS技术团队也能为您提供技术支持服务。如果您的客户期望有一种在多个平台(桌面/WEB/APP,而且某些客户端是“瘦”客户端)快速、方便地将数据接入到3D应用系统的解决方案,并且当访问数据时,在各个平台上的性能和用户体验保持一致,HOOPSPlatform将帮助您完成。利用HOOPSPlatform,您可以开发在任何环境下的3D基础应用架构。HOOPSPlatform可以帮您打造3D创新型产品,HOOPSSDK包含的技术有:快速且准确的CAD
在应用开发中,有时候我们需要获取系统的设备信息,用于数据上报和行为分析。那在鸿蒙系统中,我们应该怎么去获取设备的系统信息呢,比如说获取手机的系统版本号、手机的制造商、手机型号等数据。1、获取方式这里分为两种情况,一种是设备信息的获取,一种是系统信息的获取。1.1、获取设备信息获取设备信息,鸿蒙的SDK包为我们提供了DeviceInfo类,通过该类的一些静态方法,可以获取设备信息,DeviceInfo类的包路径为:ohos.system.DeviceInfo.具体的方法如下:ModifierandTypeMethodDescriptionstatic StringgetAbiList()Obt