由于目前网上对于springboot配置文件的加载问题,存在着各种不同的说法。所以导致自己不敢确定到底何种结论才是真正正确的,故专门花费了一些时间进行亲自验证。
在经过自己对配置文件的加载问题进行验证后,发现所谓配置文件的优先级并不一定是固定不变的,而是会受一些前提条件的影响。下面将对bootstrap.properties、bootstrap.yml、application.properties、application.yml这四种我们可能使用到的配置文件的加载优先级问题进行详细的说明(此处以springCloud微服务项目为背景,不然单纯的springBoot项目是不会加载bootstrap配置文件的,且以下说明默认配置文件都是在同一目录)。
首先,在默认的情况下也就是不存在活动的profile(即不指定spring.profiles.active=?)时,四种文件的加载优先级依次为bootstrap.properties -> bootstrap.yml -> application.properties -> application.yml。感兴趣可以在源码上打断点可以得知配置文件的加载分为两次,如图所示:
第一次是bootstrap(.properties/.yml)的加载:
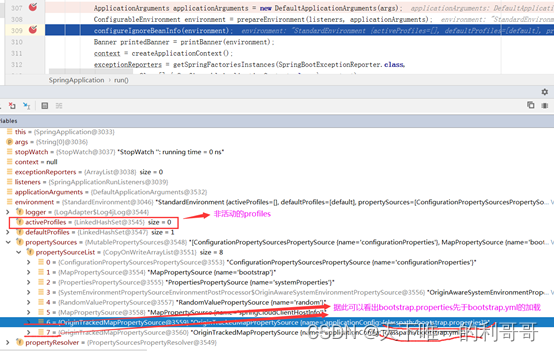
以此得出加载优先级bootstrap.properties -> bootstrap.yml
第二次是application(.properties/yml)的加载:
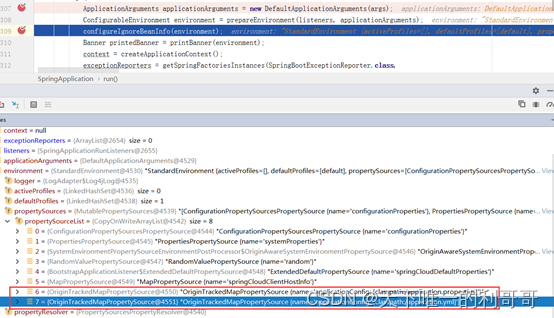
以此得出application.properties -> application.yml。
总结:bootstrap的配置先于application的配置加载,同时.properties的加载又先于.yml的加载,即加载优先级bootstrap.properties -> bootstrap.yml -> application.properties -> application.yml。
需要注意的是:
1.当同一个配置属性在bootstrap.properties和bootstrap.yml文件中都存在时,那么properties中的配置会被加载,而忽略yml文件中的配置(即优先级高的配置覆盖优先级低的配置),不同配置相互互补。此处application(.properties/yml)同理。
2.但当同一配置在bootstrap.properties和application.properties中都存在时,那么虽然优先加载bootstrap.properties但是会被applicatioin.properties中的配置覆盖,此时则变成了低优先级覆盖高优先的配置,所以网上很多文章所说的高优先级覆盖低优先级其实是不严谨的。
3.不同的配置会进行互补操作,即SpringBoot会读取全部的配置文件,加载所有不同的配置项,汇成一个总的配置。
例如在指定了spring.profiles.active=dev/test/prod此类时,即有了活动的profile时,加载优先级便会发生变化此时活动的优先级最高,还是直接上图:

指定profile为dev
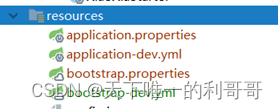
配置文件如上
看一下加载顺序变成怎么样的了,同样第一次先加载bootstrap:
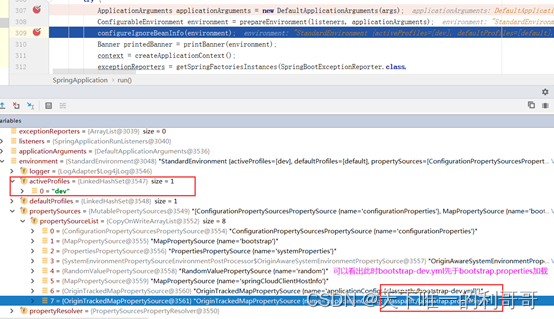
第二次加载application:
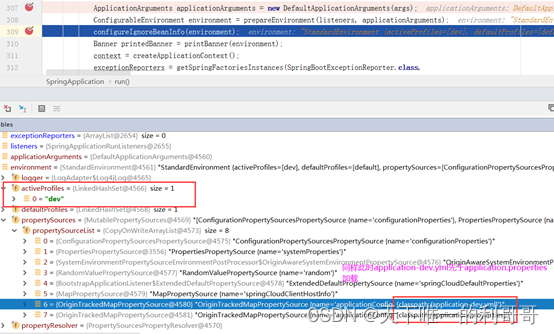
综上此时的加载优先级变为了bootstrap-dev.yml -> bootstrap.properties -> application-dev.yml ->application.properties。且同属性配置的覆盖问题和之前一样,在同为bootstrap或同为application的情况下,优先级高的覆盖优先级低的。但当同时存在bootstrap和application时后者仍会覆盖前者中的配置。
举例1:假如此时只有bootstrap-dev.yml 和bootstrap.properties且存在相同配置,则使用bootstrap-dev.yml中的配置,此时遵循高优先级覆盖低优先级。
举例2:假如此时有bootstrap-dev.yml 、bootstrap.properties及application.properties且存在相同配置,则使用application.properties中的配置,遵循application覆盖bootstrap原则,同样此时变成了低优先级覆盖高优先级。
如项目使用nacos做配置中心,则存在相同配置时以nacos中配置为主(在没有开启本地覆盖nacos远程配置的情况下),nacos中的配置将会覆盖一切本地相同的配置,不同配置可以和本地进行互补。
如果需要启动参数或者本地配置覆盖远程配置,那么需要在远程配置里配置上允许重写:
spring.cloud.config.allowOverride=true
但这是不够的,尽管它开启了总开关,但是还有两个默认的小开关卡住了。
应同时添加如下配置:
spring.cloud.config.overrideNone=true
spring.cloud.config.overrideSystemProperties=false
第一个开关是远端不覆盖本地?true 是的不覆盖。
第二个开关是远端是否覆盖系统配置?false 不覆盖。 (默认为true 覆盖)
请注意,第一个小开关包括第二个。
overrideNone = true的话会开启所有包括本地配置和系统配置并忽略掉overrideSystemProperties配置。
如果只想开启overrideSystemProperties,那么就是overrideNone = false,overrideSystemProperties=false。
我有一个Ruby程序,它使用rubyzip压缩XML文件的目录树。gem。我的问题是文件开始变得很重,我想提高压缩级别,因为压缩时间不是问题。我在rubyzipdocumentation中找不到一种为创建的ZIP文件指定压缩级别的方法。有人知道如何更改此设置吗?是否有另一个允许指定压缩级别的Ruby库? 最佳答案 这是我通过查看rubyzip内部创建的代码。level=Zlib::BEST_COMPRESSIONZip::ZipOutputStream.open(zip_file)do|zip|Dir.glob("**/*")d
我试图在一个项目中使用rake,如果我把所有东西都放到Rakefile中,它会很大并且很难读取/找到东西,所以我试着将每个命名空间放在lib/rake中它自己的文件中,我添加了这个到我的rake文件的顶部:Dir['#{File.dirname(__FILE__)}/lib/rake/*.rake'].map{|f|requiref}它加载文件没问题,但没有任务。我现在只有一个.rake文件作为测试,名为“servers.rake”,它看起来像这样:namespace:serverdotask:testdoputs"test"endend所以当我运行rakeserver:testid时
我的目标是转换表单输入,例如“100兆字节”或“1GB”,并将其转换为我可以存储在数据库中的文件大小(以千字节为单位)。目前,我有这个:defquota_convert@regex=/([0-9]+)(.*)s/@sizes=%w{kilobytemegabytegigabyte}m=self.quota.match(@regex)if@sizes.include?m[2]eval("self.quota=#{m[1]}.#{m[2]}")endend这有效,但前提是输入是倍数(“gigabytes”,而不是“gigabyte”)并且由于使用了eval看起来疯狂不安全。所以,功能正常,
Rails2.3可以选择随时使用RouteSet#add_configuration_file添加更多路由。是否可以在Rails3项目中做同样的事情? 最佳答案 在config/application.rb中:config.paths.config.routes在Rails3.2(也可能是Rails3.1)中,使用:config.paths["config/routes"] 关于ruby-on-rails-Rails3中的多个路由文件,我们在StackOverflow上找到一个类似的问题
对于具有离线功能的智能手机应用程序,我正在为Xml文件创建单向文本同步。我希望我的服务器将增量/差异(例如GNU差异补丁)发送到目标设备。这是计划:Time=0Server:hasversion_1ofXmlfile(~800kiB)Client:hasversion_1ofXmlfile(~800kiB)Time=1Server:hasversion_1andversion_2ofXmlfile(each~800kiB)computesdeltaoftheseversions(=patch)(~10kiB)sendspatchtoClient(~10kiBtransferred)Cl
我正在寻找执行以下操作的正确语法(在Perl、Shell或Ruby中):#variabletoaccessthedatalinesappendedasafileEND_OF_SCRIPT_MARKERrawdatastartshereanditcontinues. 最佳答案 Perl用__DATA__做这个:#!/usr/bin/perlusestrict;usewarnings;while(){print;}__DATA__Texttoprintgoeshere 关于ruby-如何将脚
如何在buildr项目中使用Ruby?我在很多不同的项目中使用过Ruby、JRuby、Java和Clojure。我目前正在使用我的标准Ruby开发一个模拟应用程序,我想尝试使用Clojure后端(我确实喜欢功能代码)以及JRubygui和测试套件。我还可以看到在未来的不同项目中使用Scala作为后端。我想我要为我的项目尝试一下buildr(http://buildr.apache.org/),但我注意到buildr似乎没有设置为在项目中使用JRuby代码本身!这看起来有点傻,因为该工具旨在统一通用的JVM语言并且是在ruby中构建的。除了将输出的jar包含在一个独特的、仅限ruby
使用带有Rails插件的vim,您可以创建一个迁移文件,然后一次性打开该文件吗?textmate也可以这样吗? 最佳答案 你可以使用rails.vim然后做类似的事情::Rgeneratemigratonadd_foo_to_bar插件将打开迁移生成的文件,这正是您想要的。我不能代表textmate。 关于ruby-使用VimRails,您可以创建一个新的迁移文件并一次性打开它吗?,我们在StackOverflow上找到一个类似的问题: https://sta
鉴于我有以下迁移:Sequel.migrationdoupdoalter_table:usersdoadd_column:is_admin,:default=>falseend#SequelrunsaDESCRIBEtablestatement,whenthemodelisloaded.#Atthispoint,itdoesnotknowthatusershaveais_adminflag.#Soitfails.@user=User.find(:email=>"admin@fancy-startup.example")@user.is_admin=true@user.save!ende
好的,所以我的目标是轻松地将一些数据保存到磁盘以备后用。您如何简单地写入然后读取一个对象?所以如果我有一个简单的类classCattr_accessor:a,:bdefinitialize(a,b)@a,@b=a,bendend所以如果我从中非常快地制作一个objobj=C.new("foo","bar")#justgaveitsomerandomvalues然后我可以把它变成一个kindaidstring=obj.to_s#whichreturns""我终于可以将此字符串打印到文件或其他内容中。我的问题是,我该如何再次将这个id变回一个对象?我知道我可以自己挑选信息并制作一个接受该信