
在读多写少的互联网业务场景,往往“读”性能会成为第一个瓶颈。随着业务的发展,数据库负载越来越高,逐渐成为系统的瓶颈。面对“读”性能瓶颈,大致有以下几种解题思路:
以数据库部署架构为基础,对数据操作进行分离,主节点主要处理写请求,从节点主要处理读请求。通过引入多个副本来分散读请求,从而实现 读请求 的水平扩展。主副本 与 从副本 间的数据一致就是通过 “复制” 来完成。读写分离架构有几个非常重要的概念:
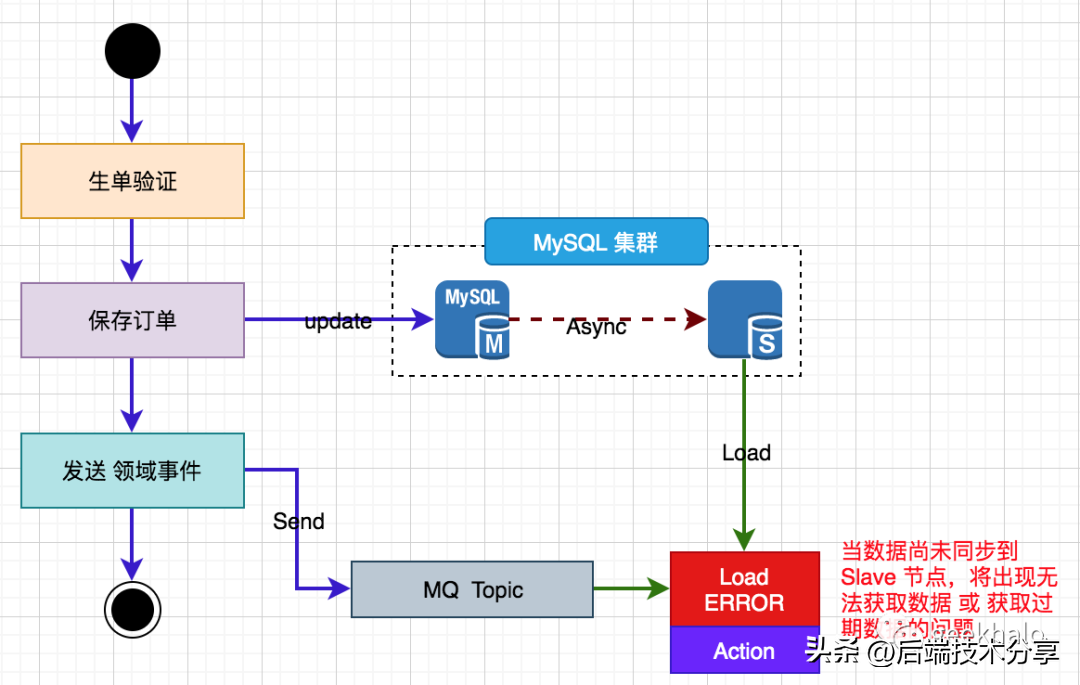
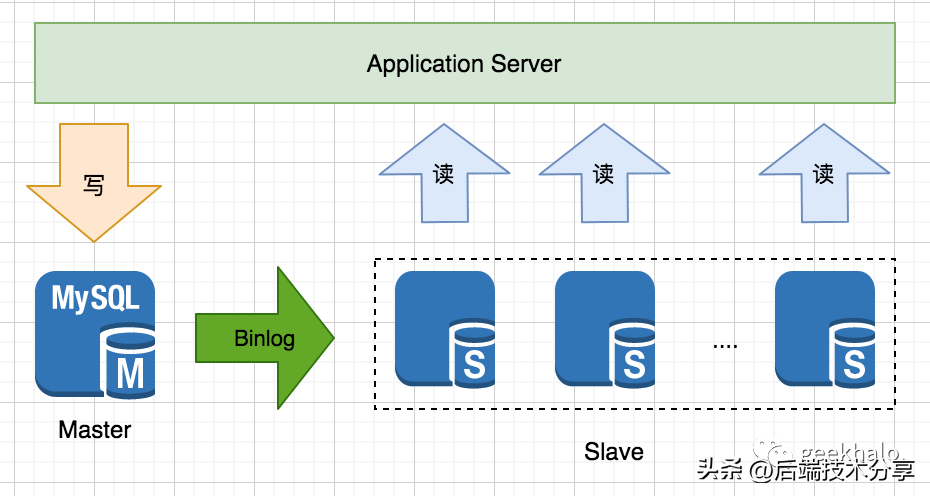 通过扩展 Slave 可以实现 读请求 的水平扩展,核心流程如下:
通过扩展 Slave 可以实现 读请求 的水平扩展,核心流程如下:备注:Slave 过多会加重 Master 的压力,可通过多级复制或分区进行解决。读写分离架构可以方便的对读请求进行扩展,看似美好,但需要解决两个问题:
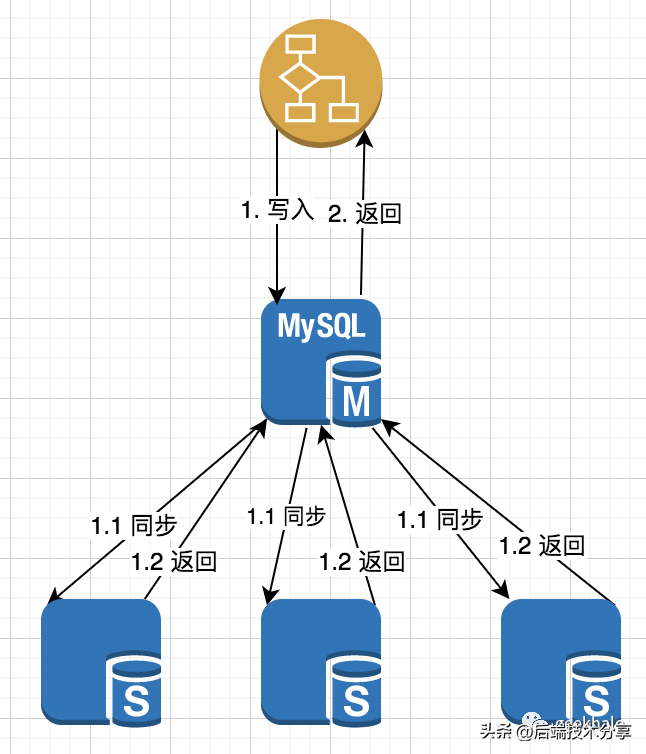 核心流程:
核心流程: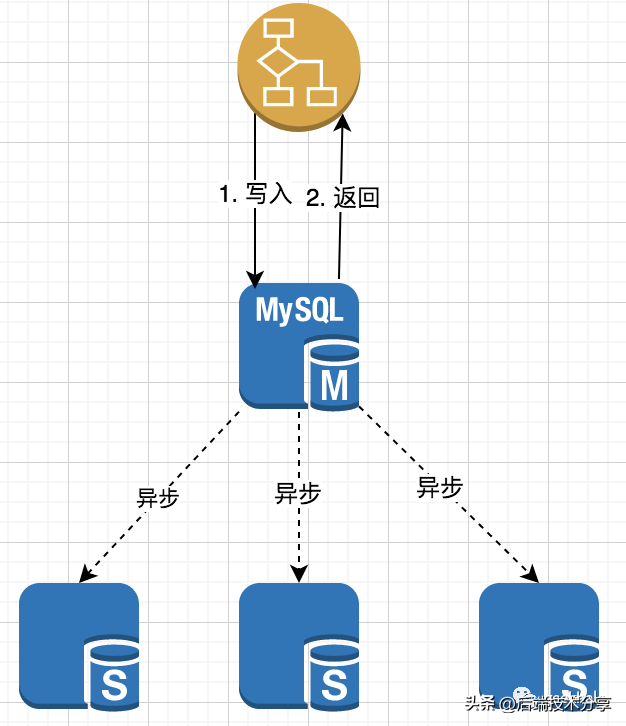 核心流程:
核心流程: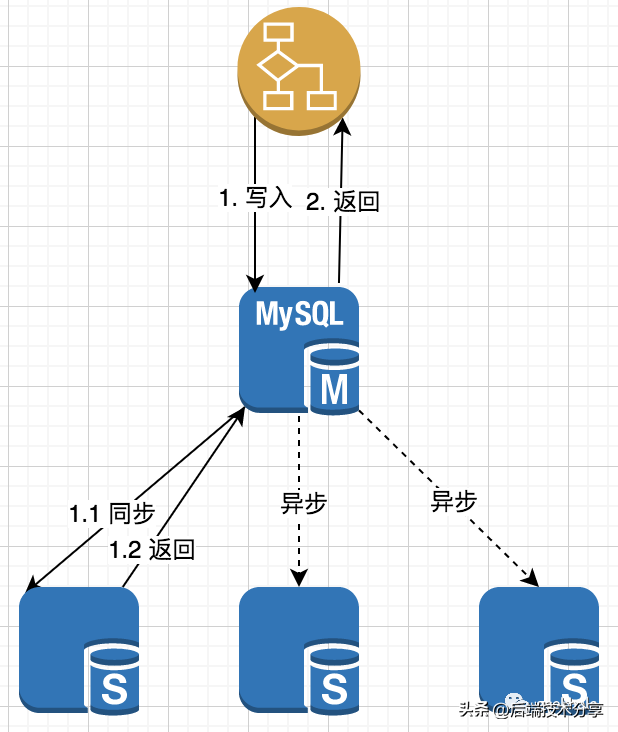 核心流程
核心流程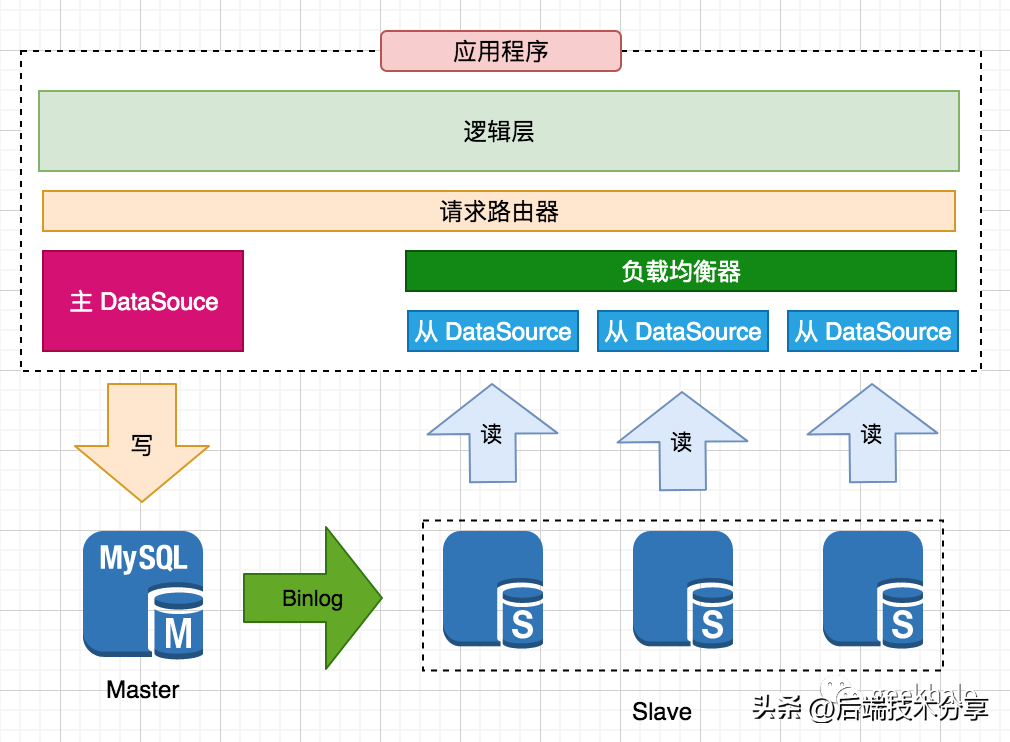 核心流程:
核心流程: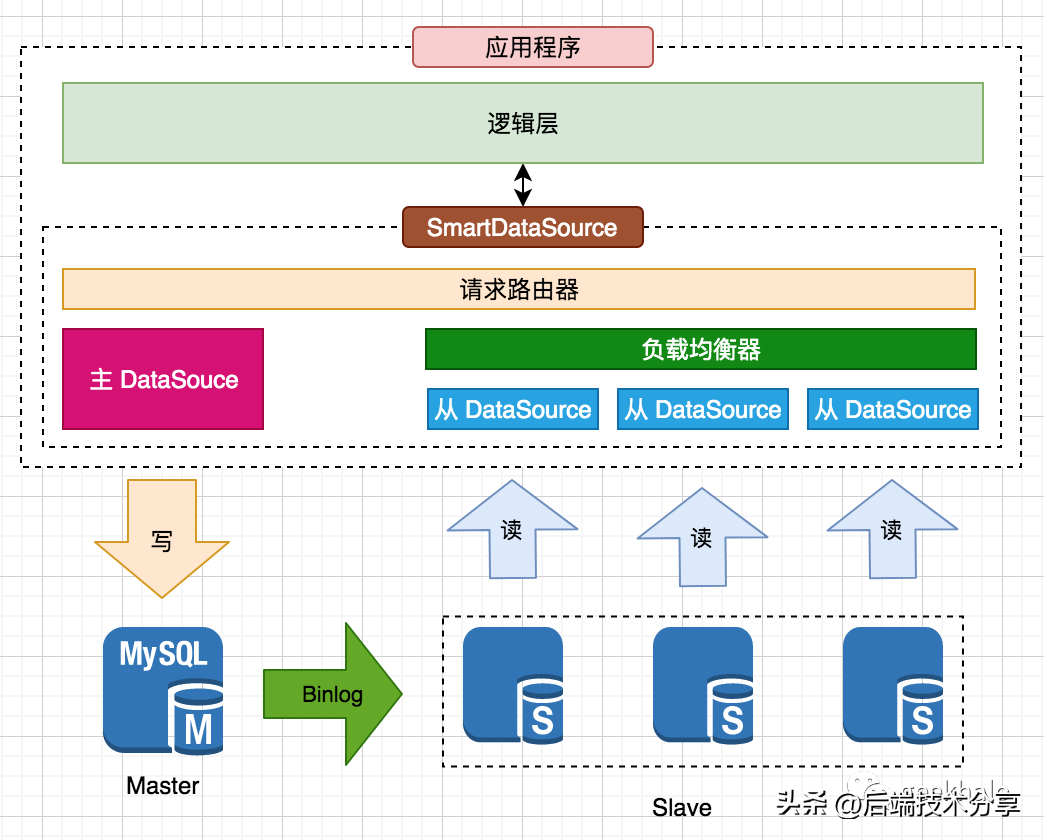 核心设计如下:
核心设计如下: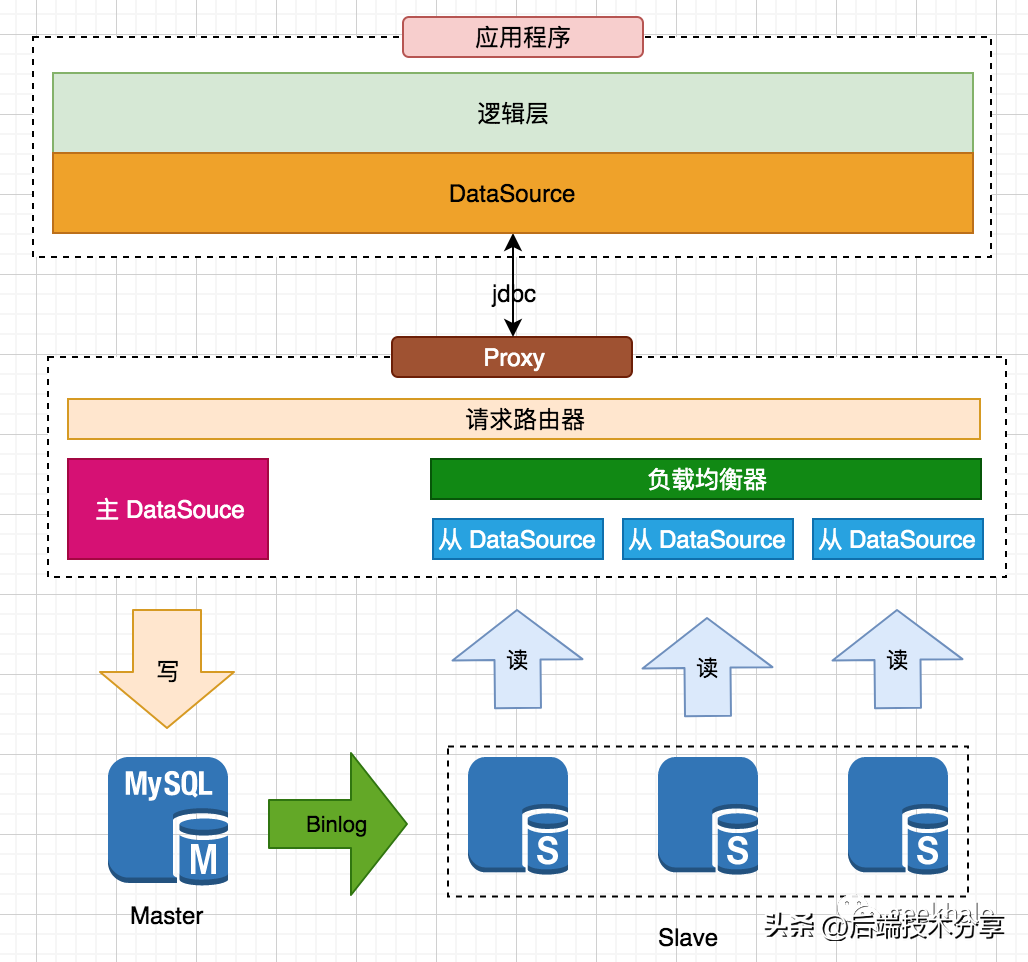 核心设计:
核心设计:通常情况下,会在配置中心的基础上,综合使用智能路由和Proxy路由两种模式:智能路由。用于应用程序,追求极致的性能;Proxy路由。用于数据库管理,追求管理的便利性;配置中心。为智能路由和Proxy路由提供统一的配置信息。
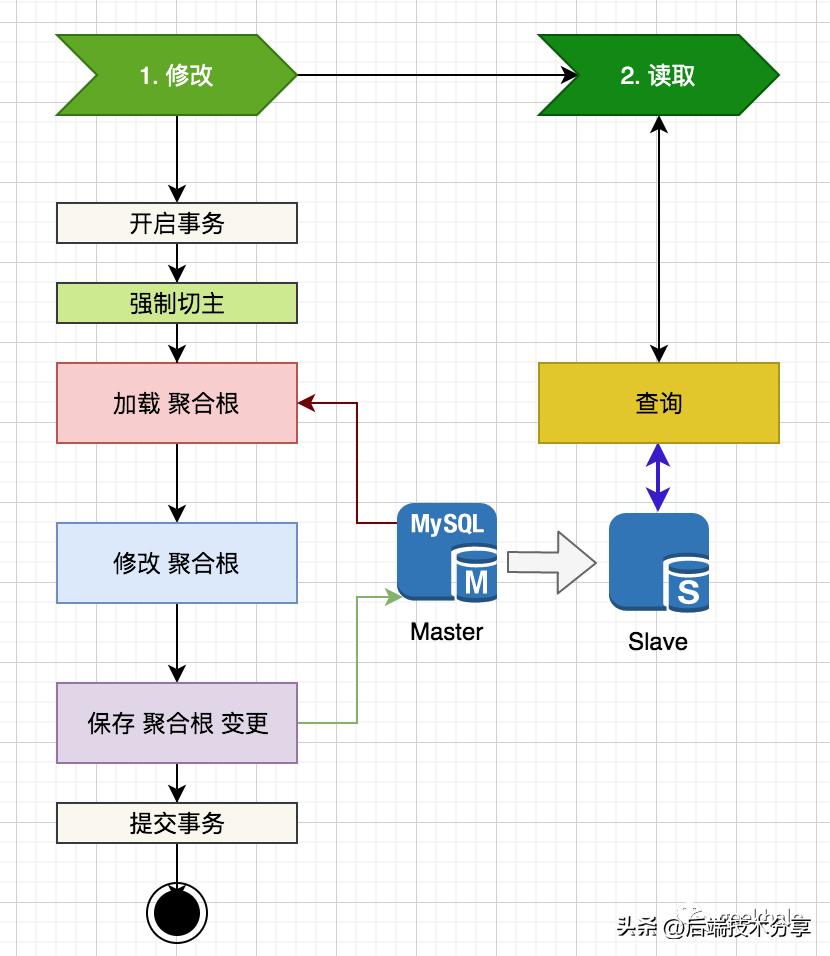
对于更新场景,为了避免 主从延时导致的 写覆盖问题,通常使用强制切主策略。写覆盖的根源,见下图:
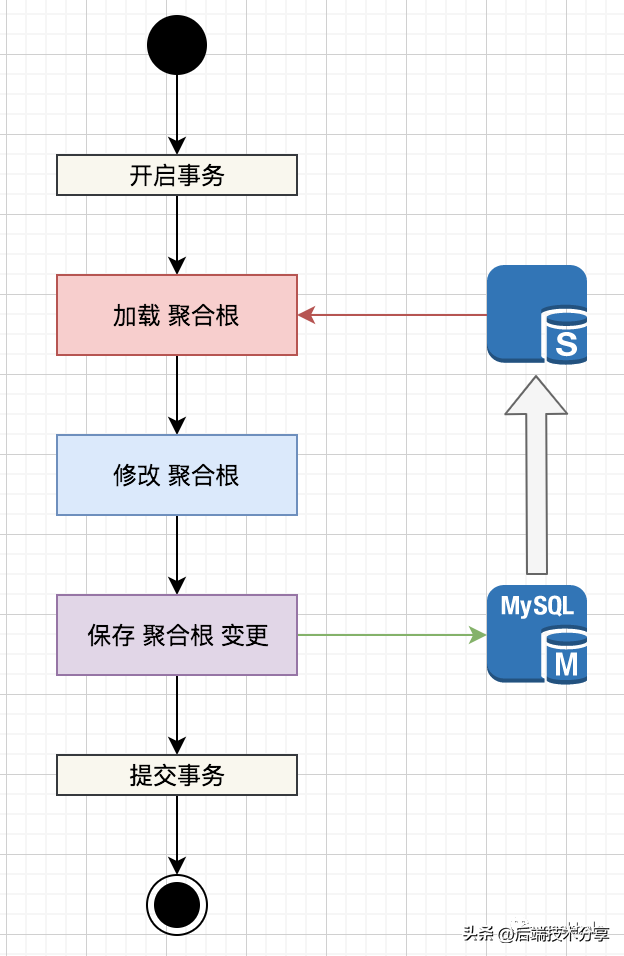 由于存在主从延时,所加载的 聚合根 不一定是最新的数据,因此,后续的修改 和 保存,都是在过期数据上执行,导致写丢失。
由于存在主从延时,所加载的 聚合根 不一定是最新的数据,因此,后续的修改 和 保存,都是在过期数据上执行,导致写丢失。备注:乐观锁保护下,不会出现写丢失情况;面对这种场景,最简单的策略便是:强制切主。具体流程如下:
 直接从 Mater 进行加载,避免 Slave 查询到过期数据。
直接从 Mater 进行加载,避免 Slave 查询到过期数据。SmartDataSource 和 Proxy 都提供了强制切主的设置方式,在此不做过多介绍。
 核心流程如下:
核心流程如下: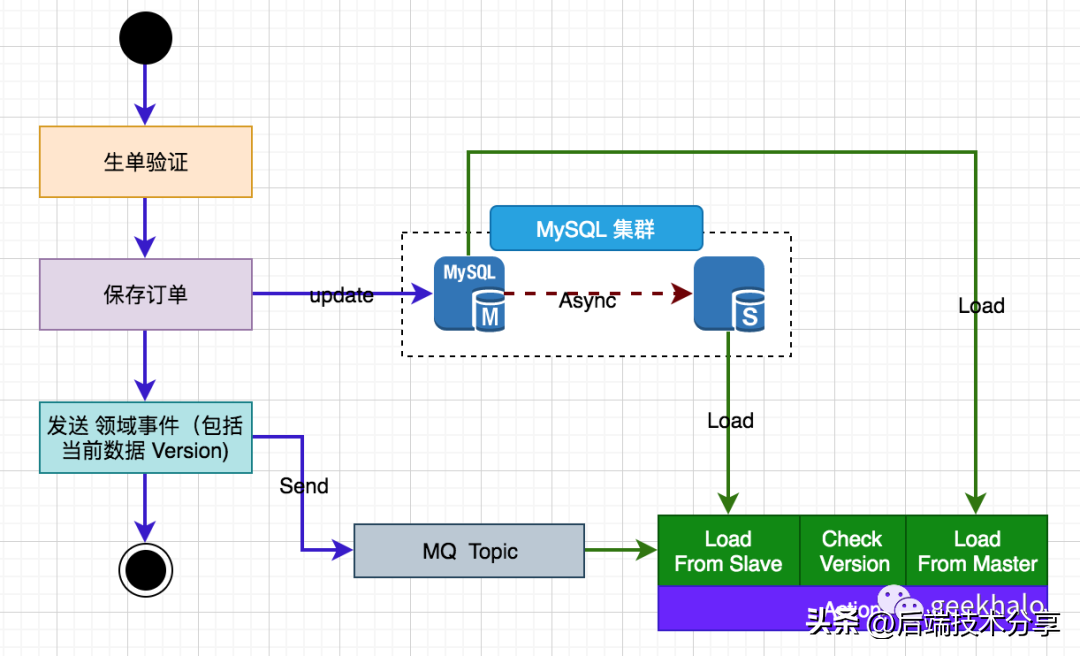 核心流程如下:
核心流程如下:时间戳是一种特殊的version,可以使用数据表的 update_time 作为 version。
 核心流程:
核心流程: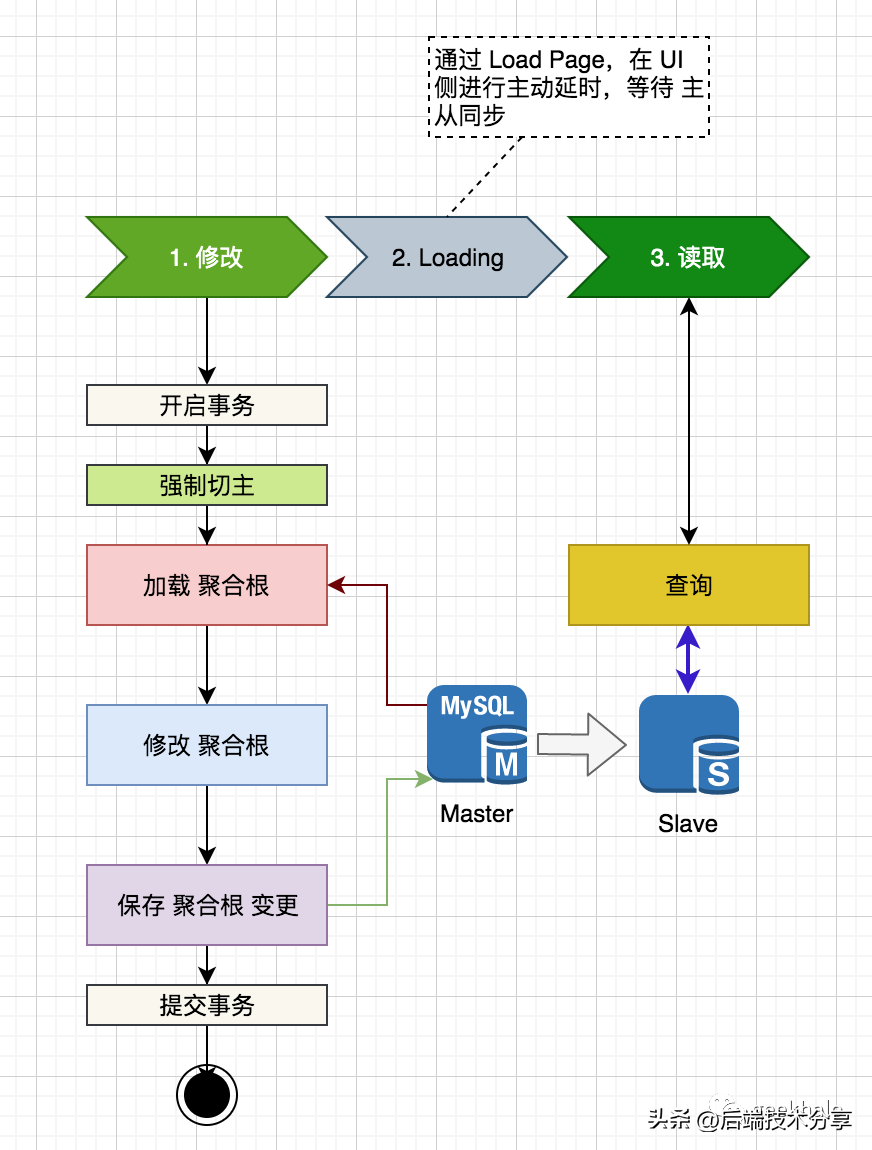 整体流程如下:
整体流程如下: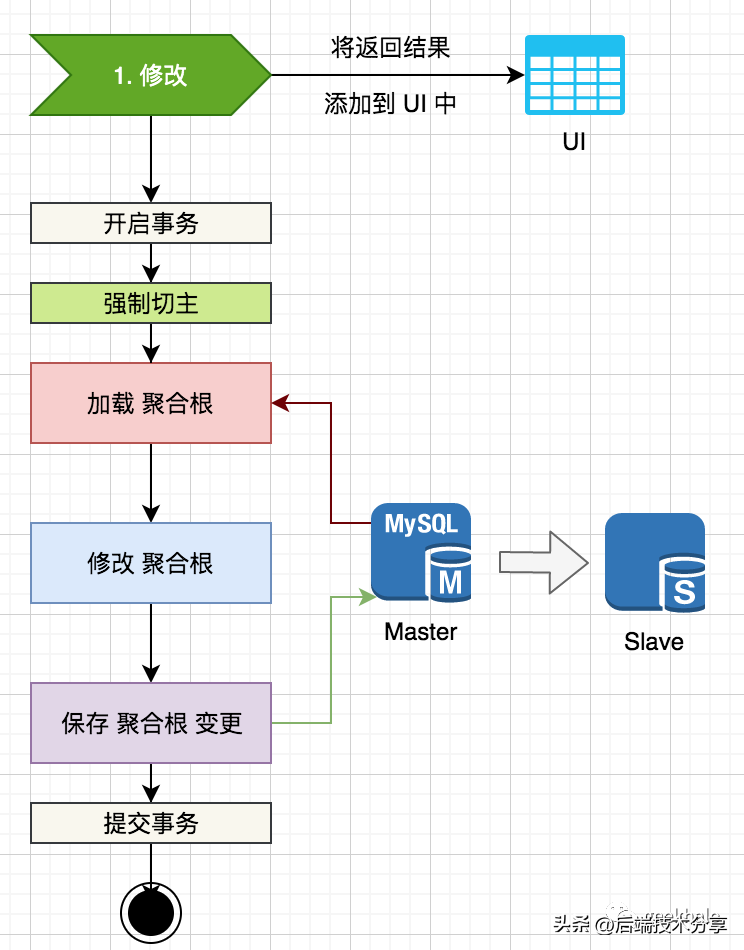 核心点包括:
核心点包括: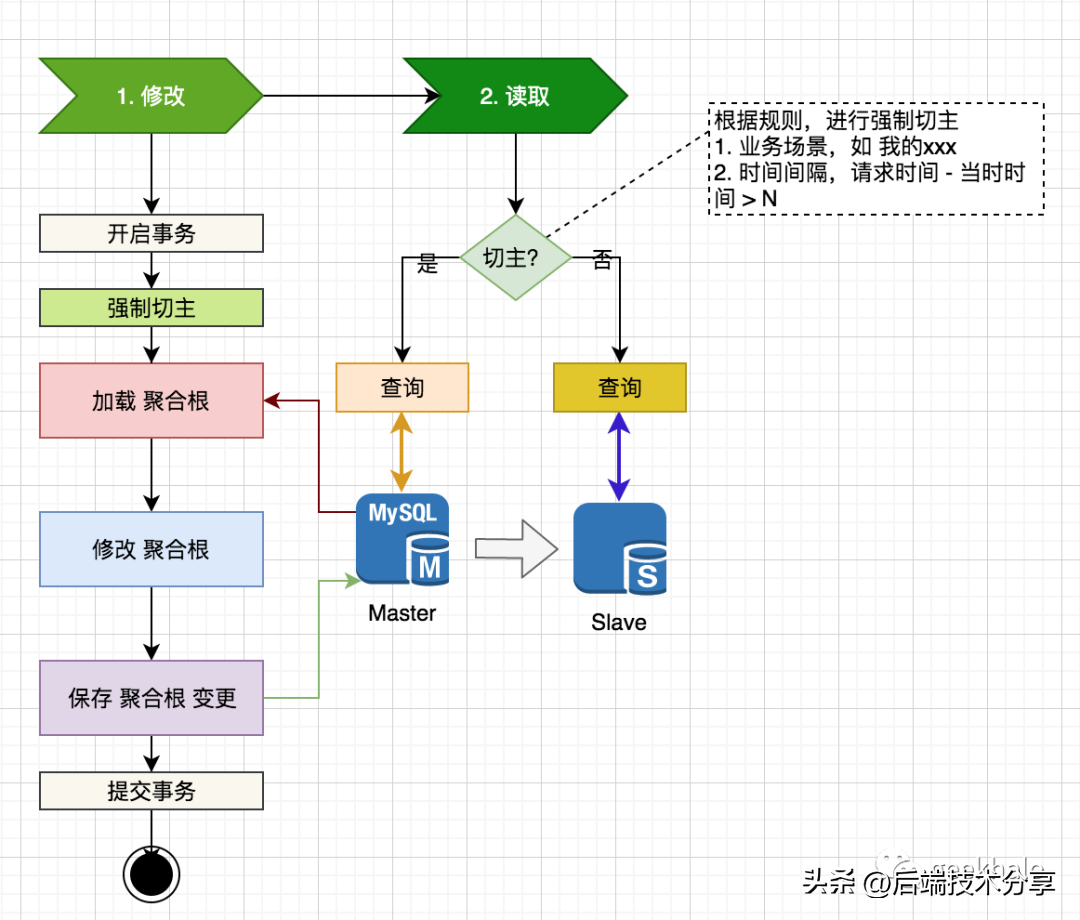 根据规则,决定是否强制切主,如下:
根据规则,决定是否强制切主,如下:我有一个模型:classItem项目有一个属性“商店”基于存储的值,我希望Item对象对特定方法具有不同的行为。Rails中是否有针对此的通用设计模式?如果方法中没有大的if-else语句,这是如何干净利落地完成的? 最佳答案 通常通过Single-TableInheritance. 关于ruby-on-rails-Rails-子类化模型的设计模式是什么?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.co
我已经从我的命令行中获得了一切,所以我可以运行rubymyfile并且它可以正常工作。但是当我尝试从sublime中运行它时,我得到了undefinedmethod`require_relative'formain:Object有人知道我的sublime设置中缺少什么吗?我正在使用OSX并安装了rvm。 最佳答案 或者,您可以只使用“require”,它应该可以正常工作。我认为“require_relative”仅适用于ruby1.9+ 关于ruby-主要:Objectwhenrun
我将应用程序升级到Rails4,一切正常。我可以登录并转到我的编辑页面。也更新了观点。使用标准View时,用户会更新。但是当我添加例如字段:name时,它不会在表单中更新。使用devise3.1.1和gem'protected_attributes'我需要在设备或数据库上运行某种更新命令吗?我也搜索过这个地方,找到了许多不同的解决方案,但没有一个会更新我的用户字段。我没有添加任何自定义字段。 最佳答案 如果您想允许额外的参数,您可以在ApplicationController中使用beforefilter,因为Rails4将参数
目录前言滤波电路科普主要分类实际情况单位的概念常用评价参数函数型滤波器简单分析滤波电路构成低通滤波器RC低通滤波器RL低通滤波器高通滤波器RC高通滤波器RL高通滤波器部分摘自《LC滤波器设计与制作》,侵权删。前言最近需要学习放大电路和滤波电路,但是由于只在之前做音乐频谱分析仪的时候简单了解过一点点运放,所以也是相当从零开始学习了。滤波电路科普主要分类滤波器:主要是从不同频率的成分中提取出特定频率的信号。有源滤波器:由RC元件与运算放大器组成的滤波器。可滤除某一次或多次谐波,最普通易于采用的无源滤波器结构是将电感与电容串联,可对主要次谐波(3、5、7)构成低阻抗旁路。无源滤波器:无源滤波器,又称
项目介绍随着我国经济迅速发展,人们对手机的需求越来越大,各种手机软件也都在被广泛应用,但是对于手机进行数据信息管理,对于手机的各种软件也是备受用户的喜爱小学生兴趣延时班预约小程序的设计与开发被用户普遍使用,为方便用户能够可以随时进行小学生兴趣延时班预约小程序的设计与开发的数据信息管理,特开发了小程序的设计与开发的管理系统。小学生兴趣延时班预约小程序的设计与开发的开发利用现有的成熟技术参考,以源代码为模板,分析功能调整与小学生兴趣延时班预约小程序的设计与开发的实际需求相结合,讨论了小学生兴趣延时班预约小程序的设计与开发的使用。开发环境开发说明:前端使用微信微信小程序开发工具:后端使用ssm:VU
我在我的项目中有一个用户和一个管理员角色。我使用Devise创建了身份验证。在我的管理员角色中,我没有任何确认。在我的用户模型中,我有以下内容:devise:database_authenticatable,:confirmable,:recoverable,:rememberable,:trackable,:validatable,:timeoutable,:registerable#Setupaccessible(orprotected)attributesforyourmodelattr_accessible:email,:username,:prename,:surname,:
我是一名决定学习Ruby和RubyonRails的ASP.NETMVC开发人员。我已经有所了解并在RoR上创建了一个网站。在ASP.NETMVC上开发,我一直使用三层架构:数据层、业务层和UI(或表示)层。尝试在RubyonRails应用程序中使用这种方法,我发现没有关于它的信息(或者也许我只是找不到它?)。也许有人可以建议我如何在RubyonRails上创建或使用三层架构?附言我使用ruby1.9.3和RubyonRails3.2.3。 最佳答案 我建议在制作RoR应用程序时遵循RubyonRails(RoR)风格。Rails
我正在尝试创建密码规则来设计可恢复的密码更改。我通过passwords_controller.rb做了一个父类(superclass),但我需要在应用规则之前检查用户角色,但我所拥有的只是reset_password_token。 最佳答案 假设您的模型是用户:User.with_reset_password_token(your_token_here)Source 关于ruby-on-rails-设计通过reset_password_token获取用户,我们在StackOverflow
我已经使用Apartment设置了一个Rails5应用程序(1.2.0)和Devise(4.2.0)。由于某些DDNS问题,应用只能在app.myapp.com下访问(请注意子域app)。myapp.com重定向到app.myapp.com。我的用例是每个注册该应用的用户(租户)都应该通过他们的子域(例如tenant.myapp.com)访问他们的特定数据。用户不应限定在其子域内。基本上应该可以从任何子域登录。重定向到租户的正确子域由ApplicationController处理。根据Devise标准,登录页面位于app.myapp.com/users/sign_in。这就是问题开始的
我在关注RyanbatesRailsCast的devise和omniauth(第235集-devise-and-omniauth-revised)。当我尝试使用Twitter登录时,标题中不断出现错误。defself.new_with_session(params,session)ifsession["devise.user_attributes"]new(session["devise.user_attributes"],without_protection:true)do|user|user.attributes=paramsuser.valid?end完整跟踪:C:/Ruby20