决策引擎服务是风控系统的大脑,承载着风控策略编排和计算的任务,对决策的时耗和精度有着严格的要求,本文以决策流执行路径实现方案为切入点,一窥风控决策引擎高效的原理。
在上文 风控决策引擎——决策流构建实战 中详细介绍了风控决策引擎的发展历程,决策流的编排能力,满足了策略运营人员对当前风险场景下的防控策略足够灵活、高效的部署。
“灵活”往往意味着不可控,从多年的开发经验中来看,产品的功能在既定的范围内,基本不会出现不可控的问题(除非是 BUG)。像 SQL 查询语言,对数据分析人员来说非常的灵活,抽象的语法可以满足任何数据组装查询组装需求,但此时危机正在蔓延:随时可能出现一个慢查询导致性能问题!
“灵活”和“高效”往往在程序内是互斥的,足够的灵活,往往是牺牲一定的效率得到的。研发人员能做的,就是在两者中博弈,找到最佳平衡。
如下是策略运营人员配置的较常见的决策流图:

流程图看似简单,但是在实际执行程序执行过程中会遇到各种各样的问题和挑战,根因还是上下游业务对风控决策执行的耗时有严格的控制要求。
此阶段就像一个工作审批流,从开始节点一步一步的往下串行执行,直到终点。决策过程中,完全依赖节点路径的复杂度,假设一个节点的平均耗时为 100ms,那么如下红色执行路径需要耗时 500ms。

500ms 对风控来说是比较奢侈的,整个业务线一次请求耗时可能大半时间都被我们消耗掉了,这显然是不能接受的。可以想象,随着业务场景越来越复杂,策略人员对决策流的编排复杂度越来越高,导致整个决策流的决策路径越来越长,耗时呈线性增长,这种技术实现方案肯定是不能接受的。
总结:
活干不完,咱就堆人。同样的,一个线程干不完的,咱就堆线程并发计算。
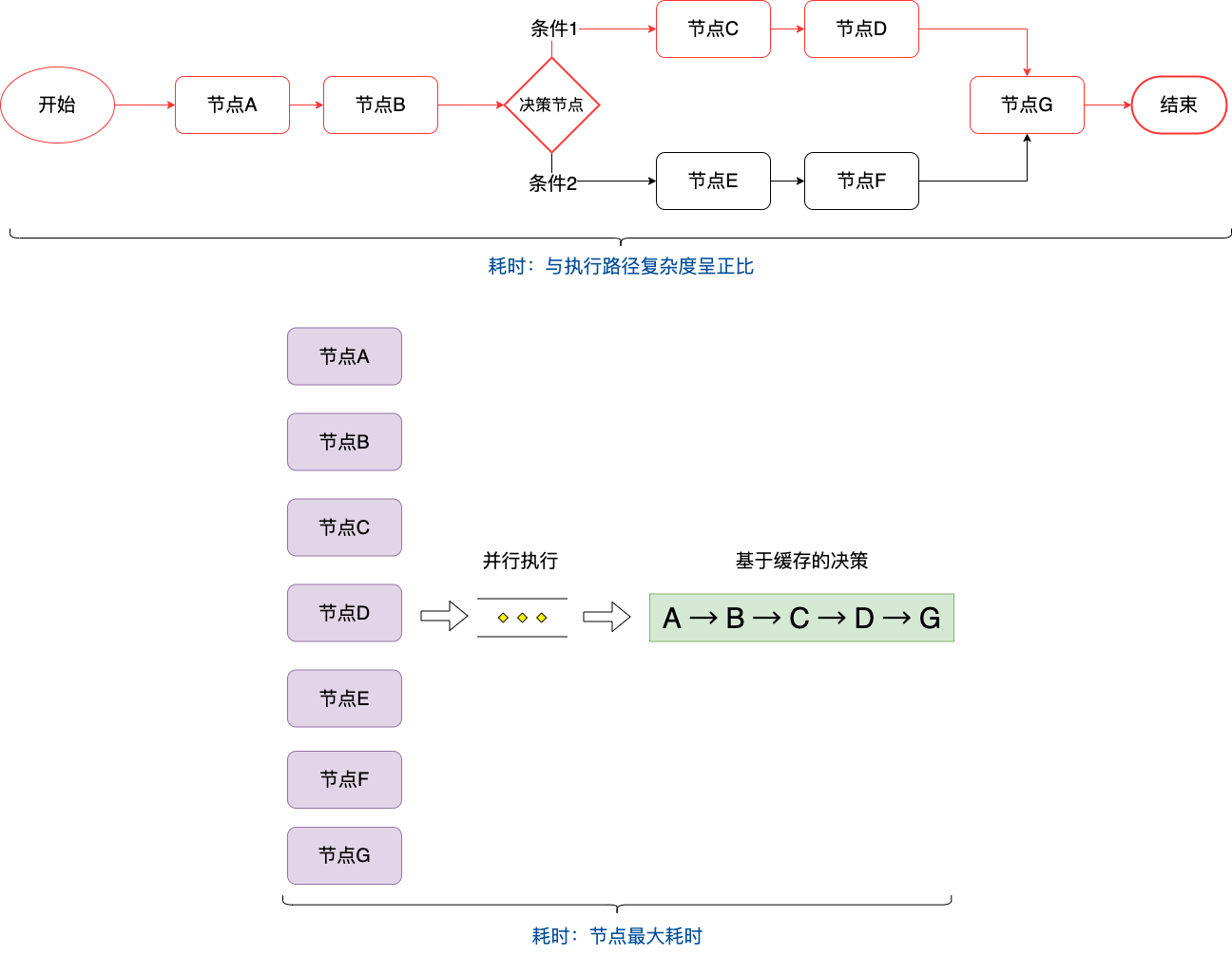
本着空间换时间的思想,预先将决策流内的节点全部预加载完成,将结果缓存住,真正执行决策流的时候,请求缓存直接计算执行,大大节省了决策时间。
此时影响决策性能的卡点在最耗时的那个节点,只需集中人力解决掉这个节点的性能问题就能降低决策流执行时间了。
总结:
方案二除了不考虑成本问题外,最大的痛点在于依赖关系问题,这是致命的。此时需要在运行时动态分析决策流节点之间的依赖关系。
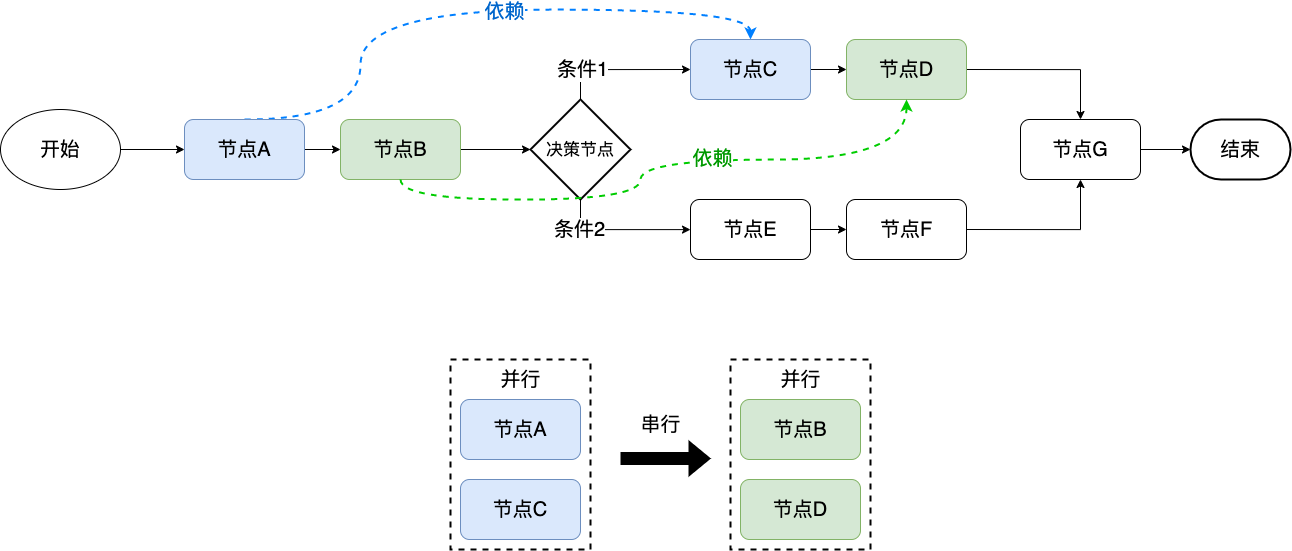
从图中可以看出,节点 C 依赖节点 A,节点 D 依赖节点 B,其它节点相互不依赖,那么此时可以通过依赖分析出节点与节点之间的分组关系,通过分组头结点先后顺序串行执行。
那么如何实现节点的依赖分析及先后执行顺序呢?
流程图本身可以就是一个 DAG(有向无环图),节点执行的先后顺序可以用 BFS(广度优先遍历)遍历出一维数组,然后遍历分析每个节点的入参和之前的节点的出参是否有关联,有关联的归并到之前节点组链表的“尾巴上”,否则即为不依赖,可并行执行。
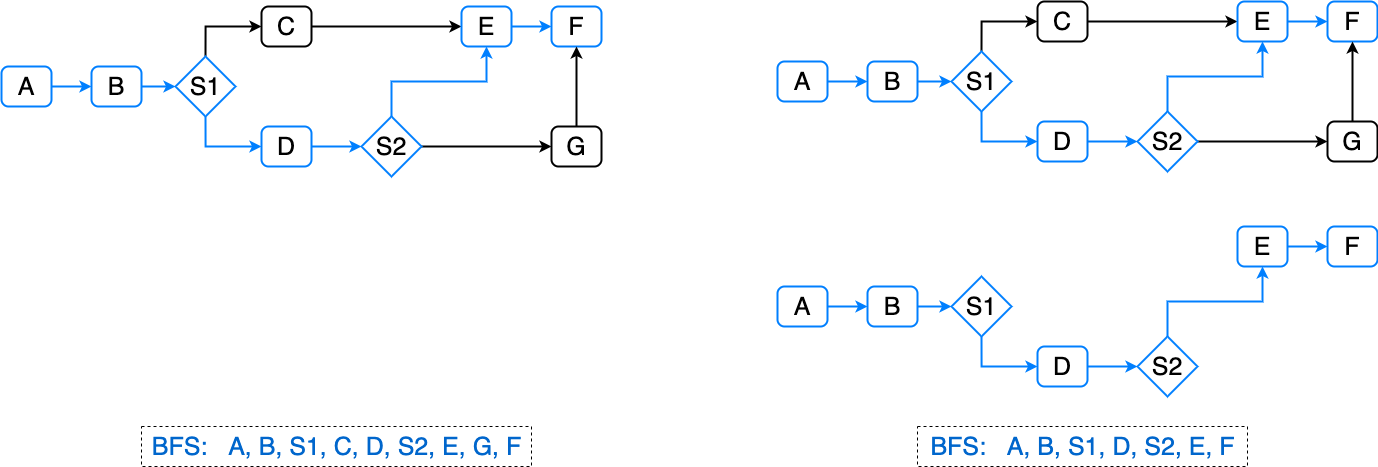
此时整个决策流执行耗时情况如下:
决策流执行耗时 = 并行组1耗时 + 并行组2耗时 + ... + 并行组 N耗时
总结:
方案 2、3 都是全量并行加载各节点数据,对算力和成本的消耗是巨大的,实际在运行的过程中,公司在成本这块肯定是不能接受的,可能资损召回都不定能抵得上服务器和外部资源的开销。
通过分析决策流图,可以发现,分流节点的功能是排它,即决策数据流向只会选择一条路径执行,那么此时我们能在并行执行之前确认哪些路径在当次决策请求中不会经过,则可以排除掉不会经过路径上的节点,从而减少不必要的算力和成本。
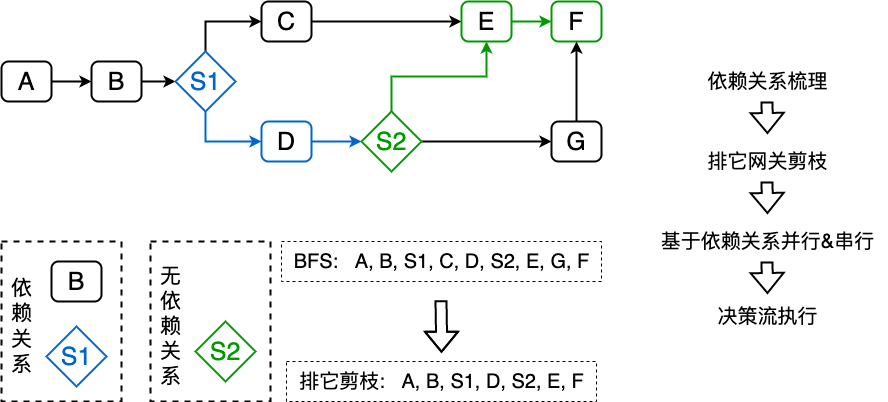
排它网关剪枝如上图,优先找出排它网关节点 S1, S2,分析入参是否依赖上游节点,此时 S1 依赖节点 B,S2 无依赖,则可按照排它节点分组并发执行决策出排它路径,此时 S1 节点对应的节点 C 被“剪枝”,S2 节点对应的节点 G 被“剪枝”。
总结:
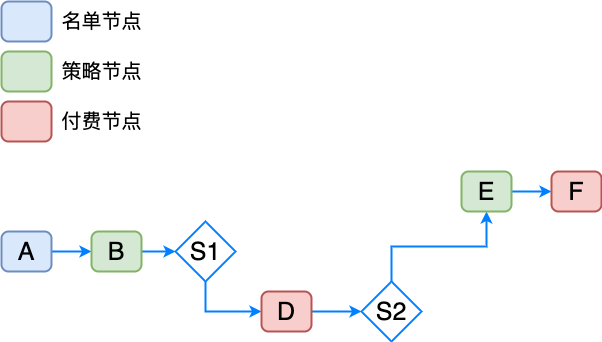
按照方案 4,已经解放了一大部分不会走到分支的算力,但是在正确的决策路径上,依然存在浪费,举例如上:
此时,需要标识出付费节点(或者任何需要控制资源的节点),改为懒加载模式,即在前置并发加载所有节点时剔除懒加载节点,在决策流路径真正执行到该节点时再去计算,确保调用了一定是有效的,此时,构建节点时需要区分设置节点类型是饿汉式 or 懒汉式。
总结:
本文梳理了决策引擎编排决策流过程中为了提高决策性能和节约成本上做出的一些列优化方案,针对不同的场景,可自由选择激进的方案 or 性能和成本兼顾的方案。
研发是站在产品规划的角度去思考实现方案的,脱离规划的设计再好,也不能真正的落地,谨记。
欢迎关注公众号:咕咕鸡技术专栏
个人技术博客:https://jifuwei.github.io/

我想在一个没有Sass引擎的类中使用Sass颜色函数。我已经在项目中使用了sassgem,所以我认为搭载会像以下一样简单:classRectangleincludeSass::Script::FunctionsdefcolorSass::Script::Color.new([0x82,0x39,0x06])enddefrender#hamlengineexecutedwithcontextofself#sothatwithintemlateicouldcall#%stop{offset:'0%',stop:{color:lighten(color)}}endend更新:参见上面的#re
我想为我的Rails网络应用程序提供推荐功能。特别是,我想向新注册的用户推荐他可能想要关注的其他用户。Rails中是否有用于此目的的引擎/gem?如果没有,我应该从哪里开始构建它?谢谢。 最佳答案 有Coletivogemhttps://github.com/diogenes/coletivo我试了一下。在MySQL上运行。Neo4jhttp://neo4j.org真的很容易实现一个“跟随谁”。事实上,大多数展示其能力的样本都涉及“跟随谁”。快速提示-只有在JRuby上运行时,Neo4j.rb才会很酷。如果不是-使用Neograph
无论您是想搭建桌面端、WEB端或者移动端APP应用,HOOPSPlatform组件都可以为您提供弹性的3D集成架构,同时,由工业领域3D技术专家组成的HOOPS技术团队也能为您提供技术支持服务。如果您的客户期望有一种在多个平台(桌面/WEB/APP,而且某些客户端是“瘦”客户端)快速、方便地将数据接入到3D应用系统的解决方案,并且当访问数据时,在各个平台上的性能和用户体验保持一致,HOOPSPlatform将帮助您完成。利用HOOPSPlatform,您可以开发在任何环境下的3D基础应用架构。HOOPSPlatform可以帮您打造3D创新型产品,HOOPSSDK包含的技术有:快速且准确的CAD
导读:随着叮咚买菜业务的发展,不同的业务场景对数据分析提出了不同的需求,他们希望引入一款实时OLAP数据库,构建一个灵活的多维实时查询和分析的平台,统一数据的接入和查询方案,解决各业务线对数据高效实时查询和精细化运营的需求。经过调研选型,最终引入ApacheDoris作为最终的OLAP分析引擎,Doris作为核心的OLAP引擎支持复杂地分析操作、提供多维的数据视图,在叮咚买菜数十个业务场景中广泛应用。作者|叮咚买菜资深数据工程师韩青叮咚买菜创立于2017年5月,是一家专注美好食物的创业公司。叮咚买菜专注吃的事业,为满足更多人“想吃什么”而努力,通过美好食材的供应、美好滋味的开发以及美食品牌的孵
一、引擎主循环UE版本:4.27一、引擎主循环的位置:Launch.cpp:GuardedMain函数二、、GuardedMain函数执行逻辑:1、EnginePreInit:加载大多数模块int32ErrorLevel=EnginePreInit(CmdLine);PreInit模块加载顺序:模块加载过程:(1)注册模块中定义的UObject,同时为每个类构造一个类默认对象(CDO,记录类的默认状态,作为模板用于子类实例创建)(2)调用模块的StartUpModule方法2、FEngineLoop::Init()1、检查Engine的配置文件找出使用了哪一个GameEngine类(UGame
随着ruby被引入为新的编程救世主,我想知道是否有人基于易用性、运行所需的资源、可用性和易定制性而有偏好。两者有更好的吗? 最佳答案 好吧,任何基于Rails的社交网络应用程序的比较都应该包括insoshi(http://portal.insoshi.com/)。话虽这么说,这三个都非常相似,区别在于实现细节。Lovd和Insoshi都是完整的Rails应用程序;它旨在供您将它们用作入门工具包,并使用您自己的自定义功能对其进行扩展。另一方面,CommunityEngine是一个Rails插件。这意味着您可以更轻松地向现有Rail
一般来说,我是Middleman和ruby的新手。我已经安装了Ruby我已经安装了Middleman和gem以使其运行。我需要使用slim而不是默认的模板系统。所以我安装了Slimgem。Slim的网站只说我需要'slim'才能让它工作。中间人网站说我只需要在config.rb文件中添加模板引擎,但是没有给出例子...对于没有ruby背景的人来说,这没有帮助。我在git上找了几个config.rb,它们都有:require'slim'和#Setslim-langoutputstyleSlim::Engine.set_default_options:pretty=>true#Se
关闭。这个问题不符合StackOverflowguidelines.它目前不接受答案。要求我们推荐或查找工具、库或最喜欢的场外资源的问题对于StackOverflow来说是偏离主题的,因为它们往往会吸引自以为是的答案和垃圾邮件。相反,describetheproblem以及迄今为止为解决该问题所做的工作。关闭9年前。Improvethisquestion是否有适用于这些的3d游戏引擎?
我有一个Rails3引擎。在初始化程序中,它需要来自某个文件夹的一堆文件。在这个文件中,我引擎的用户定义了代码、业务逻辑、配置引擎等。所有这些数据都静态存储在我的引擎主模块中(在应用程序属性中)moduleMyEngineclass我希望在开发模式下根据每个请求重新加载这些文件。(这样用户就不必重新加载服务器来查看他刚刚所做的更改)当然我可以做这样的事情而不是初始化config.to_preparedoMyEngine.application.clear!load('some/file')end但是这样我会遇到问题(因为这个文件中定义的常量不会真正被重新加载)。理想的解决方案是让我的整
许多正则表达式引擎在单行字符串中匹配.*两次,例如,在执行基于正则表达式的字符串替换时:根据定义,第一个匹配项是整个(单行)字符串,正如预期的那样。在许多引擎中有第二个匹配项,即空字符串;也就是说,即使第一个匹配项消耗了整个输入字符串,.*仍会再次匹配,然后匹配输入字符串末尾的空字符串。注意:要确保只找到一个匹配项,请使用^.*我的问题是:这种行为有充分的理由吗?一旦输入字符串被完全使用,我不希望再次尝试找到匹配项。除了反复试验之外,您能否从支持的文档/正则表达式方言/标准中收集到哪些引擎表现出这种行为?更新:revo'shelpfulanswer解释当前行为的方式;至于潜在的原因,请