
🚀write in front🚀
📜所属专栏: 初阶数据结构
🛰️博客主页:睿睿的博客主页
🛰️代码仓库:🎉VS2022_C语言仓库
🎡您的点赞、关注、收藏、评论,是对我最大的激励和支持!!!
关注我,关注我,关注我,你们将会看到更多的优质内容!!

在学完了顺序表的基本知识后,我们可以通过一些习题来巩固所学知识!
删除链表中等于给定值 val 的所有结点。oj链接
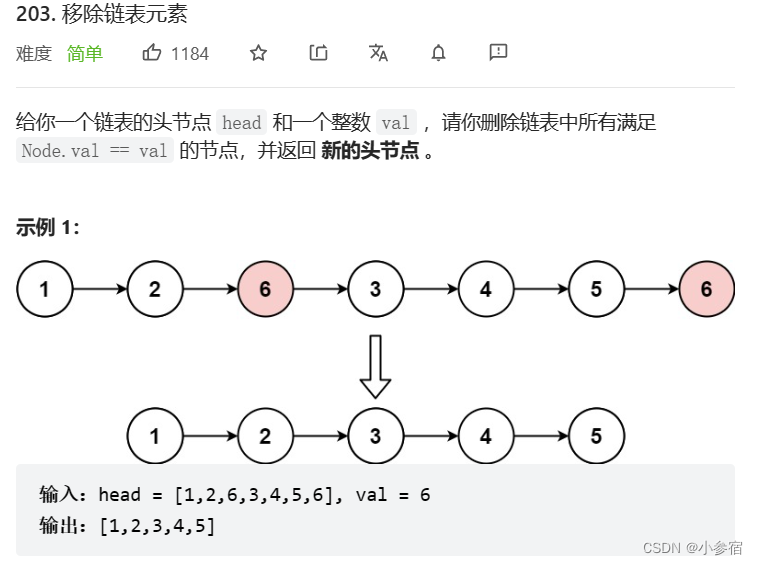
这道题目有两种做法:
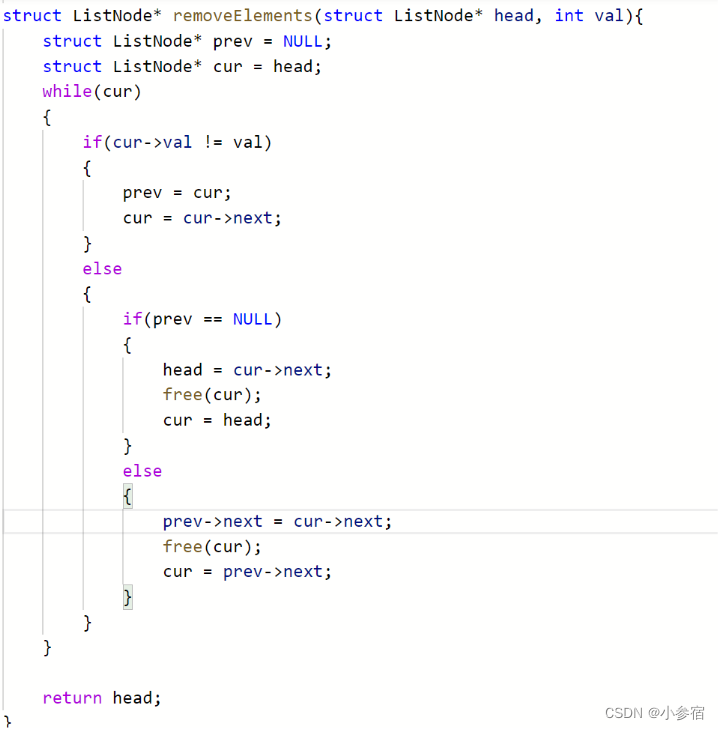
struct ListNode* removeElements(struct ListNode* head, int val)
{
struct ListNode*cur=head,*newnode=NULL,*tail=NULL;
while(cur)
{
if(cur->val!=val)
{
if(newnode==NULL)
{
newnode=cur;
tail=cur;
}
else
{
tail->next=cur;
tail=tail->next;
}
cur=cur->next;
}
else
{
struct ListNode*next=cur;
cur=next->next;
free(next);
}
}
if(tail)
{
tail->next=NULL;
}
return newnode;
}
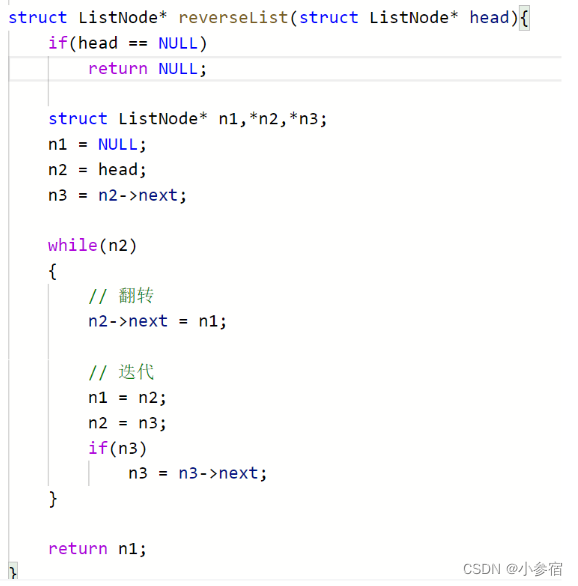
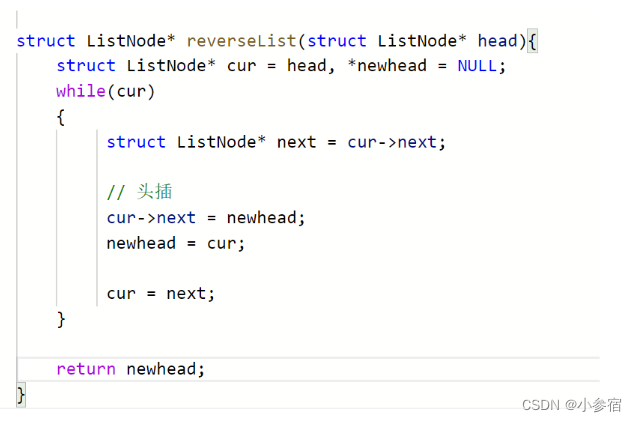
反转一个单链表。oj链接
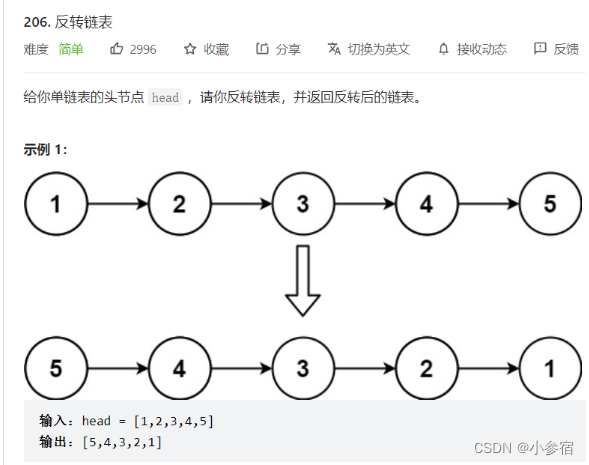
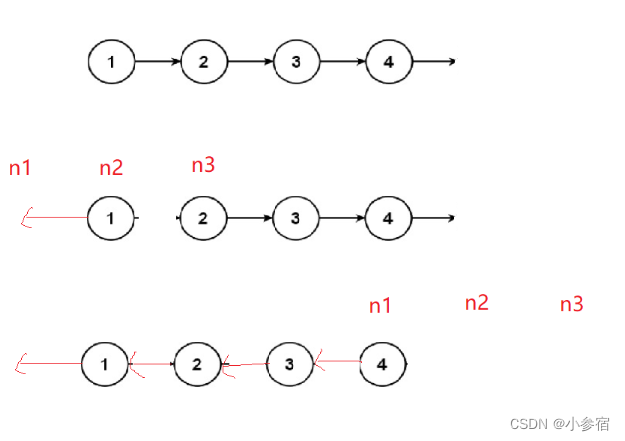
这道题也有两种方法,
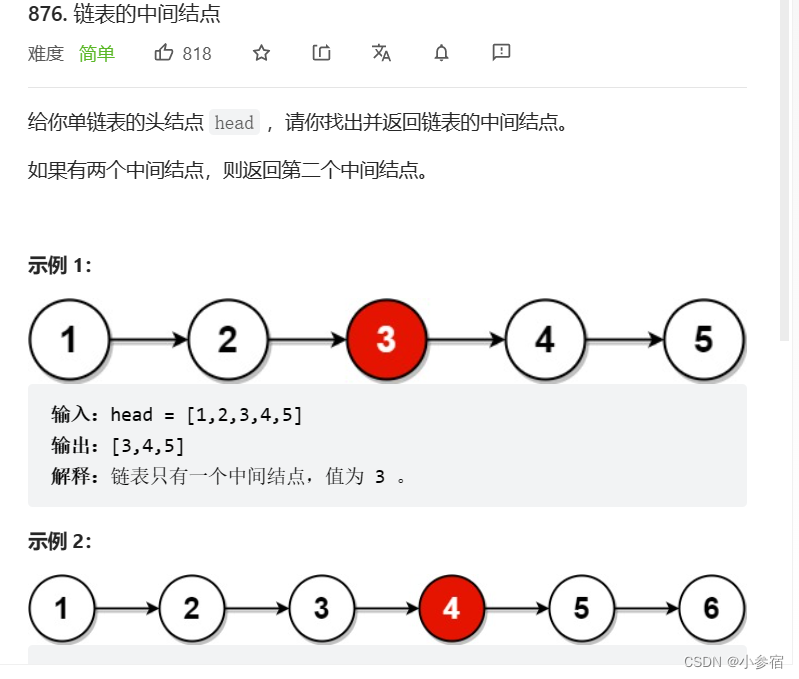
给定一个带有头结点 head 的非空单链表,返回链表的中间结点。如果有两个中间结点,则返回第二个中间结点。oj链接
这里我们就要介绍一下快慢指针了。通过快慢指针我们可以解决很多问题,以后都会用到。
那么什么是快慢指针呢?
顾名思义,快慢指针就是通过两个不同指针步长的不同来遍历链表。
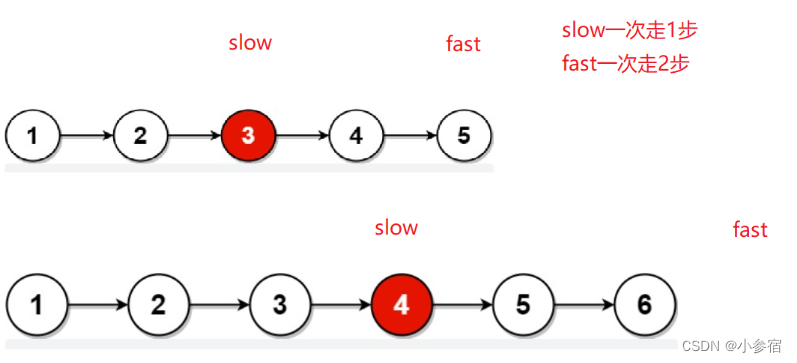
这道题我们让一个指针走两步,一个指针走一步,当快指针指向空或快指针的next指向空的时候,慢指针指向位置就是中间节点位置。
struct ListNode* middleNode(struct ListNode* head)
{
struct ListNode*slow=head,*fast=head;
while(fast!=NULL&&fast->next!=NULL)
{
slow=slow->next;
fast=fast->next->next;
}
return slow;
}
输入一个链表,输出该链表中倒数第k个结点。oj链接
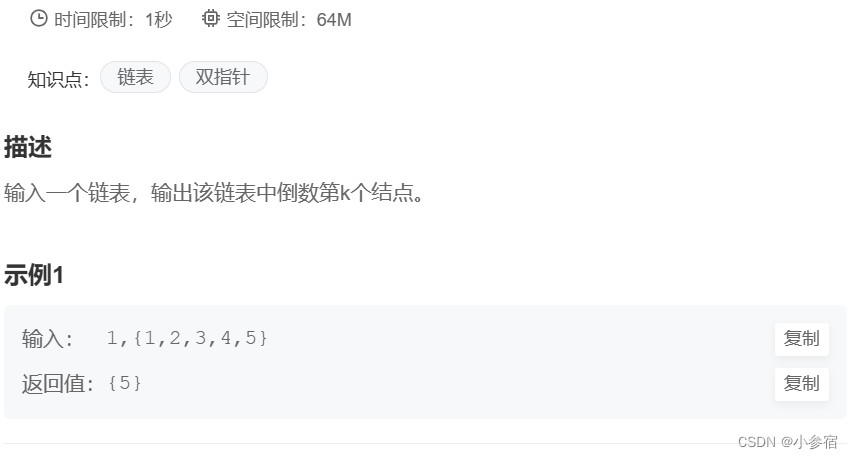
其实也是快慢指针的思想,只是这里不是步长的不同,而是起点不同:
要寻找倒数第k个节点,就让快指针的起点在慢指针的后k步。当快指针指向空的时候,慢指针就指向倒数第k个节点。
struct ListNode* FindKthToTail(struct ListNode* pListHead, int k ) {
// write code here
struct ListNode* slow=pListHead;
struct ListNode* fast=pListHead;
while(k--)
{
if(fast==NULL)
{
return NULL;
}
fast=fast->next;
}
while(fast)
{
fast=fast->next;
slow=slow->next;
}
return slow;
}
给定一个链表,判断链表中是否有环。oj链接
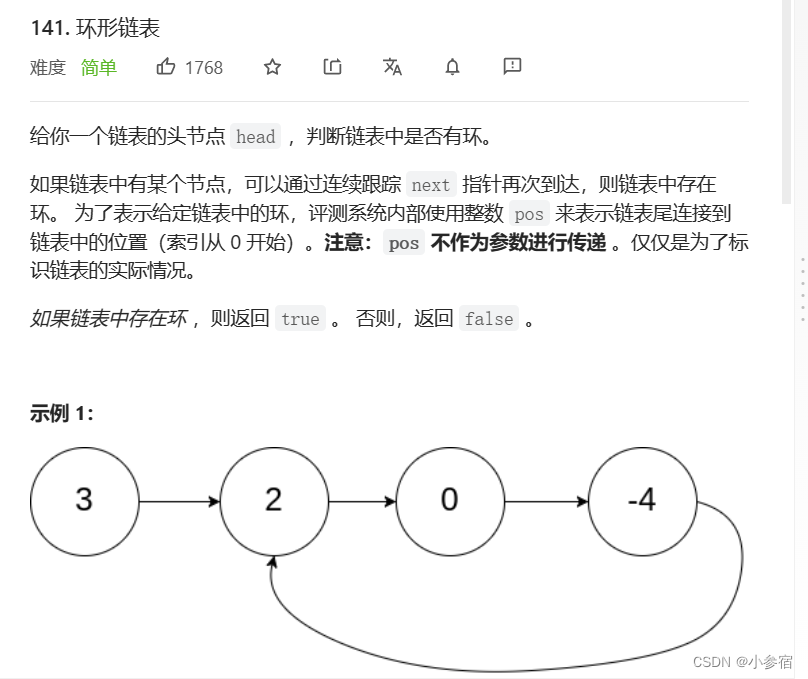
这道题也是用快慢指针,即慢指针一次走一步,快指针一次走两步,两个指针从链表起始位置开始运行,如果链表带环则一定会在环中相遇,否则快指针率先走到链表的末尾。比如:陪女朋友到操作跑步减肥。
那么,为什么快指针每次走两步,慢指针走一步可以?
假设链表带环,两个指针最后都会进入环,快指针先进环,慢指针后进环。
此时,两个指针每移动一次,之间的距离就缩小一步,不会出现每次刚好是套圈的情况,因此:在满指针走到一圈之前,快指针肯定是可以追上慢指针的,即相遇。
代码如下:
bool hasCycle(struct ListNode *head)
{
struct ListNode*fast=head,*slow=head;
if(head==NULL||head->next==NULL)
{
return false;
}
fast=fast->next;
while(fast!=slow)
{
if(fast==NULL||fast->next==NULL)
break;
fast=fast->next->next;
slow=slow->next;
}
if(fast==slow)
return true;
return false;
}
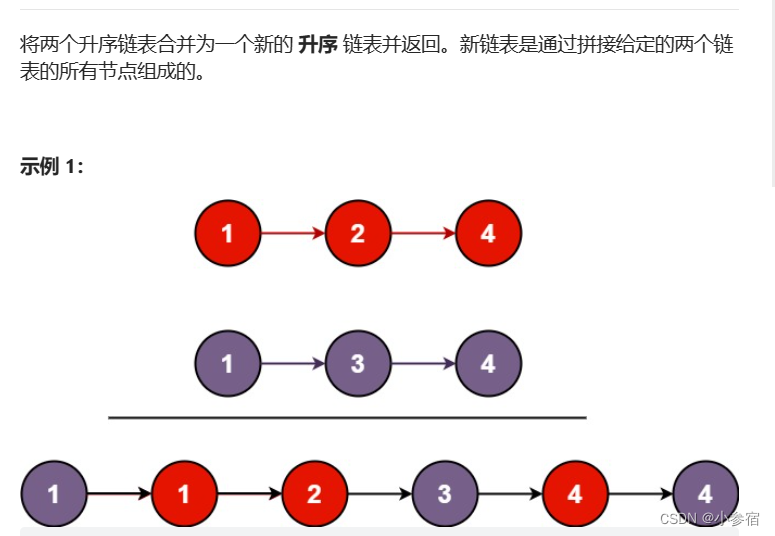
将两个有序链表合并为一个新的有序链表并返回。新链表是通过拼接给定的两个链表的所有结点组成的oj链表
这道题引入了哨兵位,也就是空的头节点。其实,对于链表尾插的时候,需要判断是否为空,比较麻烦,只要我们创建一个空的头节点就可以避免很多情况。
链表在头插的时候我们不需要头节点;
链表在尾插的有空的头节点会更方便。
struct ListNode* mergeTwoLists(struct ListNode* list1, struct ListNode* list2)
{
struct ListNode*newnode=(struct ListNode*)malloc(sizeof(struct ListNode));
struct ListNode*tail=newnode;
tail->next=NULL;
while(list1&&list2)
{
if(list1->val<list2->val)
{
tail->next=list1;
tail=list1;
list1=list1->next;
}
else
{
tail->next=list2;
tail=list2;
list2=list2->next;
}
}
if(list1)
tail->next=list1;
if(list2)
tail->next=list2;
return newnode->next;
}
编写代码,以给定值x为基准将链表分割成两部分,所有小于x的结点排在大于或等于x的结点之前 。oj链接

这道题我们创建两个新链表(带有哨兵位的空头节点),小于的尾插到一个链表,大于的尾插到另外一个链表,最后将他们连起来即可。
class Partition {
public:
ListNode* partition(ListNode* pHead, int x)
{
// write code here
struct ListNode*greaternode=NULL;
struct ListNode*lessnode=NULL,*cur=pHead;
struct ListNode* gtail=greaternode,*ltail=lessnode;
while(cur!=NULL)
{
if(cur->val>=x)
{
gtail->next=cur;
gtail=cur;
cur=cur->next;
gtail->next=NULL;
}
else
{
ltail->next=cur;
ltail=cur;
cur=cur->next;
ltail->next=NULL;
}
}
ltail->next=greaternode->next;
return lessnode->next;
}
};
还是那句话,数据结构需要多画图,并且对各种情况要有十足的把握才能做对题目。
更新不易,辛苦各位小伙伴们动动小手,👍三连走一走💕💕 ~ ~ ~ 你们真的对我很重要!最后,本文仍有许多不足之处,欢迎各位认真读完文章的小伙伴们随时私信交流、批评指正!
专栏订阅:
每日一题
c语言学习
算法
智力题
初阶数据结构
更新不易,辛苦各位小伙伴们动动小手,👍三连走一走💕💕 ~ ~ ~ 你们真的对我很重要!最后,本文仍有许多不足之处,欢迎各位认真读完文章的小伙伴们随时私信交流、批评指正!

我想将html转换为纯文本。不过,我不想只删除标签,我想智能地保留尽可能多的格式。为插入换行符标签,检测段落并格式化它们等。输入非常简单,通常是格式良好的html(不是整个文档,只是一堆内容,通常没有anchor或图像)。我可以将几个正则表达式放在一起,让我达到80%,但我认为可能有一些现有的解决方案更智能。 最佳答案 首先,不要尝试为此使用正则表达式。很有可能你会想出一个脆弱/脆弱的解决方案,它会随着HTML的变化而崩溃,或者很难管理和维护。您可以使用Nokogiri快速解析HTML并提取文本:require'nokogiri'h
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
我正在尝试从Postgresql表(table1)中获取数据,该表由另一个相关表(property)的字段(table2)过滤。在纯SQL中,我会这样编写查询:SELECT*FROMtable1JOINtable2USING(table2_id)WHEREtable2.propertyLIKE'query%'这工作正常:scope:my_scope,->(query){includes(:table2).where("table2.property":query)}但我真正需要的是使用LIKE运算符进行过滤,而不是严格相等。然而,这是行不通的:scope:my_scope,->(que
有没有办法在这个简单的get方法中添加超时选项?我正在使用法拉第3.3。Faraday.get(url)四处寻找,我只能先发起连接后应用超时选项,然后应用超时选项。或者有什么简单的方法?这就是我现在正在做的:conn=Faraday.newresponse=conn.getdo|req|req.urlurlreq.options.timeout=2#2secondsend 最佳答案 试试这个:conn=Faraday.newdo|conn|conn.options.timeout=20endresponse=conn.get(url
有时我需要处理键/值数据。我不喜欢使用数组,因为它们在大小上没有限制(很容易不小心添加超过2个项目,而且您最终需要稍后验证大小)。此外,0和1的索引变成了魔数(MagicNumber),并且在传达含义方面做得很差(“当我说0时,我的意思是head...”)。散列也不合适,因为可能会不小心添加额外的条目。我写了下面的类来解决这个问题:classPairattr_accessor:head,:taildefinitialize(h,t)@head,@tail=h,tendend它工作得很好并且解决了问题,但我很想知道:Ruby标准库是否已经带有这样一个类? 最佳
我想在Ruby中创建一个用于开发目的的极其简单的Web服务器(不,不想使用现成的解决方案)。代码如下:#!/usr/bin/rubyrequire'socket'server=TCPServer.new('127.0.0.1',8080)whileconnection=server.acceptheaders=[]length=0whileline=connection.getsheaders想法是从命令行运行这个脚本,提供另一个脚本,它将在其标准输入上获取请求,并在其标准输出上返回完整的响应。到目前为止一切顺利,但事实证明这真的很脆弱,因为它在第二个请求上中断并出现错误:/usr/b
我意识到这可能是一个非常基本的问题,但我现在已经花了几天时间回过头来解决这个问题,但出于某种原因,Google就是没有帮助我。(我认为部分问题在于我是一个初学者,我不知道该问什么......)我也看过O'Reilly的RubyCookbook和RailsAPI,但我仍然停留在这个问题上.我找到了一些关于多态关系的信息,但它似乎不是我需要的(尽管如果我错了请告诉我)。我正在尝试调整MichaelHartl'stutorial创建一个包含用户、文章和评论的博客应用程序(不使用脚手架)。我希望评论既属于用户又属于文章。我的主要问题是:我不知道如何将当前文章的ID放入评论Controller。
给定一个复杂的对象层次结构,幸运的是它不包含循环引用,我如何实现支持各种格式的序列化?我不是来讨论实际实现的。相反,我正在寻找可能会派上用场的设计模式提示。更准确地说:我正在使用Ruby,我想解析XML和JSON数据以构建复杂的对象层次结构。此外,应该可以将该层次结构序列化为JSON、XML和可能的HTML。我可以为此使用Builder模式吗?在任何提到的情况下,我都有某种结构化数据-无论是在内存中还是文本中-我想用它来构建其他东西。我认为将序列化逻辑与实际业务逻辑分开会很好,这样我以后就可以轻松支持多种XML格式。 最佳答案 我最
我正在尝试使用Curbgem执行以下POST以解析云curl-XPOST\-H"X-Parse-Application-Id:PARSE_APP_ID"\-H"X-Parse-REST-API-Key:PARSE_API_KEY"\-H"Content-Type:image/jpeg"\--data-binary'@myPicture.jpg'\https://api.parse.com/1/files/pic.jpg用这个:curl=Curl::Easy.new("https://api.parse.com/1/files/lion.jpg")curl.multipart_form_
无论您是想搭建桌面端、WEB端或者移动端APP应用,HOOPSPlatform组件都可以为您提供弹性的3D集成架构,同时,由工业领域3D技术专家组成的HOOPS技术团队也能为您提供技术支持服务。如果您的客户期望有一种在多个平台(桌面/WEB/APP,而且某些客户端是“瘦”客户端)快速、方便地将数据接入到3D应用系统的解决方案,并且当访问数据时,在各个平台上的性能和用户体验保持一致,HOOPSPlatform将帮助您完成。利用HOOPSPlatform,您可以开发在任何环境下的3D基础应用架构。HOOPSPlatform可以帮您打造3D创新型产品,HOOPSSDK包含的技术有:快速且准确的CAD