文章目录
部署 MongoDB 一般有三种方式
| 模式 | 架构 | 优点 | 缺点 |
|---|---|---|---|
| standalone 独立模式 | 单节点 | 容易部署 | 无容灾方案 |
| relicaset 主从模式 | 常用一主两从 | 高可用,自动进行故障切换恢复 | 部署和应用都比较复杂 |
| sharded 分片模式 | 常用 分片数为4,配置服务器的副本为 3 ,数据节点副本为 2 | 支持水平扩展,可忍受非常大的数据集,并提供高吞吐量d操作 | 概念比较苦涩难懂 |
主从模式:同一份数据被保存在N台机器上,每台机器上都有一份数据。
分片模式:一份数据被分开保存在N台机器上,N个机器上的数据组合起来是一份数据。
本文使用 bitnami chart 进行 MongoDB 的部署
引入 bitnami
helm repo add bitnami https://charts.bitnami.com/bitnami
官方文档:https://github.com/bitnami/charts/tree/master/bitnami/mongodb
新增配置文件 values.yaml
global:
storageClass: "nfs-client"
metrics:
enabled: true
auth:
rootPassword: "5gTU4o7g5g"
service:
type: "NodePort"
nodePorts:
mongodb: "30017"
architecture:默认就是独立模式
service.nodePorts.mongodb:开启外部访问
部署命令
helm install mongodb bitnami/mongodb -f values.yaml -n [命名空间]
官方文档:https://github.com/bitnami/charts/tree/master/bitnami/mongodb
新增配置文件 values.yaml
global:
storageClass: "nfs-client"
architecture: "replicaset"
auth:
rootPassword: "5gTU4o7g5g"
replicaSetKey: "mymongodb"
usernames:
- "user"
passwords:
- "123456"
databases:
- "message"
replicaCount: 2
externalAccess:
enabled: true
service:
externalTrafficPolicy: "Cluster"
type: "NodePort"
nodePorts:
- 30018
- 30019
architecture:架构设置为 replicaset
auth.replicaSetKey:更新 upgrade 时有用,可以不设置,若要设置,字符必须大于5
auth.usernames、auth.passwords、 auth.databases:用户名、密码和数据库;格式为数组,一一对应
replicaCount:副本集,按需设置
externalAccess.enabled:开启外部访问
externalAccess.service.externalTrafficPolicy:有 Local 和 Cluster 两种选项;Cluster:[集群里所有 ip] + [nodeport端口] 都访问服务,Local :只能用 [容器所在 ip] + [nodeport端口] 才能访问
externalAccess.service.type:LoadBalancer 或者 NodePort,这里使用 NodePort
externalAccess.service.nodePorts:这里是数组结构,数组大小和 replicaCount 一致
部署命令
helm install mongodb bitnami/mongodb -f values.yaml -n [命名空间]
官方部署文档:https://github.com/bitnami/charts/tree/master/bitnami/mongodb-sharded
官方原理文档:https://www.mongodb.com/docs/manual/sharding/
| 配置项 | 默认配置 | 推荐配置 | |
|---|---|---|---|
| mongos | 路由 | 1 | 1 |
| config | 配置服务器 | 1 | 3 |
| shards | 分片数 | 1 | 4 |
| replica | 副本数 | 2 | 2 |
新增配置文件 values.yaml
global:
storageClass: "nfs-client"
auth:
rootPassword: "5gTU4o7g5g"
##### 可不配置 #######
shards: 4
configsvr:
replicaCount: 3
shardsvr:
dataNode:
replicaCount: 2
##### 可不配置 #######
service:
type: "NodePort"
nodePorts:
mongodb: "30019"
shards、configsvr、shardsvr:可以不配置,按默认值也可以
service.type:外部访问方式,选择 NodePort
service.nodePorts.mongodb:开发端口
部署命令
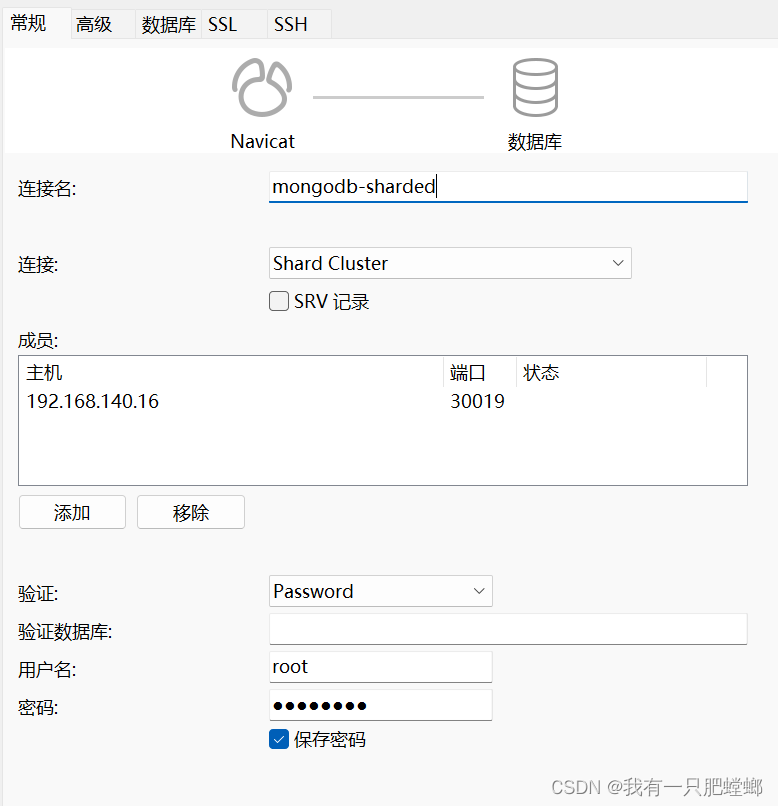
helm install mongodb bitnami/mongodb-sharded -f values.yaml -n [命名空间]
默认部署结构
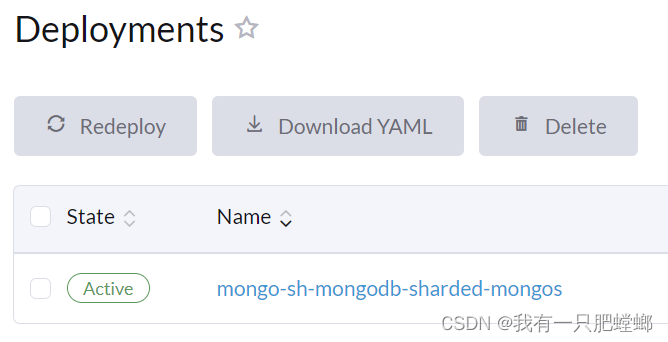
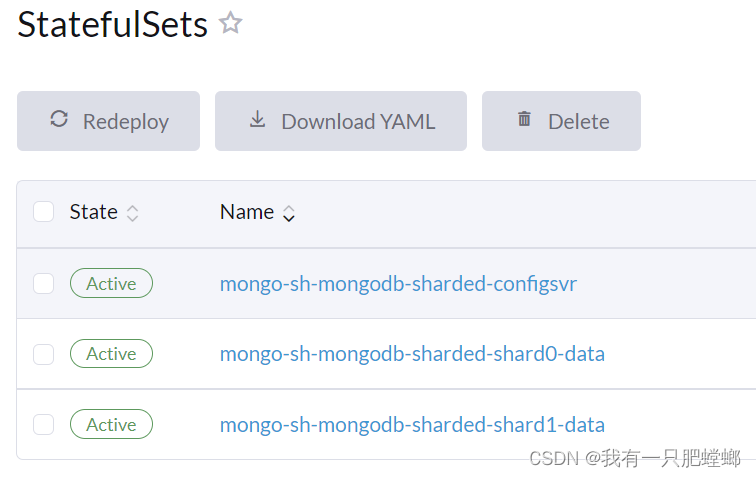
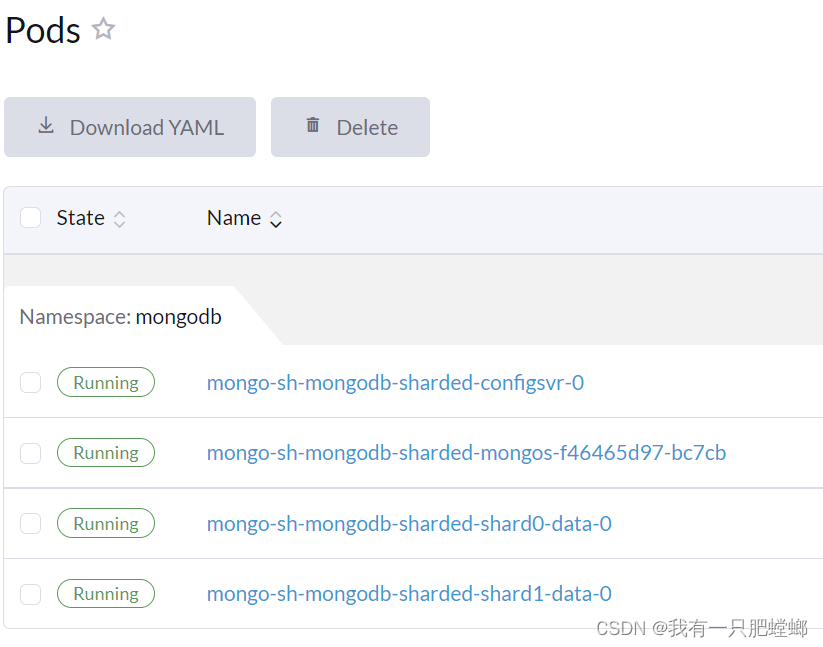
优化部署结构
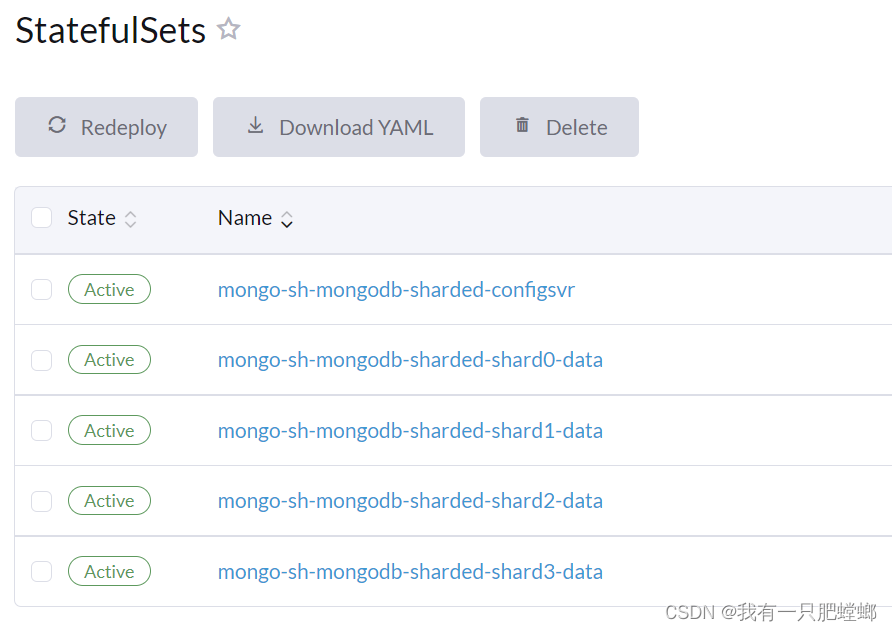
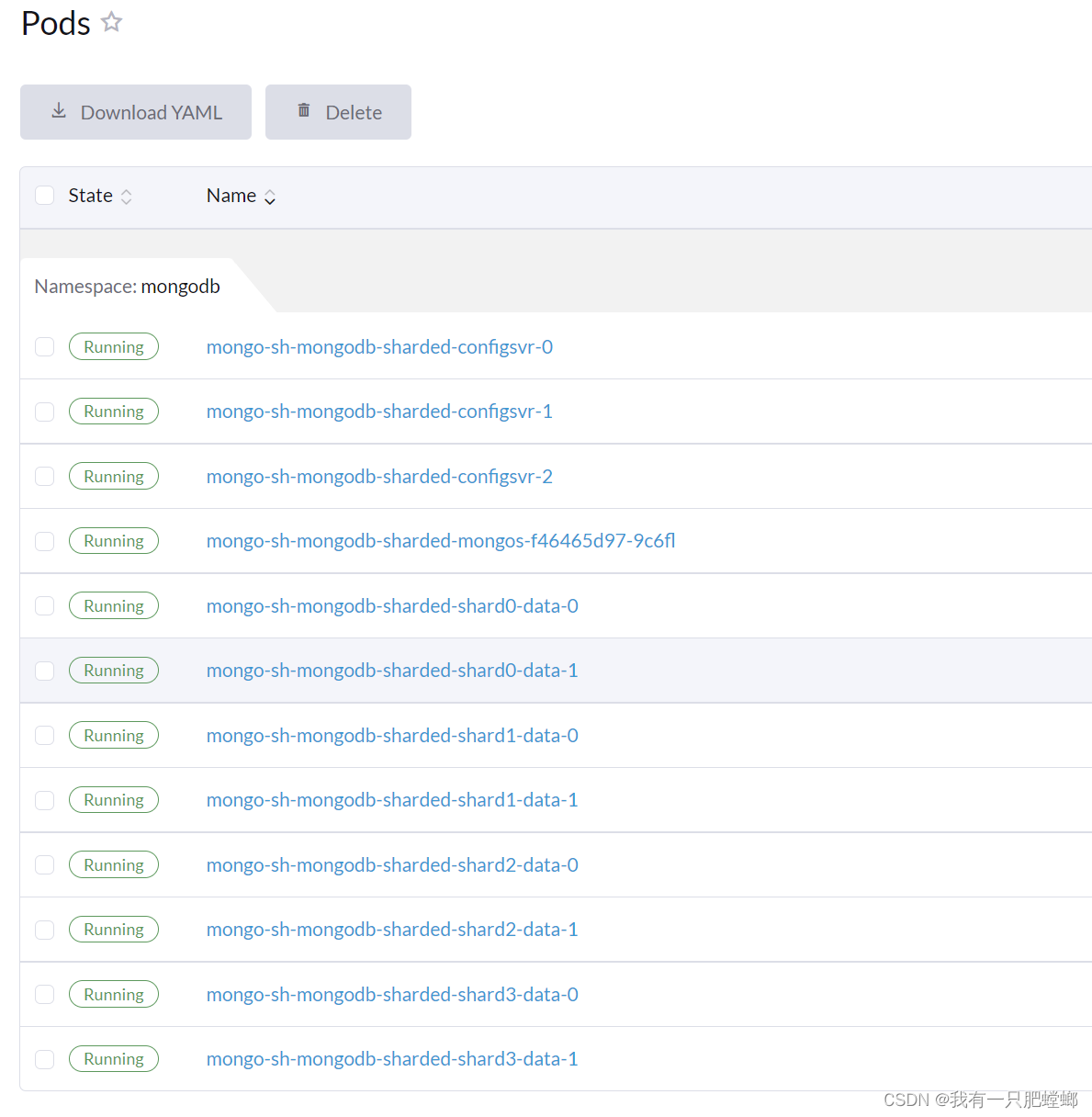
standalone 独立模式

relicaset 主从模式
sharded 分片模式
pom 文件添加依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-mongodb</artifactId>
</dependency>
application.yml 示例
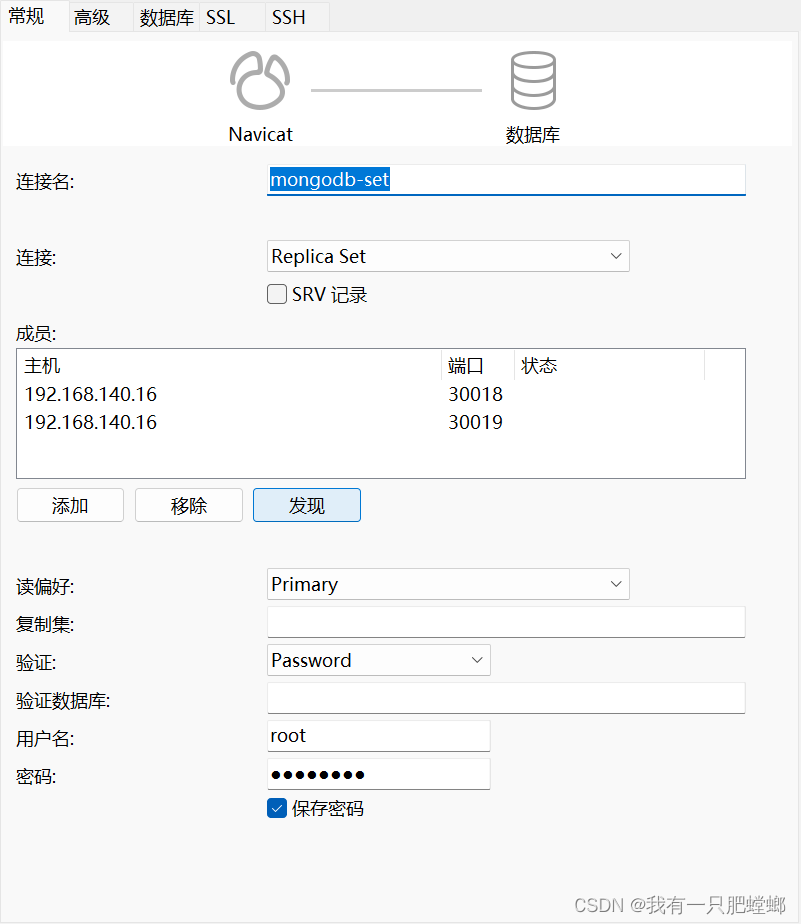
有账号密码时,必须添加 authSource=admin
data:
mongodb:
uri: mongodb://root:123456@192.168.140.01:30020/datasource?authSource=admin
官方示例
mongodb://[username:password@]host1[:port1][,...hostN[:portN]][/[defaultauthdb][?options]]
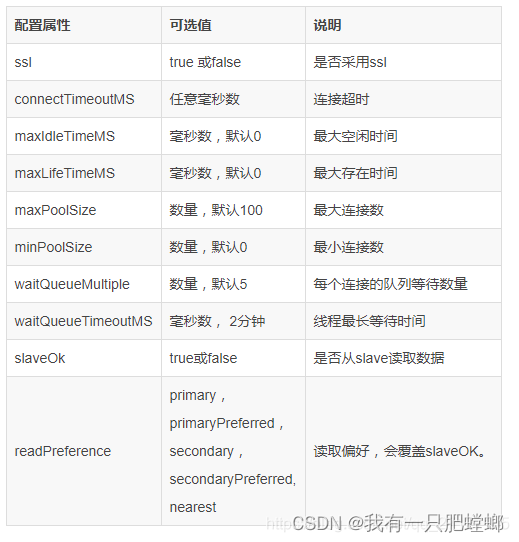
options 属性简介
官方 Replica Set 示例
mongodb://db0.example.com:27017,db1.example.com:27017,db2.example.com:27017/?replicaSet=myRepl
官方文档:https://www.mongodb.com/docs/manual/reference/connection-string/
不做详细介绍,有需要可看官网
官方文档 https://mongodb.github.io/mongo-java-driver/3.4/driver/getting-started/installation/
storageClass 参考文档
搭建本地存储可以参考 k8s 安装本地 storageClass
搭建NFS存储可以参考 K8S 集群使用 NFS 做 storageclass
我有一个模型:classItem项目有一个属性“商店”基于存储的值,我希望Item对象对特定方法具有不同的行为。Rails中是否有针对此的通用设计模式?如果方法中没有大的if-else语句,这是如何干净利落地完成的? 最佳答案 通常通过Single-TableInheritance. 关于ruby-on-rails-Rails-子类化模型的设计模式是什么?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.co
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
鉴于我有以下迁移:Sequel.migrationdoupdoalter_table:usersdoadd_column:is_admin,:default=>falseend#SequelrunsaDESCRIBEtablestatement,whenthemodelisloaded.#Atthispoint,itdoesnotknowthatusershaveais_adminflag.#Soitfails.@user=User.find(:email=>"admin@fancy-startup.example")@user.is_admin=true@user.save!ende
我是Google云的新手,我正在尝试对其进行首次部署。我的第一个部署是RubyonRails项目。我基本上是在关注thisguideinthegoogleclouddocumentation.唯一的区别是我使用的是我自己的项目,而不是他们提供的“helloworld”项目。这是我的app.yaml文件runtime:customvm:trueentrypoint:bundleexecrackup-p8080-Eproductionconfig.ruresources:cpu:0.5memory_gb:1.3disk_size_gb:10当我转到我的项目目录并运行gcloudprevie
给定一个复杂的对象层次结构,幸运的是它不包含循环引用,我如何实现支持各种格式的序列化?我不是来讨论实际实现的。相反,我正在寻找可能会派上用场的设计模式提示。更准确地说:我正在使用Ruby,我想解析XML和JSON数据以构建复杂的对象层次结构。此外,应该可以将该层次结构序列化为JSON、XML和可能的HTML。我可以为此使用Builder模式吗?在任何提到的情况下,我都有某种结构化数据-无论是在内存中还是文本中-我想用它来构建其他东西。我认为将序列化逻辑与实际业务逻辑分开会很好,这样我以后就可以轻松支持多种XML格式。 最佳答案 我最
我可以在Azure网站上部署RubyonRails吗? 最佳答案 还没有。目前仅支持.NET和PHP。 关于ruby-on-rails-RubyonRails可以部署在Azure网站上吗?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/12964010/
前置步骤我们都操作完了,这篇开始介绍jenkins的集成。话不多说,看操作1、登录进入jenkins后会让你选择安装插件,选择第一个默认的就行。安装完成后设置账号密码,重新登录。2、配置JDK和Git都需要执行路径,所以需要先把执行路径找到,先进入服务器的docker容器,2.1JDK的路径root@69eef9ee86cf:/usr/bin#echo$JAVA_HOME/usr/local/openjdk-82.2Git的路径root@69eef9ee86cf:/#whichgit/usr/bin/git3、先配置JDK和Git。点击:ManageJenkins>>GlobalToolCon
深度学习部署:Windows安装pycocotools报错解决方法1.pycocotools库的简介2.pycocotools安装的坑3.解决办法更多Ai资讯:公主号AiCharm本系列是作者在跑一些深度学习实例时,遇到的各种各样的问题及解决办法,希望能够帮助到大家。ERROR:Commanderroredoutwithexitstatus1:'D:\Anaconda3\python.exe'-u-c'importsys,setuptools,tokenize;sys.argv[0]='"'"'C:\\Users\\46653\\AppData\\Local\\Temp\\pip-instal
了解Rails缓存如何工作的人可以真正帮助我。这是嵌套在Rails::Initializer.runblock中的代码:config.after_initializedoSomeClass.const_set'SOME_CONST','SOME_VAL'end现在,如果我运行script/server并发出请求,一切都很好。然而,在我的Rails应用程序的第二个请求中,一切都因单元化常量错误而变得糟糕。在生产模式下,我可以成功发出第二个请求,这意味着常量仍然存在。我已通过将以上内容更改为以下内容来解决问题:config.after_initializedorequire'some_cl
Ocra无法处理需要“tk”的应用程序require'tk'puts'nope'用奥克拉http://github.com/larsch/ocra不起作用(如链接中的一个问题所述)问题:https://github.com/larsch/ocra/issues/29(Ocra是1.9的"new"rubyscript2exe,本质上它用于将rb脚本部署为可执行文件)唯一的问题似乎是缺少tcl的DLL文件我不认为这是一个问题据我所知,问题是缺少tk的DLL文件如果它们是已知的,则可以在执行ocra时将它们包括在内有没有办法知道tk工作所需的DLL依赖项? 最佳答