[作者:Surpassme]Jenkins pipeline 是基于Groovy语言实现的一种DSL(领域特定语言),用于描述整条流水线是如何进行的。流水线的主要内容包括源码拉取、构建、打包、部署、测试、生成报告等步骤。
从源码管理仓库到生成测试报告这些过程中,可以根据需要分成若干阶段,而每个阶段仅处理一件事情,而每个阶段也可以通过多个步骤来完成,因此我们可以基于这些阶段和步骤些进行抽象,形成工程化的pipeline,因此一个基本的pipeline示例如下所示:
pipeline{
agent any
stages{
stage("Sample stage"){
steps {
echo "Hi,Surpass.Welcome visit my blog:https://www.cnblogs.com/surpassme/"
}
}
}
}
以上示例详细解释如下所示:
整条流水线的逻辑运行位置流水线的中每个阶段都必须在某个地方(例如物理机、虚拟机或容器)运行,因此可能通过指定 agent部分来指定具体在哪里运行。
至少包含一个stage1.steps
至少包含一个步骤
2.在一个stage中仅有一个steps
以上每一个部分都是必需的,否则Jenkins都会报错
[作者:Surpassme]基本的pipeline结构是无法满足日常现实多变的需求。因此,Jenkins pipeline可以通过各种指令来扩展丰富自己。以下为Jenkins pipeline支持的命令。
[作者:Surpassme]environment主要用于设置环境变量。可以定义在stage和pipeline部分。环境变量可以分为:Jenkins内置变量和自定义环境变量。
[作者:Surpassme]在执行pipeline时,可以通过env命令来获取Jenkins的全部内置环境变量,其主要使用方法如下所示:
pipeline {
agent any
stages{
stage("PrintEnviroment"){
steps{
// method A
echo "Running ${env.BUILD_ID} on ${env.JENKINS_URL}"
// method B
echo "Running $env.BUILD_ID on $env.JENKINS_URL"
// method C
echo "Running ${BUILD_ID} on ${JENKINS_URL}"
}
}
}
}
默认情况下,env中的所有环境变量都可以直接在pipeline中使用。因此上面三种方法都可以使用,但
不推荐第三种方法,因为在出现变量名冲突时,排查问题非常难。
如果需要查看env所有可用的环境变量,可以通过以下方式进行访问。http://jenkins-master-address/pipeline-syntax/globals。示例如下所示:
Jenkins 内置环境变量如下所示:
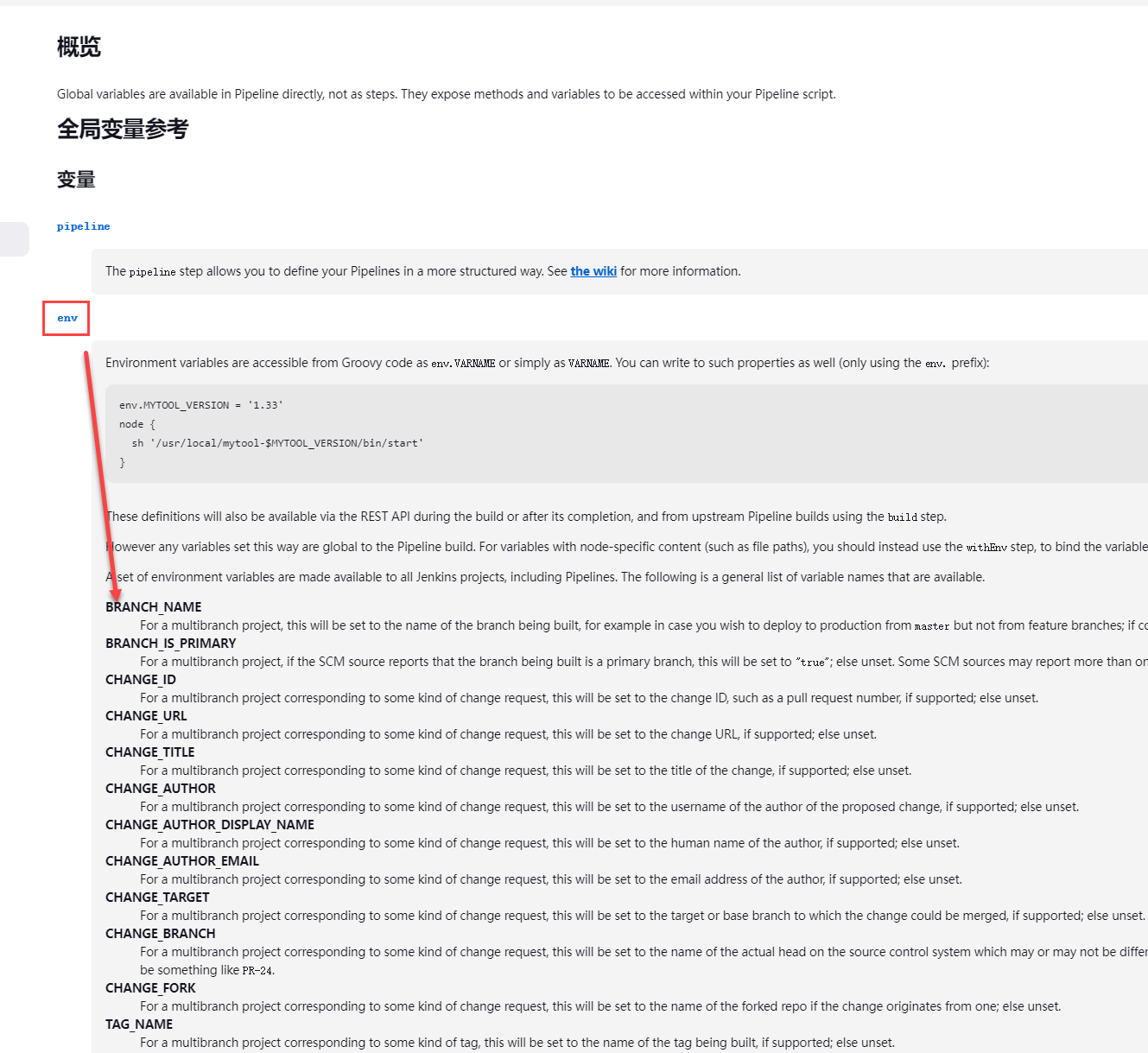
以下为日常经常使用到的内置环境变量简介。如下所示:
多分支piple 项目支持。可根据不同的分支执行不同的语句。例如当分支为release时,部署到生产环境,分支为test时,部署至测试环境。
构建号,同一个项目中,持续累加的数字。
当前构建的URL地址,点击该URL,可以快速跳转至构建页面
构建的工作空间,为绝对路径
在调试pipeline时,也可以在pipeline 的开始阶段使用以下代码片断,打印所有env的环境变量,来进行排查问题。如下所示:
sh "printenv"
[作者:Surpassme]当内置环境变量无法满足要求时,我们也可以定义自己的环境变量。这个时候就需要使用environment命令来自定义环境变量。示例如下所示:
pipeline {
agent any
environment{
NAME="Surpass"
AGE="28"
}
stages{
stage("PrintGolbalEnviroment"){
steps{
echo "Global Enviroment is name is ${env.NAME} age is ${env.AGE}"
}
}
stage("PrintLocalEnviroment"){
environment{
CITY="Shanghai"
FROM="Wuhan"
}
steps{
echo "Global Enviroment is name is ${env.NAME} age is ${env.AGE}"
echo "Local Enviroment is city is ${env.CITY} from is ${env.FROM}"
}
}
}
}
[作者:Surpassme]environment 可以在pipeline中定义,属于全局环境变量,代表整个pipeline均可以使用该环境变量。也可以在stage中定义,属于局部环境变量,仅限于该阶段内部有效,外部无法使用。
除了以上几中自定义环境变量,还可以通过script来定义全局变量,示例如下所示:
pipeline {
agent any
environment{
NAME="Surpass"
AGE="28"
}
stages{
stage("Set environment by script"){
steps{
script{
env.SURPASS_NAME="Surpass"
env.SURPASS_AGE=28
}
}
}
stage("PrintGolbalEnvironment"){
steps{
echo "Global Enviroment is name is ${env.NAME} age is ${env.AGE}"
}
}
stage("PrintLocalEnvironment"){
environment{
CITY="Shanghai"
FROM="Wuhan"
}
steps{
echo "Global Enviroment is name is ${env.NAME} age is ${env.AGE}"
echo "Local Enviroment is city is ${env.CITY} from is ${env.FROM}"
}
}
stage("PrintSetEnvironment"){
steps{
echo "print global env by script ${env.SURPASS_NAME}"
echo "print global env by script ${env.SURPASS_AGE}"
}
}
}
}
在自定义环境变量,需要注意的地方如下所示:
不同的pipeline间不能共享环境变量覆盖 [作者:Surpassme]env中的环境变量都是内置的,用户自定义的环境变量是与具体的pipeline相关的。如果需要定义全局并且跨pipeline自定义环境变量,可以这样设置。
Manage Jenkins->Configure System-> Global properties,勾选 Environment variables,添加对应的环境变量即可。

以上自定义的全局环境变量,会被加入env环境变量列表中,后续使用时可以使用${env.SURPASS_NAME}和${env.SURPASS_AGE}来获取。
[作者:Surpassme]可定义在pipeline或stage部分。在运行时,会自动下载并安装指定的工具和加入PATH变量中。但在agent none时,会失效
基于在线自动安装,受限于网络不可达、网络速度、网络策略等因素,一般还是建议,还是提前下载到本地,然后在Jenkins进行配置好之后,在pipeline中直接使用即可。
其操作步骤如下所示:
1.下载golang SDK本地
2.在Jenkins 中安装go插件
3.在Jenkins中进行配置
Manage Jenkins->Configure System-> Global Tool Configuration->GO

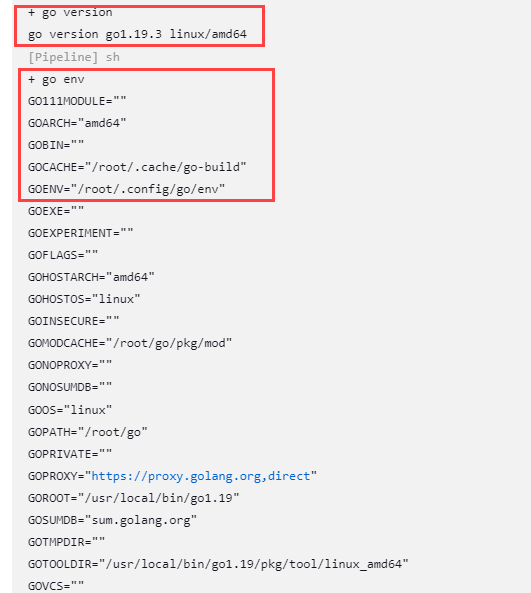
pipeline{
agent any
tools {
go "go-1.19"
}
stages{
stage("tools demo"){
steps{
sh "go version"
sh "go env"
}
}
}
}
运行结果如下所示:
[作者:Surpassme]Python 环境很容易产生版本冲突和第三方库冲突等问题,因此Python通过会进行工程级别的环境隔离。在Jenkins中,我们可以使用插件Pyenv Pipeline Plugin(https://plugins.jenkins.io/pyenv-pipeline/)来解决此类问题。其操作步骤如下所示:
pipeline{
agent any
stages{
stage("python virtual env demo"){
steps{
withPythonEnv("/usr/local/bin/python3") {
// Uses the specific python3.5 executable located in /usr/bin
sh "python3 --version"
sh "python3 -c \"print('hello,Surpass')\""
}
}
}
}
}
运行结果如下所示:

[作者:Surpassme]在实际项目中,同一份源码可能会存在多个版本的编译构建等。tools 除了支持pipeline域也支持stage域。示例如下所示:
pipeline{
agent any
stages{
stage("build with go 1.19"){
tools {
go "go-1.15"
}
steps{
echo "use go 1.15 build"
}
}
stage("build with go 1.19"){
tools {
go "go-1.19"
}
steps{
echo "use go 1.19 build"
}
}
}
}
[作者:Surpassme]input 命令可以实现pipeline中的交互操作。利用input命令,我们可以一些简单的场景。
在部署环境前,由相应负责人员进行确认
因为pipeline在遇到input命令时,会暂停执行。因此,我们可以利用这个特性,使运行某个阶段前,暂停执行pipeline
input 命令的常用参数如下所示:
该参数为必选参数,input命令的消息提示框消息。
该参数为可选参数, input命令标识符,默认为stage的名称
该参数为可选参数,类型为字符串类型,可以进行操作的用户ID或用户组名称,使用,分隔,在,左右不允许有空格。可以用来做权限控制。
该参数为可选参数,类型为字符串类型,保存input命令的实际操作者的用户名的变量名
该参数为可选参数,自定义确定按钮的文本
该参数为可选参数,提供参数列表供input命令使用。
比如我们现在实现第一种简易的审核流程。示例脚本如下所示:
pipeline{
agent any
stages{
stage("input simple use"){
steps{
input message:"Confirm or Cancle ?"
}
}
}
}
当执行到input simple use阶段时,pipeline会暂停,当鼠标移动到该阶段虚线视图上时,会出现一个浮层 ,以供选择。示意图如下所示:
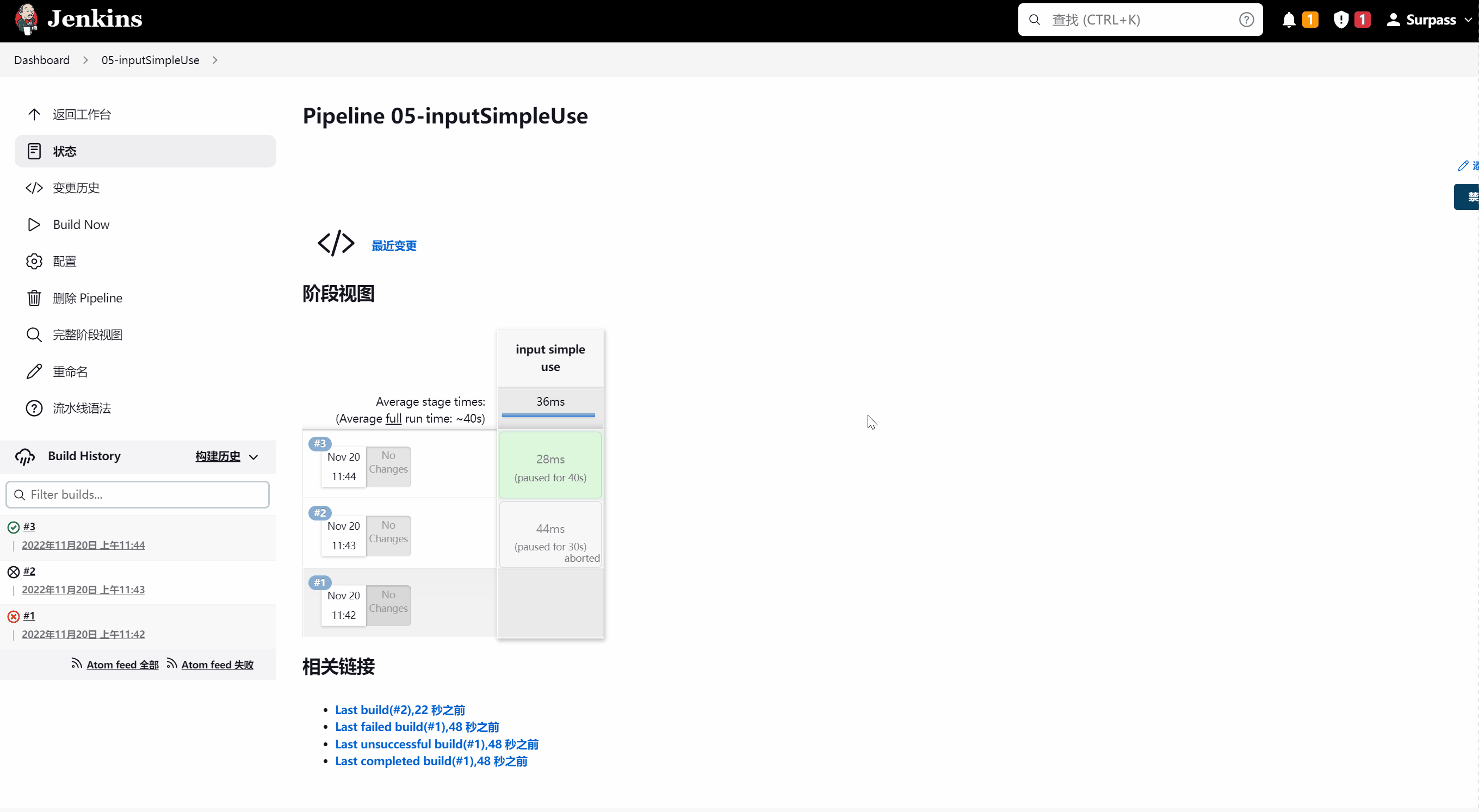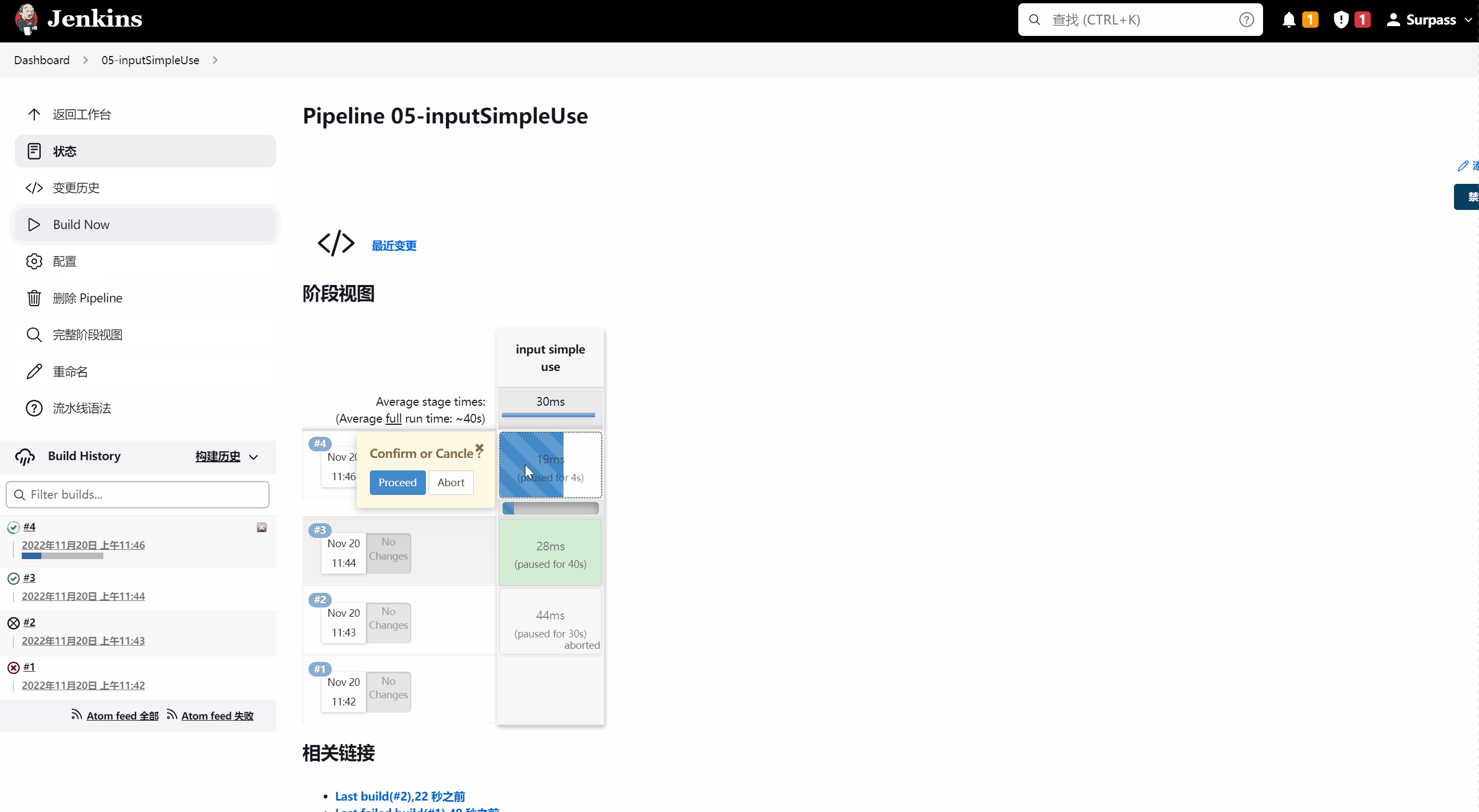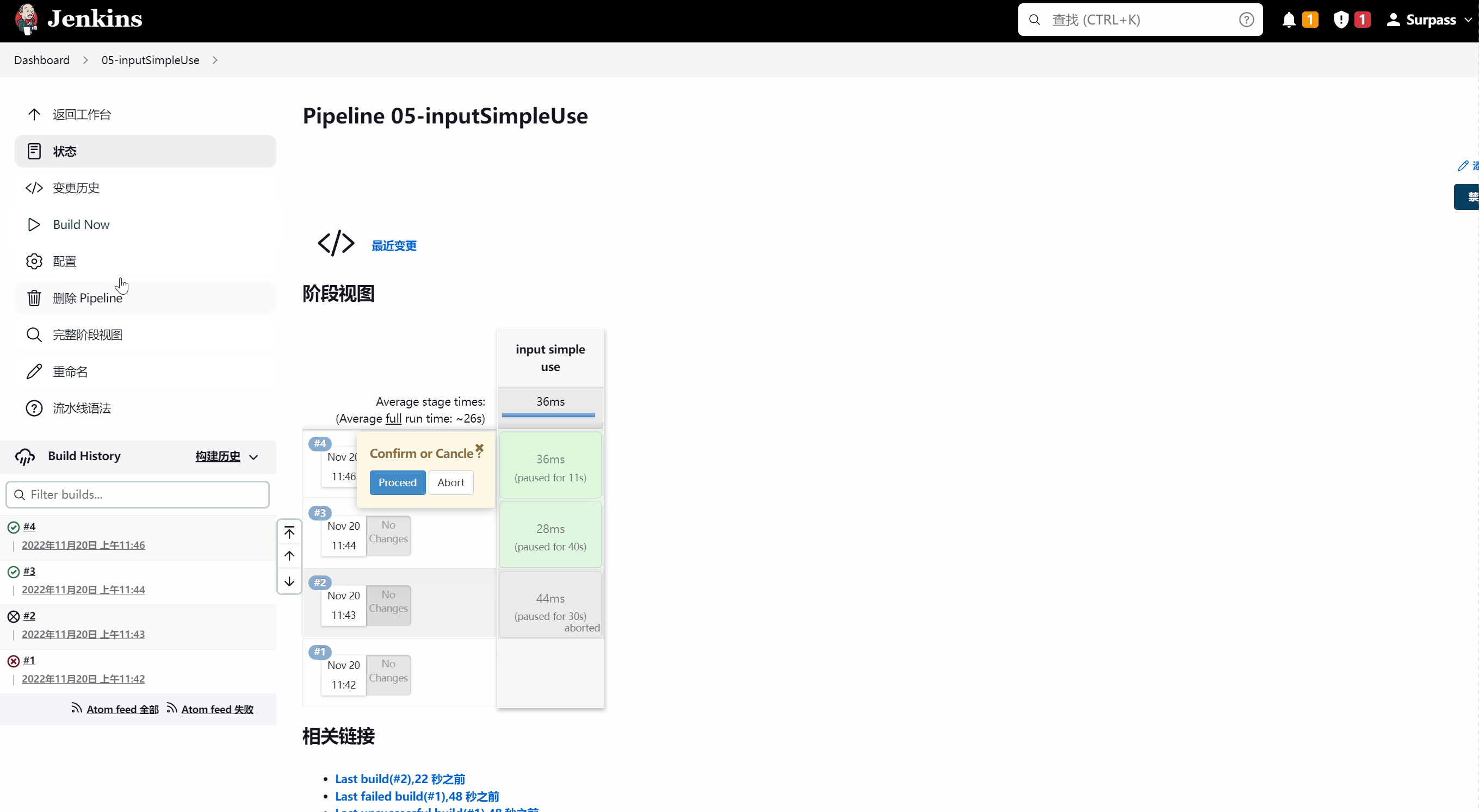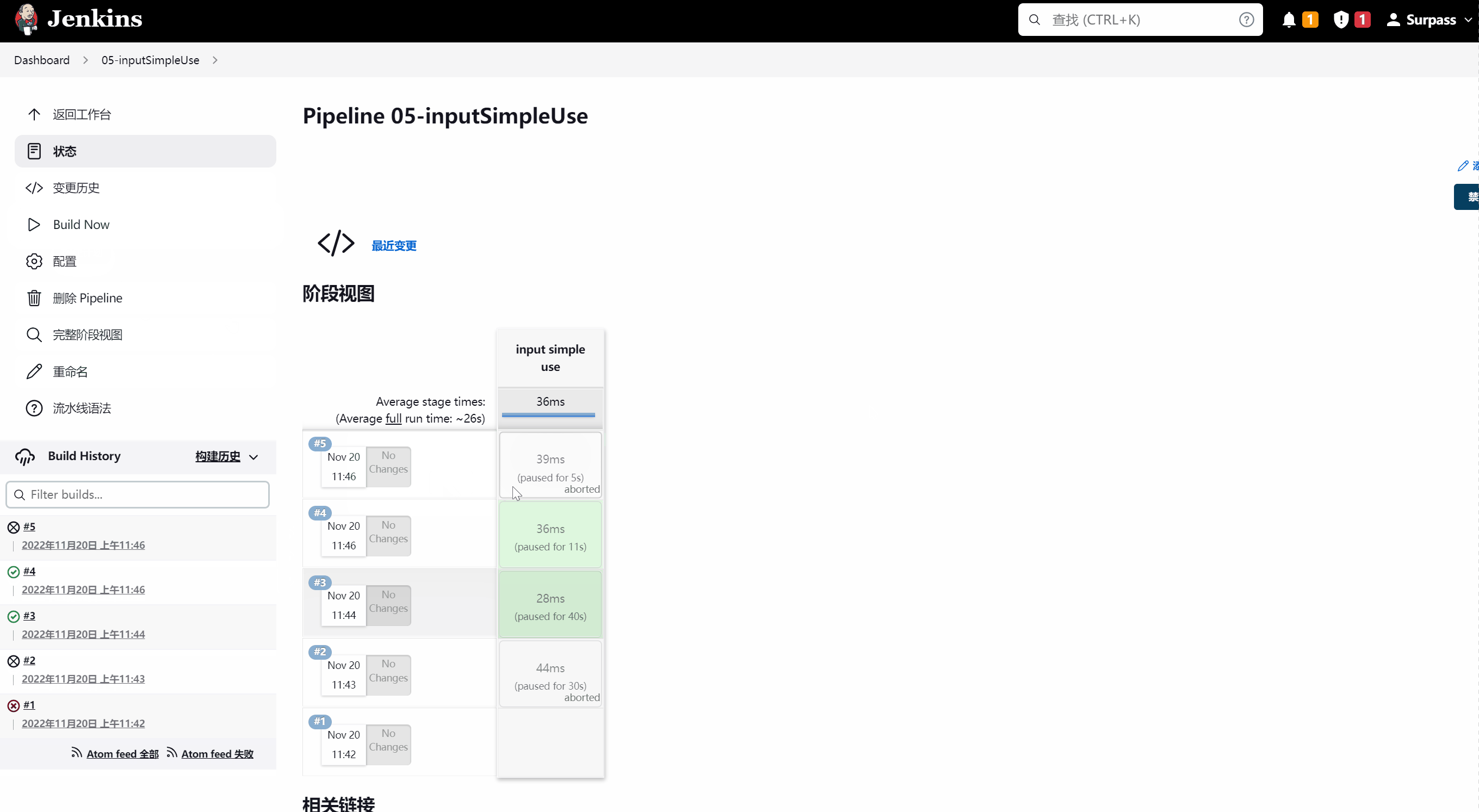
示例脚本如下所示:
pipeline{
agent any
environment {
DEPLOY_ENV=""
}
stages{
stage("choose deploy nodes"){
steps{
script{
DEPLOY_ENV=input(
message: "准备部署到哪个节点?",
parameters:[choice(
name:'chooseNode',
choices:["node-1","node-2","node-3"],
description:"选择部署节点")
],
ok:"确定",
submitter:"admin,Surpass",
submitterParameter:"approvers"
)
}
}
}
stage("deply"){
steps{
echo "操作人员:${DEPLOY_ENV['approvers']}"
echo "部署节点:${DEPLOY_ENV['chooseNode']}"
}
}
}
}
因为input返回的值需要跨阶段,因此需要将input的返回值定义为全局变量。
input 命令返回值类型取决于返回的值个数,详情如下所示:
运行结果如下所示:

[作者:Surpassme]用于配置pipeline本身的选项,可以定义在pipeline和stage中。常用的配置项如下所示:
[作者:Surpassme]用于配置保存最近历史构建记录的数量。示例如下所示:
options{
buildDiscarder(logRotator(numToKeepStr:'5'))
}
此选项只能在pipeline下的 options 中使用
[作者:Surpassme]Jenkins 从版本控制库中拉取源码时,默认会存放到工作空间目录中,此选项可以指定检出到工作空间的子目录中,示例如下所示:
options{
checkoutToSubdirectory('subdir')
}
[作者:Surpassme]同一个pipeline,Jenkins默认是可以同时执行的,而此选项则是禁止多个pipeline并行执行,示例如下所示:
options {
disableConcurrentBuilds()
}
[作者:Surpassme]当发生失败时进行重试,可以指定整个pipeline的重试次数。示例如下所示:
options{
retry(3)
}
需要注意的是这里的重试次数是指总次数,即包含第一次失败。当使用retry选项时,options可以放在stage中
[作者:Surpassme]若pipeline执行时间过长,超出了设置的超时时间之后,则Jenkins将中止pipeline。示例如下所示:
options{
timeout(time:1,unit:'SECONDS')
}
1.timeout时间单位有SECONDS、MINUTES、HOURS。
2.当使用timeout选项时,options可以放在stage块中
[作者:Surpassme]为控制台输出时间戳。示例如下所示:
options {
timestamps()
}
[作者:Surpassme]在pipeline中使用parallel可以很方便的实现并行构建。
示例如下所示:
pipeline{
agent any
stages{
stage("Non Parallel stage"){
steps{
echo "This is non-parallel stage"
}
}
stage("Parallel stage"){
failFast true
parallel{
stage("Parallel A"){
steps{
echo "Parallel A"
}
}
stage("Parallel B"){
steps{
echo "Parallel B"
}
}
stage("Parallel C"){
steps{
echo "Parallel C"
}
}
}
}
}
}
在使用parallel时,注意事项如下所示:
块本身不允许包含agent和toolsfailFast truefailFast true 简单来讲就是表示,只要有一个并行阶段运行失败,则立即退出。
[作者:Surpassme]示例如下所示:
pipeline{
agent any
stages{
stage("Non-parallel steps"){
steps{
echo "Non-parallel steps"
}
}
stage("Parallel steps"){
steps{
parallel(
parallelA:{
echo "parallelA steps"
},
parallelB:{
echo "parallelB steps"
},
parallelC:{
echo "parallelC steps"
}
)
}
}
}
}
[作者:Surpassme]阶段并行和步骤并行的主要区别如下所示:
大括号,而步骤并行时,使用的是括号原文地址:https://www.jianshu.com/p/f2895e38a824
本文同步在微信订阅号上发布,如各位小伙伴们喜欢我的文章,也可以关注我的微信订阅号:woaitest,或扫描下面的二维码添加关注:

很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
我脑子里浮现出一些关于一种新编程语言的想法,所以我想我会尝试实现它。一位friend建议我尝试使用Treetop(Rubygem)来创建一个解析器。Treetop的文档很少,我以前从未做过这种事情。我的解析器表现得好像有一个无限循环,但没有堆栈跟踪;事实证明很难追踪到。有人可以指出入门级解析/AST指南的方向吗?我真的需要一些列出规则、常见用法等的东西来使用像Treetop这样的工具。我的语法分析器在GitHub上,以防有人希望帮助我改进它。class{initialize=lambda(name){receiver.name=name}greet=lambda{IO.puts("He
所以我在关注Railscast,我注意到在html.erb文件中,ruby代码有一个微弱的背景高亮效果,以区别于其他代码HTML文档。我知道Ryan使用TextMate。我正在使用SublimeText3。我怎样才能达到同样的效果?谢谢! 最佳答案 为SublimeText安装ERB包。假设您安装了SublimeText包管理器*,只需点击cmd+shift+P即可获得命令菜单,然后键入installpackage并选择PackageControl:InstallPackage获取包管理器菜单。在该菜单中,键入ERB并在看到包时选择
在Ruby类中,我重写了三个方法,并且在每个方法中,我基本上做同样的事情:classExampleClassdefconfirmation_required?is_allowed&&superenddefpostpone_email_change?is_allowed&&superenddefreconfirmation_required?is_allowed&&superendend有更简洁的语法吗?如何缩短代码? 最佳答案 如何使用别名?classExampleClassdefconfirmation_required?is_a
可能已经问过了,但我找不到它。这里有2个常见的情况(对我来说,在编程Rails时......)用ruby编写是令人沮丧的:"astring".match(/abc(.+)abc/)[1]在这种情况下,我得到一个错误,因为字符串不匹配,因此在nil上调用[]运算符。我想找到的是比以下内容更好的替代方法:temp="astring".match(/abc(.+)abc/);temp.nil??nil:temp[1]简而言之,如果不匹配,则简单地返回nil而不会出错第二种情况是这样的:var=something.very.long.and.tedious.to.writevar=some
我正在学习Ruby的基础知识(刚刚开始),我遇到了Hash.[]method.它被引入a=["foo",1,"bar",2]=>["foo",1,"bar",2]Hash[*a]=>{"foo"=>1,"bar"=>2}稍加思索,我发现Hash[*a]等同于Hash.[](*a)或Hash.[]*一个。我的问题是为什么会这样。是什么让您将*a放在方括号内,是否有某种规则可以在何时何地使用“it”?编辑:我的措辞似乎造成了一些困惑。我不是在问数组扩展。我明白了。我的问题基本上是:如果[]是方法名称,为什么可以将参数放在括号内?这看起来几乎——但不完全是——就像说如果你有一个方法Foo.d
导读:随着叮咚买菜业务的发展,不同的业务场景对数据分析提出了不同的需求,他们希望引入一款实时OLAP数据库,构建一个灵活的多维实时查询和分析的平台,统一数据的接入和查询方案,解决各业务线对数据高效实时查询和精细化运营的需求。经过调研选型,最终引入ApacheDoris作为最终的OLAP分析引擎,Doris作为核心的OLAP引擎支持复杂地分析操作、提供多维的数据视图,在叮咚买菜数十个业务场景中广泛应用。作者|叮咚买菜资深数据工程师韩青叮咚买菜创立于2017年5月,是一家专注美好食物的创业公司。叮咚买菜专注吃的事业,为满足更多人“想吃什么”而努力,通过美好食材的供应、美好滋味的开发以及美食品牌的孵
我从Ubuntu服务器上的RVM转移到rbenv。当我使用RVM时,使用bundle没有问题。转移到rbenv后,我在Jenkins的执行shell中收到“找不到命令”错误。我内爆并删除了RVM,并从~/.bashrc'中删除了所有与RVM相关的行。使用后我仍然收到此错误:rvmimploderm~/.rvm-rfrm~/.rvmrcgeminstallbundlerecho'exportPATH="$HOME/.rbenv/bin:$PATH"'>>~/.bashrcecho'eval"$(rbenvinit-)"'>>~/.bashrc.~/.bashrcrbenvversions
前置步骤我们都操作完了,这篇开始介绍jenkins的集成。话不多说,看操作1、登录进入jenkins后会让你选择安装插件,选择第一个默认的就行。安装完成后设置账号密码,重新登录。2、配置JDK和Git都需要执行路径,所以需要先把执行路径找到,先进入服务器的docker容器,2.1JDK的路径root@69eef9ee86cf:/usr/bin#echo$JAVA_HOME/usr/local/openjdk-82.2Git的路径root@69eef9ee86cf:/#whichgit/usr/bin/git3、先配置JDK和Git。点击:ManageJenkins>>GlobalToolCon
我正在尝试使用ruby编写一个双线程客户端,一个线程从套接字读取数据并将其打印出来,另一个线程读取本地数据并将其发送到远程服务器。我发现的问题是Ruby似乎无法捕获线程内的错误,这是一个示例:#!/usr/bin/rubyThread.new{loop{$stdout.puts"hi"abc.putsefsleep1}}loop{sleep1}显然,如果我在线程外键入abc.putsef,代码将永远不会运行,因为Ruby将报告“undefinedvariableabc”。但是,如果它在一个线程内,则没有错误报告。我的问题是,如何让Ruby捕获这样的错误?或者至少,报告线程中的错误?