 对于很多的开发小伙伴来说,在MySQL中进行in子查询是一个非常常见的操作。虽然也有很多人说,尽量少用in子查询,in的数量过多会影响查询性能。但其实MySQL做了不少的优化手段来保证in子查询的性能,大家也能在实际的业务中感受到in子查询的速度也没那么慢。那今天就带大家了解一下,MySQL到底是怎么来优化in子查询的。
对于很多的开发小伙伴来说,在MySQL中进行in子查询是一个非常常见的操作。虽然也有很多人说,尽量少用in子查询,in的数量过多会影响查询性能。但其实MySQL做了不少的优化手段来保证in子查询的性能,大家也能在实际的业务中感受到in子查询的速度也没那么慢。那今天就带大家了解一下,MySQL到底是怎么来优化in子查询的。select * from table1 where key1 in ('bb','ff','gg');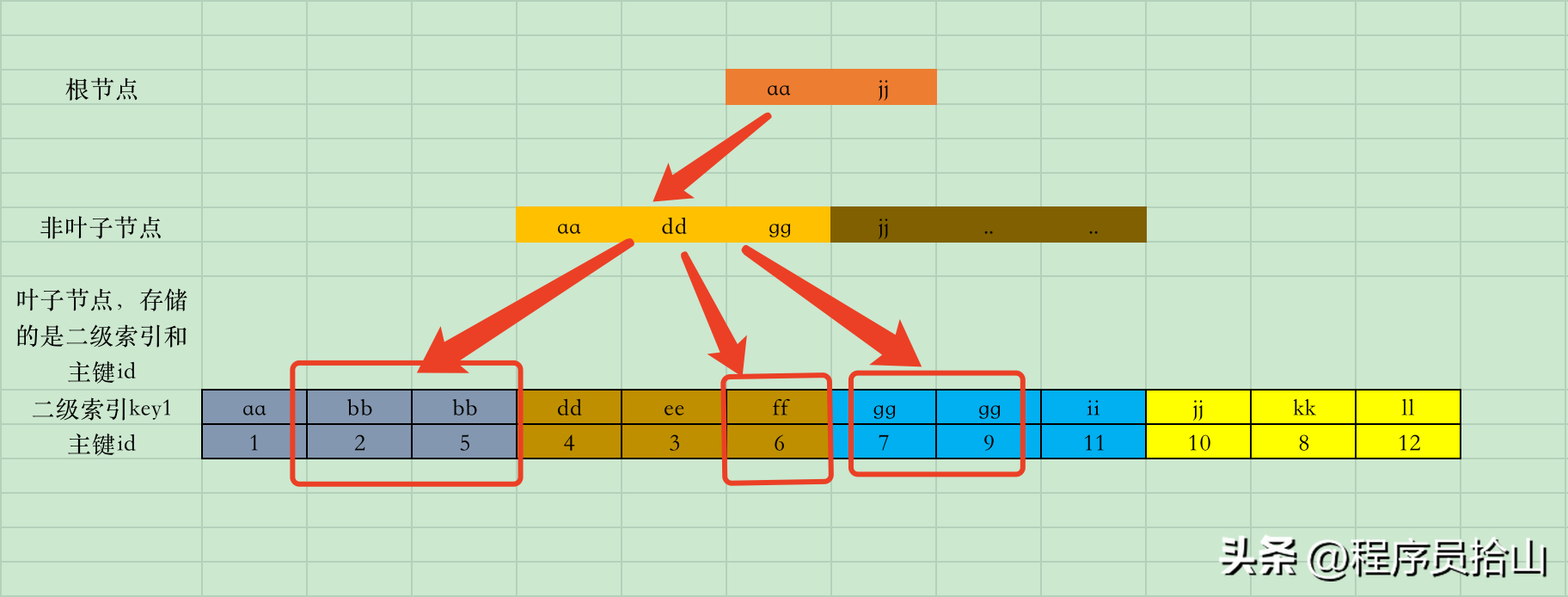 在这个图里,最上层的是根节点,中间的是非叶子节点,最下面的是叶子节点。对于一个普通的二级索引来说,叶子节点存储的是索引key和主键id,这些基础知识就不详细展开说了。需要注意的是,二级索引在叶子节点中是按照key的顺序从小到大排序的,但是对应的主键id可不一定。可能与大家想象的不同,MySQL在执行in子查询时,会把in语句中的条件当做一个个的区间,比如:['bb','bb'],['ff','ff'],['gg','gg']然后MySQL在二级索引树上,会先查询['bb','bb']这个区间,比如首先查询到第一个数据页中符合条件的第一条数据(bb,2),获取到主键id=2之后,去聚簇索引回表查询所需的数据(因为我们使用的select *,需要获取到所有的列值)。然后查询第一个数据页中符合条件的第二条数据(bb,5),获取到主键id=5之后,去聚簇索引回表查询所需的数据,然后查询第二个数据页中符合条件的第三条数据(ff,6),不断的重复上面的动作。。。。最后获取到一个结果集,返回到Server,再由Server返回到客户端。看到这里大家是否可以感觉到,这样查询数据也太麻烦了,特别是当in子查询的条件越来越多时,如何保证性能呢?下面,我们一起来看一下,MySQL是如何优化in子查询的。
在这个图里,最上层的是根节点,中间的是非叶子节点,最下面的是叶子节点。对于一个普通的二级索引来说,叶子节点存储的是索引key和主键id,这些基础知识就不详细展开说了。需要注意的是,二级索引在叶子节点中是按照key的顺序从小到大排序的,但是对应的主键id可不一定。可能与大家想象的不同,MySQL在执行in子查询时,会把in语句中的条件当做一个个的区间,比如:['bb','bb'],['ff','ff'],['gg','gg']然后MySQL在二级索引树上,会先查询['bb','bb']这个区间,比如首先查询到第一个数据页中符合条件的第一条数据(bb,2),获取到主键id=2之后,去聚簇索引回表查询所需的数据(因为我们使用的select *,需要获取到所有的列值)。然后查询第一个数据页中符合条件的第二条数据(bb,5),获取到主键id=5之后,去聚簇索引回表查询所需的数据,然后查询第二个数据页中符合条件的第三条数据(ff,6),不断的重复上面的动作。。。。最后获取到一个结果集,返回到Server,再由Server返回到客户端。看到这里大家是否可以感觉到,这样查询数据也太麻烦了,特别是当in子查询的条件越来越多时,如何保证性能呢?下面,我们一起来看一下,MySQL是如何优化in子查询的。CREATE TABLE table1 (
`id` int(11) NOT NULL AUTO_INCREMENT,
`c1` int(11) NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE,
INDEX `idx_c1`(`c1`) USING BTREE
) ENGINE = InnoDB
CREATE TABLE table2 (
`id` int(11) NOT NULL AUTO_INCREMENT,
`c2` int(11) NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE,
INDEX `idx_c2`(`c2`) USING BTREE
) ENGINE = InnoDBSELECT
*
FROM
table1 t1
WHERE
t1.c1 IN ( SELECT id FROM table2 t2 WHERE t2.c2 = 3 );SELECT
`t1`.`id` AS `id`,
`t1`.`c1` AS `c1`
FROM
`table2` `t2`
JOIN `table1` `t1`
WHERE
( ( `t1`.`c1` = `t2`.`id` ) AND ( `t2`.`c2` = 3 ) )我正在学习如何使用Nokogiri,根据这段代码我遇到了一些问题:require'rubygems'require'mechanize'post_agent=WWW::Mechanize.newpost_page=post_agent.get('http://www.vbulletin.org/forum/showthread.php?t=230708')puts"\nabsolutepathwithtbodygivesnil"putspost_page.parser.xpath('/html/body/div/div/div/div/div/table/tbody/tr/td/div
总的来说,我对ruby还比较陌生,我正在为我正在创建的对象编写一些rspec测试用例。许多测试用例都非常基础,我只是想确保正确填充和返回值。我想知道是否有办法使用循环结构来执行此操作。不必为我要测试的每个方法都设置一个assertEquals。例如:describeitem,"TestingtheItem"doit"willhaveanullvaluetostart"doitem=Item.new#HereIcoulddotheitem.name.shouldbe_nil#thenIcoulddoitem.category.shouldbe_nilendend但我想要一些方法来使用
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
我正在尝试测试是否存在表单。我是Rails新手。我的new.html.erb_spec.rb文件的内容是:require'spec_helper'describe"messages/new.html.erb"doit"shouldrendertheform"dorender'/messages/new.html.erb'reponse.shouldhave_form_putting_to(@message)with_submit_buttonendendView本身,new.html.erb,有代码:当我运行rspec时,它失败了:1)messages/new.html.erbshou
给定这段代码defcreate@upgrades=User.update_all(["role=?","upgraded"],:id=>params[:upgrade])redirect_toadmin_upgrades_path,:notice=>"Successfullyupgradeduser."end我如何在该操作中实际验证它们是否已保存或未重定向到适当的页面和消息? 最佳答案 在Rails3中,update_all不返回任何有意义的信息,除了已更新的记录数(这可能取决于您的DBMS是否返回该信息)。http://ar.ru
我在我的项目目录中完成了compasscreate.和compassinitrails。几个问题:我已将我的.sass文件放在public/stylesheets中。这是放置它们的正确位置吗?当我运行compasswatch时,它不会自动编译这些.sass文件。我必须手动指定文件:compasswatchpublic/stylesheets/myfile.sass等。如何让它自动运行?文件ie.css、print.css和screen.css已放在stylesheets/compiled。如何在编译后不让它们重新出现的情况下删除它们?我自己编译的.sass文件编译成compiled/t
我正在用Ruby编写一个简单的程序来检查域列表是否被占用。基本上它循环遍历列表,并使用以下函数进行检查。require'rubygems'require'whois'defcheck_domain(domain)c=Whois::Client.newc.query("google.com").available?end程序不断出错(即使我在google.com中进行硬编码),并打印以下消息。鉴于该程序非常简单,我已经没有什么想法了-有什么建议吗?/Library/Ruby/Gems/1.8/gems/whois-2.0.2/lib/whois/server/adapters/base.
我正在寻找执行以下操作的正确语法(在Perl、Shell或Ruby中):#variabletoaccessthedatalinesappendedasafileEND_OF_SCRIPT_MARKERrawdatastartshereanditcontinues. 最佳答案 Perl用__DATA__做这个:#!/usr/bin/perlusestrict;usewarnings;while(){print;}__DATA__Texttoprintgoeshere 关于ruby-如何将脚
Rackup通过Rack的默认处理程序成功运行任何Rack应用程序。例如:classRackAppdefcall(environment)['200',{'Content-Type'=>'text/html'},["Helloworld"]]endendrunRackApp.new但是当最后一行更改为使用Rack的内置CGI处理程序时,rackup给出“NoMethodErrorat/undefinedmethod`call'fornil:NilClass”:Rack::Handler::CGI.runRackApp.newRack的其他内置处理程序也提出了同样的反对意见。例如Rack
在rails源中:https://github.com/rails/rails/blob/master/activesupport/lib/active_support/lazy_load_hooks.rb可以看到以下内容@load_hooks=Hash.new{|h,k|h[k]=[]}在IRB中,它只是初始化一个空哈希。和做有什么区别@load_hooks=Hash.new 最佳答案 查看rubydocumentationforHashnew→new_hashclicktotogglesourcenew(obj)→new_has