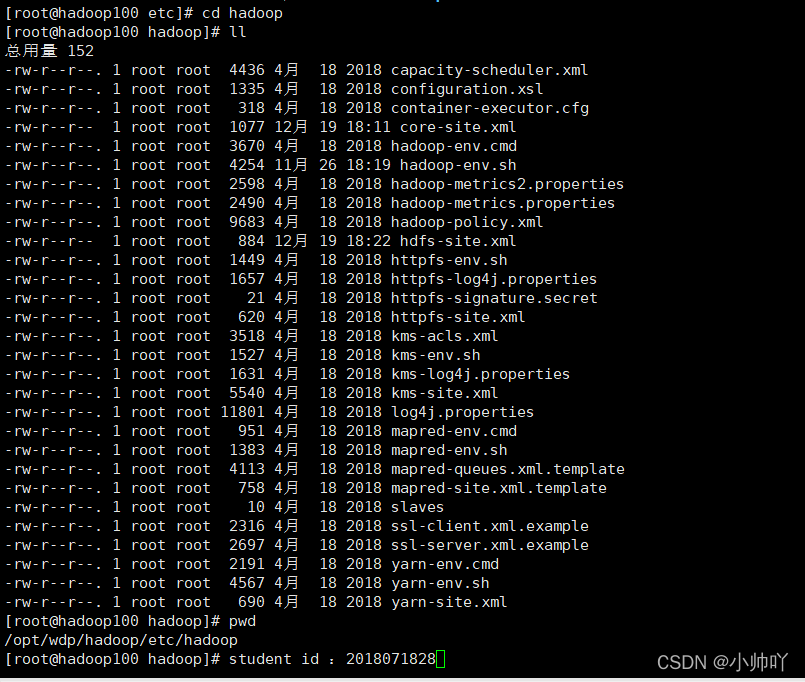
上节课主要是完成了Hadoop的安装,这次主要完成以下内容
配置HDFS
web端查看HDFS文件系统
配置yarn
web端查看yarn系统
配置mapreduce
运行MapReduce的WordCount 程序
上次课完成到如下图的状态

还需要改善一下,就是我们在root用户下解压安装他的拥有者是数字不是root
通过chown命令更改一下拥有者
chown -R root:root /opt/wdp

运行一下hadoop命令有如下提示说明hadoop可以用

Hadoop运行模式
(1)本地模式(默认模式):是否启动进程----没有,在几台机器上安装的—1台,
不需要启用单独进程,直接可以运行,测试和开发时使用。
(2)伪分布式模式:是否启动进程----需要,在几台机器上安装的—1台
等同于完全分布式,只有一个节点。
(3)完全分布式模式:是否启动进程----需要,在几台机器上安装的—多台
多个节点一起运行。
HDFS是什么
HDFS(Hadoop Distributed File System),它是一个文件系统,用于存储文件,通过目录树来定位文件;其次,它是分布式的,由很多服务器联合起来实现其功能,集群中的服务器有各自的角色。
HDFS的设计适合一次写入,多次读出的场景,且不支持文件的修改。适合用来做数据分析,并不适合用来做网盘应用。
我们用HDFS而不是本地存储因为HDFS是分布式存储,你一个人的主机往往存储量很有限

一个namenode管多个datanode,每个datanode里面有多个block,每个block大小为128M
这种架构主要由四个部分组成,分别为 HDFS Client、 NameNode、 DataNode 和 SecondaryNameNode。下面我们分别介绍这四个组成部分。
1)Client:就是客户端。
(1)文件切分。文件上传 HDFS 的时候, Client 将文件切分成一个一个的 Block,然后进行存储。
(2)与 NameNode 交互,获取文件的位置信息。
(3)与 DataNode 交互,读取或者写入数据。
(4) Client 提供一些命令来管理 HDFS,比如启动或者关闭 HDFS。
(5) Client 可以通过一些命令来访问 HDFS。
2)NameNode:就是master,它是一个主管、管理者。
(1)管理 HDFS 的名称空间。
(2)管理数据块(Block)映射信息
(3)配置副本策略
(4)处理客户端读写请求。
3)DataNode:就是 Slave。 NameNode 下达命令, DataNode 执行实际的操作。
(1)存储实际的数据块。
(2)执行数据块的读/写操作。
4)Secondary NameNode:并非 NameNode 的热备。当 NameNode 挂掉的时候,它并不能马上替换 NameNode 并提供服务。
(1)辅助 NameNode,分担其工作量。
(2)定期合并 Fsimage 和 Edits,并推送给 NameNode。
(3)在紧急情况下,可辅助恢复 NameNode。
在wdp文件夹下新建一个datain文件夹
在datain文件夹下新建一个aa.txt文件

然后vi命令进入aa.txt文件
按i进入编辑模式,然后输入以下内容,注意以Tab键分隔
输入完成后Esc+:+wq保存离开

(一个小技巧,按下Esc键后,yy复制,p粘贴)
然后进入到hadoop路径下

bin,sbin文件夹与启动有关
etc文件夹与环境有关
lib文件夹是库
share文件夹下的hadoop下的mapreduce下有我们要用的demo

运行下面这个命令
hadoop jar hadoop-mapreduce-examples-2.7.6.jar wordcount /opt/wdp/datain/aa.txt /opt/wdp/dataout

首先起map和reduce

由于文件很小一共18个词是所以map和reduce都很快完成


通过上图箭头指示表示计算成功

红色箭头所指文件中保存了计算结果
cat命令查看文件内容会看到不同字符串出现次数
在本地模式的基础上配置HDFS伪分布式
(1)配置集群
(a)配置:hadoop-env.sh
上节课已完成
(b)配置:core-site.xml

进入上图路径

vi命令进入箭头所指文件,在configuration中插入下面内容
<!-- 指定HDFS中NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop100:9000</value>
</property>
<!-- 指定hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/wdp/hadoop/data/tmp</value>
</property>

注意箭头所指为自己的主机名
(c)配置:hdfs-site.xml
步骤同上
<!-- 指定HDFS副本的数量 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>

(2)启动集群
(a)格式化namenode(第一次启动时格式化,以后就不要总格式化)只在第一台机器里格式化
hdfs namenode -format


如上图箭头说明格式化成功
(b)启动namenode
hadoop-daemon.sh start namenode
(c)启动datanode
hadoop-daemon.sh start datanode
或者用下面一条命令代替(b)与(c)
start-dfs.sh

输入三轮yes与密码
(3)查看集群
(a)查看是否启动成功
输入命令jps

(b)查看产生的log日志
当前目录:/opt/wdp/hadoop/logs

jps命令下没谁看谁的log,看以log结尾的
vi进去,shift+g跳转到最后一行

INFO表示无误
(c)web端查看HDFS文件系统
http://172.16.50.100:50070/dfshealth.html#tab-overview





输入命令hdfs会给出提示

输入命名
hdfs dfs -mkdir /data


把本地路径/opt/wdp/datain/aa.txt文件推到HDFS
hdfs dfs -put /opt/wdp/datain/aa.txt /data

可以看到上传成功

进入到hadoop的share的hadoop的mapreduce目录
此时再次运行wordcount案例
注:我们在格式化之后,会自动到hdfs而非本地路径中找输入文件
输入以下命令
hadoop jar hadoop-mapreduce-examples-2.7.6.jar wordcount /data/aa.txt /out





YARN的作用是调度,比如启多少个map,多少个reduce,怎么优化
1)在集群的基础上配置Yarn:
(1)配置yarn-env.sh中的JAVA_HOME
首先进入如下路径
vi yarn-env.sh

export JAVA_HOME=/opt/wdp/jdk/
更改如上图,然后保存退出
(2)配置yarn-site.xml 主从结构
vi yarn-site.xml
<!-- reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定YARN的ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop100</value>
</property>

(3)配置:mapred-env.sh
配置一下JAVA_HOME
vi mapred-env.sh
export JAVA_HOME=/opt/wdp/jdk/

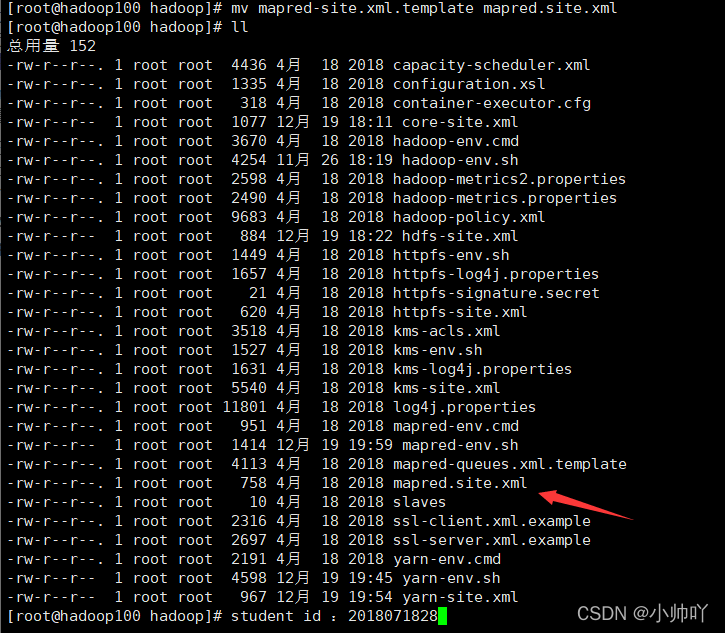
(4)配置: (对mapred-site.xml.template重新命名为) mapred-site.xml
mv mapred-site.xml.template mapred.site.xml
vi mapred.site.xml
<!-- 指定mr运行在yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>

2)启动Yarn Hadoop spark flink
(1)启动resourcemanager
sbin/yarn-daemon.sh start resourcemanager
(2)启动nodemanager
sbin/yarn-daemon.sh start nodemanager
用下面命令代替上面两行
start-yarn.sh

3)Yarn的操作
(1)yarn的浏览器页面查看
http://172.16.50.100:8088/cluster
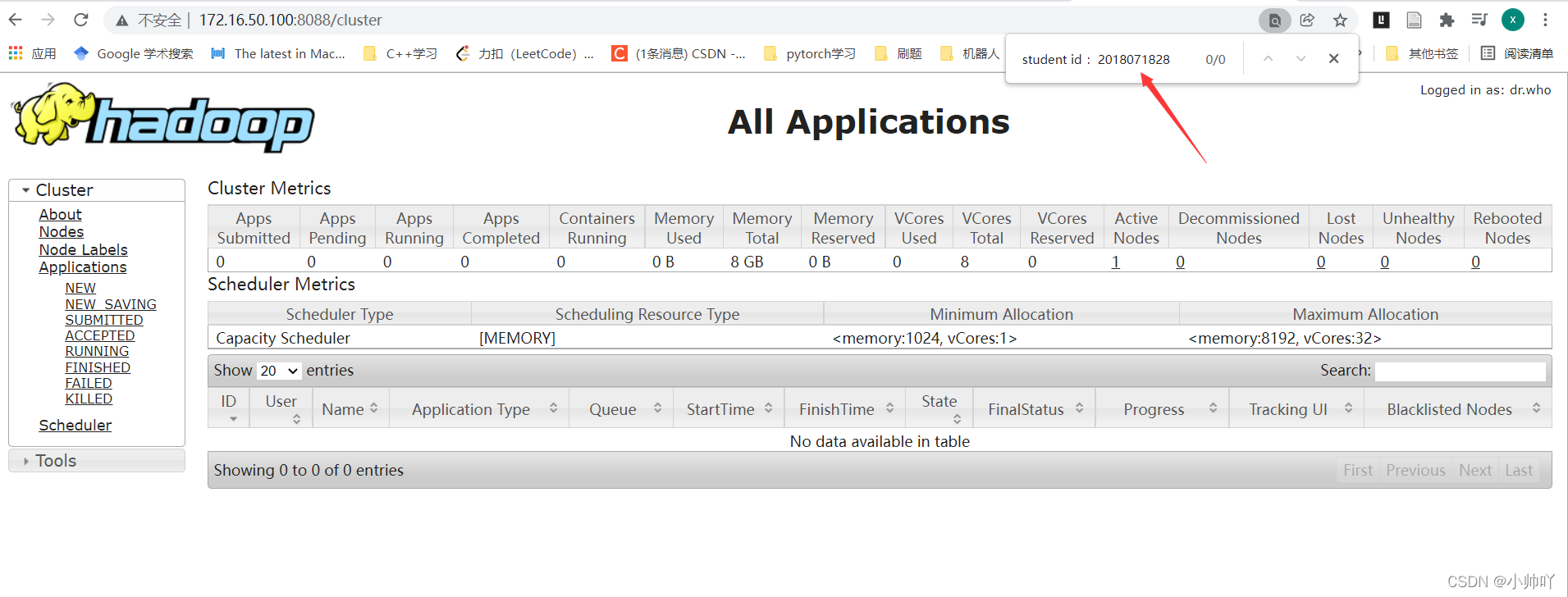
如果进行了之前的步骤只需更改slave文件就行

在slaves文件中加入主机名即可
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
这里是Ruby新手。完成一些练习后碰壁了。练习:计算一系列成绩的字母等级创建一个方法get_grade来接受测试分数数组。数组中的每个分数应介于0和100之间,其中100是最大分数。计算平均分并将字母等级作为字符串返回,即“A”、“B”、“C”、“D”、“E”或“F”。我一直返回错误:avg.rb:1:syntaxerror,unexpectedtLBRACK,expecting')'defget_grade([100,90,80])^avg.rb:1:syntaxerror,unexpected')',expecting$end这是我目前所拥有的。我想坚持使用下面的方法或.join,
在应用开发中,有时候我们需要获取系统的设备信息,用于数据上报和行为分析。那在鸿蒙系统中,我们应该怎么去获取设备的系统信息呢,比如说获取手机的系统版本号、手机的制造商、手机型号等数据。1、获取方式这里分为两种情况,一种是设备信息的获取,一种是系统信息的获取。1.1、获取设备信息获取设备信息,鸿蒙的SDK包为我们提供了DeviceInfo类,通过该类的一些静态方法,可以获取设备信息,DeviceInfo类的包路径为:ohos.system.DeviceInfo.具体的方法如下:ModifierandTypeMethodDescriptionstatic StringgetAbiList()Obt
项目介绍随着我国经济迅速发展,人们对手机的需求越来越大,各种手机软件也都在被广泛应用,但是对于手机进行数据信息管理,对于手机的各种软件也是备受用户的喜爱小学生兴趣延时班预约小程序的设计与开发被用户普遍使用,为方便用户能够可以随时进行小学生兴趣延时班预约小程序的设计与开发的数据信息管理,特开发了小程序的设计与开发的管理系统。小学生兴趣延时班预约小程序的设计与开发的开发利用现有的成熟技术参考,以源代码为模板,分析功能调整与小学生兴趣延时班预约小程序的设计与开发的实际需求相结合,讨论了小学生兴趣延时班预约小程序的设计与开发的使用。开发环境开发说明:前端使用微信微信小程序开发工具:后端使用ssm:VU
基础版云数据库RDS的产品系列包括基础版、高可用版、集群版、三节点企业版,本文介绍基础版实例的相关信息。RDS基础版实例也称为单机版实例,只有单个数据库节点,计算与存储分离,性价比超高。说明RDS基础版实例只有一个数据库节点,没有备节点作为热备份,因此当该节点意外宕机或者执行重启实例、变更配置、版本升级等任务时,会出现较长时间的不可用。如果业务对数据库的可用性要求较高,不建议使用基础版实例,可选择其他系列(如高可用版),部分基础版实例也支持升级为高可用版。基础版与高可用版的对比拓扑图如下所示。优势 性能由于不提供备节点,主节点不会因为实时的数据库复制而产生额外的性能开销,因此基础版的性能相对于
我对如何计算通过{%assignvar=0%}赋值的变量加一完全感到困惑。这应该是最简单的任务。到目前为止,这是我尝试过的:{%assignamount=0%}{%forvariantinproduct.variants%}{%assignamount=amount+1%}{%endfor%}Amount:{{amount}}结果总是0。也许我忽略了一些明显的东西。也许有更好的方法。我想要存档的只是获取运行的迭代次数。 最佳答案 因为{{incrementamount}}将输出您的变量值并且不会影响{%assign%}定义的变量,我
给定一个nxmbool数组:[[true,true,false],[false,true,true],[false,true,true]]有什么简单的方法可以返回“该列中有多少个true?”结果应该是[1,3,2] 最佳答案 使用转置得到一个数组,其中每个子数组代表一列,然后将每一列映射到其中的true数:arr.transpose.map{|subarr|subarr.count(true)}这是一个带有inject的版本,应该在1.8.6上运行,没有任何依赖:arr.transpose.map{|subarr|subarr.in
给定两个大小相等的数组,如何找到不考虑位置的匹配元素的数量?例如:[0,0,5]和[0,5,5]将返回2的匹配项,因为有一个0和一个5共同;[1,0,0,3]和[0,0,1,4]将返回3的匹配项,因为0有两场,1有一场;[1,2,2,3]和[1,2,3,4]将返回3的匹配项。我尝试了很多想法,但它们都变得相当粗糙和令人费解。我猜想有一些不错的Ruby习惯用法,或者可能是一个正则表达式,可以很好地回答这个解决方案。 最佳答案 您可以使用count完成它:a.count{|e|index=b.index(e)andb.delete_at
我使用irb。下面是我写的代码。“斧头”..“bc”我期待"ax""ay""az""ba"bb""bc"但结果只是“斧头”..“bc”我该如何纠正?谢谢。 最佳答案 >puts("ax".."bc").to_aaxayazbabbbc 关于ruby-从结束值创建一系列字符串,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/7617092/
Ruby中如何“一般地”计算以下格式(有根、无根)的JSON对象的数量?一般来说,我的意思是元素可能不同(例如“标题”被称为其他东西)。没有根:{[{"title":"Post1","body":"Hello!"},{"title":"Post2","body":"Goodbye!"}]}根包裹:{"posts":[{"title":"Post1","body":"Hello!"},{"title":"Post2","body":"Goodbye!"}]} 最佳答案 首先,withoutroot代码不是有效的json格式。它将没有包