Robots.txt 是网站里的一个文件,它告诉搜索引擎抓取工具(蜘蛛)禁止或允许抓取网站的哪些内容。主流搜索引擎(包括 Google、Bing 和 Yahoo)都能够识别并尊重 Robots.txt的要求。
如需查看网站是否有Robots文件,请访问网址:域名/robots.txt,譬如https://xxx.com/robots.txt,
下图的示例,是一个 WordPress网站安装完Rank math SEO插件自动生成的robots文件及其内容。
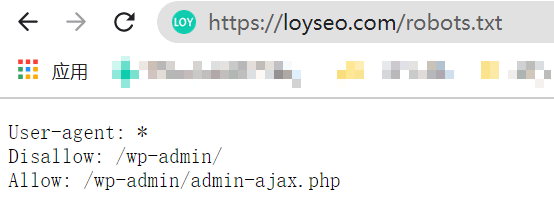
本文原文出自专注于外贸建站的LOYSEO:https://loyseo.com/robots-txt/
要想知道Robots.txt文件是如何发挥作用的,就要了解搜索引擎的工作机制:①爬行②抓取③索引(也可以叫做收录)。
爬行:搜索引擎的蜘蛛在爬网的过程中,通过从其他网站中获取到了你的网址,那么它就会记录下这个网址。还有,你也可以通过搜索引擎的站长工具,譬如在Google Search Console中提交你的网站地图(Sitemap),告知搜索引擎你的网站网址。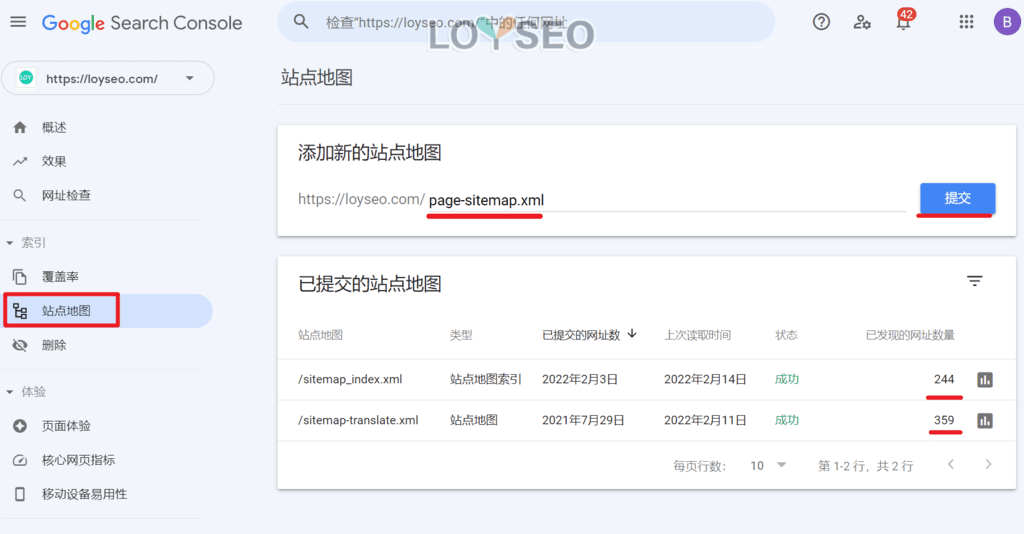
抓取:蜘蛛通过访问之前爬行获取的网址,抓取你网页里的内容并存档。爬行就像记录商店门牌号,抓取就是进店拍照。那是否你提交的网址一定都会被抓取呢?不一定,因为搜索引擎分配给你的抓取份额是有限的,如果你的站点很小,那基本不用担心,那如果你的站点规模庞大,那么,对于使用Robots.txt文件,禁止某些不必要的内容被抓取,就很用必要了,这能让抓取份额用在有意义的地方,而不是被无意义的内容消耗。
索引:也被称为收录,英文叫做index,也就是搜索引擎将之前抓取到的内容,呈现到用户搜索的相关搜索引擎结果中了。你可以通过在搜索引擎的搜索框中输入命令,site:你的网站或网址,以便查看你的网站有多少以及哪些网址被收录。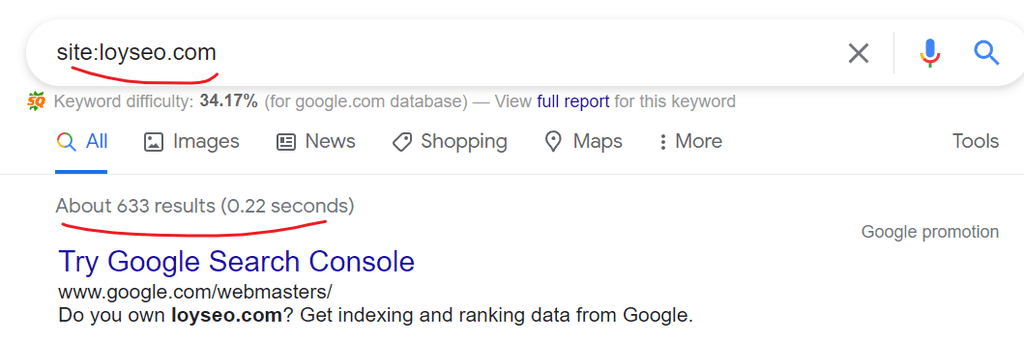 也可以直接在站长工具中查看被索引的网页。
也可以直接在站长工具中查看被索引的网页。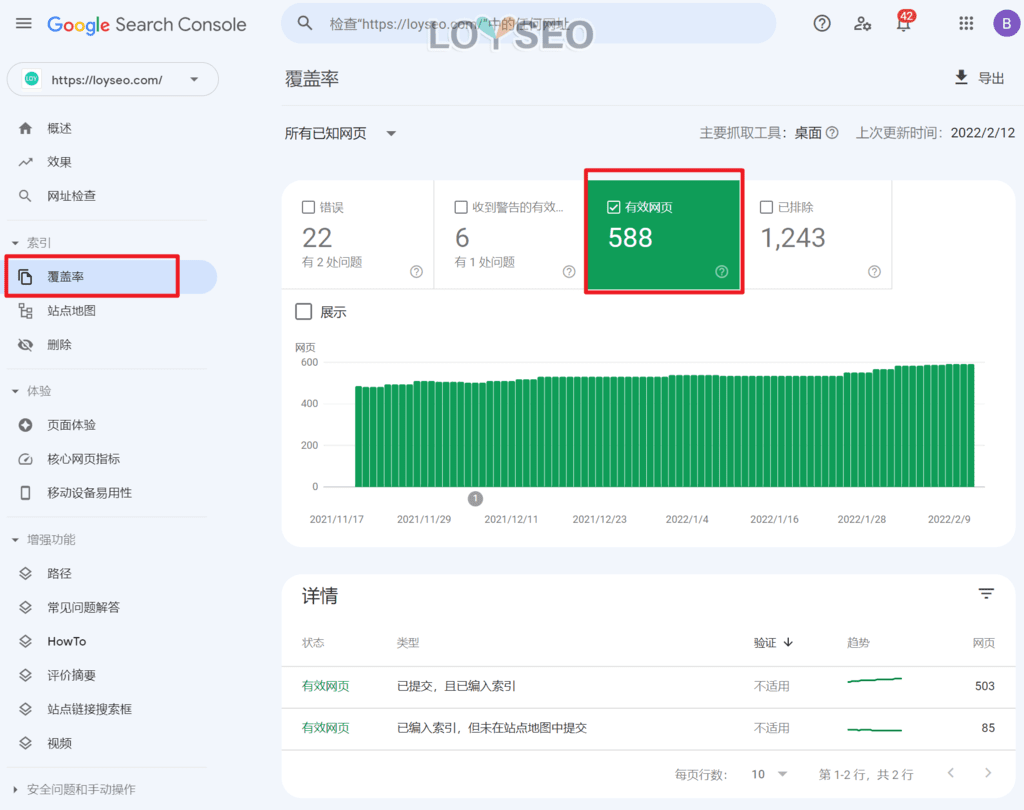 是否被抓取的内容一定会被索引呢?并不是,搜索引擎有自己的规则来判定你的内容是否值得被索引,如果你的内容是重复的、抄袭的、无意义无价值的,那么很可能是被抓取了,但是没有索引。并且索引也是需要时间的,尤其对于新站,就像一个新人一样,还需要时间考验你,至于这个时间是多久,那就是搜索引擎说了算了,你需要做的是持续坚持的做正确且有用的事情:写内容体现专业度、做外部拓展增加信用度。
是否被抓取的内容一定会被索引呢?并不是,搜索引擎有自己的规则来判定你的内容是否值得被索引,如果你的内容是重复的、抄袭的、无意义无价值的,那么很可能是被抓取了,但是没有索引。并且索引也是需要时间的,尤其对于新站,就像一个新人一样,还需要时间考验你,至于这个时间是多久,那就是搜索引擎说了算了,你需要做的是持续坚持的做正确且有用的事情:写内容体现专业度、做外部拓展增加信用度。
好了,了解到搜索引擎的工作机制后,我们开始说Robots文件的运作。
当搜索引擎的蜘蛛来到网站时,首先会阅读这个Robots.txt文件,了解到什么网址禁止被抓取后,搜索引擎便不去抓取这些页面。
但是,如果这些网址存在其他的导入链接(即外链时),譬如其他网址给了你一条外链指向这个内容,那么这个页面还是可能会被索引的,虽然,因为无法抓取而不能直接获取页面的内容,但是搜索引擎会根据外链提供的相关信息对这个内容进行索引并展示在搜索结果中。
所以,如果你想一个内容不被抓取,也不被索引,那么你还需要通过在内容中设置noindex元标记(meta robots)。
好了,了解了Robots.txt的工作原理后,我们开始制作一个robots.txt文件。
如果你使用wordpress建站的,那么安装插件rank math seo或其他主流seo插件后,基本都能直接在插件中找到robots.txt文件的编辑功能,你只需要按下文所述,学习如何编辑指令规则即可。
以rank math seo插件为例,你可以按照下图所示,编辑robots.txt文件。
![]()
如果你不是用wordpress建站的,且建站系统本身不提供robots.txt编辑功能,你可以按照下文的教程自制。
请用记事本或者其他文本型的软件(譬如Emeditor)创建一个名为robots.txt的文件,注意名字不能改,也不能大写,必须全小写。
Robots.txt文件怎么写呢?
请用记事本继续编辑这个文件,输入指令规则,示例如下:
User-agent: * #搜索引擎抓取工具名称(即蜘蛛):任意,不限,谁都行
Disallow: / #禁止抓取:根目录下的所有内容
Allow:/post/ #允许抓取:/post/及其目录下的所有内容
上面这段是一组指令规则的构成,你可以参照写多段。
user-agent表示搜索引擎抓取工具的名字,disallow就表示禁止抓取,allow表示允许抓取,#号后的内容为注释,实际使用时可以去掉。注意,规则部分区分大小写,譬如/post/和/POST/不是相同的内容。
搜索引擎抓取工具的名字是多种多样的,谷歌、百度、必应都各自有自己的蜘蛛,并且每家搜索引擎的蜘蛛还不止一种,譬如谷歌有Googlebot、Googlebot-Image等等,如果你想了解谷歌蜘蛛种类,可以查看此文。
下表是常见的搜索引擎的蜘蛛名称。
| 搜索引擎 | 类型 | User-agent |
|---|---|---|
| Baidu | General | baiduspider |
| Baidu | Images | baiduspider-image |
| Baidu | Mobile | baiduspider-mobile |
| Baidu | News | baiduspider-news |
| Baidu | Video | baiduspider-video |
| Bing | General | bingbot |
| Bing | General | msnbot |
| Bing | Images & Video | msnbot-media |
| Bing | Ads | adidxbot |
| General | Googlebot |
|
| Images | Googlebot-Image |
|
| Mobile | Googlebot-Mobile |
|
| News | Googlebot-News |
|
| Video | Googlebot-Video |
|
| AdSense | Mediapartners-Google |
|
| AdWords | AdsBot-Google |
|
| Yahoo! | General | slurp |
| Yandex | General | yandex |
我们可以针对不同的蜘蛛写不同的规则,下面以示例进行详解。
下面的指令表示:针对谷歌和百度的蜘蛛,禁止抓取的内容=无,也就是什么都可以抓取。
User-agent: Googlebot
User-agent: Baiduspider
Disallow:
下面的指令是基于WordPress建站的网址结构的,解释已在备注中
User-agent: Googlebot
Disallow:/wp-admin/ #禁止抓取wordpress网站后台的内容
Disallow:/my-account/ #禁止抓取会员中心目录下的内容
Disallow:*/feed/ #wordpress会自动生成feed,为了不消耗抓取份额,可以禁用,其中*表示/feed/之前可以是任意内容
Disallow:/?s= #在wordpress网站中,这是关键词搜索结果的网址结构,所以禁止抓取关键词搜索结果页,避免重复内容被抓取
Disallow:/*.gif$ #禁止抓取所有gif文件
User-agent: *
Disallow:/ #除了谷歌,其他搜索引擎都不允许爬取网站
Sitemap: https://example.com/sitemap.xml #sitemap规则不是必须写的,但是建议写,以便蜘蛛抓取。
Sitemap: http://www.example.com/sitemap.xml
如果你想知道更多的robots.txt规则撰写方法,请点击此处。
robots.txt文件应该放到哪里呢?
由于网站建站系统不同、服务器架构不同,上传文件的方法没有统一的,譬如可以借助主机的管理面板,又或是用FTP,在连通到网站所在的文件目录后,将robots.txt放在网站所在文件夹第一层中(也就是根目录)。
当成功上传后,通常在浏览器中访问域名/robots.txt就可以查看到文件。
测试robots.txt中所写的规则是否正确有效,需借助搜索引擎站长工具中提供的功能,以谷歌为例,我们用google search console的robots.txt测试工具(如下图)来进行测试,但这要求你先要将网站添加到google search console中。
打开工具页面后,在选择资源里找到你的网站
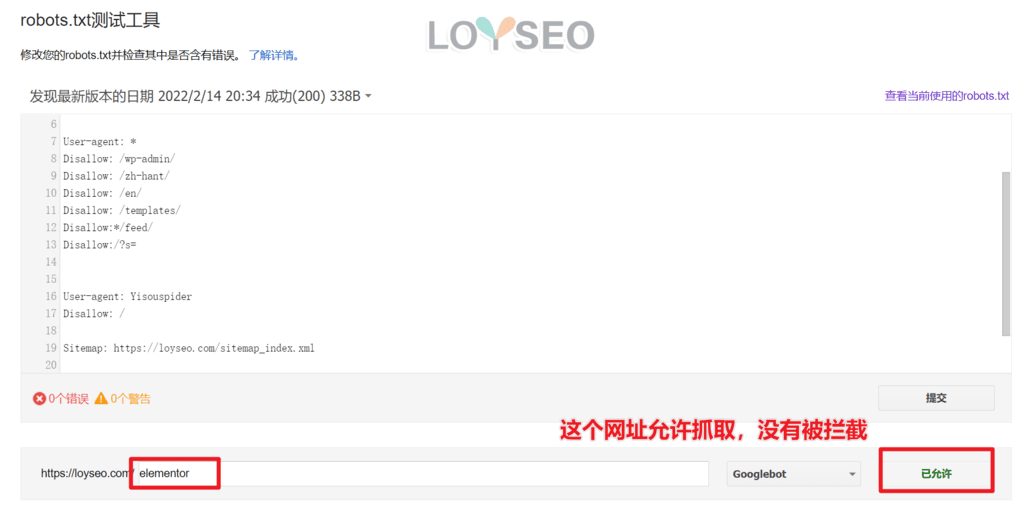
当打开测试工具后,我们能看到谷歌获取了我们网站里的robots文件内容,如果你发现它不是最新版的,请把规则部分复制到输入框中,然后点击提交进行更新。接下来,在图的左下角,输入你需要测试的网址,点击右侧的测试按钮后,系统会反馈已拦截或已允许,当被拦截时,还会突出显示是哪条规则拦截了它。
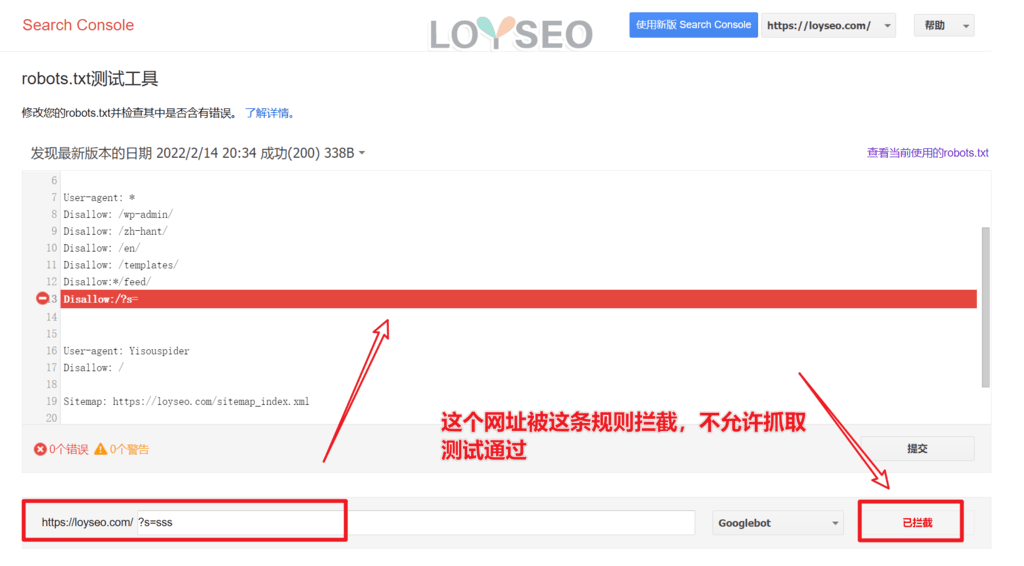
在图中,你还可以选择爬取工具,默认是Googlebot,表示谷歌全部的爬虫。你也可以按需选择谷歌图片、视频的爬虫等等。
如果网址是允许抓取的,那么会提示已允许。所以当发现想要被禁止爬取的网址被允许,那你就要检查一下规则是否撰写正确。
如果你的网站较小,且索引符合你的预期,你可以不要robots.txt文件,主流搜索引擎足够聪明的去识别你的内容。但建议还是要有一个Robots.txt文件,因为搜索引擎访问网站时,首先就是查阅它。
不要这么做,因为搜索引擎需要靠资源类文件来解读你的网页。
本文由专注于外贸建站的LOYSEO 发布
我有一个Ruby程序,它使用rubyzip压缩XML文件的目录树。gem。我的问题是文件开始变得很重,我想提高压缩级别,因为压缩时间不是问题。我在rubyzipdocumentation中找不到一种为创建的ZIP文件指定压缩级别的方法。有人知道如何更改此设置吗?是否有另一个允许指定压缩级别的Ruby库? 最佳答案 这是我通过查看rubyzip内部创建的代码。level=Zlib::BEST_COMPRESSIONZip::ZipOutputStream.open(zip_file)do|zip|Dir.glob("**/*")d
我试图在一个项目中使用rake,如果我把所有东西都放到Rakefile中,它会很大并且很难读取/找到东西,所以我试着将每个命名空间放在lib/rake中它自己的文件中,我添加了这个到我的rake文件的顶部:Dir['#{File.dirname(__FILE__)}/lib/rake/*.rake'].map{|f|requiref}它加载文件没问题,但没有任务。我现在只有一个.rake文件作为测试,名为“servers.rake”,它看起来像这样:namespace:serverdotask:testdoputs"test"endend所以当我运行rakeserver:testid时
我的目标是转换表单输入,例如“100兆字节”或“1GB”,并将其转换为我可以存储在数据库中的文件大小(以千字节为单位)。目前,我有这个:defquota_convert@regex=/([0-9]+)(.*)s/@sizes=%w{kilobytemegabytegigabyte}m=self.quota.match(@regex)if@sizes.include?m[2]eval("self.quota=#{m[1]}.#{m[2]}")endend这有效,但前提是输入是倍数(“gigabytes”,而不是“gigabyte”)并且由于使用了eval看起来疯狂不安全。所以,功能正常,
Rails2.3可以选择随时使用RouteSet#add_configuration_file添加更多路由。是否可以在Rails3项目中做同样的事情? 最佳答案 在config/application.rb中:config.paths.config.routes在Rails3.2(也可能是Rails3.1)中,使用:config.paths["config/routes"] 关于ruby-on-rails-Rails3中的多个路由文件,我们在StackOverflow上找到一个类似的问题
对于具有离线功能的智能手机应用程序,我正在为Xml文件创建单向文本同步。我希望我的服务器将增量/差异(例如GNU差异补丁)发送到目标设备。这是计划:Time=0Server:hasversion_1ofXmlfile(~800kiB)Client:hasversion_1ofXmlfile(~800kiB)Time=1Server:hasversion_1andversion_2ofXmlfile(each~800kiB)computesdeltaoftheseversions(=patch)(~10kiB)sendspatchtoClient(~10kiBtransferred)Cl
我正在寻找执行以下操作的正确语法(在Perl、Shell或Ruby中):#variabletoaccessthedatalinesappendedasafileEND_OF_SCRIPT_MARKERrawdatastartshereanditcontinues. 最佳答案 Perl用__DATA__做这个:#!/usr/bin/perlusestrict;usewarnings;while(){print;}__DATA__Texttoprintgoeshere 关于ruby-如何将脚
使用带有Rails插件的vim,您可以创建一个迁移文件,然后一次性打开该文件吗?textmate也可以这样吗? 最佳答案 你可以使用rails.vim然后做类似的事情::Rgeneratemigratonadd_foo_to_bar插件将打开迁移生成的文件,这正是您想要的。我不能代表textmate。 关于ruby-使用VimRails,您可以创建一个新的迁移文件并一次性打开它吗?,我们在StackOverflow上找到一个类似的问题: https://sta
好的,所以我的目标是轻松地将一些数据保存到磁盘以备后用。您如何简单地写入然后读取一个对象?所以如果我有一个简单的类classCattr_accessor:a,:bdefinitialize(a,b)@a,@b=a,bendend所以如果我从中非常快地制作一个objobj=C.new("foo","bar")#justgaveitsomerandomvalues然后我可以把它变成一个kindaidstring=obj.to_s#whichreturns""我终于可以将此字符串打印到文件或其他内容中。我的问题是,我该如何再次将这个id变回一个对象?我知道我可以自己挑选信息并制作一个接受该信
我正在编写一个小脚本来定位aws存储桶中的特定文件,并创建一个临时验证的url以发送给同事。(理想情况下,这将创建类似于在控制台上右键单击存储桶中的文件并复制链接地址的结果)。我研究过回形针,它似乎不符合这个标准,但我可能只是不知道它的全部功能。我尝试了以下方法:defauthenticated_url(file_name,bucket)AWS::S3::S3Object.url_for(file_name,bucket,:secure=>true,:expires=>20*60)end产生这种类型的结果:...-1.amazonaws.com/file_path/file.zip.A
我注意到像bundler这样的项目在每个specfile中执行requirespec_helper我还注意到rspec使用选项--require,它允许您在引导rspec时要求一个文件。您还可以将其添加到.rspec文件中,因此只要您运行不带参数的rspec就会添加它。使用上述方法有什么缺点可以解释为什么像bundler这样的项目选择在每个规范文件中都需要spec_helper吗? 最佳答案 我不在Bundler上工作,所以我不能直接谈论他们的做法。并非所有项目都checkin.rspec文件。原因是这个文件,通常按照当前的惯例,只