
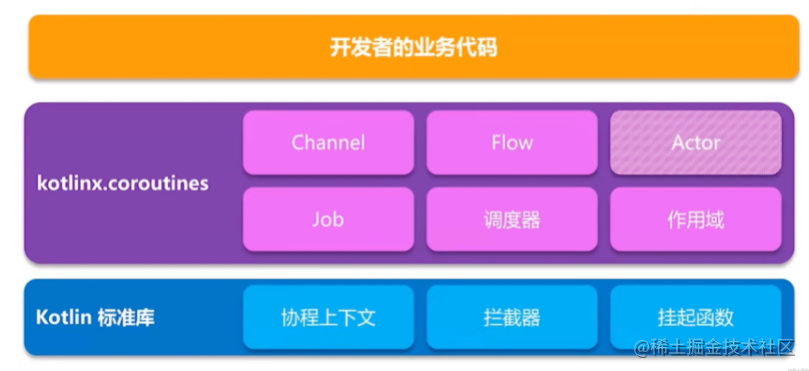
协程是一个并发方案。也是一种思想。
传统意义上的协程是单线程的,面对io密集型任务他的内存消耗更少,进而效率高。但是面对计算密集型的任务不如多线程并行运算效率高。
不同的语言对于协程都有不同的实现,甚至同一种语言对于不同平台的操作系统都有对应的实现。
我们kotlin语言的协程是 coroutines for jvm的实现方式。底层原理也是利用java 线程。
dependencies {
// Kotlin
implementation "org.jetbrains.kotlin:kotlin-stdlib:1.4.32"
// 协程核心库
implementation "org.jetbrains.kotlinx:kotlinx-coroutines-core:1.4.3"
// 协程Android支持库
implementation "org.jetbrains.kotlinx:kotlinx-coroutines-android:1.4.3"
// 协程Java8支持库
implementation "org.jetbrains.kotlinx:kotlinx-coroutines-jdk8:1.4.3"
// lifecycle对于协程的扩展封装
implementation "androidx.lifecycle:lifecycle-viewmodel-ktx:2.2.0"
implementation "androidx.lifecycle:lifecycle-runtime-ktx:2.2.0"
implementation "androidx.lifecycle:lifecycle-livedata-ktx:2.2.0"
}
1.网络上没有详细的关于协程的概念定义,每种语言、每个系统对其实现都不一样。可谓是众说纷纭,什么内核态用户态巴拉巴拉,很容易给我们带偏
2.kotlin的各种语法糖对我们造成的干扰。如:
所以扎实的kotlin语法基本功是学习协程的前提。
实在看不懂得地方就反编译为java,以java最终翻译为准。
kotlin中的协程干的事就是把异步回调代码拍扁了,捋直了,让异步回调代码同步化。除此之外,没有任何特别之处。
创建一个协程,就是编译器背后偷偷生成一系列代码,比如说状态机。
通过挂起和恢复让状态机状态流转实现把层层嵌套的回调代码变成像同步代码那样直观、简洁。
它不是什么线程框架,也不是什么高深的内核态,用户态。它其实对于咱们安卓来说,就是一个关于回调函数的语法糖。。。
本文将会围绕挂起与恢复彻底剖析协程的实现原理
再Kotlin中函数是一等公民,有自己的类型
fun foo(){}
//类型为 () -> Unit
fun foo(p: Int){}
//类型为 (Int) -> String
class Foo{
fun bar(p0: String,p1: Long):Any{}
}
//那么 bar 的类型为:Foo.(String,Long) -> Any
//Foo就是bar的 receiver。也可以写成 (Foo,String,Long) ->Any
fun foo(){}
//引用是 ::foo
fun foo(p0: Int): String
//引用也是 ::foo
咋都一样?没办法,就这样规定的。使用的时候 只能靠编译器推断
val f: () -> Unit = ::foo //编译器会推断出是fun foo(){}
val g: (Int) -> String = ::foo //推断为fun foo(p0: Int): String
带Receiver的写法
class Foo{
fun bar(p0: String,p1: Long):Any{}
}
val h: (Foo,String,Long) -> Any = Foo:bar
绑定receiver的函数引用:
val foo: Foo = Foo()
val m: (String,Long) -> Any = foo:bar
额外知识点
val x: (Foo,String,Long) -> Any = Foo:bar
val y: Function3<Foo,String,Long,Any> = x
Foo.(String,Long) -> Any = (Foo,String,Long) ->Any = Function3<Foo,String,Long,Any>
fun yy(p: (Foo,String,Long)->Any){
p(Foo(),"Hello",3L)//直接p()就能调用
//p.invoke(Foo(),"Hello",3L) 也可以用invoke形式
}
就是匿名函数,它跟普通函数比是没有名字的,听起来好像是废话
//普通函数
fun func(){
println("hello");
}
//去掉函数名 func,就成了匿名函数
fun(){
println("hello");
}
//可以赋值给一个变量
val func = fun(){
println("hello");
}
//匿名函数的类型
val func :()->Unit = fun(){
println("hello");
}
//Lambda表达式
val func={
print("Hello");
}
//Lambda类型
val func :()->String = {
print("Hello");
"Hello" //如果是Lambda中,最后一行被当作返回值,能省掉return。普通函数则不行
}
//带参数Lambda
val f1: (Int)->Unit = {p:Int ->
print(p);
}
//可进一步简化为
val f1 = {p:Int ->
print(p);
}
//当只有一个参数的时候,还可以写成
val f1: (Int)->Unit = {
print(it);
}
函数跟匿名函数看起来没啥区别,但是反编译为java后还是能看出点差异
如果只是用普通的函数,那么他跟普通java 函数没啥区别。
比如 fun a() 就是对应java方法public void a(){}
但是如果通过函数引用(:: a)来用这个函数,那么他并不是直接调用fun a()而是重新生成一个Function0
suspend 修饰。
挂起函数中能调用任何函数。
非挂起函数只能调用非挂起函数。
换句话说,suspend函数只能在suspend函数中调用。
简单的挂起函数展示:
//com.example.studycoroutine.chapter.CoroutineRun.kt
suspend fun suspendFun(): Int {
return 1;
}
public static final Object suspendFun(Continuation completion) {
return Boxing.boxInt(1);
}
这下理解suspend为啥只能在suspend里面调用了吧?
想要让道貌岸然的suspend函数干活必须要先满足它!!!就是给它里面塞入一颗球。
然后他想调用其他的suspend函数,只需将球继续塞到其它的suspend方法里面。
普通函数里没这玩意啊,所以压根没法调用suspend函数。。。
question1.这不是鸡生蛋生鸡的问题么?第一颗球是哪来的?
question2.为啥编译后返回值也变了?
question3.suspendFun 如果在协程体内被调用,那么他的球(completion)是谁?
public fun <T> (suspend () -> T).startCoroutine(completion: Continuation<T>) {
createCoroutineUnintercepted(completion).intercepted().resume(Unit)
}
public fun <T> (suspend () -> T).createCoroutine(completion: Continuation<T>): Continuation<Unit> =
SafeContinuation(createCoroutineUnintercepted(completion).intercepted(), COROUTINE_SUSPENDED)
以一个最简单的方式启动一个协程。
fun main() {
val b = suspend {
val a = hello2()
a
}
b.createCoroutine(MyCompletionContinuation()).resume(Unit)
}
suspend fun hello2() = suspendCoroutine<Int> {
thread{
Thread.sleep(1000)
it.resume(10086)
}
}
class MyContinuation() : Continuation<Int> {
override val context: CoroutineContext = CoroutineName("Co-01")
override fun resumeWith(result: Result<Int>) {
log("MyContinuation resumeWith 结果 = ${result.getOrNull()}")
}
}
startCoroutine 没有返回值 ,而createCoroutine返回一个Continuation,不难看出是SafeContinuation
好像看起来主要的区别就是startCoroutine直接调用resume(Unit),所以不用包装成SafeContinuation,而createCoroutine则返回一个SafeContinuation,因为不知道将会在何时何处调用resume,必须保证resume只调用一次,所以包装为safeContinuation
SafeContinuationd的作用是为了确保只有发生异步调用时才挂起
//kotlin.coroutines.intrinsics.CoroutinesIntrinsicsH.kt
@SinceKotlin("1.3")
public expect fun <T> (suspend () -> T).createCoroutineUnintercepted(completion: Continuation<T>): Continuation<Unit>
其实可以简单的理解为kotlin层面的原语,就是返回一个协程体。
引用代码Demo-K1首先b 是一个匿名函数,他肯定要被编译为一个FunctionX,同时它还被suspend修饰 所以它肯定跟普通匿名函数编译后不一样。
编译后的源码为
public static final void main() {
Function1 var0 = (Function1)(new Function1((Continuation)null) {
int label;
@Nullable
public final Object invokeSuspend(@NotNull Object $result) {
Object var3 = IntrinsicsKt.getCOROUTINE_SUSPENDED();
Object var10000;
switch(this.label) {
case 0:
ResultKt.throwOnFailure($result);
this.label = 1;
var10000 = TestSampleKt.hello2(this);
if (var10000 == var3) {
return var3;
}
break;
case 1:
ResultKt.throwOnFailure($result);
var10000 = $result;
break;
default:
throw new IllegalStateException("call to 'resume' before 'invoke' with coroutine");
}
int a = ((Number)var10000).intValue();
return Boxing.boxInt(a);
}
@NotNull
public final Continuation create(@NotNull Continuation completion) {
Intrinsics.checkParameterIsNotNull(completion, "completion");
Function1 var2 = new <anonymous constructor>(completion);
return var2;
}
public final Object invoke(Object var1) {
return((<undefinedtype>)this.create((Continuation)var1)).invokeSuspend(Unit.INSTANCE);
}
});
boolean var1 = false;
Continuation var7 = ContinuationKt.createCoroutine(var0, (Continuation)(newMyContinuation()));
Unit var8 = Unit.INSTANCE;
boolean var2 = false;
Companion var3 = Result.Companion;
boolean var5 = false;
Object var6 = Result.constructor-impl(var8);
var7.resumeWith(var6);
}
我们可以看到先是 Function1 var0 = new Function1创建了一个对象,此时跟协程没关系,这步只是编译器层面的匿名函数语法优化
如果直接
fun main() {
suspend {
val a = hello2()
a
}.createCoroutine(MyContinuation()).resume(Unit)
}
也是一样会创建Function1 var0 = new Function1
继续调用createCoroutine
再继续createCoroutineUnintercepted ,找到在JVM平台的实现
//kotlin.coroutines.intrinsics.IntrinsicsJVM.class
@SinceKotlin("1.3")
public actual fun <T> (suspend () -> T).createCoroutineUnintercepted(
completion: Continuation<T>
): Continuation<Unit> {
//probeCompletion还是我们传入completion对象,在我们的Demo就是myCoroutine
val probeCompletion = probeCoroutineCreated(completion)//probeCoroutineCreated方法点进去看了,好像是debug用的.我的理解是这样的
//This就是这个suspend lambda。在Demo中就是myCoroutineFun
return if (this is BaseContinuationImpl)
create(probeCompletion)
else
//else分支在我们demo中不会走到
//当 [createCoroutineUnintercepted] 遇到不继承 BaseContinuationImpl 的挂起 lambda 时,将使用此函数。
createCoroutineFromSuspendFunction(probeCompletion) {
(this as Function1<Continuation<T>, Any?>).invoke(it)
}
}
@NotNull
public final Continuation create(@NotNull Continuation completion) {
Intrinsics.checkNotNullParameter(completion, "completion");
Function1 var2 = new <anonymous constructor>(completion);
return var2;
}
把completion传入,并创建一个新的Function1,作为Continuation返回,这就是创建出来的协程体对象,协程的工作核心就是它内部的状态机,invokeSuspend函数
调用 create
@NotNull
public final Continuation create(@NotNull Continuation completion) {
Intrinsics.checkNotNullParameter(completion, "completion");
Function1 var2 = new <anonymous constructor>(completion);
return var2;
}
把completion传入,并创建一个新的Function1,作为Continuation返回,这就是创建出来的协程体对象,协程的工作核心就是它内部的状态机,invokeSuspend函数
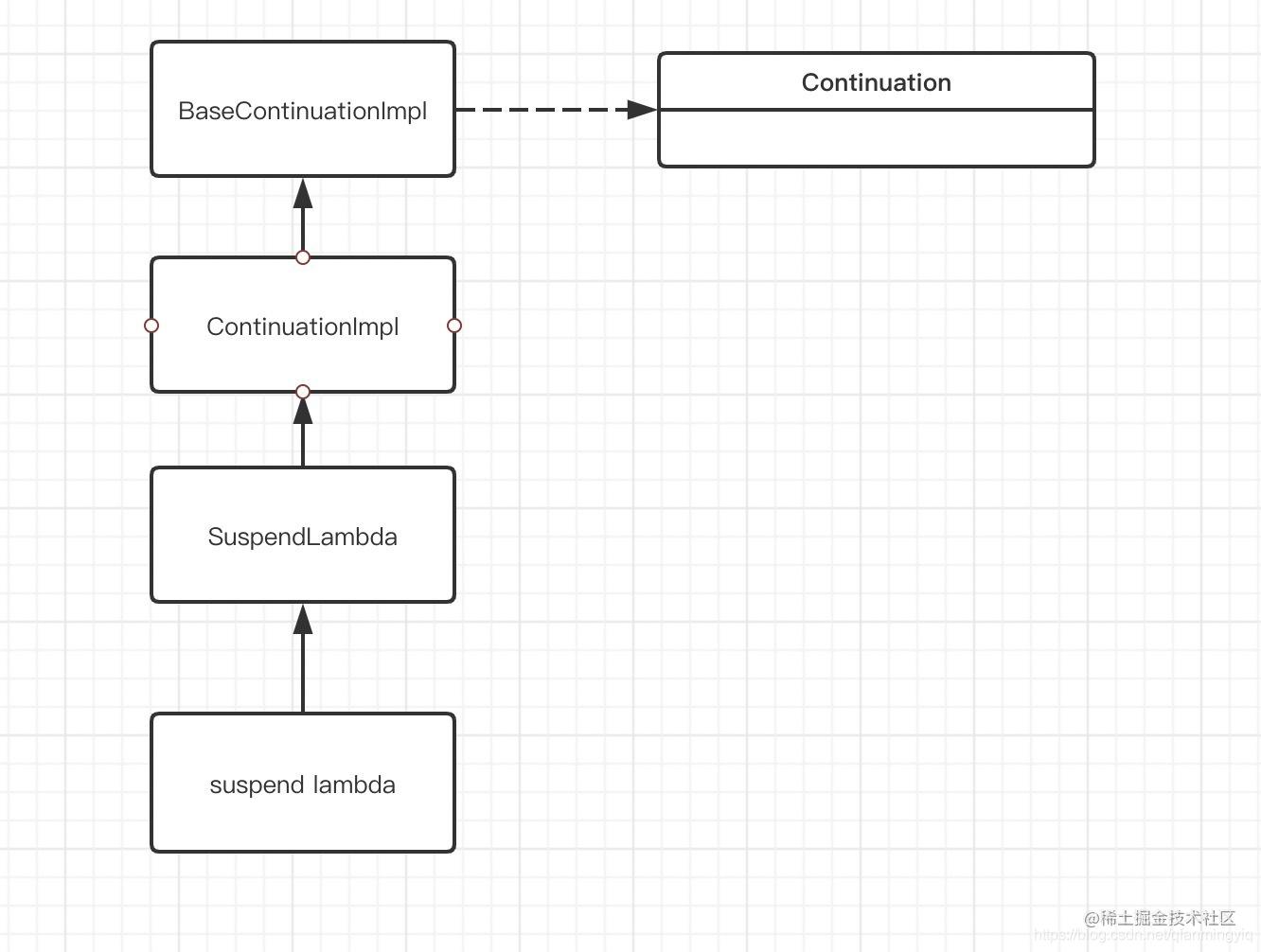
已知协程启动会调用协程体的resume,该调用最终会来到BaseContinuationImpl::resumeWith
internal abstract class BaseContinuationImpl{
fun resumeWith(result: Result<Any?>) {
// This loop unrolls recursion in current.resumeWith(param) to make saner and shorter stack traces on resume
var current = this
var param = result
while (true) {
with(current) {
val completion = completion!! // fail fast when trying to resume continuation without completion
val outcome: Result<Any?> =
try {
val outcome = invokeSuspend(param)//调用状态机
if (outcome === COROUTINE_SUSPENDED) return
Result.success(outcome)
} catch (exception: Throwable) {
Result.failure(exception)
}
releaseIntercepted() // this state machine instance is terminating
if (completion is BaseContinuationImpl) {
// unrolling recursion via loop
current = completion
param = outcome
} else {
//最终走到这里,这个completion就是被塞的第一颗球。
completion.resumeWith(outcome)
return
}
}
}
}
}
状态机代码截取
public final Object invokeSuspend(@NotNull Object $result) {
Object var3 = IntrinsicsKt.getCOROUTINE_SUSPENDED();
Object var10000;
switch(this.label) {
case 0://第一次进来 label = 0
ResultKt.throwOnFailure($result);
// label改成1了,意味着下一次被恢复的时候会走case 1,这就是所谓的【状态流转】
this.label = 1;
//全体目光向我看齐,我宣布个事:this is 协程体对象。
var10000 = TestSampleKt.hello2(this);
if (var10000 == var3) {
return var3;
}
break;
case 1:
ResultKt.throwOnFailure($result);
var10000 = $result;
break;
default:
throw new IllegalStateException("call to 'resume' before 'invoke' with coroutine");
}
int a = ((Number)var10000).intValue();
return Boxing.boxInt(a);
}
question3答案出来了,传进去的是create创建的那个continuation
最后再来聊聊question2,从上面的代码已经很清楚的告诉我们为啥挂起函数反编译后的返回值变为object了。
以hello2为例子,hello2能返回代表挂起的白板,也能返回result。如果返回白板,状态机return,协程挂起。如果返回result,那么hello2执行完毕,是一个没有挂起的挂起函数,通常编译器也会提醒 suspend 修饰词无意义。所以这就是设计需要,没有啥因为所以。
最后,除了直接返回结果的情况,挂起函数一定会以resume结尾,要么返回result,要么返回异常。代表这个挂起函数返回了。
调用resume意义在于重新回调BaseContinuationImpl的resumeWith,进而唤醒状态机,继续执行协程体的代码。
换句话说,我们自定义的suspend函数,一定要利用suspendCoroutine 获得续体,即状态机对象,否则无法实现真正的挂起与resume。
我们可以不用suspendCoroutine,用更直接的suspendCoroutineUninterceptedOrReturn也能实现,不过这种方式要手动返回白板。不过一定要小心,要在合理的情况下返回或者不返回,不然会产生很多意想不到的结果
suspend fun mySuspendOne() = suspendCoroutineUninterceptedOrReturn<String> { continuation ->
thread {
TimeUnit.SECONDS.sleep(1)
continuation.resume("hello world")
}
//因为我们这个函数没有返回正确结果,所以必须返回一个挂起标识,否则BaseContinuationImpl会认为完成了任务。
// 并且我们的线程又在运行没有取消,这将很多意想不到的结果
kotlin.coroutines.intrinsics.COROUTINE_SUSPENDED
}
而suspendCoroutine则没有这个隐患
suspend fun mySafeSuspendOne() = suspendCoroutine<String> { continuation ->
thread {
TimeUnit.SECONDS.sleep(1)
continuation.resume("hello world")
}
//suspendCoroutine函数很聪明的帮我们判断返回结果如果不是想要的对象,自动返
kotlin.coroutines.intrinsics.COROUTINE_SUSPENDED
}
public suspend inline fun <T> suspendCoroutine(crossinline block: (Continuation<T>) -> Unit): T =
suspendCoroutineUninterceptedOrReturn { c: Continuation<T> ->
//封装一个代理Continuation对象
val safe = SafeContinuation(c.intercepted())
block(safe)
//根据block返回结果判断要不要返回COROUTINE_SUSPENDED
safe.getOrThrow()
}
//调用单参数的这个构造方法
internal actual constructor(delegate: Continuation<T>) : this(delegate, UNDECIDED)
@Volatile
private var result: Any? = initialResult //UNDECIDED赋值给 result
//java原子属性更新器那一套东西
private companion object {
@Suppress("UNCHECKED_CAST")
@JvmStatic
private val RESULT = AtomicReferenceFieldUpdater.newUpdater<SafeContinuation<*>, Any?>(
SafeContinuation::class.java, Any::class.java as Class<Any?>, "result"
)
}
internal actual fun getOrThrow(): Any? {
var result = this.result // atomic read
if (result === UNDECIDED) { //如果UNDECIDED,那么就把result设置为COROUTINE_SUSPENDED
if (RESULT.compareAndSet(this, UNDECIDED, COROUTINE_SUSPENDED)) returnCOROUTINE_SUSPENDED
result = this.result // reread volatile var
}
return when {
result === RESUMED -> COROUTINE_SUSPENDED // already called continuation, indicate COROUTINE_SUSPENDED upstream
result is Result.Failure -> throw result.exception
else -> result // either COROUTINE_SUSPENDED or data <-这里返回白板
}
}
public actual override fun resumeWith(result: Result<T>) {
while (true) { // lock-free loop
val cur = this.result // atomic read。不理解这里的官方注释为啥叫做原子读。我觉得 Volatile只能保证可见性。
when {
//这里如果是UNDECIDED 就把 结果附上去。
cur === UNDECIDED -> if (RESULT.compareAndSet(this, UNDECIDED, result.value)) return
//如果是挂起状态,就通过resumeWith回调状态机
cur === COROUTINE_SUSPENDED -> if (RESULT.compareAndSet(this, COROUTINE_SUSPENDED, RESUMED)){
delegate.resumeWith(result)
return
}
else -> throw IllegalStateException("Already resumed")
}
}
}
val safe = SafeContinuation(c.intercepted())
block(safe)
safe.getOrThrow()
先回顾一下什么叫真正的挂起,就是getOrThrow返回了“白板”,那么什么时候getOrThrow能返回白板?答案就是result被初始化后值没被修改过。那么也就是说resumeWith没有被执行过,即:block(safe)这句代码,block这个被传进来的函数,执行过程中没有调用safe的resumeWith。原理就是这么简单,cas代码保证关键逻辑的原子性与并发安全
继续以Demo-K1为例子,这里假设hello2运行在一条新的子线程,否则仍然是没有挂起。
{
thread{
Thread.sleep(1000)
it.resume(10086)
}
}
最后,可以说开启一个协程,就是利用编译器生成一个状态机对象,帮我们把回调代码拍扁,成为同步代码。
总的来说,我对ruby还比较陌生,我正在为我正在创建的对象编写一些rspec测试用例。许多测试用例都非常基础,我只是想确保正确填充和返回值。我想知道是否有办法使用循环结构来执行此操作。不必为我要测试的每个方法都设置一个assertEquals。例如:describeitem,"TestingtheItem"doit"willhaveanullvaluetostart"doitem=Item.new#HereIcoulddotheitem.name.shouldbe_nil#thenIcoulddoitem.category.shouldbe_nilendend但我想要一些方法来使用
我试图在一个项目中使用rake,如果我把所有东西都放到Rakefile中,它会很大并且很难读取/找到东西,所以我试着将每个命名空间放在lib/rake中它自己的文件中,我添加了这个到我的rake文件的顶部:Dir['#{File.dirname(__FILE__)}/lib/rake/*.rake'].map{|f|requiref}它加载文件没问题,但没有任务。我现在只有一个.rake文件作为测试,名为“servers.rake”,它看起来像这样:namespace:serverdotask:testdoputs"test"endend所以当我运行rakeserver:testid时
作为我的Rails应用程序的一部分,我编写了一个小导入程序,它从我们的LDAP系统中吸取数据并将其塞入一个用户表中。不幸的是,与LDAP相关的代码在遍历我们的32K用户时泄漏了大量内存,我一直无法弄清楚如何解决这个问题。这个问题似乎在某种程度上与LDAP库有关,因为当我删除对LDAP内容的调用时,内存使用情况会很好地稳定下来。此外,不断增加的对象是Net::BER::BerIdentifiedString和Net::BER::BerIdentifiedArray,它们都是LDAP库的一部分。当我运行导入时,内存使用量最终达到超过1GB的峰值。如果问题存在,我需要找到一些方法来更正我的代
Rails2.3可以选择随时使用RouteSet#add_configuration_file添加更多路由。是否可以在Rails3项目中做同样的事情? 最佳答案 在config/application.rb中:config.paths.config.routes在Rails3.2(也可能是Rails3.1)中,使用:config.paths["config/routes"] 关于ruby-on-rails-Rails3中的多个路由文件,我们在StackOverflow上找到一个类似的问题
我需要从一个View访问多个模型。以前,我的links_controller仅用于提供以不同方式排序的链接资源。现在我想包括一个部分(我假设)显示按分数排序的顶级用户(@users=User.all.sort_by(&:score))我知道我可以将此代码插入每个链接操作并从View访问它,但这似乎不是“ruby方式”,我将需要在不久的将来访问更多模型。这可能会变得很脏,是否有针对这种情况的任何技术?注意事项:我认为我的应用程序正朝着单一格式和动态页面内容的方向发展,本质上是一个典型的网络应用程序。我知道before_filter但考虑到我希望应用程序进入的方向,这似乎很麻烦。最终从任何
我在我的项目中添加了一个系统来重置用户密码并通过电子邮件将密码发送给他,以防他忘记密码。昨天它运行良好(当我实现它时)。当我今天尝试启动服务器时,出现以下错误。=>BootingWEBrick=>Rails3.2.1applicationstartingindevelopmentonhttp://0.0.0.0:3000=>Callwith-dtodetach=>Ctrl-CtoshutdownserverExiting/Users/vinayshenoy/.rvm/gems/ruby-1.9.3-p0/gems/actionmailer-3.2.1/lib/action_mailer
刚入门rails,开始慢慢理解。有人可以解释或给我一些关于在application_controller中编码的好处或时间和原因的想法吗?有哪些用例。您如何为Rails应用程序使用应用程序Controller?我不想在那里放太多代码,因为据我了解,每个请求都会调用此Controller。这是真的? 最佳答案 ApplicationController实际上是您应用程序中的每个其他Controller都将从中继承的类(尽管这不是强制性的)。我同意不要用太多代码弄乱它并保持干净整洁的态度,尽管在某些情况下ApplicationContr
我想向我的Controller传递一个参数,它是一个简单的复选框,但我不知道如何在模型的form_for中引入它,这是我的观点:{:id=>'go_finance'}do|f|%>Transferirde:para:Entrada:"input",:placeholder=>"Quantofoiganho?"%>Saída:"output",:placeholder=>"Quantofoigasto?"%>Nota:我想做一个额外的复选框,但我该怎么做,模型中没有一个对象,而是一个要检查的对象,以便在Controller中创建一个ifelse,如果没有检查,请帮助我,非常感谢,谢谢
我注意到像bundler这样的项目在每个specfile中执行requirespec_helper我还注意到rspec使用选项--require,它允许您在引导rspec时要求一个文件。您还可以将其添加到.rspec文件中,因此只要您运行不带参数的rspec就会添加它。使用上述方法有什么缺点可以解释为什么像bundler这样的项目选择在每个规范文件中都需要spec_helper吗? 最佳答案 我不在Bundler上工作,所以我不能直接谈论他们的做法。并非所有项目都checkin.rspec文件。原因是这个文件,通常按照当前的惯例,只
我正在使用active_admin,我在Rails3应用程序的应用程序中有一个目录管理,其中包含模型和页面的声明。时不时地我也有一个类,当那个类有一个常量时,就像这样:classFooBAR="bar"end然后,我在每个必须在我的Rails应用程序中重新加载一些代码的请求中收到此警告:/Users/pupeno/helloworld/app/admin/billing.rb:12:warning:alreadyinitializedconstantBAR知道发生了什么以及如何避免这些警告吗? 最佳答案 在纯Ruby中:classA