目录
2.match(ttype, values, regex=False)
写此sqlparse库的目的还是寻找在python编程内可行的SQL血缘解析,JAVA去解析Hive的源码实践的话我还是打算放到后期来做,先把Python能够实现的先实现完。上篇系列讲述的基于antrl解析说是用python其实还是太牵强了,无非就是使用PyJnius调用JAVA的类方法来实现,没有多大的意义来牵扯到Python编程。主要是HiveSQL的底层就是JAVA代码,怎么改写还是绕不开JAVA的。不过上篇系列我有提到过sqlparse,其实这个库用来解析血缘的话也不是不可以,但是能够实现的功能是有限的,目前我实验还行,一些复杂超过千行的数据分析SQL没有测试过。做一些简单的血缘解析的话还是没有应该太大问题,后续我会在此基础之上开发尝试。
首先先给官网地址:python-sqlparse。有足够好编码能力可以直接上github上面看源码,解读更细:github.sqlparse
sqlparse是用于Python的非验证SQL解析器。它支持解析、拆分和格式化SQL语句。既然有解析功能那么我们就能做初步的血缘解析功能。这个库的函数解析没有像Pandas和numpy写的那么详细,毕竟是人家个人的开源库,功能写的已经很不错了,能够省去我们很多递归剥离AST树的时间。官网上关于该库使用操作很简单,很多比较好的功能函数也没有使用到,我希望可以尽力将此库开发为通用SQL血缘解析的基础工具库。如果该功能开发完我会将此项目开源。
我通过细读源码来了解此库的大体功能。
看初始化代码方法有四种:parse,parsestream,format,split这四种
def parse(sql, encoding=None):
"""Parse sql and return a list of statements.
:param sql: A string containing one or more SQL statements.
:param encoding: The encoding of the statement (optional).
:returns: A tuple of :class:`~sqlparse.sql.Statement` instances.
"""
return tuple(parsestream(sql, encoding))
传入一个SQL语句,返回一个 sqlparse.sql.Statement的元组,我们可以递归方式获得输出。
query = 'Select a, col_2 as b from Table_A;'
for each in sqlparse.parse(query):
print(each)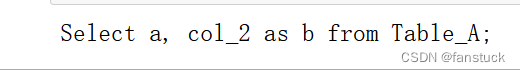
其元组根据;符号来进行切分存储:
query = 'Select a, col_2 as b from Table_A;select * from foo'
for each in sqlparse.parse(query):
print(each)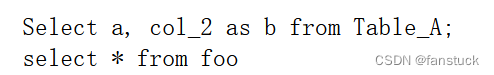

可以看到第一个方法是调用了parsestream来完成流式解析的,那么这个方法也就是循环读取sql语句来完成转换statment的:
def parsestream(stream, encoding=None):
"""Parses sql statements from file-like object.
:param stream: A file-like object.
:param encoding: The encoding of the stream contents (optional).
:returns: A generator of :class:`~sqlparse.sql.Statement` instances.
"""
stack = engine.FilterStack()
stack.enable_grouping()
return stack.run(stream, encoding)
这里的引擎是可以替换的。
sqlparse.parsestream(query)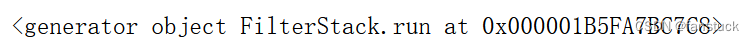
它将返回一个sqlparse.sql.Statement实例的发生器。来看看这个run方法:
def run(self, sql, encoding=None):
stream = lexer.tokenize(sql, encoding)
# Process token stream
for filter_ in self.preprocess:
stream = filter_.process(stream)
stream = StatementSplitter().process(stream)
# Output: Stream processed Statements
for stmt in stream:
if self._grouping:
stmt = grouping.group(stmt)
for filter_ in self.stmtprocess:
filter_.process(stmt)
for filter_ in self.postprocess:
stmt = filter_.process(stmt)
yield stmt该方法就是生产一个statment,这个类应该就是这个库的基类了,多半围绕这个数据结构来处理。
该方法就是将sql语句标准化:
query = 'Select a, col_2 as b from Table_A;select * from foo'
print(sqlparse.format(query, reindent=True, keyword_case='upper'))

format()函数接受关键字参数:
该方法用于分割sql语句:
sqlparse.split(query) 这里补充一下calss类sqlparse.sql.Statement是可以直接通过str转换为字符串的。
这里补充一下calss类sqlparse.sql.Statement是可以直接通过str转换为字符串的。
结果返回一个分割后的list。至此初始方法就写完了,下面我将详解一下基类,这将决定是我们是否能灵活运用此库。
我们来看看Token的初始方法属性:
def __init__(self, ttype, value):
value = str(value)
self.value = value
self.ttype = ttype
self.parent = None
self.is_group = False
self.is_keyword = ttype in T.Keyword
self.is_whitespace = self.ttype in T.Whitespace
self.normalized = value.upper() if self.is_keyword else value这个Token类也就是语法解析器的重点数据流了:

此类需要生成Tokens使用,这牵扯到另一个方法tokens.py:
此方法也就是将statment类转换为Token流:
parsed = sqlparse.parse(query)
stmt = parsed[0]
stmt.tokens 
其中我们需要解析的每个Token的标识码也就是第一个ttype属性,解析之后:
for each_token in sql_tokens:
print(each_token.ttype,each_token.value) 
我们拿一个Token来研究就能逐渐解析到其他token。我们建立一个列表将其主要属性ttype和value收集起来:
type(list_ttype[0])
type(list_value[0])第一个属性为sqlparse.tokens._TokenType第二个value直接就是str了。上tokens看_TokenType:
# Special token types
Text = Token.Text
Whitespace = Text.Whitespace
Newline = Whitespace.Newline
Error = Token.Error
# Text that doesn't belong to this lexer (e.g. HTML in PHP)
Other = Token.Other
# Common token types for source code
Keyword = Token.Keyword
Name = Token.Name
Literal = Token.Literal
String = Literal.String
Number = Literal.Number
Punctuation = Token.Punctuation
Operator = Token.Operator
Comparison = Operator.Comparison
Wildcard = Token.Wildcard
Comment = Token.Comment
Assignment = Token.Assignment
# Generic types for non-source code
Generic = Token.Generic
Command = Generic.Command
# String and some others are not direct children of Token.
# alias them:
Token.Token = Token
Token.String = String
Token.Number = Number
# SQL specific tokens
DML = Keyword.DML
DDL = Keyword.DDL
CTE = Keyword.CTE可以发现这就是Token的识别解析类型码,通过该码就可以访问获得解析出的关键字了。
关于此基类又有五种主要的方法:
flatten()用于解析子组
for each_token in sql_tokens:
#list_ttype.append(each_token.ttype),list_value.append(each_token.value)
print(each_token.flatten())
match(ttype, values, regex=False)检查标记是否与给定参数匹配。
list_ttype=[]
list_value=[]
for each_token in sql_tokens:
#list_ttype.append(each_token.ttype),list_value.append(each_token.value)
print(each_token.match(each_token.ttype,each_token.ttype)) 
or运算为None匹配为True输出。
ttype是一种token类型。如果此标记与给定的标记类型不匹配。values是此标记的可能值列表。这些values一起进行OR运算,因此如果只有一个值与True匹配,则返回。除关键字标记外,比较区分大小写。为了方便起见,可以传入单个字符串。如果regex为True(默认值为False),则给定值将被视为正则表达式。
另外还有三种方法has_ancestor(other),is_child_of(other),within(group_cls)这都有调用功能函数相关,可以先不用了解。
由此Token传入流单体已经差不多分析完,但是AST树该如何生成这是个问题,还有关于树的递归问题和层级问题,我们继续根据基类来慢慢摸清。这篇文章已经足够多内容了,先打住。下一篇再细讲。
以上就是本期全部内容。我是fanstuck ,有问题大家随时留言讨论 ,我们下期见
我有一个字符串input="maybe(thisis|thatwas)some((nice|ugly)(day|night)|(strange(weather|time)))"Ruby中解析该字符串的最佳方法是什么?我的意思是脚本应该能够像这样构建句子:maybethisissomeuglynightmaybethatwassomenicenightmaybethiswassomestrangetime等等,你明白了......我应该一个字符一个字符地读取字符串并构建一个带有堆栈的状态机来存储括号值以供以后计算,还是有更好的方法?也许为此目的准备了一个开箱即用的库?
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
我正在使用ruby1.9解析以下带有MacRoman字符的csv文件#encoding:ISO-8859-1#csv_parse.csvName,main-dialogue"Marceu","Giveittohimóhe,hiswife."我做了以下解析。require'csv'input_string=File.read("../csv_parse.rb").force_encoding("ISO-8859-1").encode("UTF-8")#=>"Name,main-dialogue\r\n\"Marceu\",\"Giveittohim\x97he,hiswife.\"\
简而言之错误:NOTE:Gem::SourceIndex#add_specisdeprecated,useSpecification.add_spec.Itwillberemovedonorafter2011-11-01.Gem::SourceIndex#add_speccalledfrom/opt/local/lib/ruby/site_ruby/1.8/rubygems/source_index.rb:91./opt/local/lib/ruby/gems/1.8/gems/rails-2.3.8/lib/rails/gem_dependency.rb:275:in`==':und
这个问题在这里已经有了答案:关闭10年前。PossibleDuplicate:Pythonconditionalassignmentoperator对于这样一个简单的问题表示歉意,但是谷歌搜索||=并不是很有帮助;)Python中是否有与Ruby和Perl中的||=语句等效的语句?例如:foo="hey"foo||="what"#assignfooifit'sundefined#fooisstill"hey"bar||="yeah"#baris"yeah"另外,类似这样的东西的通用术语是什么?条件分配是我的第一个猜测,但Wikipediapage跟我想的不太一样。
什么是ruby的rack或python的Java的wsgi?还有一个路由库。 最佳答案 来自Python标准PEP333:Bycontrast,althoughJavahasjustasmanywebapplicationframeworksavailable,Java's"servlet"APImakesitpossibleforapplicationswrittenwithanyJavawebapplicationframeworktoruninanywebserverthatsupportstheservletAPI.ht
无论您是想搭建桌面端、WEB端或者移动端APP应用,HOOPSPlatform组件都可以为您提供弹性的3D集成架构,同时,由工业领域3D技术专家组成的HOOPS技术团队也能为您提供技术支持服务。如果您的客户期望有一种在多个平台(桌面/WEB/APP,而且某些客户端是“瘦”客户端)快速、方便地将数据接入到3D应用系统的解决方案,并且当访问数据时,在各个平台上的性能和用户体验保持一致,HOOPSPlatform将帮助您完成。利用HOOPSPlatform,您可以开发在任何环境下的3D基础应用架构。HOOPSPlatform可以帮您打造3D创新型产品,HOOPSSDK包含的技术有:快速且准确的CAD
华为OD机试题本篇题目:明明的随机数题目输入描述输出描述:示例1输入输出说明代码编写思路最近更新的博客华为od2023|什么是华为od,od薪资待遇,od机试题清单华为OD机试真题大全,用Python解华为机试题|机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南华为o
我想解析一个已经存在的.mid文件,改变它的乐器,例如从“acousticgrandpiano”到“violin”,然后将它保存回去或作为另一个.mid文件。根据我在文档中看到的内容,该乐器通过program_change或patch_change指令进行了更改,但我找不到任何在已经存在的MIDI文件中执行此操作的库.他们似乎都只支持从头开始创建的MIDI文件。 最佳答案 MIDIpackage会为您完成此操作,但具体方法取决于midi文件的原始内容。一个MIDI文件由一个或多个音轨组成,每个音轨是十六个channel中任何一个上的