本文介绍基于Python中ArcPy模块,对大量栅格遥感影像文件进行批量掩膜与批量重采样的操作。
首先,我们来明确一下本文的具体需求。现有一个存储有大量.tif格式遥感影像的文件夹;且其中除了.tif格式的遥感影像文件外,还具有其它格式的文件。
我们希望,依据一个已知的面要素矢量图层文件,对上述文件夹中的全部.tif格式遥感影像进行掩膜,并对掩膜后的遥感影像文件再分别加以批量重采样,使得其空间分辨率为1000 m。
明确了需求后,我们就可以开始具体的操作。首先,本文所需用到的代码如下。
# -*- coding: utf-8 -*-
"""
Created on Fri Apr 15 16:44:26 2022
@author: fkxxgis
"""
import arcpy
from arcpy.sa import *
tif_file_path="E:/LST/Data/NDVI/03_Mosaic/"
shp_file="E:/LST/Data/Region/YellowRiver_nineprovince.shp"
out_file_path="E:/LST/Data/NDVI/04_Mask/"
resample_file_path="E:/LST/Data/NDVI/05_Resample/"
arcpy.env.workspace=tif_file_path
arcpy.env.extent=shp_file
tif_file_name=arcpy.ListRasters("*","tif")
for tif_file in tif_file_name:
mask_result=ExtractByMask(tif_file,shp_file)
mask_result_path=out_file_path+"/"+tif_file.strip(".tif")+"_Mask.tif"
mask_result.save(mask_result_path)
arcpy.env.workspace=out_file_path
tif_file_name=arcpy.ListRasters("*","tif")
for tif_file in tif_file_name:
resample_file_name=tif_file.strip(".tif")+"_Re.tif"
arcpy.Resample_management(tif_file,resample_file_path+resample_file_name,
1000,"BILINEAR")
其中,tif_file_path是原有掩膜前遥感图像的保存路径,shp_file是已知面要素矢量图层文件的保存路径,out_file_path是我们新生成的掩膜后遥感影像的保存路径,resample_file_path则是最终重采样后遥感影像的保存路径。
在这里,我们首先利用arcpy.ListRasters()函数,获取路径下原有的全部.tif格式的图像文件,并存放于tif_file_name中;随后,遍历tif_file_path路径下全部.tif格式图像文件(即遍历tif_file_name),并利用ExtractByMask()函数进行掩膜操作;其次,对于掩膜好的图层,在其原有文件名后添加"_Mask.tif"后缀,作为新文件的文件名。
对全部图像文件完成掩膜操作后,我们继续进行重采样操作。和前述代码思路类似,我们依然还是先遍历文件,并在其原有文件名后添加"_Re.tif"后缀,作为新文件的文件名;随后,利用Resample_management()函数进行重采样。其中,1000表示重采样的空间分辨率,在这里单位为米;"BILINEAR"表示用双线性插值的方法完成重采样。
以上便是本次操作的全部代码;我们这里选择在 IDLE (Python GUI) 中运行代码。运行完毕,得到的一个结果文件如下图;可以看到,遥感影像已经完成了掩膜,且空间分辨率已经为1000 m。
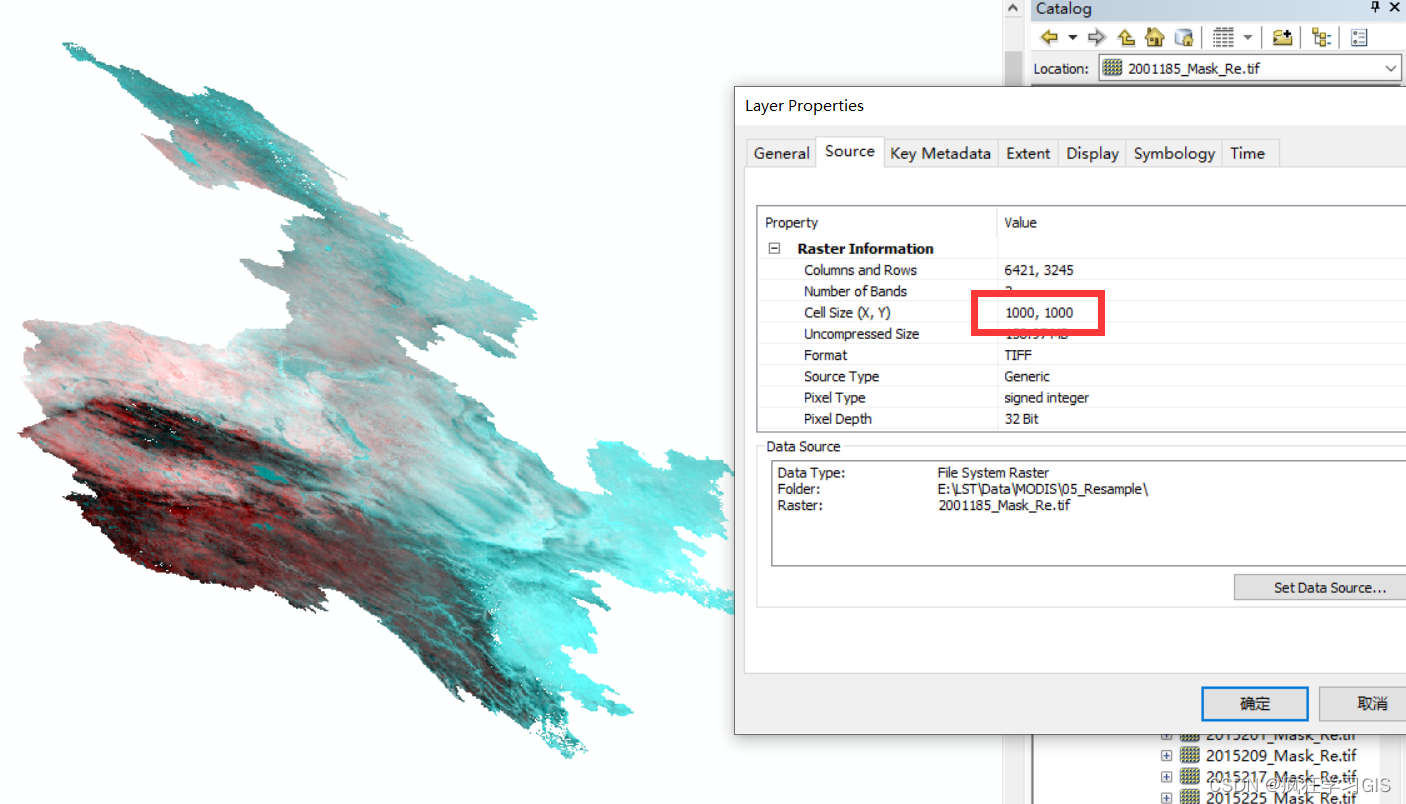
至此,大功告成。
我想使用Ruby检查数千对文件中的每对文件是否包含相同的信息。有人能指出我正确的方向吗? 最佳答案 require'fileutils'FileUtils.compare_file('file1','file2')当且仅当文件file1和file2相同时返回true。 关于ruby-如何批量检查文件内容是否相同,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/33769865/
假设你有这个结构:classHouse请注意,Tv的用户是故意不可访问的。所以你有一个三层嵌套的表单,允许你在一个页面上输入房子、房间和电视。这是Controller的创建方法:defcreate@house=House.new(params[:house])if@house.save#...standardstuffelse#...standardstuffendend问题:您究竟如何为每台电视填充user_id(它应该来自current_user.id)?什么是好的做法?这是我在其中看到的catch22。将user_ids直接填充到params散列中(它们嵌套得很深)保存将失败,因
在我的Rails应用程序中,我有users,它可以有许多invoices,而invoices又可以有许多payments。现在在dashboardView中,我想总结一个user曾经收到的所有payments,按年、季度或月。付款也分割为毛额、Netty和税额。user.rb:classUser:items).allpayments_with_invoice.select{|x|range.cover?x.date}.sum(&:"#{kind}_amount")endend发票.rb:classInvoicepayment.rb:classPaymentdashboards_cont
我运行的是OSX,对视频转换一无所知。但我有大约200个视频都是mp4格式,无法在Firefox中播放。我需要将它们转换为ogg才能使用html5视频标签。这些文件位于一个文件夹结构中,这使得一次一个地处理一个文件变得困难。我希望bash命令或Ruby命令遍历所有子文件夹并找到所有.mp4并转换它们。我找到了一份关于如何使用Google执行此操作的引用资料:http://athmasagar.wordpress.com/2011/05/12/a-bash-script-to-convert-mp4-files-to-oggogv/#!/bin/bashforfin$(ls*mp4|se
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭8年前。Improvethisquestion我作为承包商加入了一个Rails项目。该项目已经进行了一年多。代码由大约10名不同的开发人员编写,其中大多数也是承包商。他们有不同的代码风格。其中一些来自Java。该代码在metric_fu方面得分很低。许多函数非常长(100-300行)。有些函数有大量的逻辑分支、循环和递归。每个请求都会生成大量的sql查询。性能很差。许多过时的代码从未使用过但从未有机会被清理。核心架构明显错误或设计过度
如果我有一个数组:a=[1,2,3]如何随机选择数组的子集,使每个子集的元素都是唯一的?也就是说,对于a,可能的子集是:[][1][2][3][1,2][2,3][1,2,3]我无法生成所有可能的子集,因为a的实际大小非常大,所以有很多很多子集。目前,我正在使用“随机游走”的想法——对于a的每个元素,我都会“抛硬币”,如果硬币正面朝上则将其包括在内——但我不确定这是否真的对空间进行了均匀采样。感觉它偏向于中间,但这可能只是我的想法在进行模式匹配,因为会有更多中等大小的可能性。我使用的方法是否正确,或者我应该如何随机抽样?(我知道这更像是一个与语言无关的“数学”问题,但我觉得这不是真正的
是否可以使用Sequel在一次调用中进行多次更新??例如,在我的服务器上进行大约200次更新可能需要几分钟,但如果我伪造一个SQL查询,它会在几秒钟内运行。我想知道Sequel是否可以用来伪造那个SQL查询,或者更好的是,自己完成整个操作。 最佳答案 我遇到的解决方案涉及update_sql方法。它不是自己执行操作,而是输出原始SQL查询。要批量更新多个更新,只需将它们与;连接起来即可。在此期间,使用结果字符串调用run方法,一切就绪。批处理解决方案比多次更新快得多。 关于sql-是否可
我有一个Rails应用,其用户模型包含一个admin属性。它使用attr_accessible锁定。我的模型如下所示:attr_accessible:name,:email,:other_email,:plant_id,:password,:password_confirmationattr_accessible:name,:email,:other_email,:plant_id,:password,:password_confirmation,:admin,:as=>:admin下面是我的用户Controller中的更新方法:defupdate@user=User.find(par
我正在读取一个大小为10mb且包含一些ID的文件。我将它们读入ruby列表。我担心将来可能会导致内存问题,因为文件中的id数量可能会增加。有没有一种批量读取大文件的有效方法?谢谢 最佳答案 与LazyEnumerators和each_slice,您可以两全其美。中间切线不用担心,可以批量迭代多行。batch_size可以自由选择。header_lines=1batch_size=2000File.open("big_file")do|file|file.lazy.drop(header_lines).each_slice(batch
我有一个存储在数组中的大约30万个常用词的列表。因此,数组的1个元素=1个单词。另一方面,我有一个巨大的字符串列表,其中可能包含这30万个单词中的一个或多个。示例字符串为:ifdxawesome453。现在,我需要根据常用词检查这些长字符串中的每一个。如果在该字符串中找到一个单词,则立即返回。因此,我需要再次检查这30万个单词ifdxawesome453并查看其中是否包含任何单词。所以我做的是:huge_list_of_words.any?do|word|random_long_word.include?(word)end虽然这对于随机长单词的小样本来说没问题,但如果我有数百万个单词,