摘要:华为云分布式云原生UCS服务,是面向分布式云场景下的新一代云原生产品,提供UCS (Huawei Cloud)、UCS (Partner Cloud)、UCS (Multi-Cloud)、UCS (On-Premises) 以及UCS (Attached Clusters) 等产品,覆盖公有云、多云、本地数据中心、边缘等分布式云场景。
本文分享自华为云社区《华为云 UCS (On-Premises) 发布!运行在您本地数据中心的CCE集群》,作者:云容器大未来。
华为云分布式云原生UCS服务,是面向分布式云场景下的新一代云原生产品,提供UCS (Huawei Cloud)、UCS (Partner Cloud)、UCS (Multi-Cloud)、UCS (On-Premises) 以及UCS (Attached Clusters) 等产品,覆盖公有云、多云、本地数据中心、边缘等分布式云场景。
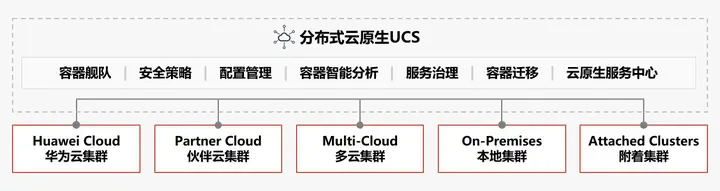
• UCS (Huawei Cloud):由UCS纳管的华为云CCE集群或CCE Turbo集群。
• UCS (Partner Cloud):由UCS纳管的华为伙伴云(如天翼云、移动云等)CCE集群或CCE Turbo集群。
• UCS (Multi-Cloud): 由UCS提供的运行在第三方云服务供应商(如AWS、GCP)基础设施之上的CCE集群。
• UCS (Attached Clusters): 由UCS纳管满足CNCF标准的第三方Kubernetes集群,如AWS EKS、GCP GKE或者自建的Kubernetes集群。
• UCS (On-Premises):由UCS提供的运行在客户本地数据中心基础设施之上的CCE集群。
继UCS (Huawei Cloud) 和UCS (Attached Clusters) 商用上线后,日前UCS (On-Premises) 也正式上线,欢迎申请试用。
Gartner报告预测到2025年超过85%的应用为云原生应用,云原生是企业数字化、智能化的必由之路。同时,据IDC调研指出目前云原生应用中有超过82%的客户使用了多个云服务提供商的产品来部署业务,以容器为代表的云原生技术和业务的跨云跨地域分布式部署已成为业界发展趋势。企业使用公有云服务,期望依托新架构,加快云原生架构升级,从而更快地实现数字化转型进程。然而,由于技术和法规限制等原因,部分工作负载不得不在本地运行。同时,这些企业还希望利用公有云的可伸缩性来处理突发的流量高峰,从而不必提前预测业务高峰和波动,无需购买冗余资源。此外,云上、云下同时部署本身面临着管理挑战,亟需一个统一的平台来管理跨集群应用的分发、实例之间的流量。UCS (On-Premises)正是在这样的企业诉求下推出的产品,提供了云上和云下统一治理的解决方案。
借助UCS (On-Premises),您可以在云上开发和部署应用,同时保持业务在本地运行的完全灵活性,以满足法规或策略要求。
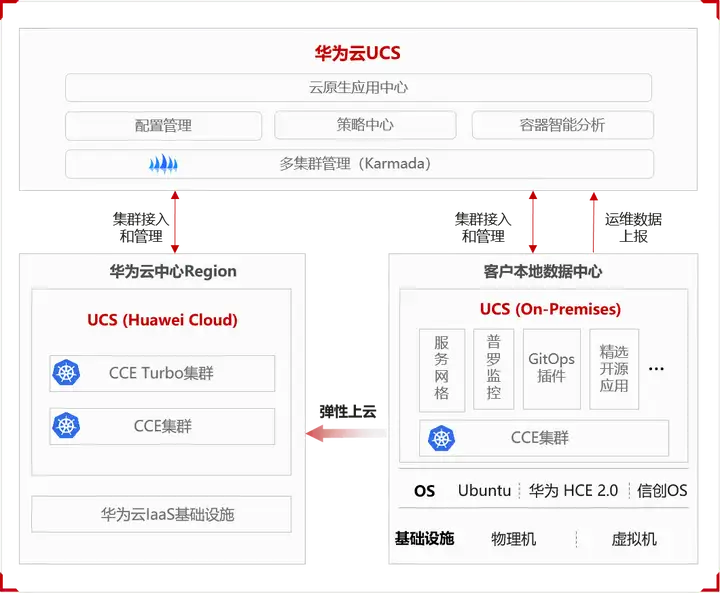
图1 UCS (On-Premises) 架构图
如上图1所示,华为云UCS (On-Premises) 具备以下核心优势:
• 支持异构基础设施,有效利旧
UCS (On-Premises) 支持裸金属服务器、VMWare虚拟化等异构基础设施,可有效利旧已有资源。同时,可支持Ubuntu22.04以及国产信创OS等操作系统。
• 本地数据中心按需弹性上云,有效降本
UCS (On-Premises) 支持按需动态弹性扩缩,业务常态运行时,应用在客户本地机房运行,性能满足常规业务诉求。业务突发峰值时,基于容器舰队(Karmada)跨集群管理能力,可快速将业务弹性扩容到公有云CCE Turbo容器集群,达到成本与性能的平衡。
• 云上&云下一致体验,功能灵活扩展
UCS (On-Premises) 复用公有云租户体系,客户本地无须部署租户管理系统,统一从公有云UCS入口进行操作,包括从云端进行集群管理、负载管理、容器洞察以及服务治理等,提供云上&云下一致性体验。同时,可以将Service Mesh、Prometheus、Gitops等插件从公有云灵活扩展到UCS (On-Premises)。
• 本地部署,安全合规
UCS (On-Premises) 部署在用户本地数据中心,根据用户安全等级要求,支持公网、云专线、VPN等方式接入到云端,并通过堡垒机/防火墙等安全技术,实现云端和本地数据的交互,满足敏感数据本地驻留诉求。
作为华为云UCS产品的一部分,UCS (On-Premises) 扩展了UCS的云上能力,让客户可以在本地环境中运行应用。当前,华为云UCS 已与诸多行业客户联合创新:
• 某汽车企业基于UCS (On-Premises) 实现本地AI计算以及数据仿真,集群利用率提升2倍
自动驾驶AI训练平台对“AI计算”、“灵活弹性扩容”有着强烈的诉求。UCS (On-Premises) 使能AI计算,通过Volcano调度加速完成AI训练、AI推理以及数据仿真,集群利用率提升2倍。同时,UCS (On-Premises) 支持现有IDC扩容使用云上资源,适应业务弹性诉求,轻松应对流量高峰。UCS多集群统一管理使能客户专注业务发展,统一调度能力提升AI训练任务调度效率,支持客户业务快速发展。
• 某电信企业基于UCS (On-Premises) 实现边缘数据中心统一管理,多集群管理效率提升90%
企业为满足对时延敏感的业务场景,通常将业务部署在边缘数据中心,但分散的、大量的多集群管理成为企业快速创新的阻碍,通过UCS (On-Premises) 可以帮助用户实现本地容器集群管理,并在云端实现多集群统一运维,多集群管理效率提升90%。UCS提供的云原生服务是一种更高效的管理方式,加速企业的业务创新。
• 某互联网金融企业基于UCS实现开发、测试和生产环境隔离,研发效能提升30%
企业IT组织经常会在不同的集群上运行开发、测试和生产环境,确保开发人员在开发过程中不会影响生产环境,同时生产环境也不会被开发人员的测试所影响。该企业将UCS (On-Premises) 作为本地开发和测试的运行环境,将UCS (Huawei Cloud) 作为业务的生产运行环境,并通过DevOps流水线来完成开发、测试和生产环境的发布,研发效能提升30%。
目前华为云UCS (On-Premises) 已开放上线,欢迎试用:https://www.huaweicloud.com/product/ucs.html
总的来说,我对ruby还比较陌生,我正在为我正在创建的对象编写一些rspec测试用例。许多测试用例都非常基础,我只是想确保正确填充和返回值。我想知道是否有办法使用循环结构来执行此操作。不必为我要测试的每个方法都设置一个assertEquals。例如:describeitem,"TestingtheItem"doit"willhaveanullvaluetostart"doitem=Item.new#HereIcoulddotheitem.name.shouldbe_nil#thenIcoulddoitem.category.shouldbe_nilendend但我想要一些方法来使用
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
这似乎应该有一个直截了当的答案,但在Google上花了很多时间,所以我找不到它。这可能是缺少正确关键字的情况。在我的RoR应用程序中,我有几个模型共享一种特定类型的字符串属性,该属性具有特殊验证和其他功能。我能想到的最接近的类似示例是表示URL的字符串。这会导致模型中出现大量重复(甚至单元测试中会出现更多重复),但我不确定如何让它更DRY。我能想到几个可能的方向...按照“validates_url_format_of”插件,但这只会让验证干给这个特殊的字符串它自己的模型,但这看起来很像重溶液为这个特殊的字符串创建一个ruby类,但是我如何得到ActiveRecord关联这个类模型
我的目标是转换表单输入,例如“100兆字节”或“1GB”,并将其转换为我可以存储在数据库中的文件大小(以千字节为单位)。目前,我有这个:defquota_convert@regex=/([0-9]+)(.*)s/@sizes=%w{kilobytemegabytegigabyte}m=self.quota.match(@regex)if@sizes.include?m[2]eval("self.quota=#{m[1]}.#{m[2]}")endend这有效,但前提是输入是倍数(“gigabytes”,而不是“gigabyte”)并且由于使用了eval看起来疯狂不安全。所以,功能正常,
作为我的Rails应用程序的一部分,我编写了一个小导入程序,它从我们的LDAP系统中吸取数据并将其塞入一个用户表中。不幸的是,与LDAP相关的代码在遍历我们的32K用户时泄漏了大量内存,我一直无法弄清楚如何解决这个问题。这个问题似乎在某种程度上与LDAP库有关,因为当我删除对LDAP内容的调用时,内存使用情况会很好地稳定下来。此外,不断增加的对象是Net::BER::BerIdentifiedString和Net::BER::BerIdentifiedArray,它们都是LDAP库的一部分。当我运行导入时,内存使用量最终达到超过1GB的峰值。如果问题存在,我需要找到一些方法来更正我的代
在我的Rails(2.3,Ruby1.8.7)应用程序中,我需要将字符串截断到一定长度。该字符串是unicode,在控制台中运行测试时,例如'א'.length,我意识到返回了双倍长度。我想要一个与编码无关的长度,以便对unicode字符串或latin1编码字符串进行相同的截断。我已经了解了Ruby的大部分unicode资料,但仍然有些一头雾水。应该如何解决这个问题? 最佳答案 Rails有一个返回多字节字符的mb_chars方法。试试unicode_string.mb_chars.slice(0,50)
如何正确创建Rails迁移,以便将表更改为MySQL中的MyISAM?目前是InnoDB。运行原始执行语句会更改表,但它不会更新db/schema.rb,因此当在测试环境中重新创建表时,它会返回到InnoDB并且我的全文搜索失败。我如何着手更改/添加迁移,以便将现有表修改为MyISAM并更新schema.rb,以便我的数据库和相应的测试数据库得到相应更新? 最佳答案 我没有找到执行此操作的好方法。您可以像有人建议的那样更改您的schema.rb,然后运行:rakedb:schema:load,但是,这将覆盖您的数据。我的做法是(假设
我正在尝试测试是否存在表单。我是Rails新手。我的new.html.erb_spec.rb文件的内容是:require'spec_helper'describe"messages/new.html.erb"doit"shouldrendertheform"dorender'/messages/new.html.erb'reponse.shouldhave_form_putting_to(@message)with_submit_buttonendendView本身,new.html.erb,有代码:当我运行rspec时,它失败了:1)messages/new.html.erbshou
我在从html页面生成PDF时遇到问题。我正在使用PDFkit。在安装它的过程中,我注意到我需要wkhtmltopdf。所以我也安装了它。我做了PDFkit的文档所说的一切......现在我在尝试加载PDF时遇到了这个错误。这里是错误:commandfailed:"/usr/local/bin/wkhtmltopdf""--margin-right""0.75in""--page-size""Letter""--margin-top""0.75in""--margin-bottom""0.75in""--encoding""UTF-8""--margin-left""0.75in""-
Rails2.3可以选择随时使用RouteSet#add_configuration_file添加更多路由。是否可以在Rails3项目中做同样的事情? 最佳答案 在config/application.rb中:config.paths.config.routes在Rails3.2(也可能是Rails3.1)中,使用:config.paths["config/routes"] 关于ruby-on-rails-Rails3中的多个路由文件,我们在StackOverflow上找到一个类似的问题