前面已经介绍了ElasticSearch的写入流程,了解了ElasticSearch写入时的分布式特性的相关原理。ElasticSearch作为一款具有强大搜索功能的存储引擎,它的读取是什么样的呢?读取相比写入简单得多,但是在使用过程中有哪些需要我们注意的呢?本篇文章会进行详细的分析。
在前面的文章我们已经知道ElasticSearch的读取分为两种GET和SEARCH。这两种操作是有一定的差异的,下面我们先对这两种核心的数据读取方式进行一一分析。
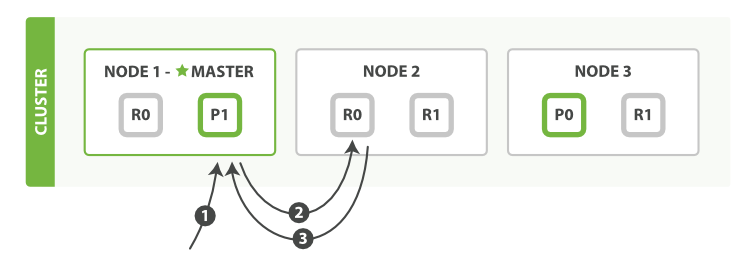
(图片来自官网)
以下是从主分片或者副本分片检索文档的步骤顺序:
注意:
在协调节点有个http_server_worker线程池。收到读请求后它的具体过程为:
数据节点上有一个get线程池。收到了请求后,处理过程为:
private class ShardTransportHandler implements TransportRequestHandler<Request> {
@Override
public void messageReceived(final Request request, final TransportChannel channel, Task task) {
asyncShardOperation(request, request.internalShardId, new ChannelActionListener<>(channel, transportShardAction, request));
}
}
if (request.refresh() && !request.realtime()) {
indexShard.refresh("refresh_flag_get");
}
GetResult result = indexShard.getService().get(
request.type(), request.id(),
request.storedFields(), request.realtime(),
request.version(), request.versionType(),
request.fetchSourceContext());
private GetResult innerGet(String type, String id, String[] gFields, boolean realtime, long version, VersionType versionType, long ifSeqNo, long ifPrimaryTerm, FetchSourceContext fetchSourceContext) {
................
Engine.GetResult get = null;
............
get = indexShard.get(new Engine.Get(realtime, realtime, type, id, uidTerm).version(version).versionType(versionType).setIfSeqNo(ifSeqNo).setIfPrimaryTerm(ifPrimaryTerm));
..........
if (get == null || get.exists() == false) {
return new GetResult(shardId.getIndexName(), type, id, UNASSIGNED_SEQ_NO, UNASSIGNED_PRIMARY_TERM, -1, false, null, null, null);
}
try {
return innerGetLoadFromStoredFields(type, id, gFields, fetchSourceContext, get, mapperService);
} finally {
get.close();
}
public GetResult get(Get get, BiFunction<String, SearcherScope, Engine.Searcher> searcherFactory) throws EngineException {
try (ReleasableLock ignored = readLock.acquire()) {
ensureOpen();
SearcherScope scope;
if (get.realtime()) {
VersionValue versionValue = null;
try (Releasable ignore = versionMap.acquireLock(get.uid().bytes())) {
// we need to lock here to access the version map to do this truly in RT
versionValue = getVersionFromMap(get.uid().bytes());
}
if (versionValue != null) {
if (versionValue.isDelete()) {
return GetResult.NOT_EXISTS;
}
。。。。。。
//刷盘操作
refreshIfNeeded("realtime_get", versionValue.seqNo);
注意:
get过程会加读锁。处理realtime选项,如果为true,则先判断是否有数据可以刷盘,然后调用Searcher进行读取。Searcher是对IndexSearcher的封装在早期realtime为true则会从tranlog中读取,后面只会从index的lucene读取了。即实时的数据只在lucene之中。
对于Search类请求,ElasticSearch请求是查询lucene的Segment,前面的写入详情流程也分析了,新增的文档会定时的refresh到磁盘中,所以搜索是属于近实时的。而且因为没有文档id,你不知道你要检索的文档在哪个分配上,需要将索引的所有的分片都去搜索下,然后汇总。ElasticSearch的search一般有两个搜索类型
所有的搜索系统一般都是两阶段查询:
第一阶段查询到匹配的docID,第二阶段再查询DocID对应的完整文档。这种在ElasticSearch中称为query_then_fetch,另一种就是一阶段查询的时候就返回完整Doc,在ElasticSearch中叫query_and_fetch,一般第二种适用于只需要查询一个Shard的请求。因为这种一次请求就能将数据请求到,减少交互次数,二阶段的原因是需要多个分片聚合汇总,如果数据量太大那么会影响网络传输效率,所以第一阶段会先返回id。
除了上述的这两种查询外,还有一种三阶段查询的情况。
搜索里面有一种算分逻辑是根据TF和DF来计算score的,而在普通的查询中,第一阶段去每个Shard中独立查询时携带条件算分都是独立的,即Shard中的TF和DF也是独立的。虽然从统计学的基础上数据量多的情况下,每一个分片的TF和DF在整体上会趋向于准确。但是总会有情况导致局部的TF和DF不准的情况出现。
ElasticSearch为了解决这个问题引入了DFS查询。
比如DFS_query_then_fetch,它在每次查询时会先收集所有Shard中的TF和DF值,然后将这些值带入请求中,再次执行query_then_fetch,这样算分的时候TF和DF就是准确的,类似的有DFS_query_and_fetch。这种查询的优势是算分更加精准,但是效率会变差。
另一种选择是用BM25代替TF/DF模型。
在ElasticSearch7.x,用户没法指定以下两种方式:DFS_query_and_fetch和query_and_fetch。
注:这两种算分的算法模型在《ElasticSearch实战篇》有介绍:
这里query_then_fetch具体的搜索的流程图如下:
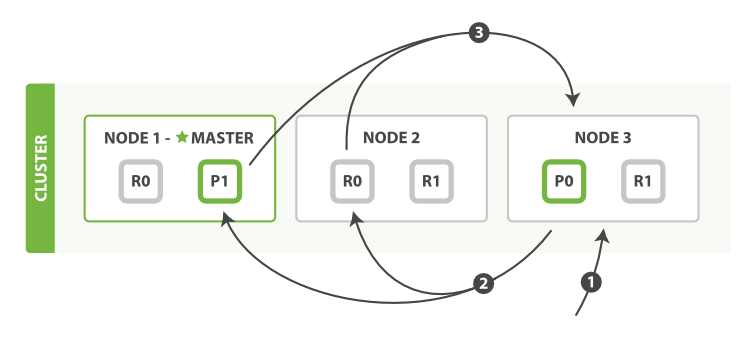
(图片来自官网)
查询阶段包含以下四个步骤:
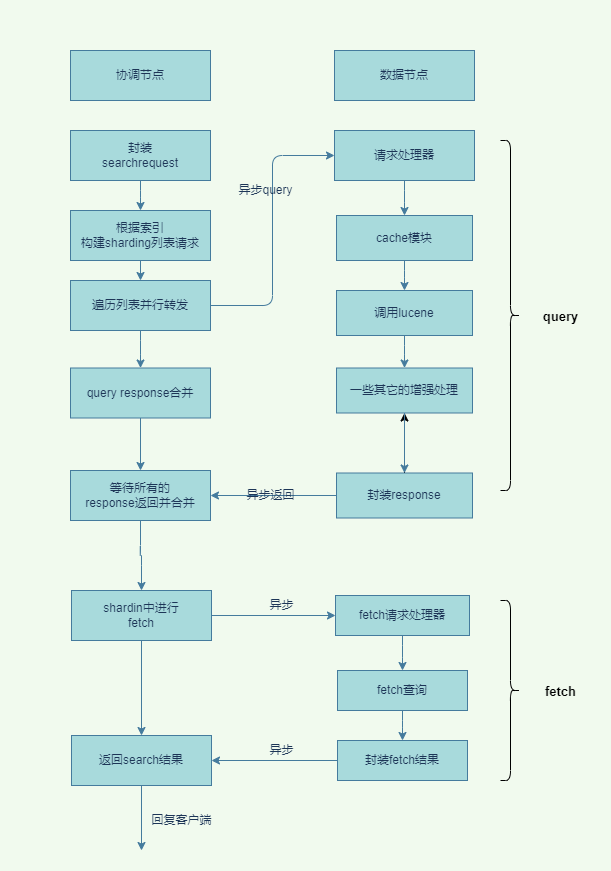
以上就是ElasticSearch的search的详细流程,下面会对每一步进行进一步的说明。
协调节点处理query请求的线程池为:
http_server_work
负责该解析功能的类为:org.elasticsearch.rest.action.search.RestSearchAction
@Override
public RestChannelConsumer prepareRequest(final RestRequest request, final NodeClient client) throws IOException {
SearchRequest searchRequest = new SearchRequest();
IntConsumer setSize = size -> searchRequest.source().size(size);
request.withContentOrSourceParamParserOrNull(parser ->
parseSearchRequest(searchRequest, request, parser, client.getNamedWriteableRegistry(), setSize));
。。。。。。。。。。。。
};
}
主要将restquest的参数封装成SearchRequest
这样SearchRequest请求发送给TransportSearchAction处理
将索引涉及到的shard列表或者有跨集群访问相关的shard列表合并
private void executeSearch(...........) {
........
//本集群的列表分片列表
localShardIterators = StreamSupport.stream(localShardRoutings.spliterator(), false)
.map(it -> new SearchShardIterator(
searchRequest.getLocalClusterAlias(), it.shardId(), it.getShardRoutings(), localIndices))
.collect(Collectors.toList());
.......
//远程集群的分片列表
final GroupShardsIterator<SearchShardIterator> shardIterators = mergeShardsIterators(localShardIterators, remoteShardIterators);
.......
}
如果有多个分片位于同一个节点,仍然会发送多次请求
public final void run() {
......
for (final SearchShardIterator iterator : toSkipShardsIts) {
assert iterator.skip();
skipShard(iterator);
}
......
......
if (shardsIts.size() > 0) {
//遍历分片发送请求
for (int i = 0; i < shardsIts.size(); i++) {
final SearchShardIterator shardRoutings = shardsIts.get(i);
assert shardRoutings.skip() == false;
assert shardItIndexMap.containsKey(shardRoutings);
int shardIndex = shardItIndexMap.get(shardRoutings);
//执行shard请求
performPhaseOnShard(shardIndex, shardRoutings, shardRoutings.nextOrNull());
}
......
shardsIts为搜索涉及的所有分片,而shardRoutings.nextOrNull()会从分片的所有副本分片选出一个分片来请求。
onShardSuccess对收集到的结果进行合并,这里需要检查所有的请求是否都已经有了回复。
然后才会判断要不要进行executeNextPhase
private void onShardResultConsumed(Result result, SearchShardIterator shardIt) {
successfulOps.incrementAndGet();
AtomicArray<ShardSearchFailure> shardFailures = this.shardFailures.get();
if (shardFailures != null) {
shardFailures.set(result.getShardIndex(), null);
}
successfulShardExecution(shardIt);
}
private void successfulShardExecution(SearchShardIterator shardsIt) {
......
//计数器累加
final int xTotalOps = totalOps.addAndGet(remainingOpsOnIterator);
//是不是所有分都已经回复,然后调用onPhaseDone();
if (xTotalOps == expectedTotalOps) {
onPhaseDone();
} else if (xTotalOps > expectedTotalOps) {
throw new AssertionError("unexpected higher total ops [" + xTotalOps + "] compared to expected [" + expectedTotalOps + "]",
new SearchPhaseExecutionException(getName(), "Shard failures", null, buildShardFailures()));
}
}当返回结果的分片数等于预期的总分片数时,协调节点会进入当前Phase的结束处理,启动下一个阶段Fetch Phase的执行。onPhaseDone()会executeNextPhase来执行下一个阶段。
当触发了executeNextPhase方法将触发fetch阶段
上一步的executeNextPhase方法触发Fetch阶段,Fetch阶段的起点为FetchSearchPhase#innerRun函数,从查询阶段的shard列表中遍历,跳过查询结果为空的 shard。其中也会封装一些分页信息的数据。
private void executeFetch(....){
//发送请求
context.getSearchTransport().sendExecuteFetch(connection, fetchSearchRequest, context.getTask(),
new SearchActionListener<FetchSearchResult>(shardTarget, shardIndex) {
//处理成功的消息
@Override
public void innerOnResponse(FetchSearchResult result) {
try {
progressListener.notifyFetchResult(shardIndex);
counter.onResult(result);
} catch (Exception e) {
context.onPhaseFailure(FetchSearchPhase.this, "", e);
}
}
//处理失败的消息
@Override
public void onFailure(Exception e) {
........
}
});
}
使用了countDown多线程工具,fetchResults存储某个分片的结果,每收到一个shard的数据就countDoun一下,当都完毕后,触发finishPhase。接着会进行下一步:
CountedCollector:
final CountedCollector<FetchSearchResult> counter = new CountedCollector<>(fetchResults, docIdsToLoad.length, finishPhase, context);finishPhase:
final Runnable finishPhase = ()
-> moveToNextPhase(searchPhaseController, queryResults, reducedQueryPhase, queryAndFetchOptimization ?
queryResults : fetchResults.getAtomicArray());
执行字段折叠功能,有兴趣可以研究下。即ExpandSearchPhase模块。ES 5.3版本以后支持的Field Collapsing查询。通过该类查询可以轻松实现按Field值进行分类,每个分类获取排名前N的文档。如在菜单行为日志中按菜单名称(用户管理、角色管理等)分类,获取每个菜单排名点击数前十的员工。用户也可以按Field进行Aggregation实现类似功能,但Field Collapsing会更易用、高效。
ExpandSearchPhase执行完了,就返回给客户端结果了。
context.sendSearchResponse(searchResponse, queryResults);处理数据节点请求的线程池为:search
根据前面的两个阶段,数据节点主要处理协调节点的两类请求:query和fetch
这里响应的请求就是第一阶段的query请求
transportService.registerRequestHandler(QUERY_ACTION_NAME, ThreadPool.Names.SAME, ShardSearchRequest::new,
(request, channel, task) -> {
//执行查询
searchService.executeQueryPhase(request, keepStatesInContext(channel.getVersion()), (SearchShardTask) task,
//注册结果监听器
new ChannelActionListener<>(channel, QUERY_ACTION_NAME, request));
});
executeQueryPhase:
public void executeQueryPhase(ShardSearchRequest request, boolean keepStatesInContext,
SearchShardTask task, ActionListener<SearchPhaseResult> listener) {
...........
final IndexShard shard = getShard(request);
rewriteAndFetchShardRequest(shard, request, new ActionListener<ShardSearchRequest>() {
@Override
public void onResponse(ShardSearchRequest orig) {
.......
//执行真正的请求
runAsync(getExecutor(shard), () -> executeQueryPhase(orig, task, keepStatesInContext), listener);
}
@Override
public void onFailure(Exception exc) {
listener.onFailure(exc);
}
});
}
executeQueryPhase会执行loadOrExecuteQueryPhase方法
private void loadOrExecuteQueryPhase(final ShardSearchRequest request, final SearchContext context) throws Exception {
final boolean canCache = indicesService.canCache(request, context);
context.getQueryShardContext().freezeContext();
if (canCache) {
indicesService.loadIntoContext(request, context, queryPhase);
} else {
queryPhase.execute(context);
}
}
这里判断是否从缓存查询,默认启用缓存,缓存的算法默认为LRU,即删除最近最少使用的数据。如果不启用缓存则会执行queryPhase.execute(context);底层调用lucene进行检索,并且进行聚合。
public void execute(SearchContext searchContext) throws QueryPhaseExecutionException {
.......
//聚合预处理
aggregationPhase.preProcess(searchContext);
.......
//全文检索并打分
rescorePhase.execute(searchContext);
.......
//自动补全和纠错
suggestPhase.execute(searchContext);
//实现聚合
aggregationPhase.execute(searchContext);
.......
}关键点:
transportService.registerRequestHandler(FETCH_ID_ACTION_NAME, ThreadPool.Names.SAME, true, true, ShardFetchSearchRequest::new,
(request, channel, task) -> {
searchService.executeFetchPhase(request, (SearchShardTask) task,
new ChannelActionListener<>(channel, FETCH_ID_ACTION_NAME, request));
});ElasticSearch查询分为两类,一类为GET,另一类为SEARCH。它们使用场景不同。
本文主要分析了ElasticSearch分布式查询主体流程,并未对lucene部分进行分析,有兴趣的可以自行查找相关资料。
程序员的核心竞争力其实还是技术,因此对技术还是要不断的学习,关注 “IT巅峰技术” 公众号 ,该公众号内容定位:中高级开发、架构师、中层管理人员等中高端岗位服务的,除了技术交流外还有很多架构思想和实战案例。
作者是 《 消息中间件 RocketMQ 技术内幕》 一书作者,同时也是 “RocketMQ 上海社区”联合创始人,曾就职于拼多多、德邦等公司,现任上市快递公司架构负责人,主要负责开发框架的搭建、中间件相关技术的二次开发和运维管理、混合云及基础服务平台的建设。
我正在用Ruby编写一个简单的程序来检查域列表是否被占用。基本上它循环遍历列表,并使用以下函数进行检查。require'rubygems'require'whois'defcheck_domain(domain)c=Whois::Client.newc.query("google.com").available?end程序不断出错(即使我在google.com中进行硬编码),并打印以下消息。鉴于该程序非常简单,我已经没有什么想法了-有什么建议吗?/Library/Ruby/Gems/1.8/gems/whois-2.0.2/lib/whois/server/adapters/base.
我知道我可以指定某些字段来使用pluck查询数据库。ids=Item.where('due_at但是我想知道,是否有一种方法可以指定我想避免从数据库查询的某些字段。某种反拔?posts=Post.where(published:true).do_not_lookup(:enormous_field) 最佳答案 Model#attribute_names应该返回列/属性数组。您可以排除其中一些并传递给pluck或select方法。像这样:posts=Post.where(published:true).select(Post.attr
我正在尝试查询我的Rails数据库(Postgres)中的购买表,我想查询时间范围。例如,我想知道在所有日期的下午2点到3点之间进行了多少次购买。此表中有一个created_at列,但我不知道如何在不搜索特定日期的情况下完成此操作。我试过:Purchases.where("created_atBETWEEN?and?",Time.now-1.hour,Time.now)但这最终只会搜索今天与那些时间的日期。 最佳答案 您需要使用PostgreSQL'sdate_part/extractfunction从created_at中提取小时
我在Rails上使用带有ruby的solr。一切正常,我只需要知道是否有任何现有代码来清理用户输入,比如以?开头的查询。或* 最佳答案 我不知道执行此操作的任何代码,但理论上可以通过查看parsingcodeinLucene来完成并搜索thrownewParseException(只有16个匹配!)。在实践中,我认为您最好只捕获代码中的任何solr异常并显示“无效查询”消息或类似信息。编辑:这里有几个“sanitizer”:http://pivotallabs.com/users/zach/blog/articles/937-s
我正在为锦标赛开发一个Rails应用程序。我在这个查询中使用了三个模型:classPlayertruehas_and_belongs_to_many:tournamentsclassTournament:destroyclassPlayerMatch"Player",:foreign_key=>"player_one"belongs_to:player_two,:class_name=>"Player",:foreign_key=>"player_two"在tournaments_controller的显示操作中,我调用以下查询:Tournament.where(:id=>params
我想用sunspot重现以下原始solr查询q=exact_term_text:fooORterm_textv:foo*ORalternate_text:bar*但我无法通过标准的太阳黑子界面理解这是否可能以及如何实现,因为看起来:fulltext方法似乎不接受多个文本/搜索字段参数我不知道将什么参数作为第一个参数传递给fulltext,就好像我通过了"foo"或"bar"结果不匹配如果我传递一个空参数,我得到一个q=*:*范围过滤器(例如with(:term).starting_with('foo*')(顾名思义)作为过滤器查询应用,因此不参与评分。似乎可以手动编写字符串(或者可能使
例如,假设我有一个名为Products的模型,并且在ProductsController中,我有以下代码用于product_listView以显示已排序的产品。@products=Product.order(params[:order_by])让我们想象一下,在product_listView中,用户可以使用下拉菜单按价格、评级、重量等进行排序。数据库中的产品不会经常更改。我很难理解的是,每次用户选择新的order_by过滤器时,rails是否必须查询,或者rails是否能够以某种方式缓存事件记录以在服务器端重新排序?有没有一种方法可以编写它,以便在用户排序时rails不会重新查询结果
我目前正在尝试了解RoR。我将两个字符串传递到我的Controller中。一个是随机的十六进制字符串,另一个是电子邮件。该项目用于对数据库进行简单的电子邮件验证。我遇到的问题是当我输入如下内容来测试我的页面时:http://signup.testsite.local/confirm/da2fdbb49cf32c6848b0aba0f80fb78c/bob.villa@gmailcom我在:email的参数散列中得到的全部是'bob'。我在gmail和com之间留下了.,因为那样会导致匹配根本不起作用。我的路由匹配如下:match"confirm/:code/:email"=>"conf
不知何故,我似乎无法获得包含我的聚合的响应...使用curl它按预期工作:HBZUMB01$curl-XPOST"http://localhost:9200/contents/_search"-d'{"size":0,"aggs":{"sport_count":{"value_count":{"field":"dwid"}}}}'我收到回复:{"took":4,"timed_out":false,"_shards":{"total":5,"successful":5,"failed":0},"hits":{"total":90,"max_score":0.0,"hits":[]},"a
我正在寻找一种方便实用的方法来将编码值添加到Ruby中的URL查询字符串。目前,我有:require'open-uri'u=URI::HTTP.new("http",nil,"mydomain.example",nil,nil,"/tv",nil,"show="+URI::encode("Rosie&Jim"),nil)pu.to_s#=>"http://mydomain.example/tv?show=Rosie%20&%20Jim"这不是我要找的,因为我需要得到“http://mydomain.example/tv?show=Rosie%20%26%20Jim”,这样show=值就