
上篇文章《Android安卓进阶技术分享之AGP工作原理》和大家分析了 AGP(Android Gradle Plugin) 做了哪些事,了解到 AGP 就是为打包这个过程服务的。
那么,本篇文章就和大家聊一聊其中的 Transform,解决一下为什么在 AGP 3.x.x 的版本可以通过反射获取的 transformClassesWithDexBuilderForXXX Task 在 4.0.0 的版本就不灵了?
源码走起!
读本篇文章以前,相信同学们已经具备 Transform 的使用基础。
相信很多人都看过这张图:
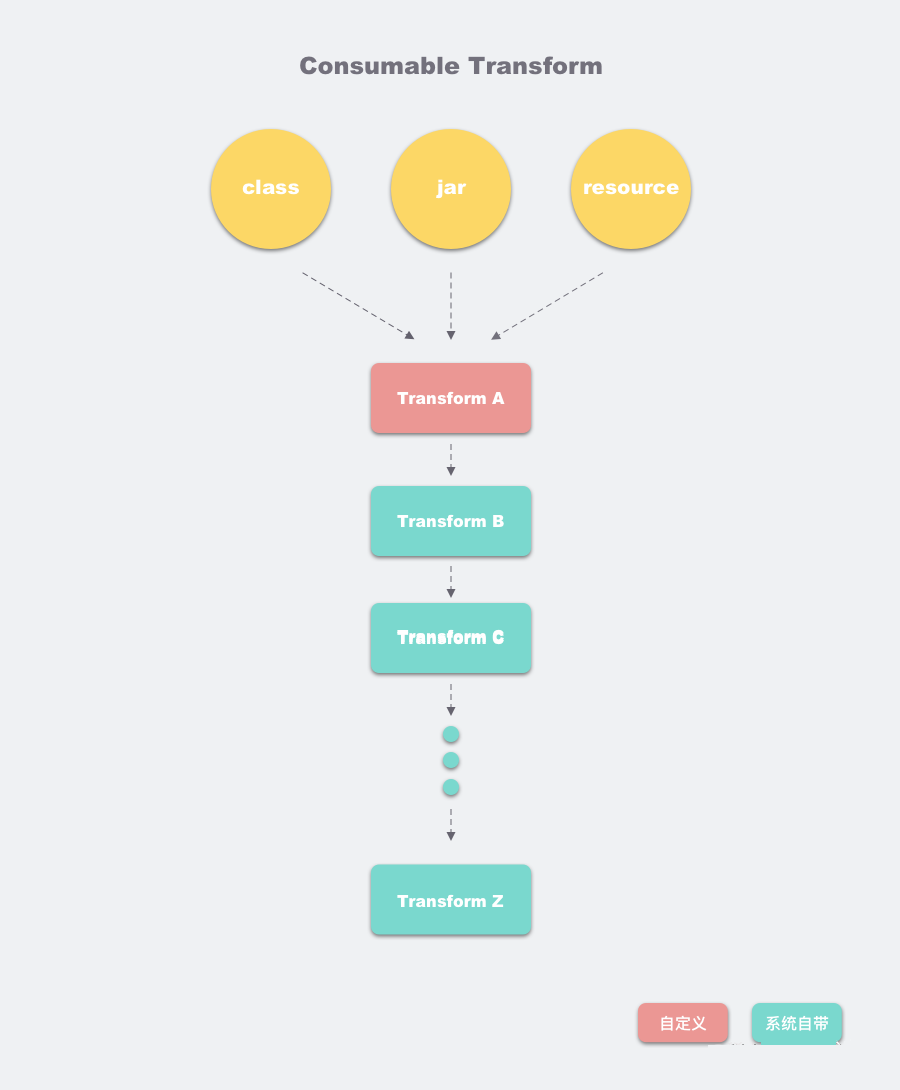
Transform过程
正如上图中展示的,我们可以看到:
• 在一个项目中,我们可能既会有自定义的 Transform,也会有系统的 Transform。
• 在处理过程中,每一个 Transform 的接受流都是接收到上一个 Transform 的输出流,原始的文件流会经过很多 Transform 的处理。
既然我们已经了解了整体的流程,再来看一下其中的细节吧。
我们都知道,使用 Transform 的目的,是为了修改其中的字节码,那么,这些 Class 文件是哪里来的呢?
直接打开 AGP 的源码,直接跳到创建编译 Task 的时候,这个方法发生在 AGP 创建跟 Variant 相关的 Task 的时候,在 AbstractAppTaskManager 里:
private void createCompileTask(@NonNull VariantPropertiesImpl variantProperties) {
ApkCreationConfig apkCreationConfig = (ApkCreationConfig) variantProperties;
// 执行javac
TaskProvider<? extends JavaCompile> javacTask = createJavacTask(variantProperties);
// 添加Class输入流
addJavacClassesStream(variantProperties);
setJavaCompilerTask(javacTask, variantProperties);
// 执行transform和dex相关的任务
createPostCompilationTasks(apkCreationConfig);
}
虽然只有几个方法,但是每个方法的作用还挺大,先看 javac。
大家对 javac 的命令肯定很熟悉,它可以将 .java 文件转化成 .class 文件。这个方法确实也是这样:
public TaskProvider<? extends JavaCompile> createJavacTask(
@NonNull ComponentPropertiesImpl componentProperties) {
// Java预编译任务,看了一下,主要是处理Java注解
taskFactory.register(new JavaPreCompileTask.CreationAction(componentProperties));
// Java编译任务
final TaskProvider<? extends JavaCompile> javacTask =
taskFactory.register(new JavaCompileCreationAction(componentProperties));
postJavacCreation(componentProperties);
return javacTask;
}
它的方法注释:
❝
Creates the task for creating *.class files using javac. These tasks are created regardless of whether Jack is used or not, but assemble will not depend on them if it is. They are always used when running unit tests.
❞
很明显,就是为了创建 .class 文件。
这一步中,最重要的一步就是注册了一个名叫 JavaCompile 的任务,也就是将 Java 文件和 Java 注解转变成 .class 的 Task。
JavaCompile 的 Task 的代码比较绕,直接跟大家说结果了,最终是调用 JDK 下面的 JavaCompiler 类,动态将 .java 转化成 .class 文件。
当然,不仅仅只有 .class 文件,还有其他的诸如 .kt 和 .jar 等,都需要特定的 Task,才能转化成我们需要的输入源。
回到第一步,进入 addJavacClassesStream 方法:
protected void addJavacClassesStream(@NonNull ComponentPropertiesImpl componentProperties) {
// create separate streams for the output of JAVAC and for the pre/post javac
// bytecode hooks
TransformManager transformManager = componentProperties.getTransformManager();
boolean needsJavaResStreams =
componentProperties.getVariantScope().getNeedsJavaResStreams();
transformManager.addStream(
OriginalStream.builder(project, "javac-output")
// Need both classes and resources because some annotation
// processors generate resources
.addContentTypes(
needsJavaResStreams
? TransformManager.CONTENT_JARS
: ImmutableSet.of(DefaultContentType.CLASSES))
.addScope(Scope.PROJECT)
.setFileCollection(project.getLayout().files(javaOutputs))
.build());
BaseVariantData variantData = componentProperties.getVariantData();
transformManager.addStream(
OriginalStream.builder(project, "pre-javac-generated-bytecode")
.addContentTypes(
needsJavaResStreams
? TransformManager.CONTENT_JARS
: ImmutableSet.of(DefaultContentType.CLASSES))
.addScope(Scope.PROJECT)
.setFileCollection(variantData.getAllPreJavacGeneratedBytecode())
.build());
transformManager.addStream(
OriginalStream.builder(project, "post-javac-generated-bytecode")
.addContentTypes(
needsJavaResStreams
? TransformManager.CONTENT_JARS
: ImmutableSet.of(DefaultContentType.CLASSES))
.addScope(Scope.PROJECT)
.setFileCollection(variantData.getAllPostJavacGeneratedBytecode())
.build());
}
这个 transformManager 就是处理 Transform 的,它在建立第一个 Transform 的原始数据流。
细心的同学可能发现了,第一个数据流的 contentType 至少也是 DefaultContentType.CLASSES,scope 是 Scope.PROJECT,自定义过 Transform 的同学肯定知道,这样设置我们自定义的 Transform 能够接收到原始数据流。
回到第一步中的 createPostCompilationTasks 方法,它用来创建编译后的任务:
public void createPostCompilationTasks(@NonNull ApkCreationConfig creationConfig) {
//...
TransformManager transformManager = componentProperties.getTransformManager();
// ...
// java8脱糖
maybeCreateDesugarTask(
componentProperties,
componentProperties.getMinSdkVersion(),
transformManager,
isTestCoverageEnabled);
BaseExtension extension = componentProperties.getGlobalScope().getExtension();
// Merge Java Resources.
createMergeJavaResTask(componentProperties);
// ----- External Transforms -----
// apply all the external transforms.
List<Transform> customTransforms = extension.getTransforms();
List<List<Object>> customTransformsDependencies = extension.getTransformsDependencies();
boolean registeredExternalTransform = false;
for (int i = 0, count = customTransforms.size(); i < count; i++) {
Transform transform = customTransforms.get(i);
List<Object> deps = customTransformsDependencies.get(i);
registeredExternalTransform |=
transformManager
.addTransform(
taskFactory,
componentProperties,
transform,
null,
task -> {
if (!deps.isEmpty()) {
task.dependsOn(deps);
}
},
taskProvider -> {
// if the task is a no-op then we make assemble task depend on it.
if (transform.getScopes().isEmpty()) {
TaskFactoryUtils.dependsOn(
componentProperties
.getTaskContainer()
.getAssembleTask(),
taskProvider);
}
})
.isPresent();
}
// Add a task to create merged runtime classes if this is a dynamic-feature,
// or a base module consuming feature jars. Merged runtime classes are needed if code
// minification is enabled in a project with features or dynamic-features.
if (componentProperties.getVariantType().isDynamicFeature()
|| variantScope.consumesFeatureJars()) {
taskFactory.register(new MergeClassesTask.CreationAction(componentProperties));
}
// ----- Minify next -----
// 混淆
// ----- Multi-Dex支持...
// 创建 dex
createDexTasks(
creationConfig, componentProperties, dexingType, registeredExternalTransform);
// ... 资源压缩等
}
在进行 Transform 之前,它还会进行一些 java8 的脱糖以及合并 java 资源的 Task,这些都是会被添加到原始的数据流中。
首先,我们得明白,每一种 Transform 其实有两种类型:
1. 消费型:需要将数据源输出给下一个 Transform。
2. 引用型:只需要读取,不需要输出。
接下来就到了我们关心的处理 Transform 的逻辑了。
从上面的方法我们可以看出,系统会为我们找到所有已经在BaseExtension 注册的 Transform 并遍历,使用 transformManager 通过 addTransform 做处理:
public <T extends Transform> Optional<TaskProvider<TransformTask>> addTransform(
@NonNull TaskFactory taskFactory,
@NonNull ComponentPropertiesImpl componentProperties,
@NonNull T transform,
@Nullable PreConfigAction preConfigAction,
@Nullable TaskConfigAction<TransformTask> configAction,
@Nullable TaskProviderCallback<TransformTask> providerCallback) {
//... 省略
List<TransformStream> inputStreams = Lists.newArrayList();
String taskName = componentProperties.computeTaskName(getTaskNamePrefix(transform));
// get referenced-only streams
List<TransformStream> referencedStreams = grabReferencedStreams(transform);
// find input streams, and compute output streams for the transform.
IntermediateStream outputStream =
findTransformStreams(
transform,
componentProperties,
inputStreams,
taskName,
componentProperties.getGlobalScope().getBuildDir());
// ... 检测工作
transforms.add(transform);
TaskConfigAction<TransformTask> wrappedConfigAction =
t -> {
t.getEnableGradleWorkers()
.set(
componentProperties
.getGlobalScope()
.getProjectOptions()
.get(BooleanOption.ENABLE_GRADLE_WORKERS));
if (configAction != null) {
configAction.configure(t);
}
};
// create the task...
return Optional.of(
taskFactory.register(
new TransformTask.CreationAction<>(
componentProperties.getName(),
taskName,
transform,
inputStreams,
referencedStreams,
outputStream,
recorder),
preConfigAction,
wrappedConfigAction,
providerCallback));
}
这里呢,先定义了一个 taskName,规则是:
transform${inputType}With${transformName}For${BuildType}
关于 taskName 规则先放这儿,后面我们会用到!
上面代码中的 referencedStreams 用来处理引用型的 Transform,所以我们着重看 outputStream,outputStream 是通过方法 findTransformStreams 方法生成的,关于数据流向的问题这个方法里面讲的特别明白:
private final List<TransformStream> streams = Lists.newArrayList();
private IntermediateStream findTransformStreams(
@NonNull Transform transform,
@NonNull ComponentPropertiesImpl componentProperties,
@NonNull List<TransformStream> inputStreams,
@NonNull String taskName,
@NonNull File buildDir) {
//...
// 消费数据流,inputStreams添加需要消费的数据流
// 1. inputStreams会消费掉streams可以消费的数据流
consumeStreams(requestedScopes, requestedTypes, inputStreams);
Set<ContentType> outputTypes = transform.getOutputTypes();
File outRootFolder =
FileUtils.join(
buildDir,
StringHelper.toStrings(
AndroidProject.FD_INTERMEDIATES,
FD_TRANSFORMS,
transform.getName(),
componentProperties.getVariantDslInfo().getDirectorySegments()));
// 创建输出流
IntermediateStream outputStream =
IntermediateStream.builder(
project,
transform.getName() + "-" + componentProperties.getName(),
taskName)
.addContentTypes(outputTypes)
.addScopes(requestedScopes)
.setRootLocation(outRootFolder)
.build();
// 2. 为下一个Transform添加生成的数据流
streams.add(outputStream);
return outputStream;
}
流程如图:
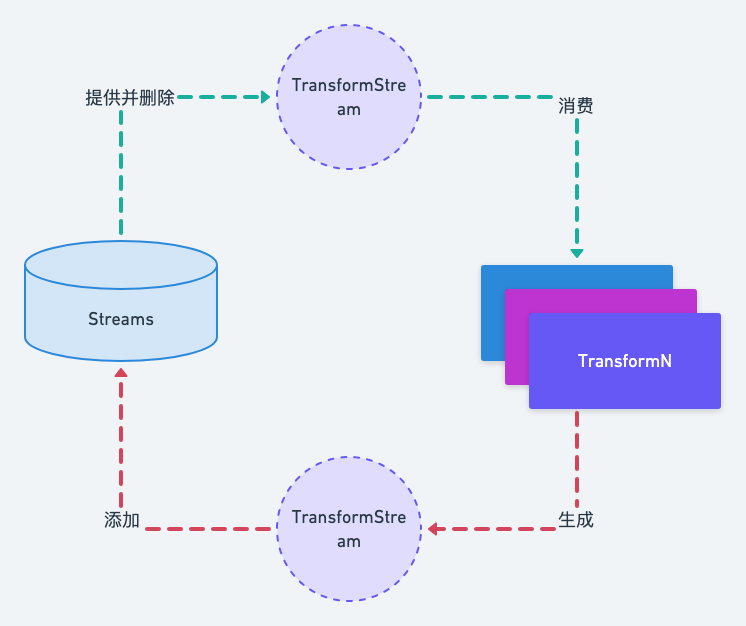
数据消费
意思就是每一个 Transform 都要走一遍图中的流程,对于大部分 Transform 来说,每一个的输入源就是上一个Transform 的输出源。
所以对于开发者来说,如果我们定义 Transform 却不将生成的文件添加到输出目录,这就会导致后面的 Transform 找不到输入源,编译器就只能报错了。
这个错误我最近才犯过。
回到这一步的开始,taskFactory 最终为我们注册了一个 TransformTask。
进入 TransformTask 这个类,里面有一个方法 transform 添加了 @TaskAction 注解,所以,一旦该 Task 执行了,这个方法就会被调用。
@TaskAction
void transform(final IncrementalTaskInputs incrementalTaskInputs)
throws IOException, TransformException, InterruptedException {
// 设置增量编译
isIncremental.setValue(transform.isIncremental() && incrementalTaskInputs.isIncremental());
// ...
recorder.record(
ExecutionType.TASK_TRANSFORM_PREPARATION,
preExecutionInfo,
getProjectPath().get(),
getVariantName(),
new Recorder.Block<Void>() {
@Override
public Void call() throws Exception {
// ... 针对增量编译对文件处理
return null;
}
});
GradleTransformExecution executionInfo =
preExecutionInfo.toBuilder().setIsIncremental(isIncremental.getValue()).build();
recorder.record(
ExecutionType.TASK_TRANSFORM,
executionInfo,
getProjectPath().get(),
getVariantName(),
new Recorder.Block<Void>() {
@Override
public Void call() throws Exception {
// ...
transform.transform(
new TransformInvocationBuilder(context)
.addInputs(consumedInputs.getValue())
.addReferencedInputs(referencedInputs.getValue())
.addSecondaryInputs(changedSecondaryInputs.getValue())
.addOutputProvider(
outputStream != null
? outputStream.asOutput()
: null)
.setIncrementalMode(isIncremental.getValue())
.build());
if (outputStream != null) {
outputStream.save();
}
return null;
}
});
}
recorder 不用管,它只是一个执行器,最终会执行 Block 中的代码。
如果是增量编译的 Task,它会处理文件,告诉我们哪些文件变化了。
之后,就执行 Transform 的 transform 方法,整个 Transform 就结束了。
回到第四步,AGP 会我们先后注册了混淆和多 Dex 支持的 Task,之后就到了创建 Dex 的 Task:
private void createDexTasks(
@NonNull ApkCreationConfig apkCreationConfig,
@NonNull ComponentPropertiesImpl componentProperties,
@NonNull DexingType dexingType,
boolean registeredExternalTransform) {
// ...
taskFactory.register(
new DexArchiveBuilderTask.CreationAction(
dexOptions,
enableDexingArtifactTransform,
componentProperties));
//...
}
DexArchiveBuilderTask 就是名为 dexBuilder 的任务,它的注释:
❝
Task that converts CLASS files to dex archives
❞
它就是创建 dex 文件的 Task。
如果想要对 Dex 有进一步的了解,可以阅读:
❝
《浅谈 Android Dex 文件》
https://tech.youzan.com/qian-tan-android-dexwen-jian/
❞
到了这一步,我们的源码分析就结束了。
之前我一直说 AGP 3.x.x 的时候可以 hook 到 transformClassesWithDexBuilderForXXX 的 task,到了 AGP 4.x.x 就不行了。
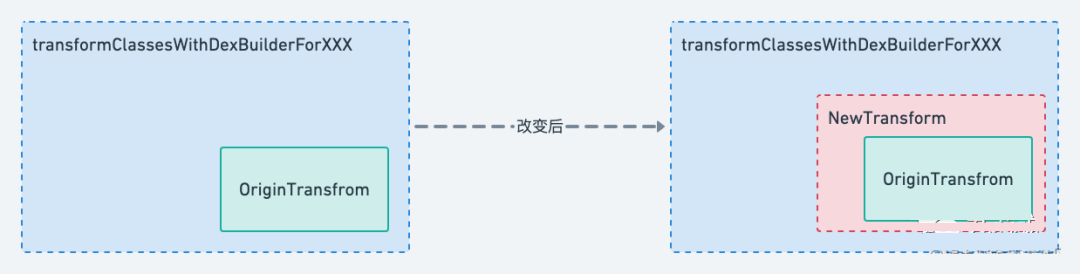
Transform
仔细看一下我上面提到 taskName 命名规则,就会发现,在 3.x.x 之前,transformClassesWithDexBuilderForXXX 其实是一个 Transform,我记得对应的类 DexTransform,它会帮助 AGP 生成 .dex 文件。
而在 4.1.1 的代码中,这个任务交给了 DexArchiveBuilderTask,已经不是一个 Transform 了。
所以啊,经常看到安卓开发者骂骂咧咧的说:卧槽,AGP版本升级了,我的这个方法不能用了!
因此,得出结论,在 AGP 上,最好还是不要去 hook 源码,建议使用官方推荐的接口去处理。
本篇文章的内容其实是对上面 Transform 流程的验证,相信大家已经对 Transform 流程有了整体的把握!
如有什么争议的内容,欢迎评论区留言,如果觉得本文不错,「点赞」是对本文最大的肯定!
文章引用:
❝
《一起玩转Android项目中的字节码》
❞
转自:九心
- EOF -
最后,如果觉得本文不错,「点赞」是对我最好的肯定!
我正在学习如何使用Nokogiri,根据这段代码我遇到了一些问题:require'rubygems'require'mechanize'post_agent=WWW::Mechanize.newpost_page=post_agent.get('http://www.vbulletin.org/forum/showthread.php?t=230708')puts"\nabsolutepathwithtbodygivesnil"putspost_page.parser.xpath('/html/body/div/div/div/div/div/table/tbody/tr/td/div
我有一个Ruby程序,它使用rubyzip压缩XML文件的目录树。gem。我的问题是文件开始变得很重,我想提高压缩级别,因为压缩时间不是问题。我在rubyzipdocumentation中找不到一种为创建的ZIP文件指定压缩级别的方法。有人知道如何更改此设置吗?是否有另一个允许指定压缩级别的Ruby库? 最佳答案 这是我通过查看rubyzip内部创建的代码。level=Zlib::BEST_COMPRESSIONZip::ZipOutputStream.open(zip_file)do|zip|Dir.glob("**/*")d
类classAprivatedeffooputs:fooendpublicdefbarputs:barendprivatedefzimputs:zimendprotecteddefdibputs:dibendendA的实例a=A.new测试a.foorescueputs:faila.barrescueputs:faila.zimrescueputs:faila.dibrescueputs:faila.gazrescueputs:fail测试输出failbarfailfailfail.发送测试[:foo,:bar,:zim,:dib,:gaz].each{|m|a.send(m)resc
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
假设我做了一个模块如下:m=Module.newdoclassCendend三个问题:除了对m的引用之外,还有什么方法可以访问C和m中的其他内容?我可以在创建匿名模块后为其命名吗(就像我输入“module...”一样)?如何在使用完匿名模块后将其删除,使其定义的常量不再存在? 最佳答案 三个答案:是的,使用ObjectSpace.此代码使c引用你的类(class)C不引用m:c=nilObjectSpace.each_object{|obj|c=objif(Class===objandobj.name=~/::C$/)}当然这取决于
我正在尝试使用ruby和Savon来使用网络服务。测试服务为http://www.webservicex.net/WS/WSDetails.aspx?WSID=9&CATID=2require'rubygems'require'savon'client=Savon::Client.new"http://www.webservicex.net/stockquote.asmx?WSDL"client.get_quotedo|soap|soap.body={:symbol=>"AAPL"}end返回SOAP异常。检查soap信封,在我看来soap请求没有正确的命名空间。任何人都可以建议我
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
我在我的项目目录中完成了compasscreate.和compassinitrails。几个问题:我已将我的.sass文件放在public/stylesheets中。这是放置它们的正确位置吗?当我运行compasswatch时,它不会自动编译这些.sass文件。我必须手动指定文件:compasswatchpublic/stylesheets/myfile.sass等。如何让它自动运行?文件ie.css、print.css和screen.css已放在stylesheets/compiled。如何在编译后不让它们重新出现的情况下删除它们?我自己编译的.sass文件编译成compiled/t
我想将html转换为纯文本。不过,我不想只删除标签,我想智能地保留尽可能多的格式。为插入换行符标签,检测段落并格式化它们等。输入非常简单,通常是格式良好的html(不是整个文档,只是一堆内容,通常没有anchor或图像)。我可以将几个正则表达式放在一起,让我达到80%,但我认为可能有一些现有的解决方案更智能。 最佳答案 首先,不要尝试为此使用正则表达式。很有可能你会想出一个脆弱/脆弱的解决方案,它会随着HTML的变化而崩溃,或者很难管理和维护。您可以使用Nokogiri快速解析HTML并提取文本:require'nokogiri'h
我想为Heroku构建一个Rails3应用程序。他们使用Postgres作为他们的数据库,所以我通过MacPorts安装了postgres9.0。现在我需要一个postgresgem并且共识是出于性能原因你想要pggem。但是我对我得到的错误感到非常困惑当我尝试在rvm下通过geminstall安装pg时。我已经非常明确地指定了所有postgres目录的位置可以找到但仍然无法完成安装:$envARCHFLAGS='-archx86_64'geminstallpg--\--with-pg-config=/opt/local/var/db/postgresql90/defaultdb/po