人工智能里程碑ChatGPT之最全详解图解

2022年11月30日,美国硅谷的初创公司OpenAI推出了名为ChatGPT的AI聊天机器人,已经拥有超过一百万的用户,受到热烈的讨论,短短几天就火爆全网。它既能完成包括写代码,查BUG,翻译文献,写小说,写商业文案,写游戏策划,作诗等一系列常见文字输出型任务,也可以在和用户对话时,记住对话的上下文,给人一种仿佛是在与真人对话的错觉。ChatGPT的出现成为了人工智能里程碑式的事件。
尽管业内人士认为,ChatGPT仍存在数据训练集不够新、不够全等问题,但在人工智能将走向何方,人工智能与人类的关系将如何发展?这些问题,任然是有待我们思考的问题。
| 模型 | 发布时间以及参数量 |
|---|---|
| GPT-1 | 2018年6月 1.17亿 |
| GPT-2 | 2019年2月 15亿 |
| GPT-3 | 2020年11月 1750亿 |
| ChatGPT | 2022年11月 千亿级 |
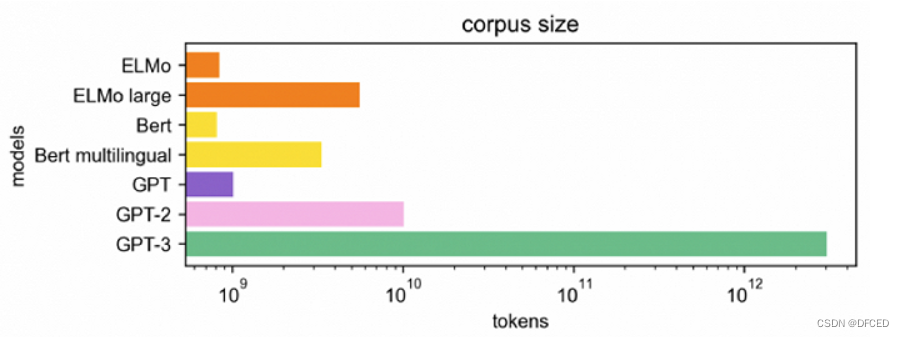 不同模型的数据集规模 不同模型的数据集规模 |
| 时间 模型 | 相关论文 |
|---|---|
| 2017年6月 Transformer模型 | 《Attention is all you need》 GPT发展的基础 |
| 2018年6月 GPT模型(Generative Pre-Training) | 《Improving Language Understanding by Generative Pre-Training》 通过生成式预训练提升语言理解能力 |
| 2019年2月 GPT-2模型 | 《Language Models are Unsupervised Multitask Learners》 提出了一个无监督多任务学习者 |
| 2020年5月 GPT-3模型 | 《Language Models are Few-Shot Learners》 少样本下的学习模型 |
| 2022年2月底 Instruction GPT模型 | 《Training language models to follow instructions with human feedback》 使用反馈指令流来控制模型 |
| 2022年11月30日 ChatGPT模型 | ChatGPT发布 |

 (以上图片来自于网络)
(以上图片来自于网络)
移动互联网领域 - 围绕ChatGPT打造硬件生态,可能产生新的生态。毕竟已经有网友表示愿意为ChatGPT每月付费1千美元,而且这样的个性化助理一旦与用户适配,切换难度极高。 为了强调个人助理的作用,手机或许会重新改名为PDA(个人数字化助手)。 当然,由于谷歌、DeepMind、Meta等公司都会产生这一技术,OpenAI未必一家独大。还可能出现“个人助理专家组”。例如各家助理给苹果提供API,苹果作为委员会组长,收集整合各家意见后再提供给用户。
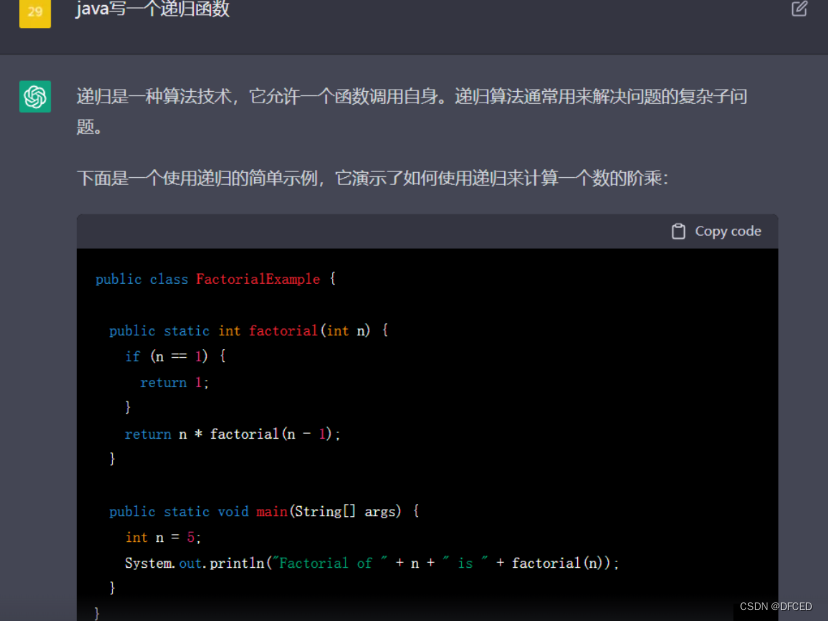
ChatGPT全称Generative Pre-Training Transfomer,我们来拆解一下,Generative:可生成的,生成式的
Pre-Training:预训练
Transfomer:专有名词不译为好。直译:变换器 意译:依靠自注意机制将输入嵌入序列转换为输出嵌入序列,不依赖卷积或循环神经网络的一种神经网络结构。
如下图所示,Transformer由self-Attenion和Feed Forward Neural Network组成
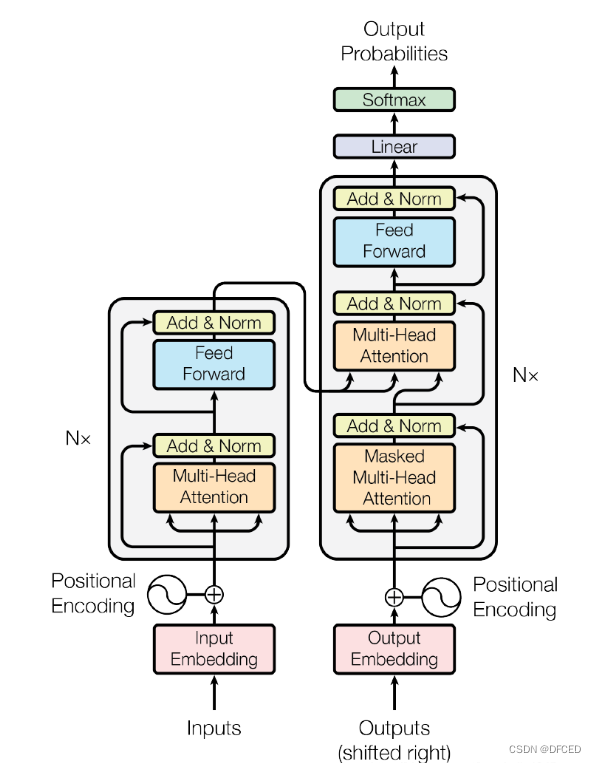
如下图所示,Transformer由四部分组成
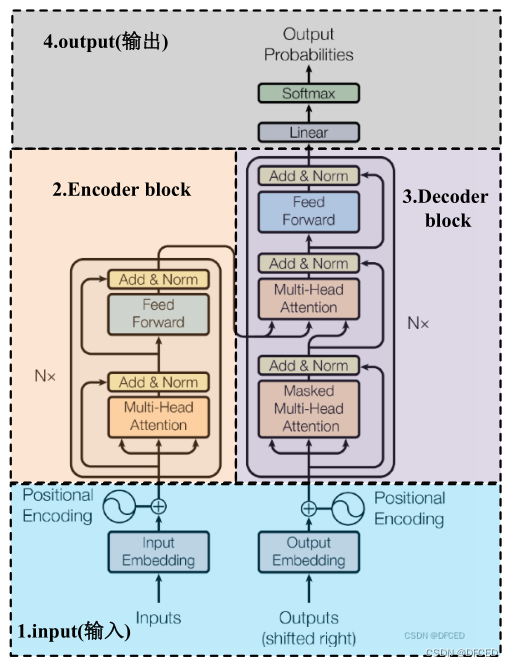
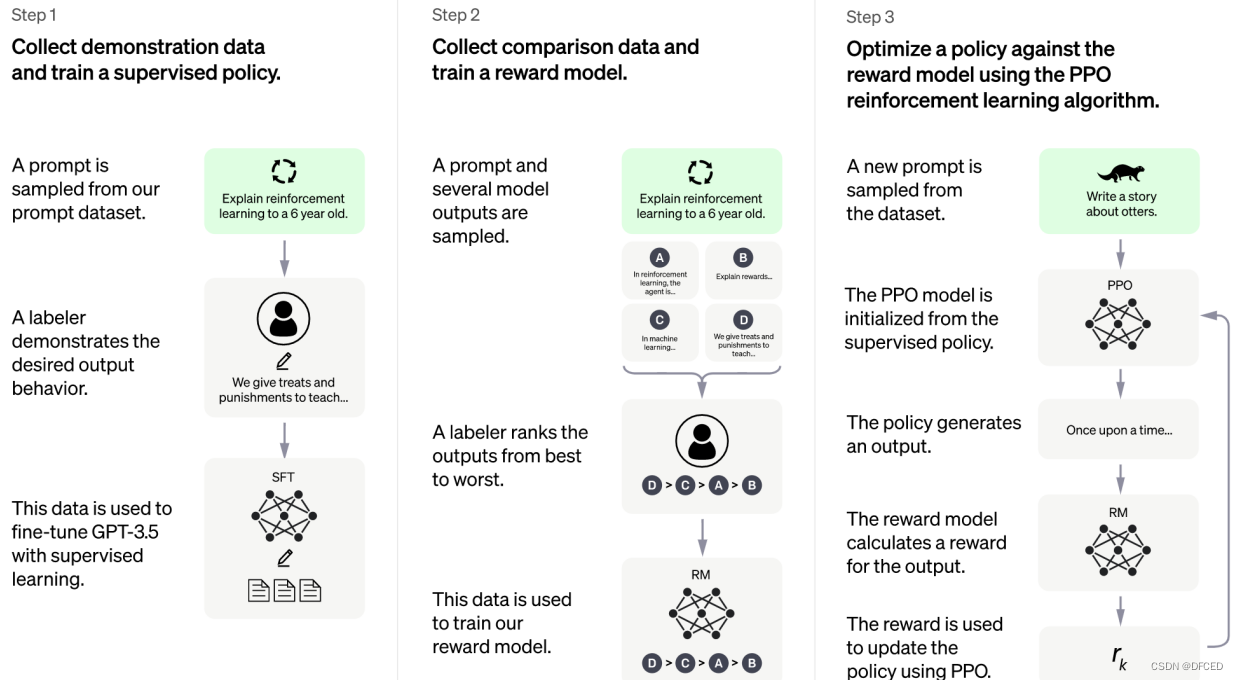
GPT 3.5本身很难理解人类不同类型指令中蕴含的不同意图,也很难判断生成内容是否是高质量的结果。为了让GPT 3.5初步具备理解指令的意图,首先会在数据集中随机抽取问题,由专业的人类标注人员,给出每个问题(prompt)的高质量答案,形成(prompt,answer)问答对,然后用这些人工标注好的数据来微调 GPT-3.5模型(获得SFT模型, Supervised Fine-Tuning)。
经过这个过程,可以认为SFT初步具备了理解人类问题中所包含意图,并根据这个意图给出相对高质量回答的能力,但是很明显,仅仅这样做是不够的,因为其回答不一定符合人类偏好。
这个阶段主要是通过人工标注训练数据,来训练奖励模型(Reward Mode)。在数据集中随机抽取问题,使用第一阶段训练得到的模型,对于每个问题,生成多个不同的回答。人类标注者对这些结果综合考虑(例如:相关性、富含信息性、有害信息等诸多标准)给出排名顺序。这一过程类似于教练或老师辅导。
接下来,使用这个排序结果数据来训练奖励模型。对多个排序结果,两两组合,形成多个训练数据对。奖励模型接受一个输入,给出评价回答质量的分数。这样,对于一对训练数据,调节参数使得高质量回答的打分比低质量的打分要高。
PPO(Proximal Policy Optimization,近端策略优化)强化学习模型的核心思路在于将Policy Gradient中On-policy的训练过程转化为Off-policy,即将在线学习转化为离线学习,这个转化过程被称之为Importance Sampling。PPO由第一阶段的监督策略模型来初始化模型的参数,这一阶段利用第二阶段训练好的奖励模型,靠奖励打分来更新预训练模型参数。具体而言,在数据集中随机抽取问题,使用PPO模型生成回答,并用上一阶段训练好的奖励模型给出质量分数。把奖励分数依次传递,由此产生策略梯度,通过强化学习的方式以更新PPO模型参数。
如果我们不断重复第二和第三阶段,通过迭代,会训练出更高质量的ChatGPT模型。
关于如何注册ChatGPT请关注我的文章
每隔一段时间,我们的邮箱总是会收到很多积压邮件,其中很多商务性质的邮件需要我们一一回复。这些商务邮件的回复涉及人情世故,要仔细把握语气,认真遣词造句,非常费神。这些工作不如交给ChatGPT来代笔,比如让ChatGPT “帮我写商务邮件回信,告知对方需求已经收到,我们正在全力跟进”。
在给别人回信时,也可以使用ChatGPT来回复,比如感谢朋友的来信,让ChatGPT写一封感谢朋友并邀请朋友来家做客的信件。
可以使用ChatGPT修复代码中的错误并获得调试帮助,同时也可以让ChatGPT写带有注释的代码,极大简化了程序员的工作流程
可以使用ChatGPT生成初稿,提高工作效率,同时也可以将其作为素材使用。当然,在闲暇之余,还可以使用ChatGPT写几首诗陶冶陶冶自己的情操,并且可以问ChatGPT几个有趣的问题娱乐一下,放松放松心情。
ChatGPT的训练数据是基于互联网世界海量文本数据的,如果这些文本数据本身不准确或者带有某种偏见,目前的ChatGPT是无法进行分辨的,因此在回答问题的时候会不可避免的将这种不准确以及偏见传递出来。
ChatGPT属于NPL领域中的非常大的深度学习模型,其训练参数以及训练数据都非常巨大,因此如果想训练ChatGPT就需要使用大型数据中心以及云计算资源,以及大量的算力和存储空间来处理海量的训练数据,简单来说训练和使用ChatGPT的成本还是非常高的。
目前ChatGPT主要可以处理自然语言方面的问答以及任务,在其他领域比如图像识别、语音识别等还不局必然相应的处理能力,但是相信在不远的将来可能会有结合图片,视频,音频的GPT,让我们拭目以待。
如果ChatGPT通过抓取互联网上的信息获得其训练数据,可能并不合法。网站上的隐私政策条款本身表明数据不能被第三方收集,ChatGPT抓取数据会涉及违反合同。在许多司法管辖区,合理使用原则在某些情况下允许未经所有者同意或版权使用信息,包括研究、引用、新闻报道、教学讽刺或批评目的。但是ChatGPT并不适用该原则,因为合理使用原则只允许访问有限信息,而不是获取整个网站的信息。在个人层面,ChatGPT需要解决未经用户同意大量数据抓取是否涉及侵犯个人信息的问题。
用户在使用ChatGPT时会输入信息,由于ChatGPT强大的功能,一些员工使用ChatGPT辅助其工作,这引起了公司对于商业秘密泄露的担忧。因为输入的信息可能会被用作ChatGPT进一步迭代的训练数据。
ChatGPT用户必须同意公司可以使用用户和ChatGPT产生的所有输入和输出,同时承诺ChatGPT会从其使用的记录中删除所有个人身份信息。然而ChatGPT未说明其如何删除信息,而且由于被收集的数据将用于ChatGPT不断的学习中,很难保证完全擦除个人信息痕迹。
ChatGPT可以说是人工智能发展史上的里程碑之作,它使得人类距离通用人工智能,强人工智能更近了一步,ChatGPT强大的功能令人瞠目结舌,同时它也面临着诸多挑战,但是我们可以相信,在不远的将来,ChatGPT一定会迈上新的台阶,强人工智能时代也终将会到来,那时的人类社会一定会发生前所未有的新变化,也终将迎来第五次工业革命,人工智能也终将成为人类发展史上璀璨的明珠

英文版英文链接关注公众号在“亚特兰蒂斯的回声”中踏上一段难忘的冒险之旅,深入未知的海洋深处。足智多谋的考古学家AriaSeaborne偶然发现了一件古代神器,揭示了一张通往失落之城亚特兰蒂斯的隐藏地图。在她神秘的导师内森·兰登教授的指导和勇敢的冒险家亚历克斯·默瑟的帮助下,阿丽亚开始了一段危险的旅程,以揭开这座传说中城市的真相。他们的冒险之旅带领他们穿越险恶的大海、神秘的岛屿和充满陷阱和谜语的致命迷宫。随着Aria潜在的魔法能力的觉醒,她被睿智勇敢的QueenNeria的幻象所指引,她让她为即将到来的挑战做好准备。三人组揭开亚特兰蒂斯令人惊叹的隐藏文明,并了解到邪恶的巫师马拉卡勋爵试图利用其古
前面一篇关于智能合约翻译文讲到了,是一种计算机程序,既然是程序,那就可以使用程序语言去编写智能合约了。而若想玩区块链上的项目,大部分区块链项目都是开源的,能看得懂智能合约代码,或找出其中的漏洞,那么,学习Solidity这门高级的智能合约语言是有必要的,当然,这都得在公链``````以太坊上,毕竟国内的联盟链有些是不兼容Solidity。Solidity是一种面向对象的高级语言,用于实现智能合约。智能合约是管理以太坊状态下的账户行为的程序。Solidity是运行在以太坊(Ethereum)虚拟机(EVM)上,其语法受到了c++、python、javascript影响。Solidity是静态类型
一、什么是MQTT协议MessageQueuingTelemetryTransport:消息队列遥测传输协议。是一种基于客户端-服务端的发布/订阅模式。与HTTP一样,基于TCP/IP协议之上的通讯协议,提供有序、无损、双向连接,由IBM(蓝色巨人)发布。原理:(1)MQTT协议身份和消息格式有三种身份:发布者(Publish)、代理(Broker)(服务器)、订阅者(Subscribe)。其中,消息的发布者和订阅者都是客户端,消息代理是服务器,消息发布者可以同时是订阅者。MQTT传输的消息分为:主题(Topic)和负载(payload)两部分Topic,可以理解为消息的类型,订阅者订阅(Su
TCL脚本语言简介•TCL(ToolCommandLanguage)是一种解释执行的脚本语言(ScriptingLanguage),它提供了通用的编程能力:支持变量、过程和控制结构;同时TCL还拥有一个功能强大的固有的核心命令集。TCL经常被用于快速原型开发,脚本编程,GUI和测试等方面。•实际上包含了两个部分:一个语言和一个库。首先,Tcl是一种简单的脚本语言,主要使用于发布命令给一些互交程序如文本编辑器、调试器和shell。由于TCL的解释器是用C\C++语言的过程库实现的,因此在某种意义上我们又可以把TCL看作C库,这个库中有丰富的用于扩展TCL命令的C\C++过程和函数,所以,Tcl是
2022年底,OpenAI的预训练模型ChatGPT给人工智能领域的爱好者和研究人员留下了深刻的印象和启发,他展现的惊人能力将人工智能的研究和应用热度推向高潮,网上也充斥着和ChatGPT的各种聊天,他可以作诗、写小说、写代码、讨论疫情问题等。下面就是一些他的神回复:人命关天的坑: 写歌,留给词作者的机会不多了。。。 回答人类怎么样面对人工智能: 什么是ChatGPT?借用网上的一段介绍,ChatGPT是由人工智能研究实验室OpenAI在2022年11月30日发布的全新聊天机器人模型,一款人工智能技术驱动的自然语言处理工具。它能够通过学习和理解人类的语言来进行对话,还能根据聊天的上下文进行互动
目录ChatGPT简介技术原理应用未来发展ChatGPT的10 种用法ChatGPT简介ChatGPT是一种基于深度学习的大型语言模型,由OpenAI公司开发。技术原理GPT是GenerativePre-trainedTransformer的缩写,意为生成式预训练变压器。它的技术原理是使用了一个基于注意力机制的变压器(Trans
开门见山|拉取镜像dockerpullelasticsearch:7.16.1|配置存放的目录#存放配置文件的文件夹mkdir-p/opt/docker/elasticsearch/node-1/config#存放数据的文件夹mkdir-p/opt/docker/elasticsearch/node-1/data#存放运行日志的文件夹mkdir-p/opt/docker/elasticsearch/node-1/log#存放IK分词插件的文件夹mkdir-p/opt/docker/elasticsearch/node-1/plugins若你使用了moba,直接右键新建即可如上图所示依次类推创建
文章目录概念索引相关操作创建索引更新副本查看索引删除索引索引的打开与关闭收缩索引索引别名查询索引别名文档相关操作新建文档查询文档更新文档删除文档映射相关操作查询文档映射创建静态映射创建索引并添加映射概念es中有三个概念要清楚,分别为索引、映射和文档(不用死记硬背,大概有个印象就可以)索引可理解为MySQL数据库;映射可理解为MySQL的表结构;文档可理解为MySQL表中的每行数据静态映射和动态映射上面已经介绍了,映射可理解为MySQL的表结构,在MySQL中,向表中插入数据是需要先创建表结构的;但在es中不必这样,可以直接插入文档,es可以根据插入的文档(数据),动态的创建映射(表结构),这就
♥️作者:白日参商🤵♂️个人主页:白日参商主页♥️坚持分析平时学习到的项目以及学习到的软件开发知识,和大家一起努力呀!!!🎈🎈加油!加油!加油!加油🎈欢迎评论💬点赞👍🏻收藏📂加关注+!「想体验ChatGPT中文聊天?」那快进来,你用不上算我输项目场景:项目条件一、那就开始吧1、安装ChatGPT-Desktop2、OpenAPI设置二、使用实例恭喜你!!!配置成功了!!!API和URL都是博主免费提供给大家的!!!恭喜你!!!配置成功了!!!API和URL都是博主免费提供给大家的!!!🎈🎈加油!加油!加油!加油🎈欢迎评论💬点赞👍🏻收藏📂加关注+!项目场景:近几个月可以说ChatGPT是火得一
HTTP缓存是指浏览器或者代理服务器将已经请求过的资源保存到本地,以便下次请求时能够直接从缓存中获取资源,从而减少网络请求次数,提高网页的加载速度和用户体验。缓存分为强缓存和协商缓存两种模式。一.强缓存强缓存是指浏览器直接从本地缓存中获取资源,而不需要向web服务器发出网络请求。这是因为浏览器在第一次请求资源时,服务器会在响应头中添加相关缓存的响应头,以表明该资源的缓存策略。常见的强缓存响应头如下所述:Cache-ControlCache-Control响应头是用于控制强制缓存和协商缓存的缓存策略。该响应头中的指令如下:max-age:指定该资源在本地缓存的最长有效时间,以秒为单位。例如:Ca