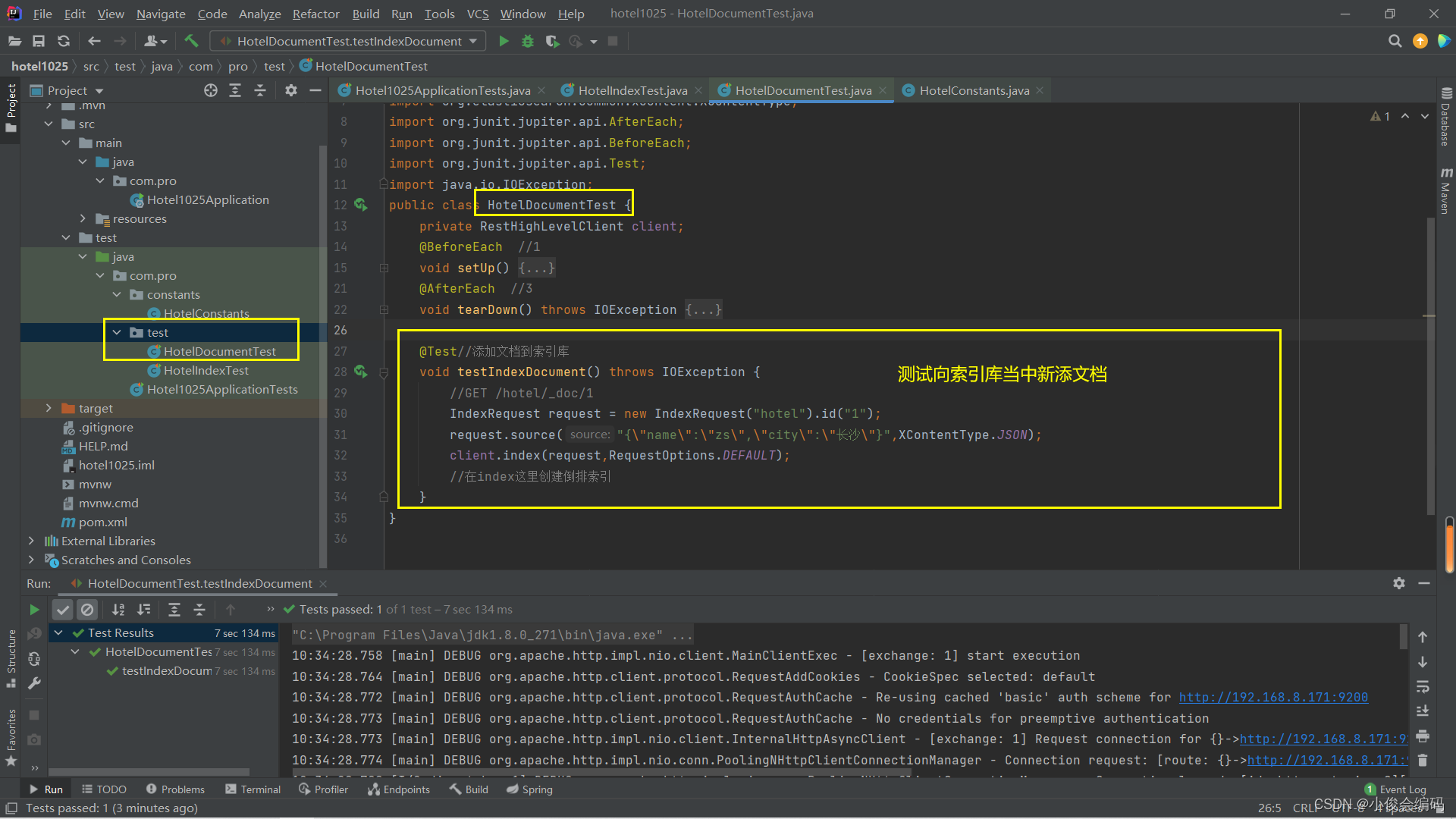
@Test//添加文档到索引库
void testIndexDocument() throws IOException {
//GET /hotel/_doc/1
IndexRequest request = new IndexRequest("hotel").id("1");
request.source("{\"name\":\"zs\",\"city\":\"长沙\"}",XContentType.JSON);
client.index(request,RequestOptions.DEFAULT);
//在index这里创建倒排索引
}@TableName("tb_hotel")
public class Hotel {
@TableId(type = IdType.AUTO)
private Long id;
private String name;
private String address;
private Integer price;
private Integer score;
private String brand;
private String city;
private String starName;
private String business;
private String latitude;
private String longitude;
private String pic;
} <!--整合mybatis-plus-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.49</version>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.0.5</version>
</dependency>
public class HotelDoc {
private Long id;
private String name;
private String address;
private Integer price;
private Integer score;
private String brand;
private String city;
private String starName;
private String business;
/*经纬度换成location*/
private String location;
private String pic;
public HotelDoc() {
}
/*构造函数*/
public HotelDoc(Hotel hotel) {
this.id = hotel.getId();
this.name = hotel.getName();
this.address = hotel.getAddress();
this.price = hotel.getPrice();
this.score = hotel.getScore();
this.brand = hotel.getBrand();
this.city = hotel.getCity();
this.starName = hotel.getStarName();
this.business = hotel.getBusiness();
/*纬度和经度*/
this.location = hotel.getLatitude()+","+hotel.getLongitude();
this.pic = hotel.getPic();
}
}
@Bean
public RestHighLevelClient client(){
return new RestHighLevelClient(
RestClient.builder(HttpHost.create("http://192.168.8.171:9200"))
);
}
#mysql
spring.datasource.driver-class-name=com.mysql.jdbc.Driver
spring.datasource.url=jdbc:mysql://192.168.8.171:3306/hotel
spring.datasource.username=root
spring.datasource.password=root
#扫描包
mybatis-plus.mapper-locations=classpath:mapper/*.xml
#别名
mybatis-plus.type-aliases-package=com.pro.domain
#驼峰
mybatis-plus.configuration.map-underscore-to-camel-case=true
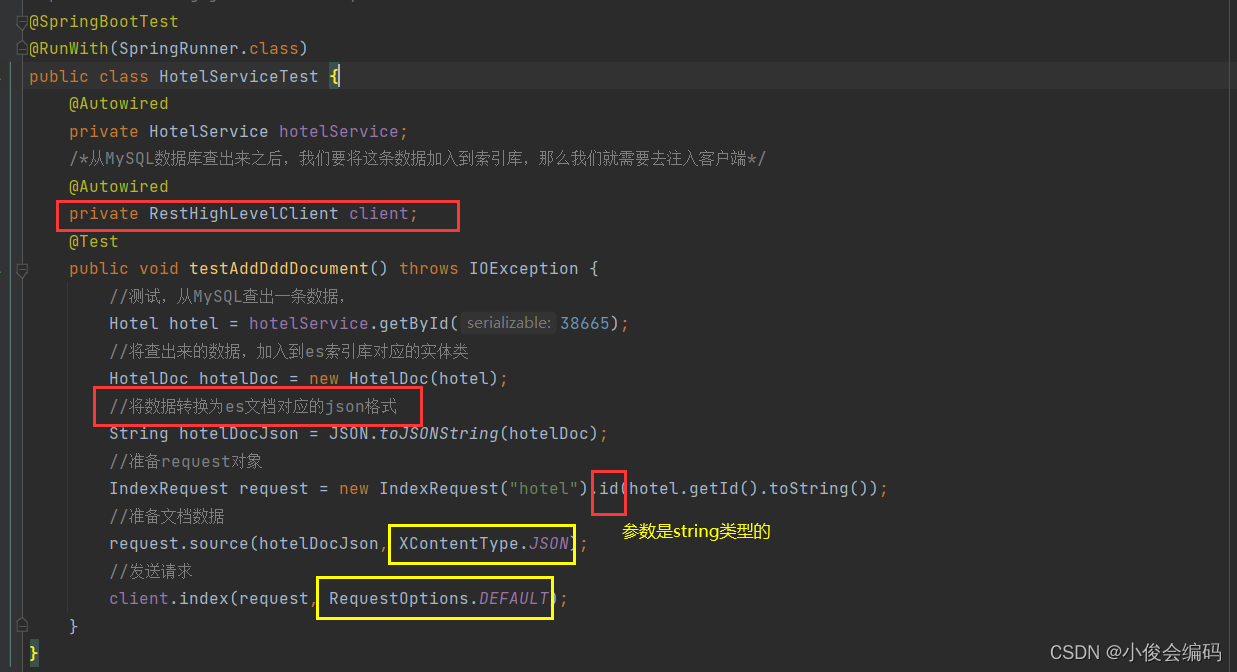
/*根据id查出索引库的文档,强转为对象输出*/
@Test
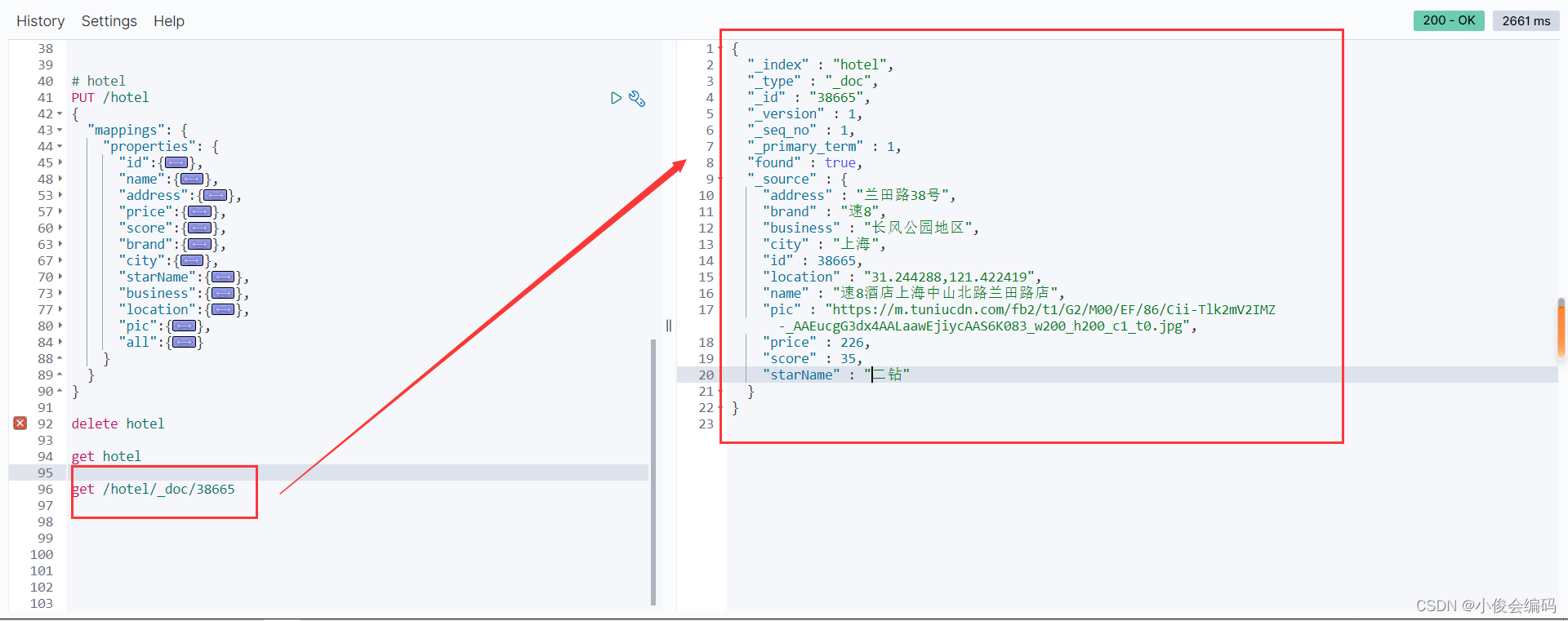
public void testGetDocumentById() throws IOException {
GetRequest request = new GetRequest("hotel", "38665");
//发请求,得到响应
GetResponse response = client.get(request, RequestOptions.DEFAULT);
String json = response.getSourceAsString();
HotelDoc hotelDoc = JSON.parseObject(json, HotelDoc.class);
System.out.println(hotelDoc);
}/*根据id修改索引库对应的文档*/
@Test
public void testUpdateDocument(){
//1.request
UpdateRequest request = new UpdateRequest("hotel", "38665");
//修改
request.doc(
"price","262",
"starName","三钻"
);
}
/*根据id删除索引库对应的文档*/
@Test
public void TestDeleteDocumentById() throws IOException {
//创建request对象
DeleteRequest request = new DeleteRequest("hotel", "38665");
//删除文档
client.delete(request,RequestOptions.DEFAULT);
}
/*将MySQL查出来的所有记录加到索引库
* 批量操作
* */
@Test
public void testBulkRequest() throws IOException {
QueryWrapper queryWrapper = new QueryWrapper();
List<Hotel> hotelList = hotelService.list(queryWrapper);
BulkRequest request = new BulkRequest();
for (Hotel hotel : hotelList) {
HotelDoc hotelDoc = new HotelDoc(hotel);
//将数据对象,一个个转为json,加入到批量操作的对象request中
request.add(new IndexRequest("hotel")
.id(hotelDoc.getId().toString())
.source(JSON.toJSONString(hotelDoc),XContentType.JSON));
}
//发送请求
client.bulk(request,RequestOptions.DEFAULT);
}https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl.htmlhttps://www.kancloud.cn/apachecn/elasticsearch-doc-zh/1945172select * from class;
select * from stu;
select * from stu where classid = 1;
-- in 条件可以是一个或多个--
select * from stu where classid in (1);
select * from stu where classid in (1,2);
select * from stu where classid = (select classid from class where classname='1班');
-- 五个聚合函数 --
select count(*) from stu;
select avg(age) from stu;
select sum(age) from stu;
select max(age) from stu;
select min(age) from stu;
-- 分组查询 select 后面只能跟分组的字段,聚合函数--
select classid,avg(age) from stu GROUP BY classid;
-- 对所有记录筛选 --
select * from stu where age < 20;
-- 对组进行筛选,使用having,后面只能跟分组的字段,聚合函数 --
select classid,avg(age) from stu GROUP BY classid having avg(age) > 21;
-- 温哥华 --
select classid,avg(age) from stu where gender = '男' GROUP BY classid having avg(age) > 21;
select * from stu,class;
select * from stu,class where stu.classid=class.classid and stu.stuid=1;
-- 内连接 两边协商,没有的去取消,查出5条数据 --
select * from stu s inner join class c on s.classid=c.classid;
-- 左连接,以左为主,可以查6条数据 --
select * from stu s left join class c on s.classid=c.classid;
-- 右连接,以右为主,可以查5条数据 --
select * from stu s right join class c on s.classid=c.classid;
#查询dsl的语法
GET /hotel/_search
{
"query":{
"查询类型":{
"FIELD":"TEXT"
}
}
}
#查所有
GET /hotel/_search
{
"query":{
"match_all":{}
}
}#match查询,会对用户的输入分词,再到索引库检索
GET /hotel/_search
{
"query":{
"match":{
"all":"深圳如家"
}
}
}
#允许多个字段搜 ,字段越多,查询性能越差
GET /hotel/_search
{
"query":{
"multi_match":{
"query":"深圳如家",
"fields": ["brand","name","business"]
}
}
}
#上面这两种查询结果是一样的,因为这三个字段我们已经copy_to all里面了,所以第一种显然要好些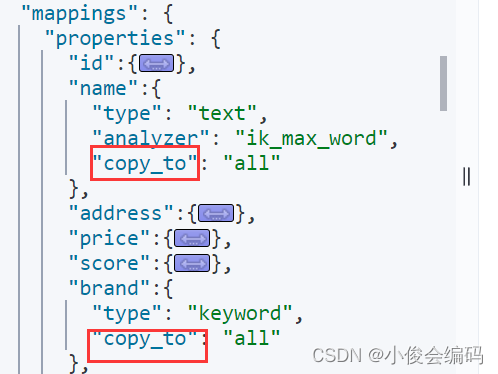
#精准查询 term 特点:不分词
GET /hotel/_search
{
"query":{
"term":{
"city":{
"value": "上海"
}
}
}
}#范围内精准查询 range 特点:不分词
GET /hotel/_search
{
"query": {
"range": {
"price": {
"gte": 100,
"lte": 300
}
}
}
}
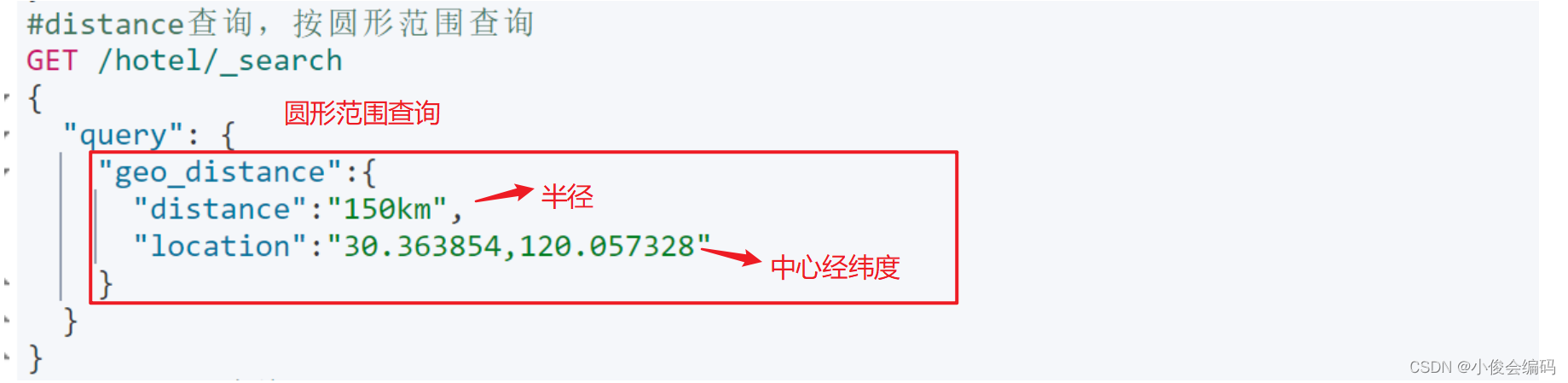
#地理查询,经纬度查询:
#geo_distance: 圆形范围
GET /hotel/_search
{
"query":{
"geo_distance":{
"distance":"150km",
"location":"31.174377,121.442875"
}
}
}
geo_bounding_box矩形范围:lat纬度,lon经度
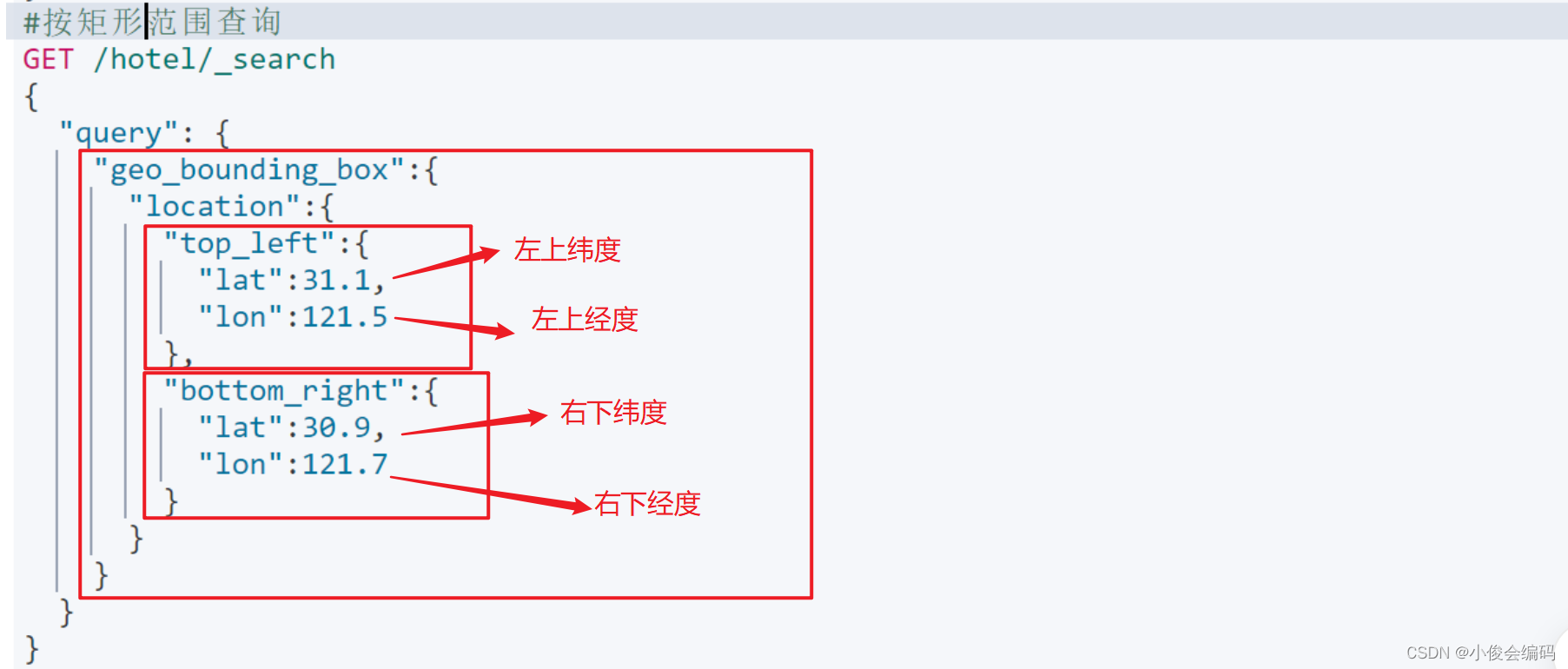
#geo_bounding_box矩形范围:lat纬度,lon经度
GET /hotel/_search
{
"query":{
"geo_bounding_box":{
"location":{
"top_left":{
"lat":31.1,
"lon":121.5
},
"bottom_right":{
"lat":30.9,
"lon":121.7
}
}
}
}
}#复合查询
将简单的查询组合起来
算分函数查询,function score ,可以控制文档相关性算分,
控制文档排名
1)function score
先查所有all里面分词有外滩的文档,然后再过滤出brand为如家的品牌(精准过滤),最后对对应文档的_score进行操作
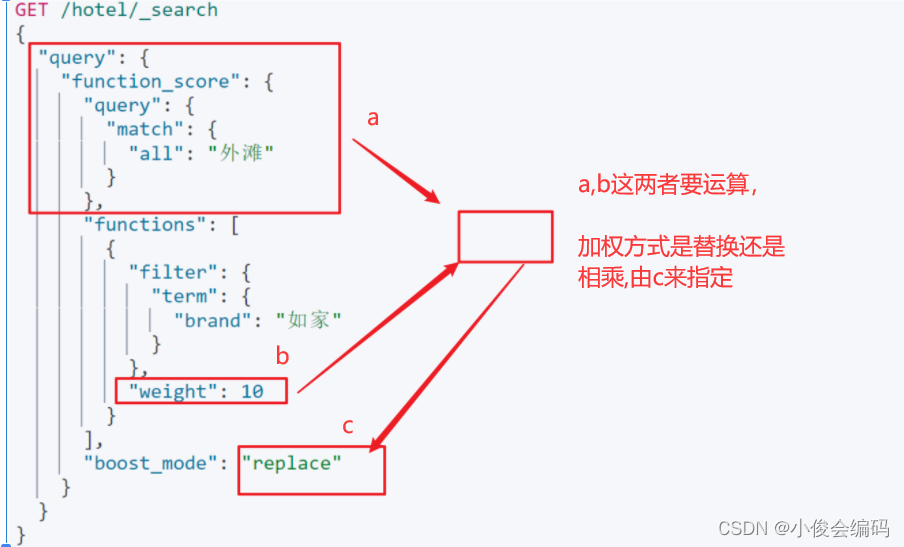
其它 :sum,avg,max,min
#1)function score先查所有all里面分词有外滩的文档,
然后再过滤出brand为如家的品牌(精准过滤),最后对对应文档的_score进行操作
GET /hotel/_search
{
"query":{
"function_score": {
"query": {
"match":{
"all":"外滩"
}
},
"functions": [
{
"filter": {
"term":{
"brand": "如家"
}
},
"weight":10
}
],
"boost_mode": "replace"
}
}
}#搜索如家,价格小于等于400,坐标在31.2,121.5周围十公里范围内的酒店
GET /hotel/_search
{
"query":{
"bool": {
"must": [
{
"match": {
"FIELD": "如家"
}
}
],
"must_not": [
{
"range": {
"FIELD": {
"gte": 400
}
}
}
],
"filter": [
{
"geo_distance":{
"distance":"10km",
"location":{
"lat":31.21,
"lon":121.5
}
}
}
]
}
}
}
}
- #排序,根据评分降序
GET /hotel/_search
{
"query":{
"match_all": {}
},
"sort":[
{
"score":{
"order":"desc"
}
}
]
}
- #按坐标排序
GET /hotel/_search
{
"query":{
"match_all": {}
},
"sort":[
{
"_geo_distance": {
"location": "31.21,121.5",
"order": "desc",
"unit": "km"
}
}
]
}
- #按分值排序,分值一致时,按价格升序
GET /hotel/_search
{
"query":{
"match_all": {}
},
"sort":[
{
"score":{
"order": "desc"
},
"price": {
"order": "asc"
}
}
]
}
- #按某坐标,周围的酒店,距离降序排序
#查询的sort的值,是公里数
#注意,如果排序,则打分为null
GET /hotel/_search
{
"query":{
"match_all": {}
},
"sort":[
{
"_geo_distance": {
"location": {
"lat": 30,
"lon": 120
},
"order": "desc",
"unit": "km"
}
}
]
}
- #分页
#es 默认的返回10条,from,size,我们现在分20条
GET /hotel/_search
{
"query":{
"match_all": {}
},
"from": 0,
"size": 20,
"sort":[
{
"price": {
"order": "asc"
}
}
]
}
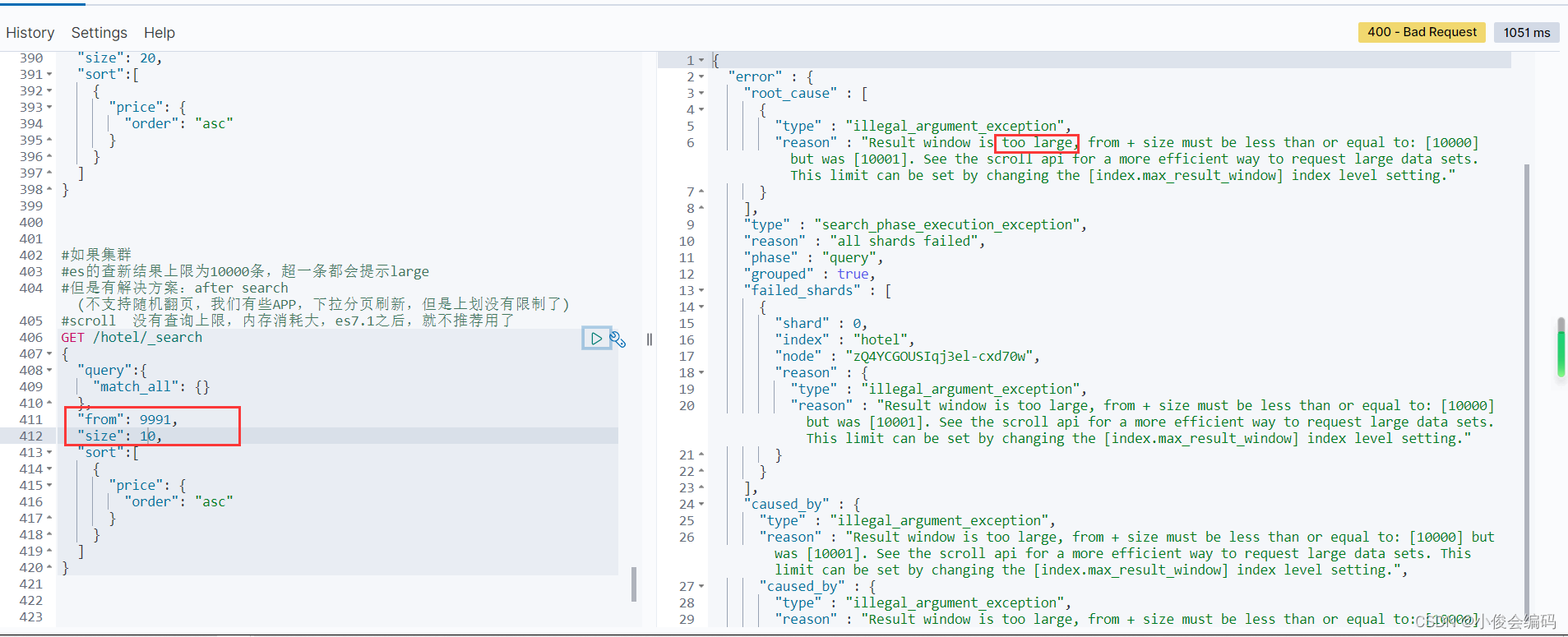
#练习:搜索:价格在220以内的酒店
#按从小到大升序排列
#取前五个酒店
GET /hotel/_search
{
"query": {
"range": {
"price": {
"lte": 220
}
}
},
"from": 0,
"size": 5,
"sort": [
{
"price": {
"order": "asc"
}
}
]
}
#高亮,require_field_match表示:是否匹配搜索字段和高亮字段
GET /hotel/_search
{
"query":{
"match":{
"all":"如家"
}
},
"highlight": {
"fields": {
"name": {"require_field_match": "false"}
}
}
}
我正在用Ruby编写一个简单的程序来检查域列表是否被占用。基本上它循环遍历列表,并使用以下函数进行检查。require'rubygems'require'whois'defcheck_domain(domain)c=Whois::Client.newc.query("google.com").available?end程序不断出错(即使我在google.com中进行硬编码),并打印以下消息。鉴于该程序非常简单,我已经没有什么想法了-有什么建议吗?/Library/Ruby/Gems/1.8/gems/whois-2.0.2/lib/whois/server/adapters/base.
大约一年前,我决定确保每个包含非唯一文本的Flash通知都将从模块中的方法中获取文本。我这样做的最初原因是为了避免一遍又一遍地输入相同的字符串。如果我想更改措辞,我可以在一个地方轻松完成,而且一遍又一遍地重复同一件事而出现拼写错误的可能性也会降低。我最终得到的是这样的:moduleMessagesdefformat_error_messages(errors)errors.map{|attribute,message|"Error:#{attribute.to_s.titleize}#{message}."}enddeferror_message_could_not_find(obje
我知道我可以指定某些字段来使用pluck查询数据库。ids=Item.where('due_at但是我想知道,是否有一种方法可以指定我想避免从数据库查询的某些字段。某种反拔?posts=Post.where(published:true).do_not_lookup(:enormous_field) 最佳答案 Model#attribute_names应该返回列/属性数组。您可以排除其中一些并传递给pluck或select方法。像这样:posts=Post.where(published:true).select(Post.attr
我正在尝试找出如何为我的Ruby项目创建一种“无类DSL”,类似于在Cucumber步骤定义文件中定义步骤定义或在Sinatra应用程序中定义路由。例如,我想要一个文件,其中调用了我的所有DSL函数:#sample.rbwhen_string_matches/hello(.+)/do|name|call_another_method(name)end我认为用我的项目特有的一堆方法污染全局(内核)命名空间是一种不好的做法。因此方法when_string_matches和call_another_method将在我的库中定义,并且sample.rb文件将以某种方式在我的DSL方法的上下文中
文章目录一、概述简介原理模块二、配置Mysql使用版本环境要求1.操作系统2.mysql要求三、配置canal-server离线下载在线下载上传解压修改配置单机配置集群配置分库分表配置1.修改全局配置2.实例配置垂直分库水平分库3.修改group-instance.xml4.启动监听四、配置canal-adapter1修改启动配置2配置映射文件3启动ES数据同步查询所有订阅同步数据同步开关启动4.验证五、配置canal-admin一、概述简介canal是Alibaba旗下的一款开源项目,Java开发。基于数据库增量日志解析,提供增量数据订阅&消费。Git地址:https://github.co
ES一、简介1、ElasticStackES技术栈:ElasticSearch:存数据+搜索;QL;Kibana:Web可视化平台,分析。LogStash:日志收集,Log4j:产生日志;log.info(xxx)。。。。使用场景:metrics:指标监控…2、基本概念Index(索引)动词:保存(插入)名词:类似MySQL数据库,给数据Type(类型)已废弃,以前类似MySQL的表现在用索引对数据分类Document(文档)真正要保存的一个JSON数据{name:"tcx"}二、入门实战{"name":"DESKTOP-1TSVGKG","cluster_name":"elasticsear
我正在尝试查询我的Rails数据库(Postgres)中的购买表,我想查询时间范围。例如,我想知道在所有日期的下午2点到3点之间进行了多少次购买。此表中有一个created_at列,但我不知道如何在不搜索特定日期的情况下完成此操作。我试过:Purchases.where("created_atBETWEEN?and?",Time.now-1.hour,Time.now)但这最终只会搜索今天与那些时间的日期。 最佳答案 您需要使用PostgreSQL'sdate_part/extractfunction从created_at中提取小时
我有一个使用SeleniumWebdriver和Nokogiri的Ruby应用程序。我想选择一个类,然后对于那个类对应的每个div,我想根据div的内容执行一个Action。例如,我正在解析以下页面:https://www.google.com/webhp?sourceid=chrome-instant&ion=1&espv=2&ie=UTF-8#q=puppies这是一个搜索结果页面,我正在寻找描述中包含“Adoption”一词的第一个结果。因此机器人应该寻找带有className:"result"的div,对于每个检查它的.descriptiondiv是否包含单词“adoption
我正在我的Rails项目中安装Grape以构建RESTfulAPI。现在一些端点的操作需要身份验证,而另一些则不需要身份验证。例如,我有users端点,看起来像这样:moduleBackendmoduleV1classUsers现在如您所见,除了password/forget之外的所有操作都需要用户登录/验证。创建一个新的端点也没有意义,比如passwords并且只是删除password/forget从逻辑上讲,这个端点应该与用户资源。问题是Grapebefore过滤器没有像except,only这样的选项,我可以在其中说对某些操作应用过滤器。您通常如何干净利落地处理这种情况?
在我做的一些网络开发中,我有多个操作开始,比如对外部API的GET请求,我希望它们同时开始,因为一个不依赖另一个的结果。我希望事情能够在后台运行。我找到了concurrent-rubylibrary这似乎运作良好。通过将其混合到您创建的类中,该类的方法具有在后台线程上运行的异步版本。这导致我编写如下代码,其中FirstAsyncWorker和SecondAsyncWorker是我编写的类,我在其中混合了Concurrent::Async模块,并编写了一个名为“work”的方法来发送HTTP请求:defindexop1_result=FirstAsyncWorker.new.async.