elasticsearch的查询依然是基于JSON风格的DSL来实现的。
Elasticsearch提供了基于JSON的DSL(Domain Specific Language)来定义查询。常见的查询类型包括:
match_allmatch_querymulti_match_queryidsrangetermgeo_distancegeo_bounding_boxboolfunction_score查询的语法基本一致:
GET /indexName/_search
{
"query": {
"查询类型": {
"查询条件": "条件值"
}
}
}
我们以查询所有为例,其中:
// 查询所有
GET /indexName/_search
{
"query": {
"match_all": {
}
}
}
其它查询无非就是查询类型、查询条件的变化。
常见的全文检索查询包括:
match查询语法如下:
GET /indexName/_search
{
"query": {
"match": {
"FIELD": "TEXT"
# FIELD属性字段 TEXT 该字段下所匹配的内容
}
}
}
mulit_match语法如下:
GET /indexName/_search
{
"query": {
"multi_match": {
"query": "TEXT",
"fields": ["FIELD1", " FIELD12"]
}
}
}
match和multi_match的区别是什么?
精确查询一般是查找keyword、数值、日期、boolean等类型字段。所以不会对搜索条件分词。常见的有:
因为精确查询的字段搜是不分词的字段,因此查询的条件也必须是不分词的词条。查询时,用户输入的内容跟自动值完全匹配时才认为符合条件。如果用户输入的内容过多,反而搜索不到数据。
语法说明:
// term查询
GET /indexName/_search
{
"query": {
"term": {
"FIELD": {
"value": "VALUE"
}
}
}
}
范围查询,一般应用在对数值类型做范围过滤的时候。比如做价格范围过滤。
基本语法:
// range查询
GET /indexName/_search
{
"query": {
"range": {
"FIELD": {
"gte": 10, // 这里的gte代表大于等于,gt则代表大于
"lte": 20 // lte代表小于等于,lt则代表小于
}
}
}
}
精确查询常见的有哪些?
所谓的地理坐标查询,其实就是根据经纬度查询,官方文档:https://www.elastic.co/guide/en/elasticsearch/reference/current/geo-queries.html
矩形范围查询,也就是geo_bounding_box查询,查询坐标落在某个矩形范围的所有文档:
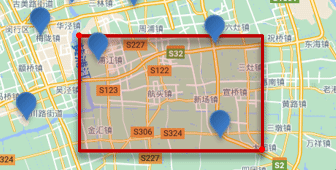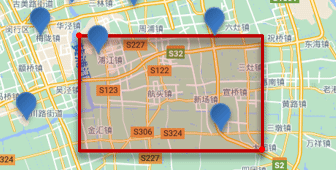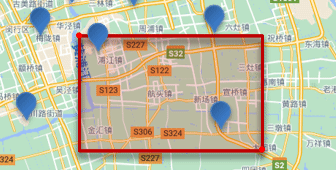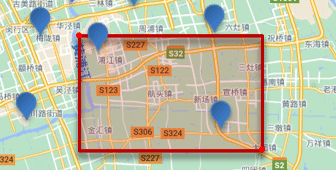
查询时,需要指定矩形的左上、右下两个点的坐标,然后画出一个矩形,落在该矩形内的都是符合条件的点。
语法如下:
// geo_bounding_box查询
GET /indexName/_search
{
"query": {
"geo_bounding_box": {
"FIELD": {
"top_left": { // 左上点
"lat": 31.1,
"lon": 121.5
},
"bottom_right": { // 右下点
"lat": 30.9,
"lon": 121.7
}
}
}
}
}
附近查询,也叫做距离查询(geo_distance):查询到指定中心点小于某个距离值的所有文档。
换句话来说,在地图上找一个点作为圆心,以指定距离为半径,画一个圆,落在圆内的坐标都算符合条件:
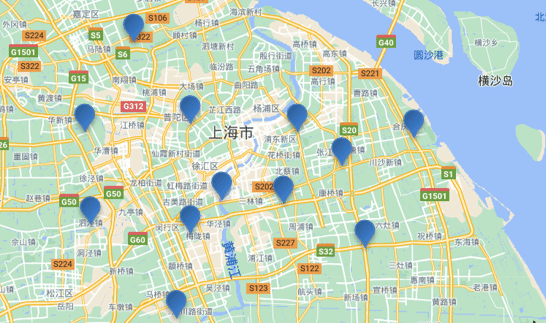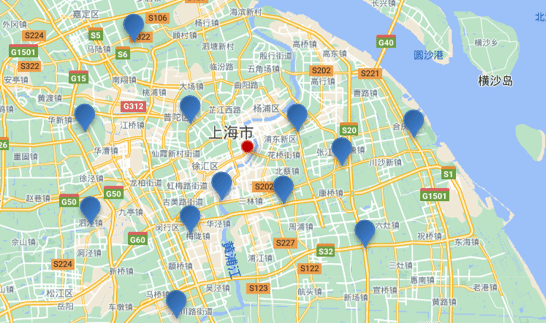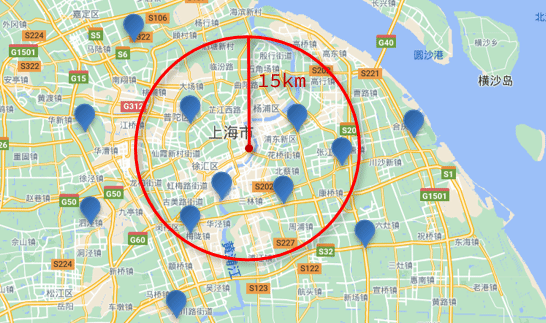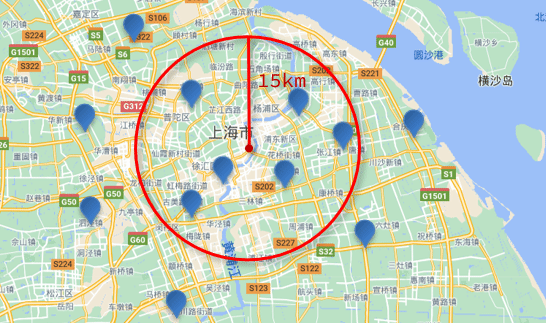
语法说明:
// geo_distance 查询
GET /indexName/_search
{
"query": {
"geo_distance": {
"distance": "15km", // 半径
"FIELD": "31.21,121.5" // 圆心
}
}
}
复合(compound)查询:复合查询可以将其它简单查询组合起来,实现更复杂的搜索逻辑。常见的有两种:
说白了谁掏钱多谁排名靠前
1)语法说明
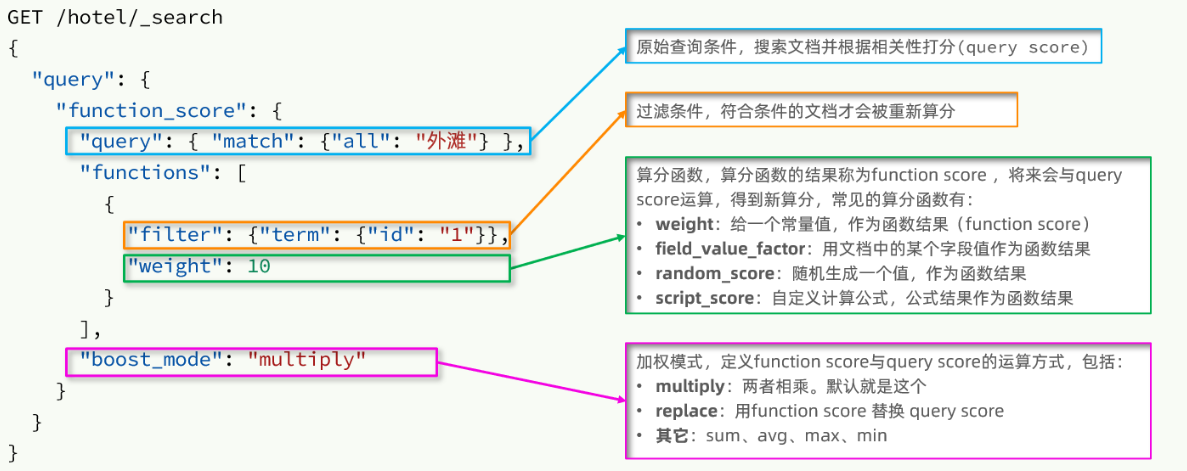
function score的运行流程如下:
2)小结
function score query定义的三要素是什么?
布尔查询是一个或多个查询子句的组合,每一个子句就是一个子查询。子查询的组合方式有:
1).语法示例

2).小结
bool查询有几种逻辑关系?
搜索的结果可以按照用户指定的方式去处理或展示。
语法:
普通字段排序:
GET /indexName/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"FIELD": "desc" // 排序字段、排序方式ASC、DESC
}
]
}
排序条件是一个数组,也就是可以写多个排序条件。按照声明的顺序,当第一个条件相等时,再按照第二个条件排序,以此类推
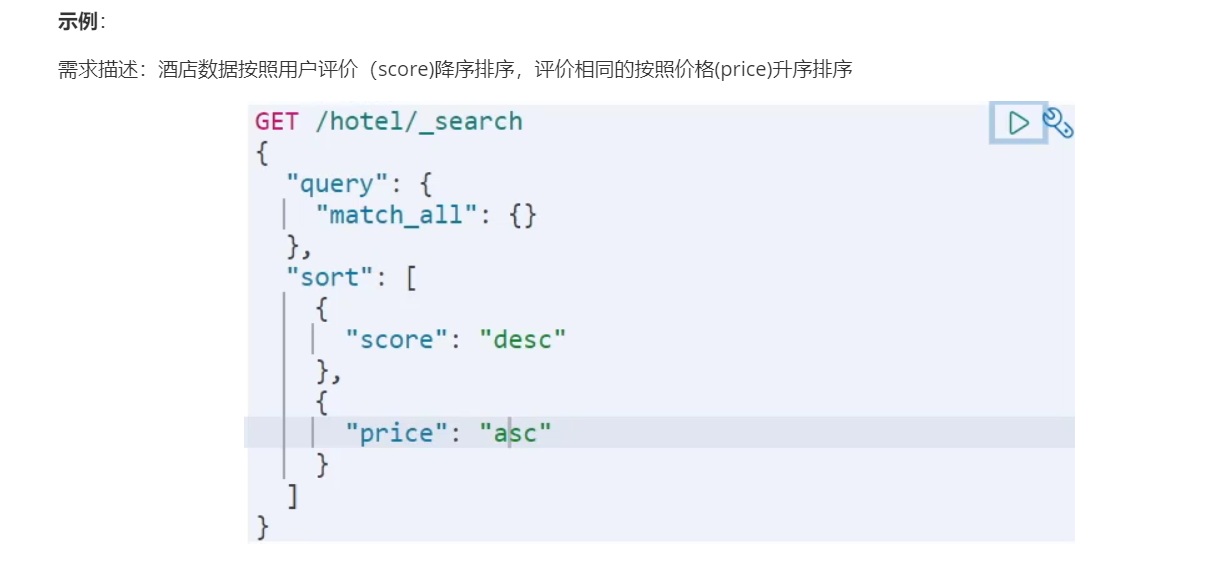
地理坐标排序:
GET /indexName/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"_geo_distance" : {
"FIELD" : "纬度,经度", // 文档中geo_point类型的字段名、目标坐标点
"order" : "asc", // 排序方式
"unit" : "km" // 排序的距离单位
}
}
]
}
语法:
基本的分页:
GET /hotel/_search
{
"query": {
"match_all": {}
},
"from": 0, // 分页开始的位置,默认为0
"size": 10, // 期望获取的文档总数
"sort": [
{"price": "asc"}
]
}
深度分页问题:
GET /hotel/_search
{
"query": {
"match_all": {}
},
"from": 990, // 分页开始的位置,默认为0
"size": 10, // 期望获取的文档总数
"sort": [
{"price": "asc"}
]
}
高亮显示的实现分为两步:
1)给文档中的所有关键字都添加一个标签,例如标签
2)页面给标签编写CSS样式
语法:
GET /hotel/_search
{
"query": {
"match": {
"FIELD": "TEXT" // 查询条件,高亮一定要使用全文检索查询
}
},
"highlight": {
"fields": { // 指定要高亮的字段
"FIELD": {
"pre_tags": "<em>", // 用来标记高亮字段的前置标签
"post_tags": "</em>" // 用来标记高亮字段的后置标签
}
}
}
}

我们以match_all查询为例
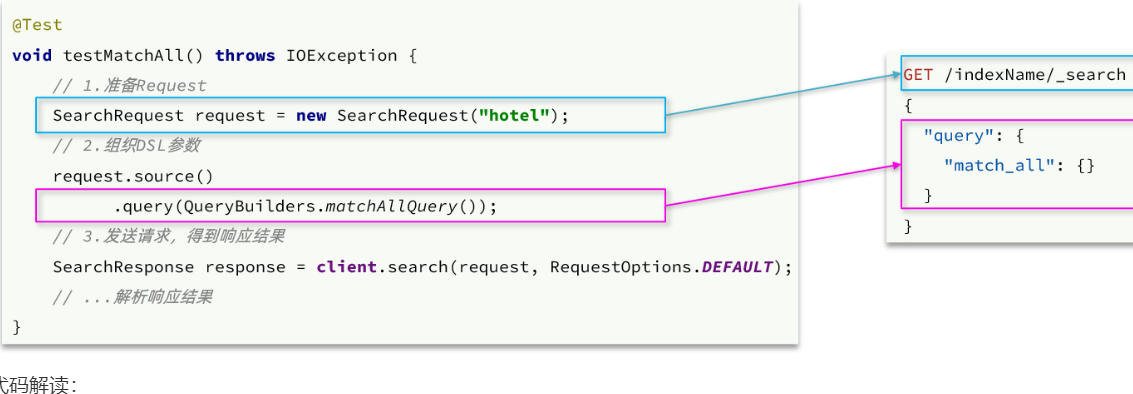
代码解读:
这里关键的API有两个,一个是request.source(),其中包含了查询、排序、分页、高亮等所有功能:
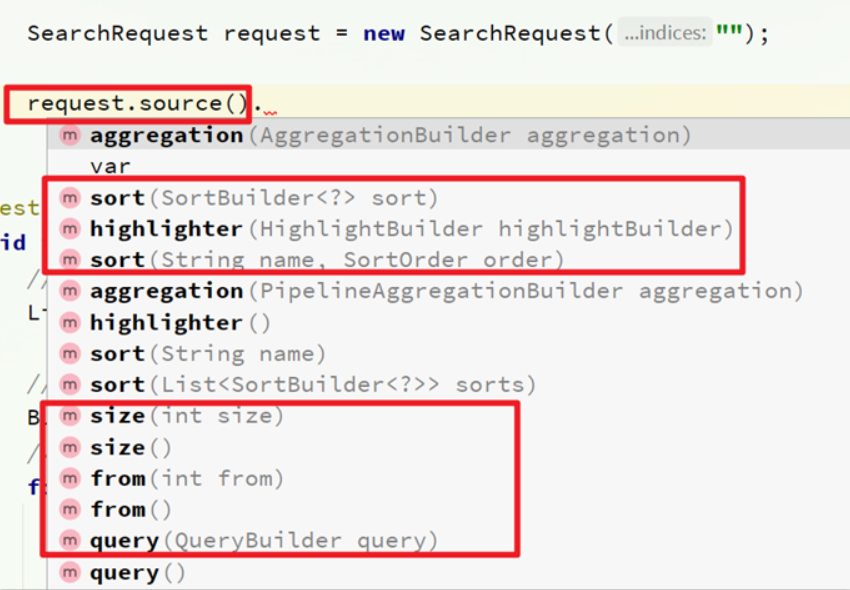
一个是QueryBuilders,其中包含match、term、function_score、bool等各种查询:

响应结果的解析:
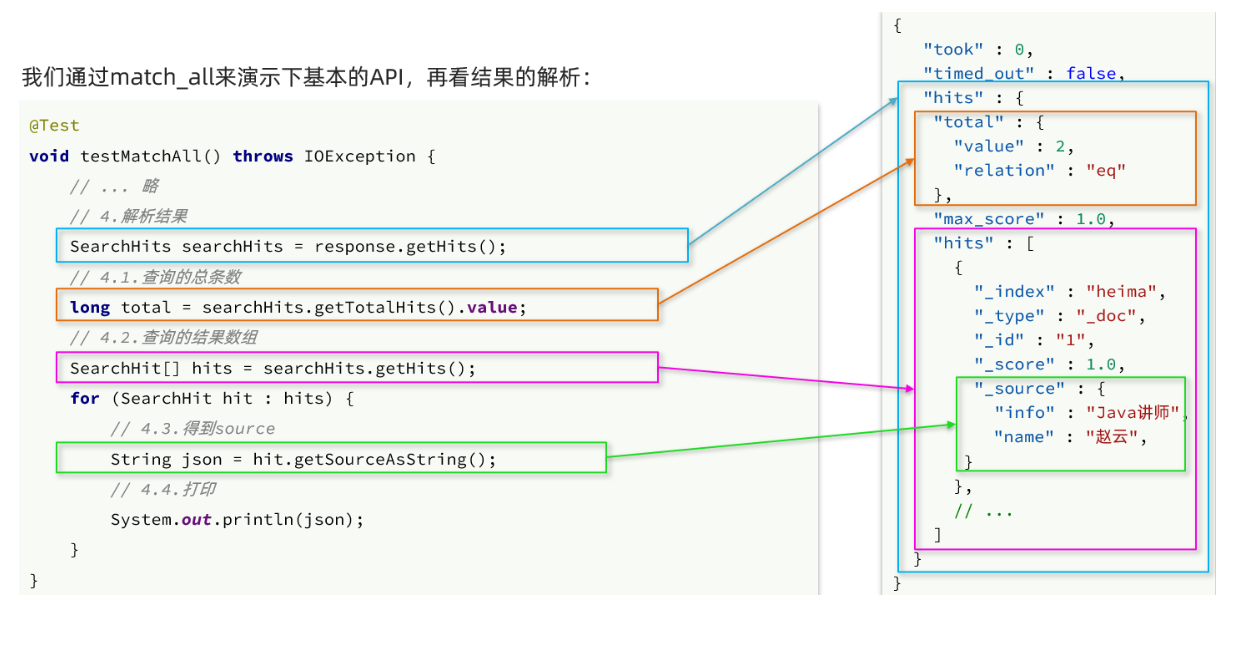
完整代码如下:
@Test
void testMatchAll() throws IOException {
// 1.准备Request
SearchRequest request = new SearchRequest("hotel");
// 2.准备DSL
request.source()
.query(QueryBuilders.matchAllQuery());
// 3.发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 4.解析响应
handleResponse(response);
}
private void handleResponse(SearchResponse response) {
// 4.解析响应
SearchHits searchHits = response.getHits();
// 4.1.获取总条数
long total = searchHits.getTotalHits().value;
System.out.println("共搜索到" + total + "条数据");
// 4.2.文档数组
SearchHit[] hits = searchHits.getHits();
// 4.3.遍历
for (SearchHit hit : hits) {
// 获取文档source
String json = hit.getSourceAsString();
// 反序列化
HotelDoc hotelDoc = JSON.parseObject(json, HotelDoc.class);
System.out.println("hotelDoc = " + hotelDoc);
}
}
查询的基本步骤是:
同样是利用QueryBuilders提供的方法:

精确查询主要是两者:
与之前的查询相比,差异同样在查询条件,其它都一样。
查询条件构造的API如下:

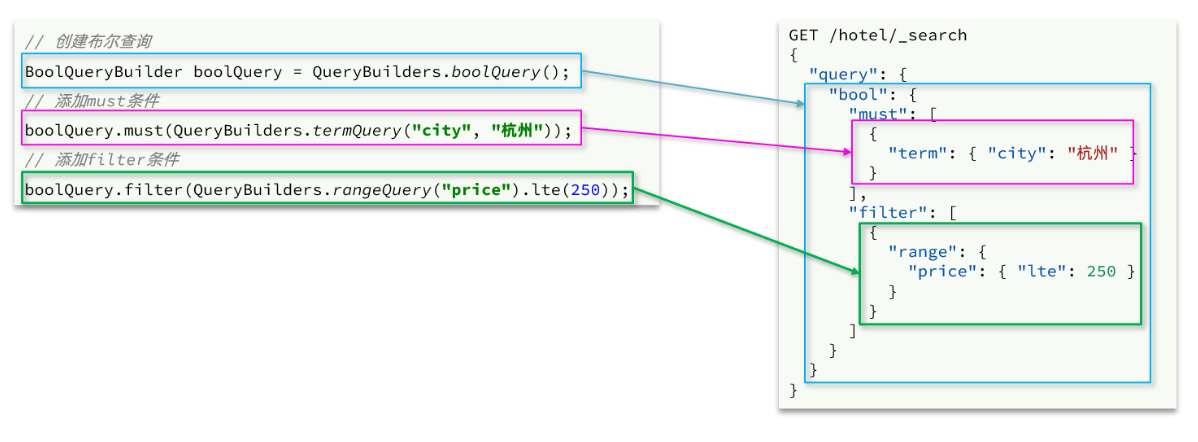
布尔查询是用must、must_not、filter等方式组合其它查询,代码示例如下:
搜索结果的排序和分页是与query同级的参数,因此同样是使用request.source()来设置。
对应的API如下:

高亮的代码与之前代码差异较大,有两点:
高亮请求的构建API如下:

高亮的结果与查询的文档结果默认是分离的,并不在一起,需要替换原来显示高亮的字段。
因此解析高亮的代码需要额外处理
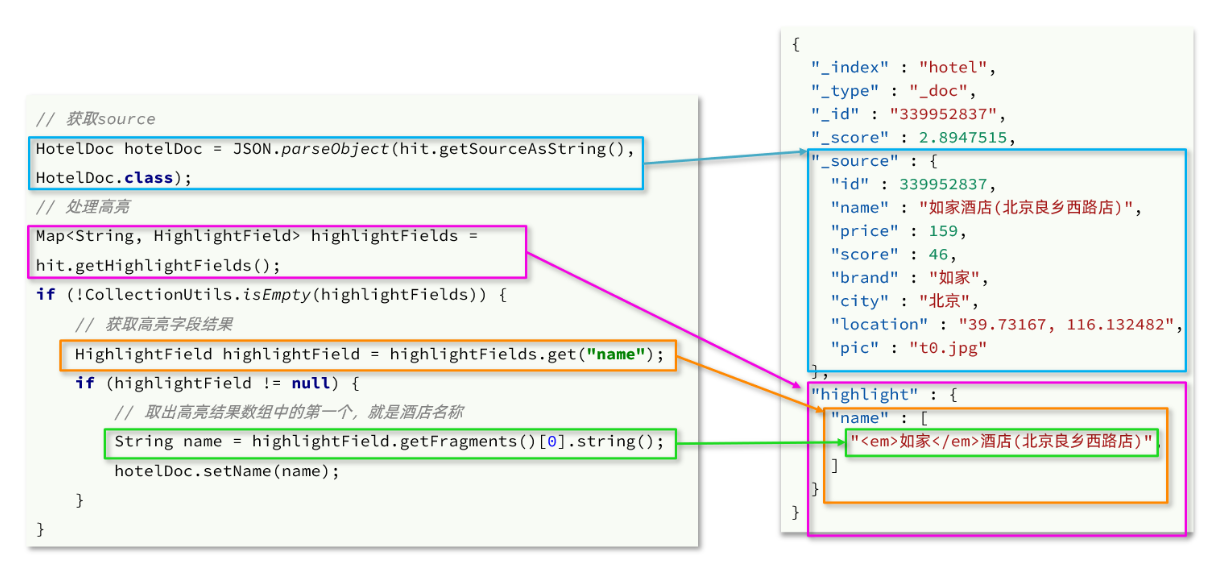
对应的JavaAPI如下:

代码如下:
// 2.算分控制
FunctionScoreQueryBuilder functionScoreQuery =
QueryBuilders.functionScoreQuery(
// 原始查询,相关性算分的查询
boolQuery,
// function score的数组
new FunctionScoreQueryBuilder.FilterFunctionBuilder[]{
// 其中的一个function score 元素
new FunctionScoreQueryBuilder.FilterFunctionBuilder(
// 过滤条件 这里实体类加个字段 "isAD" 条件为true的加广告
QueryBuilders.termQuery("isAD", true),
// 算分函数
ScoreFunctionBuilders.weightFactorFunction(10)
)
});
request.source().query(functionScoreQuery);
}
我想在一个没有Sass引擎的类中使用Sass颜色函数。我已经在项目中使用了sassgem,所以我认为搭载会像以下一样简单:classRectangleincludeSass::Script::FunctionsdefcolorSass::Script::Color.new([0x82,0x39,0x06])enddefrender#hamlengineexecutedwithcontextofself#sothatwithintemlateicouldcall#%stop{offset:'0%',stop:{color:lighten(color)}}endend更新:参见上面的#re
我使用Nokogiri(Rubygem)css搜索寻找某些在我的html里面。看起来Nokogiri的css搜索不喜欢正则表达式。我想切换到Nokogiri的xpath搜索,因为这似乎支持搜索字符串中的正则表达式。如何在xpath搜索中实现下面提到的(伪)css搜索?require'rubygems'require'nokogiri'value=Nokogiri::HTML.parse(ABBlaCD3"HTML_END#my_blockisgivenmy_bl="1"#my_eqcorrespondstothisregexmy_eq="\/[0-9]+\/"#FIXMEThefoll
我有一个涉及多台机器、消息队列和事务的问题。因此,例如用户点击网页,点击将消息发送到另一台机器,该机器将付款添加到用户的帐户。每秒可能有数千次点击。事务的所有方面都应该是容错的。我以前从未遇到过这样的事情,但一些阅读表明这是一个众所周知的问题。所以我的问题。我假设安全的方法是使用两阶段提交,但协议(protocol)是阻塞的,所以我不会获得所需的性能,我是否正确?我通常写Ruby,但似乎Redis之类的数据库和Rescue、RabbitMQ等消息队列系统对我的帮助不大——即使我实现某种两阶段提交,如果Redis崩溃,数据也会丢失,因为它本质上只是内存。所有这些让我开始关注erlang和
我想为我的Rails网络应用程序提供推荐功能。特别是,我想向新注册的用户推荐他可能想要关注的其他用户。Rails中是否有用于此目的的引擎/gem?如果没有,我应该从哪里开始构建它?谢谢。 最佳答案 有Coletivogemhttps://github.com/diogenes/coletivo我试了一下。在MySQL上运行。Neo4jhttp://neo4j.org真的很容易实现一个“跟随谁”。事实上,大多数展示其能力的样本都涉及“跟随谁”。快速提示-只有在JRuby上运行时,Neo4j.rb才会很酷。如果不是-使用Neograph
无论您是想搭建桌面端、WEB端或者移动端APP应用,HOOPSPlatform组件都可以为您提供弹性的3D集成架构,同时,由工业领域3D技术专家组成的HOOPS技术团队也能为您提供技术支持服务。如果您的客户期望有一种在多个平台(桌面/WEB/APP,而且某些客户端是“瘦”客户端)快速、方便地将数据接入到3D应用系统的解决方案,并且当访问数据时,在各个平台上的性能和用户体验保持一致,HOOPSPlatform将帮助您完成。利用HOOPSPlatform,您可以开发在任何环境下的3D基础应用架构。HOOPSPlatform可以帮您打造3D创新型产品,HOOPSSDK包含的技术有:快速且准确的CAD
导读:随着叮咚买菜业务的发展,不同的业务场景对数据分析提出了不同的需求,他们希望引入一款实时OLAP数据库,构建一个灵活的多维实时查询和分析的平台,统一数据的接入和查询方案,解决各业务线对数据高效实时查询和精细化运营的需求。经过调研选型,最终引入ApacheDoris作为最终的OLAP分析引擎,Doris作为核心的OLAP引擎支持复杂地分析操作、提供多维的数据视图,在叮咚买菜数十个业务场景中广泛应用。作者|叮咚买菜资深数据工程师韩青叮咚买菜创立于2017年5月,是一家专注美好食物的创业公司。叮咚买菜专注吃的事业,为满足更多人“想吃什么”而努力,通过美好食材的供应、美好滋味的开发以及美食品牌的孵
一、引擎主循环UE版本:4.27一、引擎主循环的位置:Launch.cpp:GuardedMain函数二、、GuardedMain函数执行逻辑:1、EnginePreInit:加载大多数模块int32ErrorLevel=EnginePreInit(CmdLine);PreInit模块加载顺序:模块加载过程:(1)注册模块中定义的UObject,同时为每个类构造一个类默认对象(CDO,记录类的默认状态,作为模板用于子类实例创建)(2)调用模块的StartUpModule方法2、FEngineLoop::Init()1、检查Engine的配置文件找出使用了哪一个GameEngine类(UGame
//1.验证返回状态码是否是200pm.test("Statuscodeis200",function(){pm.response.to.have.status(200);});//2.验证返回body内是否含有某个值pm.test("Bodymatchesstring",function(){pm.expect(pm.response.text()).to.include("string_you_want_to_search");});//3.验证某个返回值是否是100pm.test("Yourtestname",function(){varjsonData=pm.response.json
1.在Python3中,下列关于数学运算结果正确的是:(B)a=10b=3print(a//b)print(a%b)print(a/b)A.3,3,3.3333...B.3,1,3.3333...C.3.3333...,3.3333...,3D.3.3333...,1,3.3333...解析: 在Python中,//表示地板除(向下取整),%表示取余,/表示除(Python2向下取整返回3)2.如下程序Python2会打印多少个数:(D)k=1000whilek>1: print(k)k=k/2A.1000 B.10C.11D.9解析: 按照题意每次循环K/2,直到K值小于等
寻找有用的ruby的好网站是什么? 最佳答案 AgileWebDevelopment列出插件(虽然不是rubygems,我不确定为什么),并允许人们对它们进行评级。RubyToolbox按类别列出gem并比较它们的受欢迎程度。Rubygems有一个搜索框。StackOverflow对最有用的rails插件和rubygems有疑问。 关于ruby-如何搜索有用的ruby,我们在StackOverflow上找到一个类似的问题: https://stacko