注:个人观点及答案,望大家采纳,指教!!
HTTP 协议是Hyper Text Transfer Protocol(超文本传输协议)的缩写,是用于从万维网(WWW:World Wide Web )服务器传输超文本到本地浏览器的传送协议;
HTTP 是一个基于TCP/IP通信协议来传递数据(HTML文件、图片文件、查询结果等);
HTTP协议工作于客户端-服务端架构上,浏览器作为HTTP客户端通过URL向HTTP服务端发送所有请求。
web服务器有:Apache 服务器、lls服务器等;
HTTP默认端口号为80,但是也可以改为8080或者其他端口;
优点:
支持客户/服务器模式:应用广泛且跨平台:简单快速、灵活:缺点:
无连接:无状态:无状态可以减轻服务器负担,但进行关联操作时繁琐,Cookie正好可以解决这个问题明文传输:调试便利的同时带来了信息易被窃取不安全:(HTTPS通过引入SSL/TLS层,解决了这个隐患)区别一:
get重点在从服务器上获取资源,post重点在向服务器发送数据;
区别二:
get是不安全的,因为URL是可见的,可能会泄露私密信息,如密码等; post较get安全性较高;
区别三:
get传输数据是通过URL请求,以field(字段)= value的形式,置于URL后,并用"?"连接,多个请求数据间用"&"连接,如http://127.0.0.1/Test/login.action?name=admin&password=admin,这个过程用户是可见的;
post传输数据通过Http的post机制,将字段与对应值封存在请求实体中发送给服务器,这个过程对用户是不可见的
区别四:
Get传输的数据量小,因为受URL长度限制,但效率较高;
Post可以传输大量数据,所以上传文件时只能用Post方式;
区别五:
get方式只能支持ASCII字符,向服务器传的中文字符可能会乱码。
post支持标准字符集,可以正确传递中文字符。
HTTPS:是以安全为目标的 HTTP 通道,是 HTTP 的安全版。HTTPS 的安全基础是 SSL。SSL 协议位于 TCP/IP
协议与各种应用层协议之间,为数据通讯提供安全支持。
区别:
HTTP 是超文本传输协议,信息是明文传输,HTTPS 则是具有安全性的 SSL 加密传输协议。HTTP和HTTPS 使用完全不同的连接方式,所用的端口不同,前者是80 端口,后者是 443端口4.常见HTTP的状态码有哪些?
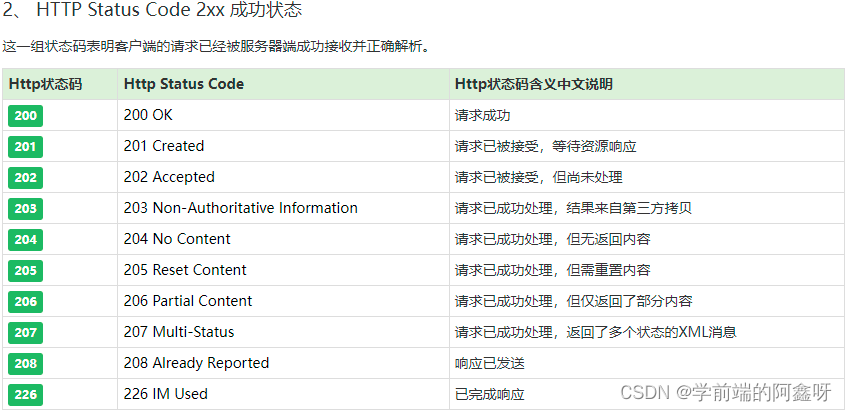
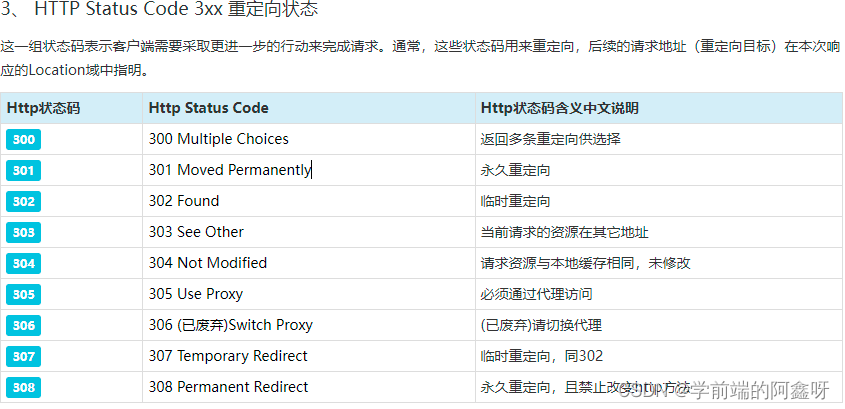
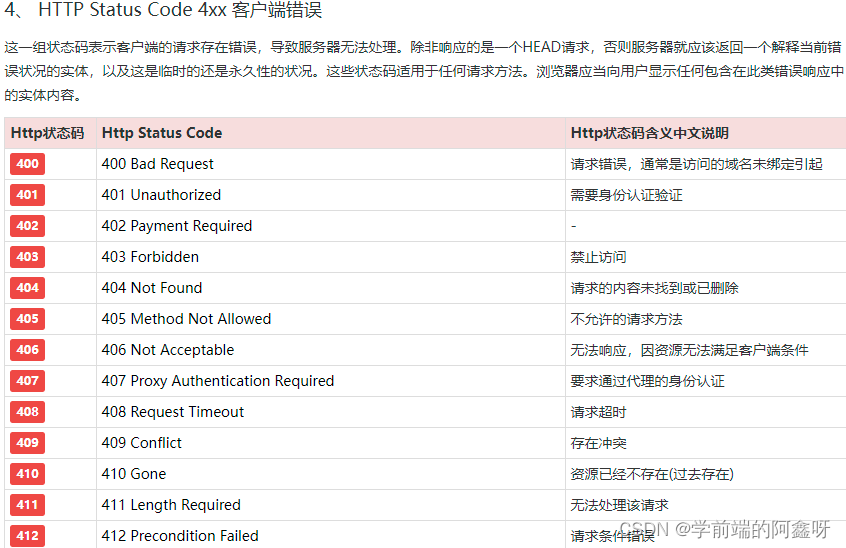
200 – 请求成功301 – 资源(网页等)被永久转移到其它URL404 – 请求的资源(网页等)不存在500 – 内部服务器错误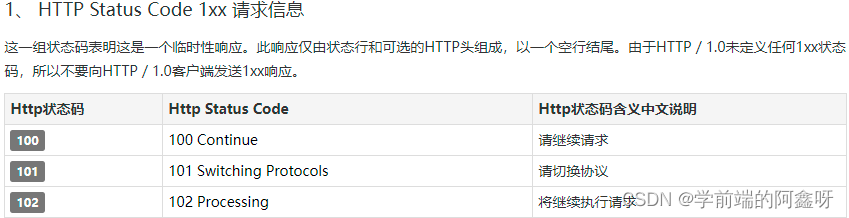

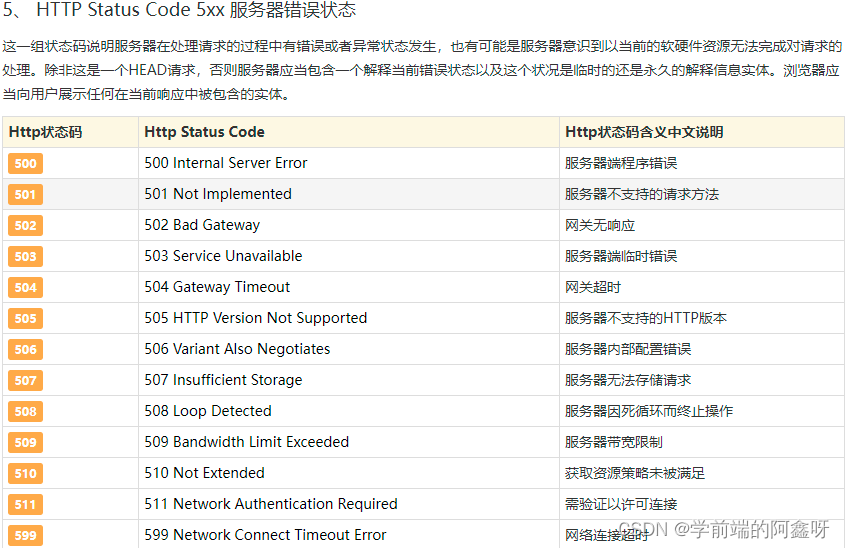
6.HTTP常见的字段有哪些?
URI&URL:
URI:统一资源标识符,不仅可以标识http,ftp等其他的网络资源
URL:统一资源定位符
请求头:
GET :获取一个资源,同时参数直接跟在URL后面,url长度受限制2048字节
POST:不仅可以获取资源,还可以提交资源(譬如上传文件),参数放在请求体中,包大小4G
HEAD:只要响应头,没有响应体,通常用于测试URL是否存在
DELETE:删除一个资源
PUT:通常修改一个资源
响应头:
Content-Length:响应体的长度
Server:服务器的信息
Content-Type:内容的类型,text/html,xml等
Last-Modified :最有的修改日期,通常跟缓存相关 20151108
Location: 新的地址
响应码:
200 OK 访问正常
206 跟断点续传相关
3XX 重定向:Location
304 缓存有效
307 临时重定向
4XX 客户端问题
401 代表没有权限访问
404 代表访问的资源不存在
5XX 通常服务器内部处理的问题
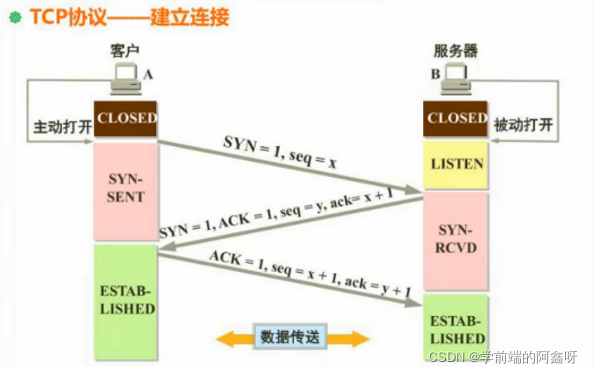
7.请谈谈你对“ ****三次握手与四次挥手**** ”的理解并说说作用?
1、第一次握手:客户端给服务端发一个 SYN 报文,并指明客户端的初始化序列号 ISN(c)。此时客户端处于 SYN_Send 状态。
2、第二次握手:服务器收到客户端的 SYN 报文之后,会以自己的 SYN 报文作为应答,并且也是指定了自己的初始化序列号 ISN(s),同时会把客户端的 ISN + 1 作为 ACK 的值,表示自己已经收到了客户端的 SYN,此时服务器处于 SYN_REVD 的状态。
3、第三次握手:客户端收到 SYN 报文之后,会发送一个 ACK 报文,当然,也是一样把服务器的 ISN + 1 作为 ACK 的值,表示已经收到了服务端的 SYN 报文,此时客户端处于 establised 状态。
服务器收到 ACK 报文之后,也处于 establised 状态,此时,双方以建立起了链接。
1、确认双方的接受能力、发送能力是否正常;
2、指定自己的初始化序列号,为后面的可靠传送做准备;
3、如果是 https 协议的话,三次握手这个过程,还会进行数字证书的验证以及加密密钥的生成到。
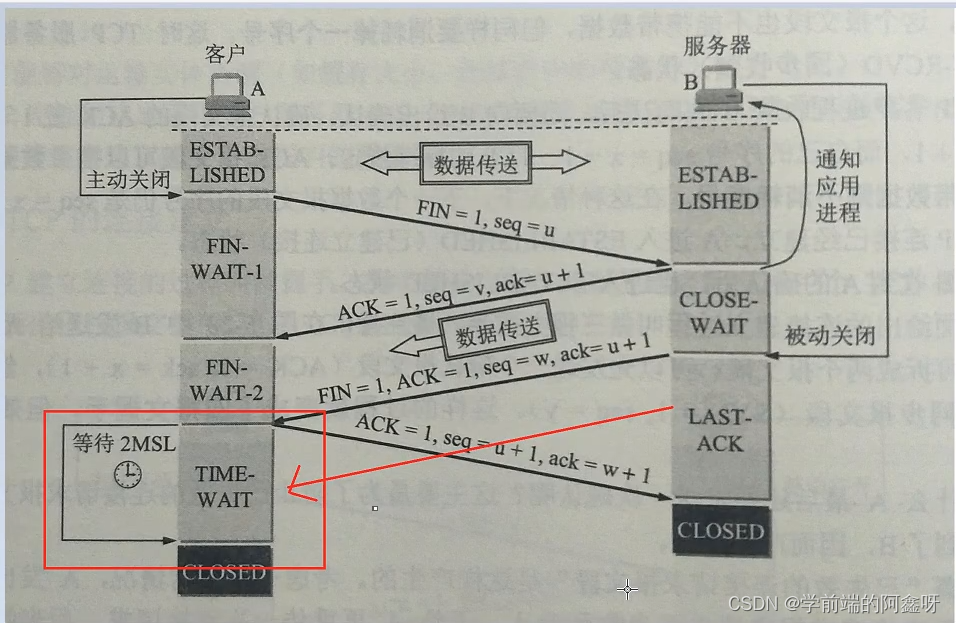
1、第一次挥手:客户端发送一个 FIN 报文,报文中会指定一个序列号。此时客户端处于FIN_WAIT1状态。
2、第二次握手:服务端收到 FIN 之后,会发送 ACK 报文,且把客户端的序列号值 + 1 作为 ACK 报文的序列号值,表明已经收到客户端的报文了,此时服务端处于 CLOSE_WAIT状态。
3、第三次挥手:如果服务端也想断开连接了,和客户端的第一次挥手一样,发给 FIN 报文,且指定一个序列号。此时服务端处于 LAST_ACK 的状态。
4、第四次挥手:客户端收到 FIN 之后,一样发送一个 ACK 报文作为应答,且把服务端的序列号值 + 1 作为自己 ACK 报文的序列号值,此时客户端处于 TIME_WAIT 状态。需要过一阵子以确保服务端收到自己的 ACK 报文之后才会进入 CLOSED 状态
服务端收到 ACK 报文之后,就处于关闭连接了,处于 CLOSED 状态。
是的,我知道最好使用webmock,但我想知道如何在RSpec中模拟此方法:defmethod_to_testurl=URI.parseurireq=Net::HTTP::Post.newurl.pathres=Net::HTTP.start(url.host,url.port)do|http|http.requestreq,foo:1endresend这是RSpec:let(:uri){'http://example.com'}specify'HTTPcall'dohttp=mock:httpNet::HTTP.stub!(:start).and_yieldhttphttp.shou
我目前正在使用以下方法获取页面的源代码:Net::HTTP.get(URI.parse(page.url))我还想获取HTTP状态,而无需发出第二个请求。有没有办法用另一种方法做到这一点?我一直在查看文档,但似乎找不到我要找的东西。 最佳答案 在我看来,除非您需要一些真正的低级访问或控制,否则最好使用Ruby的内置Open::URI模块:require'open-uri'io=open('http://www.example.org/')#=>#body=io.read[0,50]#=>"["200","OK"]io.base_ur
HashMap中为什么引入红黑树,而不是AVL树呢1.概述开始学习这个知识点之前我们需要知道,在JDK1.8以及之前,针对HashMap有什么不同。JDK1.7的时候,HashMap的底层实现是数组+链表JDK1.8的时候,HashMap的底层实现是数组+链表+红黑树我们要思考一个问题,为什么要从链表转为红黑树呢。首先先让我们了解下链表有什么不好???2.链表上述的截图其实就是链表的结构,我们来看下链表的增删改查的时间复杂度增:因为链表不是线性结构,所以每次添加的时候,只需要移动一个节点,所以可以理解为复杂度是N(1)删:算法时间复杂度跟增保持一致查:既然是非线性结构,所以查询某一个节点的时候
1.错误信息:Errorresponsefromdaemon:Gethttps://registry-1.docker.io/v2/:net/http:requestcanceledwhilewaitingforconnection(Client.Timeoutexceededwhileawaitingheaders)或者:Errorresponsefromdaemon:Gethttps://registry-1.docker.io/v2/:net/http:TLShandshaketimeout2.报错原因:docker使用的镜像网址默认为国外,下载容易超时,需要修改成国内镜像地址(首先阿里
最近在学习CAN,记录一下,也供大家参考交流。推荐几个我觉得很好的CAN学习,本文也是在看了他们的好文之后做的笔记首先是瑞萨的CAN入门,真的通透;秀!靠这篇我竟然2天理解了CAN协议!实战STM32F4CAN!原文链接:https://blog.csdn.net/XiaoXiaoPengBo/article/details/116206252CAN详解(小白教程)原文链接:https://blog.csdn.net/xwwwj/article/details/105372234一篇易懂的CAN通讯协议指南1一篇易懂的CAN通讯协议指南1-知乎(zhihu.com)视频推荐CAN总线个人知识总
目录第1题连续问题分析:解法:第2题分组问题分析:解法:第3题间隔连续问题分析:解法:第4题打折日期交叉问题分析:解法:第5题同时在线问题分析:解法:第1题连续问题如下数据为蚂蚁森林中用户领取的减少碳排放量iddtlowcarbon10012021-12-1212310022021-12-124510012021-12-134310012021-12-134510012021-12-132310022021-12-144510012021-12-1423010022021-12-154510012021-12-1523.......找出连续3天及以上减少碳排放量在100以上的用户分析:遇到这类
Rails中有没有一种方法可以提取与路由关联的HTTP动词?例如,给定这样的路线:将“users”匹配到:“users#show”,通过:[:get,:post]我能实现这样的目标吗?users_path.respond_to?(:get)(显然#respond_to不是正确的方法)我最接近的是通过执行以下操作,但它似乎并不令人满意。Rails.application.routes.routes.named_routes["users"].constraints[:request_method]#=>/^GET$/对于上下文,我有一个设置cookie然后执行redirect_to:ba
我正在使用Heroku(heroku.com)来部署我的Rails应用程序,并且正在构建一个iPhone客户端来与之交互。我的目的是将手机的唯一设备标识符作为HTTPheader传递给应用程序以进行身份验证。当我在本地测试时,我的header通过得很好,但在Heroku上它似乎去掉了我的自定义header。我用ruby脚本验证:url=URI.parse('http://#{myapp}.heroku.com/')#url=URI.parse('http://localhost:3000/')req=Net::HTTP::Post.new(url.path)#boguspara
我试图在我的网站上实现使用Facebook登录功能,但在尝试从Facebook取回访问token时遇到障碍。这是我的代码:ifparams[:error_reason]=="user_denied"thenflash[:error]="TologinwithFacebook,youmustclick'Allow'toletthesiteaccessyourinformation"redirect_to:loginelsifparams[:code]thentoken_uri=URI.parse("https://graph.facebook.com/oauth/access_token
我是Ruby的新手。我试过查看在线文档,但没有找到任何有效的方法。我想在以下HTTP请求botget_response()和get()中包含一个用户代理。有人可以指出我正确的方向吗?#PreliminarycheckthatProggitisupcheck=Net::HTTP.get_response(URI.parse(proggit_url))ifcheck.code!="200"puts"ErrorcontactingProggit"returnend#Attempttogetthejsonresponse=Net::HTTP.get(URI.parse(proggit_url)