文章目录
有个项目需要输出10-50Hz的低频信号驱动线圈,考虑使用音频功放硬件,所以做这方面的预研。
参考文章:
ffmpeg作为开源软件,应用非常广泛,这里我们借用它来把mp3转化成PCM文件。PCM文件没有文件头,帧头等信息,直接就是二进制的音频数据。播放时需要的 采样率,位深,大小端存储,通道 等信息,PCM文件也没有包含,使用ffmpeg播放时需要指定这些信息(由于PCM文件是自己生成的,所以我们知道这些信息的)。
首先选一个mp3文件,我选的源文件是一首5分钟长的歌曲,我先用格式工厂把它分割成3部分,取其中一部分,不需要太大的数据,分割后的文件大小为1.46MB,时长01:36,如下图:
把Part2.mp3放到ffmpeg目录下,打开windows shell,进入ffmpeg目录。
>ffprobe -i Part2.mp3
Duration: 00:01:36.31, start: 0.025057, bitrate: 128 kb/s
Stream #0:0: Audio: mp3, 44100 Hz, stereo, fltp, 128 kb/s
Metadata:
encoder : Lavc59.12
为了方便查看数据,我选择单通道输出
>ffmpeg -i Part2.mp3 -ar 22050 -ac 1 -f s16le Part2.pcm
Stream mapping:
Stream #0:0 -> #0:0 (mp3 (mp3float) -> pcm_s16le (native))
Press [q] to stop, [?] for help
Output #0, s16le, to 'Part2.pcm':
Metadata:
title : è·ç¦» (我ä¸é
)
album : 我很忙
genre : Pop
artist : 周æ°ä¼¦
album_artist : 周æ°ä¼¦
composer : 周æ°ä¼¦
comment : ExactAudioCopy v0.99pb3
DISCID : ISCID
encoder : Lavf59.27.100
Stream #0:0: Audio: pcm_s16le, 22050 Hz, mono, s16, 352 kb/s
Metadata:
encoder : Lavc59.37.100 pcm_s16le
size= 4146kB time=00:01:36.28 bitrate= 352.8kbits/s speed= 606x
video:0kB audio:4146kB subtitle:0kB other streams:0kB global headers:0kB muxing overhead: 0.000000%
命令简单解释:
# 输入文件
-i
# 格式
-f fmt force format
#这里的参数 s16le 表示 数据格式为有符号16bit 整型,小端存储格式
#设置音频采样率
-ar rate set audio sampling rate (in Hz)
#设置音频通道数
-ac channels set number of audio channels
#最后的参数为输出文件名
ffplay -ar 22050 -ac 1 -f s16le -i Part2.pcm
可以在电脑中播放出正常的音乐,说明这个PCM文件是有效的。
使用下面的代码:
import matplotlib.pyplot as plt #画图包
import numpy as np
cnt=500
# 1.设定文件的格式为小端,16bit有符号整型,小端存储
dt = np.dtype('<h')
# 2.读取二进制文件,作为y轴数据
y=np.fromfile('Part2.pcm', dtype=dt, count=cnt, sep='', offset=20000)
# 3.生成x轴数据
x=np.linspace(1, cnt,cnt, dtype=int)
print(x)
print(y)
# 4.绘制成图表
plt.plot(x,y,'bp--') #
# 5.显示图表
plt.show()
改变offset和cnt可以查看自己想看的某段数据图表。
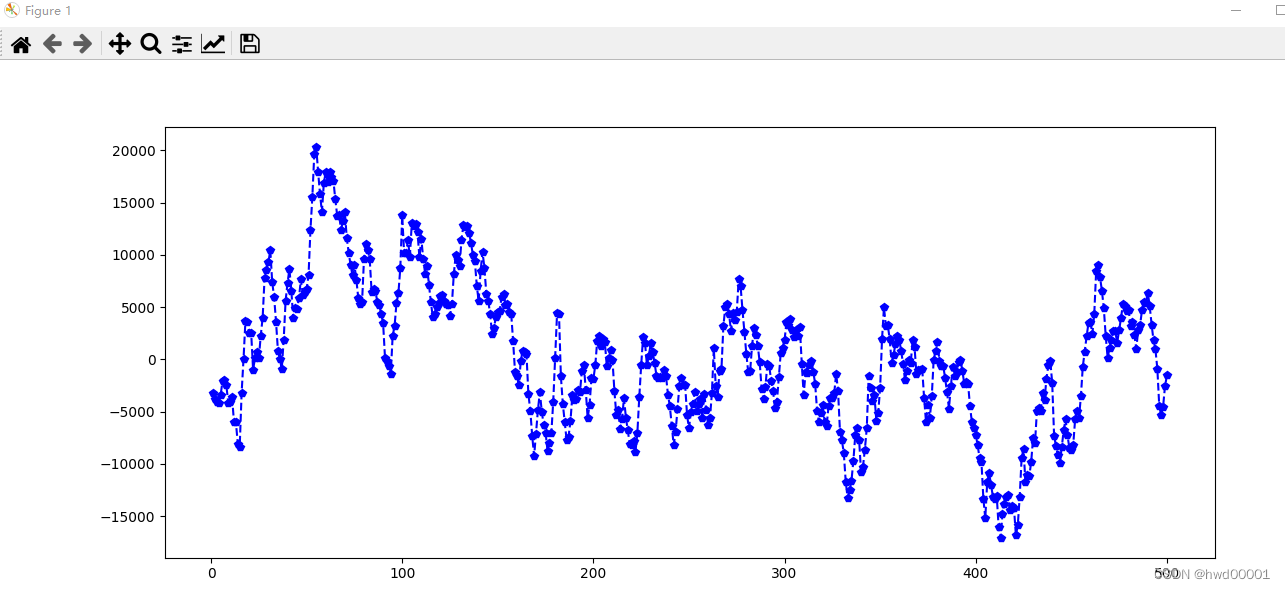
y=np.fromfile(‘Part2.pcm’, dtype=dt, count=cnt, sep=‘’, offset=20000) dt的含义详见下一节。表示以16位bit的带符号整型数据类型和小端存储格式读取文件名为“Part2.pcm”的二进制文件,从偏移量为20000个字节的位置开始读取500(cnt=500)个数据。
参数说明:
| 参数 | 类型 | 说明 |
|---|---|---|
| file | file 或 str 或 Path | 打开文件对象或文件名。 |
| dtype | data-type | 可选.返回数组的数据类型。对于二进制文件,它用于确定文件中各项的大小和字节顺序。支持大多数内置数字类型,并且可能支持扩展名类型。 |
| count | int | 要读取的项目数。-1表示所有项目(即完整文件)。 |
| sep | str | 如果文件是文本文件,则项目之间的分隔符。空(“”)分隔符表示文件应被视为二进制文件。分隔符中的空格(“”)匹配零个或多个空格字符。仅由空格组成的分隔符必须至少匹配一个空格。 |
| offset | int | 与文件当前位置的偏移量(以字节为单位)。默认值为0。仅允许用于二进制文件。 |
dt = np.dtype(‘<h’) 表示小端存储,16bit带符号整型。
| 类型 | 字符代码 |
|---|---|
| bool | ?, b1 |
| int8 | b, i1 |
| uint8 | B, u1 |
| int16 | h, i2 |
| uint16 | H, u2 |
| int32 | i, i4 |
| uint32 | I, u4 |
| int64 | q, i8 |
| uint64 | Q, u8 |
| float16 | f2, e |
| float32 | f4, f |
| float64 | f8, d |
| complex64 | F4, F |
| complex128 | F8, D |
| str | a, S(可以在S后面添加数字,表示字符串长度,比如S3表示长度为三的字符串,不写则为最大长度) |
| unicode | U |
| 大端存储 | > |
| 小端 | < |
https://gitee.com/huangweide001/py-hwd/tree/master/read_pcm_plt
我有一个Ruby程序,它使用rubyzip压缩XML文件的目录树。gem。我的问题是文件开始变得很重,我想提高压缩级别,因为压缩时间不是问题。我在rubyzipdocumentation中找不到一种为创建的ZIP文件指定压缩级别的方法。有人知道如何更改此设置吗?是否有另一个允许指定压缩级别的Ruby库? 最佳答案 这是我通过查看rubyzip内部创建的代码。level=Zlib::BEST_COMPRESSIONZip::ZipOutputStream.open(zip_file)do|zip|Dir.glob("**/*")d
我试图在一个项目中使用rake,如果我把所有东西都放到Rakefile中,它会很大并且很难读取/找到东西,所以我试着将每个命名空间放在lib/rake中它自己的文件中,我添加了这个到我的rake文件的顶部:Dir['#{File.dirname(__FILE__)}/lib/rake/*.rake'].map{|f|requiref}它加载文件没问题,但没有任务。我现在只有一个.rake文件作为测试,名为“servers.rake”,它看起来像这样:namespace:serverdotask:testdoputs"test"endend所以当我运行rakeserver:testid时
我的目标是转换表单输入,例如“100兆字节”或“1GB”,并将其转换为我可以存储在数据库中的文件大小(以千字节为单位)。目前,我有这个:defquota_convert@regex=/([0-9]+)(.*)s/@sizes=%w{kilobytemegabytegigabyte}m=self.quota.match(@regex)if@sizes.include?m[2]eval("self.quota=#{m[1]}.#{m[2]}")endend这有效,但前提是输入是倍数(“gigabytes”,而不是“gigabyte”)并且由于使用了eval看起来疯狂不安全。所以,功能正常,
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
Rails2.3可以选择随时使用RouteSet#add_configuration_file添加更多路由。是否可以在Rails3项目中做同样的事情? 最佳答案 在config/application.rb中:config.paths.config.routes在Rails3.2(也可能是Rails3.1)中,使用:config.paths["config/routes"] 关于ruby-on-rails-Rails3中的多个路由文件,我们在StackOverflow上找到一个类似的问题
对于具有离线功能的智能手机应用程序,我正在为Xml文件创建单向文本同步。我希望我的服务器将增量/差异(例如GNU差异补丁)发送到目标设备。这是计划:Time=0Server:hasversion_1ofXmlfile(~800kiB)Client:hasversion_1ofXmlfile(~800kiB)Time=1Server:hasversion_1andversion_2ofXmlfile(each~800kiB)computesdeltaoftheseversions(=patch)(~10kiB)sendspatchtoClient(~10kiBtransferred)Cl
我得到了一个包含嵌套链接的表单。编辑时链接字段为空的问题。这是我的表格:Editingkategori{:action=>'update',:id=>@konkurrancer.id})do|f|%>'Trackingurl',:style=>'width:500;'%>'Editkonkurrence'%>|我的konkurrencer模型:has_one:link我的链接模型:classLink我的konkurrancer编辑操作:defedit@konkurrancer=Konkurrancer.find(params[:id])@konkurrancer.link_attrib
我正在寻找执行以下操作的正确语法(在Perl、Shell或Ruby中):#variabletoaccessthedatalinesappendedasafileEND_OF_SCRIPT_MARKERrawdatastartshereanditcontinues. 最佳答案 Perl用__DATA__做这个:#!/usr/bin/perlusestrict;usewarnings;while(){print;}__DATA__Texttoprintgoeshere 关于ruby-如何将脚
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
使用带有Rails插件的vim,您可以创建一个迁移文件,然后一次性打开该文件吗?textmate也可以这样吗? 最佳答案 你可以使用rails.vim然后做类似的事情::Rgeneratemigratonadd_foo_to_bar插件将打开迁移生成的文件,这正是您想要的。我不能代表textmate。 关于ruby-使用VimRails,您可以创建一个新的迁移文件并一次性打开它吗?,我们在StackOverflow上找到一个类似的问题: https://sta