标准模板库STL部分包含在C++标准库中的软件库。
c++标准库:即以std::开头,但是部分编译器厂商也会把STL的内容放在std:: namespace里面
由于一个常见的误解,您可能会将C++标准库视为“STL”,或者将工具链中C++标准库的实现部分视为“STL实现”。
事实并非如此。
MSVC ++和GCC(作为编译器特定的扩展实现)都将其放在std命名空间中也是非常可惜的,这不仅具有高度误导性,而且根据标准也是非法的。
为什么c++的名词会这么混乱?
因为c++委员会制定标准,各家编译器厂商实现标准(gcc,msvc)
类似于C#中的List,长度会自动扩容(2倍扩容),普通的数组需要初始化长度。
vector容器是支持随机访问的,即可以像数组一样用[]来取值。但不是所有的STL容器都有这个特性!
| 用法 | 作用 |
|---|---|
| vec.begin(),vec.end() | 返回vector的首、尾迭代器 |
| vec.front(),vec.back() | 返回vector的首、尾元素 |
| vec.push_back() | 从vector末尾加入一个元素 |
| vec.size() | 返回vector当前的长度(大小) |
| vec.pop_back() | 从vector末尾删除一个元素 |
| vec.empty() | 返回vector是否为空,1为空、0不为空 |
| vec.clear() | 清空vector |
先进先出,没有clear,也不支持遍历
文档:std::queue - cppreference.com
| 用法 | 作用 |
|---|---|
| q.front(),q.back() | 返回queue的首、尾元素 |
| q.push() | 从queue末尾加入一个元素 |
| q.size() | 返回queue当前的长度(大小) |
| q.pop() | 删除首个元素 |
| q.empty() | 返回queue是否为空,1为空、0不为空 |
后进先出
| 用法 | 作用 |
|---|---|
| st.top() | 返回stack的栈顶元素 |
| st.push() | 从stack栈顶加入一个元素 |
| st.size() | 返回stack当前的长度(大小) |
| st.pop() | 从stack栈顶弹出一个元素 |
| st.empty() | 返回stack是否为空,1为空、0不为空 |
string是C++风格的字符串,而string本质上是一个类
string和char * 区别:
char*,管理这个字符串,是一个char*型的容器string特点:
string 类内部封装了很多成员方法,例如:查找find,拷贝copy,删除delete 替换replace,插入insert
string管理char*所分配的内存,不用担心复制越界和取值越界等,由类内部进行负责
导入:#include
<string>// 注意这里不是string.h,string.h是C字符串头文件
| 用法 | 说明 |
|---|---|
| int find(const string& str, int pos = 0) const; | 查找str第一次出现位置,从pos开始查找 |
| int compare(const string &s) const; | 字符串比较是按字符的ASCII码进行对比,返回值:0:=,1:>,-1:< |
| string& insert(int pos, const string& str); | 插入字符串 |
| string& erase(int pos, int n = npos); | 删除从Pos开始的n个字符 |
| char& operator[](int n);char& at(int n); | 获取单个字符 |
| string substr(int pos = 0, int n = npos) const; | 返回由pos开始的n个字符组成的字符串 |
参考资料:
\0:是一个空字符,在cout中输出是空的,表示字符串的结束
string str;
const char *c = str.c_str();
string str;
const char *pc = "Hello World";
str = pc;
char ch [] = "ABCDEFG";
string str(ch); //也可string str = ch;
string str="hello";
printf(“%s\n”, str); //此处出现错误的输出
cout<<str<<endl;
用printf(“%s”,str);输出是会出问题的。这是因为“%s”要求后面的对象的首地址。但是string不是这样的一个类型,若一定要printf输出。那么可以加上.c_str()。
map使用红黑树实现。查找时间在O(lg(n))-O(2*log(n))之间,构建map花费的时间比较长
c++中的map是有序的?我使用过其它语言map都是无序的,经测试确实是有序的
map中获取某个值的方法:find,然后再通过first,second来取key和value
map和multimap应该使用那一个?
在项目代码中multimap会多一些
hash_map是 STL 的一部分,但不是标准C++ (C++11) 的一部分。在标准C++中,有一个名为“std::unordered_map”的功能类似unordered_map实现:http://www.cplusplus.com/reference/unordered_map/unordered_map/
C++11 引入了 std::unordered_map和hash_map没有什么不同。
参考资料:https://stackoverflow.com/questions/5908581/is-hash-map-part-of-the-stl
hash_map 查找速度会比map快,而且查找速度基本和数据数据量大小,属于常数级别;而map的查找速度是log(n)级别。并不一定常数就比log(n)小,hash还有hash函数的耗时,明白了吧,如果你考虑效率,特别是在元素达到一定数量级时,考虑考虑hash_map。
但若你对内存使用特别严格,希望程序尽可能少消耗内存,那么一定要小心,hash_map可能会让你陷入尴尬,特别是当你的hash_map对象特别多时,你就更无法控制了,而且hash_map的构造速度较慢。
来源:C++ map和hashmap用法_qq_33216029的博客-CSDN博客_c++ hashmap
set容器,有点像C#中的hashset,里面的元素是唯一不重复的,且内部排好序(升序排列)。
set容器自动有序和快速添加、删除的性质是由其内部实现:红黑树(平衡树的一种)
| 用法 | 作用 |
|---|---|
| s.empty() | 当前集合是否为空,是返回1,否则返回0. |
| s.size() | 当前集合的元素个数 |
| s.clear() | 清空当前集合 |
| s.begin(),s.end(); | 返回集合的首尾迭代器。注意是迭代器。我们可以把迭代器理解为数组的下标。但其实迭代器是一种指针 |
| s.insert(k) | 向集合中加入元素k |
| s.erase(k) | 删除集合中元素k |
| s.find(k) | 返回集合中指向元素k的迭代器。如果不存在这个元素,就返回s.end() |
| 用法 | 作用 |
|---|---|
| q.begin(),q.end() | 返回deque的首、尾迭代器 |
| q.front(),q.back() | 返回deque的首、尾元素 |
| q.push_back() | 从队尾入队一个元素 |
| q.push_front() | 从队头入队一个元素 |
| q.pop_back() | 从队尾出队一个元素 |
| q.pop_front() | 从队头出队一个元素 |
| q.clear() | 清空队列 |
deque的特点是双端进出,即处于双端队列中的元素既可以从队首进/出队,也可以从队尾进/出队,它是线性容器。
deque比queue更优秀的一个性质是它支持随机访问,即可以像数组下标一样取出其中的一个元素。

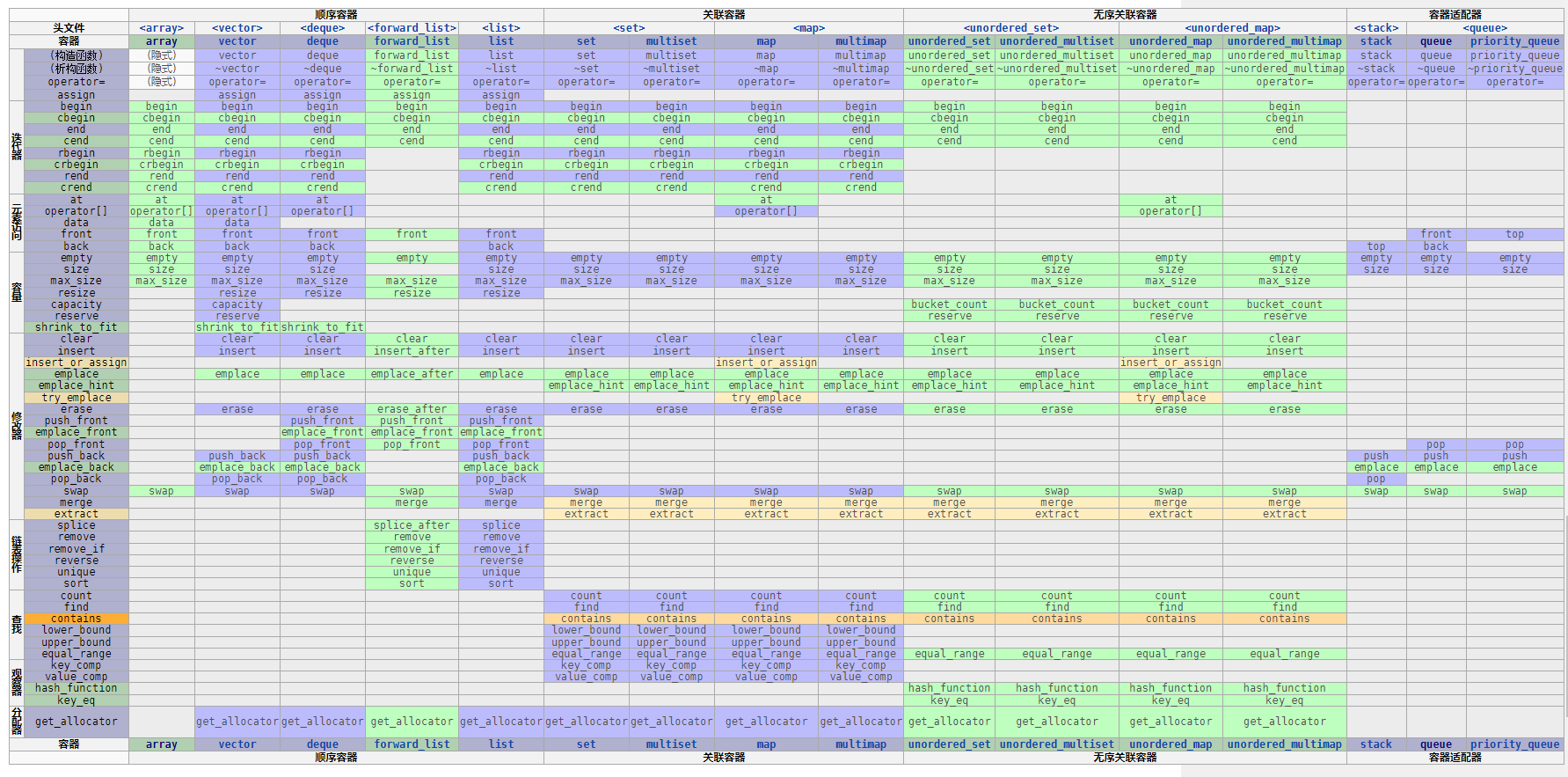
表格数据来源:容器库 - cppreference.com
对于作为String#tr参数的单引号字符串文字中反斜杠的转义状态,我觉得有些神秘。你能解释一下下面三个例子之间的对比吗?我特别不明白第二个。为了避免复杂化,我在这里使用了'd',在双引号中转义时不会改变含义("\d"="d")。'\\'.tr('\\','x')#=>"x"'\\'.tr('\\d','x')#=>"\\"'\\'.tr('\\\d','x')#=>"x" 最佳答案 在tr中转义tr的第一个参数非常类似于正则表达式中的括号字符分组。您可以在表达式的开头使用^来否定匹配(替换任何不匹配的内容)并使用例如a-f来匹配一
在Ruby1.9.3(可能还有更早的版本,不确定)中,我试图弄清楚为什么Ruby的String#split方法会给我某些结果。我得到的结果似乎与我的预期相反。这是一个例子:"abcabc".split("b")#=>["a","ca","c"]"abcabc".split("a")#=>["","bc","bc"]"abcabc".split("c")#=>["ab","ab"]在这里,第一个示例返回的正是我所期望的。但在第二个示例中,我很困惑为什么#split返回零长度字符串作为返回数组的第一个值。这是什么原因呢?这是我所期望的:"abcabc".split("a")#=>["bc"
我需要从json记录中获取一些值并像下面这样提取curr_json_doc['title']['genre'].map{|s|s['name']}.join(',')但对于某些记录,curr_json_doc['title']['genre']可以为空。所以我想对map和join()使用try函数。我试过如下curr_json_doc['title']['genre'].try(:map,{|s|s['name']}).try(:join,(','))但是没用。 最佳答案 你没有正确传递block。block被传递给参数括号外的方法
Enumerable#each和Enumerable#map的区别在于返回的是接收者还是映射后的结果。回到接收者是微不足道的,你通常不需要在each之后继续一个方法链,比如each{...}.another_method(我可能没见过这样的案例。即使你想回到接收者那里,你也可以通过tap来实现)。所以我认为所有或者大部分使用Enumerable#each的情况都可以用Enumerable#map代替。我错了吗?如果我是对的,each的目的是什么?map是否比each慢?编辑:我知道当您对返回值不感兴趣时使用each是一种常见的做法。我对这种做法是否存在不感兴趣,但感兴趣的是,除了从
我有这个ruby代码:defget_sumnreturn0ifn似乎正在为999之前的值工作。当我尝试9999时,它给了我这个:stackleveltoodeep(SystemStackError)所以,我添加了这个:RubyVM::InstructionSequence.compile_option={:tailcall_optimization=>true,:trace_instruction=>false}但什么也没发生。我的ruby版本是:ruby1.9.3p392(2013-02-22revision39386)[x86_64-darwin12.2.1]我还增加了机器的堆栈大
玩转ruby,我已经:#!/usr/bin/ruby-w#WorldweatheronlineAPIurlformat:http://api.worldweatheronline.com/free/v1/weather.ashx?q={location}&format=json&num_of_days=1&date=today&key={api_key}require'net/http'require'json'@api_key='xxx'@location='city'@url="http://api.worldweatheronline.com/free/v1/weather.
我有代码:classScenedefinitialize(number)@number=numberendattr_reader:numberendscenes=[Scene.new("one"),Scene.new("one"),Scene.new("two"),Scene.new("one")]groups=scenes.inject({})do|new_hash,scene|new_hash[scene.number]=[]ifnew_hash[scene.number].nil?new_hash[scene.number]当我启动它时出现错误:freq.rb:11:in`[]'
我的Ruby代码中有一个看起来有点像这样的结构Parameter=Struct.new(:name,:id,:default_value,:minimum,:maximum)稍后,我使用创建了这个结构的一个实例freq=Parameter.new('frequency',15,1000.0,20.0,20000.0)在某些时候,我需要这个结构的精确副本,所以我调用newFreq=freq.clone然后,我更改newFreq的名称newFreq.name.sub!('f','newF')奇迹般地,它也改变了freq.name!像newFreq.name='newFrequency'这样
map遍历数组是否比each更快?两者有速度差异吗?mapresult=arr.map{|a|a+2}每个result=[]arr.eachdo|a|result.push(a+2)end 最佳答案 我认为是的。我试过这个测试require"benchmark"n=10000arr=Array.new(10000,1)Benchmark.bmdo|x|#Mapx.reportdon.timesdoresult=arr.map{|a|a+2}endend#Eachx.reportdon.timesdoresult=[]arr.each
我想念Ruby中的Hash方法来仅转换/映射散列值。h={1=>[9,2,3,4],2=>[6],3=>[5,7,1]}h.map_values{|v|v.size}#=>{1=>4,2=>1,3=>3}你如何在Ruby中归档它?更新:我正在寻找map_values()的实现。#moreexamplesh.map_values{|v|v.reduce(0,:+)}#=>{1=>18,2=>6,3=>13}h.map_values(&:min)#=>{1=>2,2=>6,3=>1} 最佳答案 Ruby2.4引入了方法Hash#tran