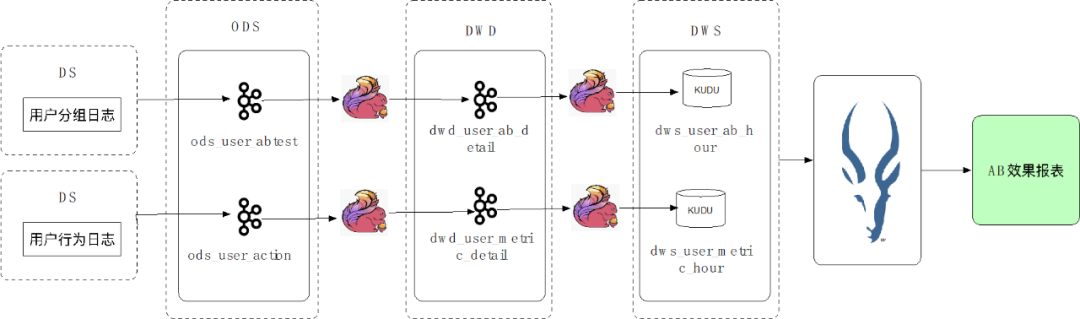
 第一步:用户的日志数据经过实时采集写入 ODS 层的 Kafka 中。ODS 层数据为原始未加工的业务数据,保存在 Kafka,7 天后自动清理。第二步:ODS 层数据经过 Flink 任务处理写入 DWD 层 Kafka 中。DWD 层数据为经过清洗的数据。第三步:DWD 层数据经过 Flink 任务处理写入 DWS 层 KUDU 数据库中落库。DWS 层数据为经过聚合、过滤等加工步骤,可以向业务方提供的数据。第四步:业务方在需要时通过 Impala 查询 KUDU 数据库中的数据生成报表。通过以上实时数据加工链路,业务方可实现实时报表展示,时效性较离线加工链路大大提高,可以满足业务方要求数据实时更新的需求。
第一步:用户的日志数据经过实时采集写入 ODS 层的 Kafka 中。ODS 层数据为原始未加工的业务数据,保存在 Kafka,7 天后自动清理。第二步:ODS 层数据经过 Flink 任务处理写入 DWD 层 Kafka 中。DWD 层数据为经过清洗的数据。第三步:DWD 层数据经过 Flink 任务处理写入 DWS 层 KUDU 数据库中落库。DWS 层数据为经过聚合、过滤等加工步骤,可以向业务方提供的数据。第四步:业务方在需要时通过 Impala 查询 KUDU 数据库中的数据生成报表。通过以上实时数据加工链路,业务方可实现实时报表展示,时效性较离线加工链路大大提高,可以满足业务方要求数据实时更新的需求。 第一步:通过 CDC 任务采集用户访问数据数据实时变更至 Kafka(对应案例步骤第一步)第二步:将 ODS 层 Kafka 数据通过 Flink 任务进行清洗和聚合,写入 MySQL 落库(对应案例步骤第二、三步)第三步:将 MySQL 数据通过 BI 报表展示(对应案例最终结果)
第一步:通过 CDC 任务采集用户访问数据数据实时变更至 Kafka(对应案例步骤第一步)第二步:将 ODS 层 Kafka 数据通过 Flink 任务进行清洗和聚合,写入 MySQL 落库(对应案例步骤第二、三步)第三步:将 MySQL 数据通过 BI 报表展示(对应案例最终结果)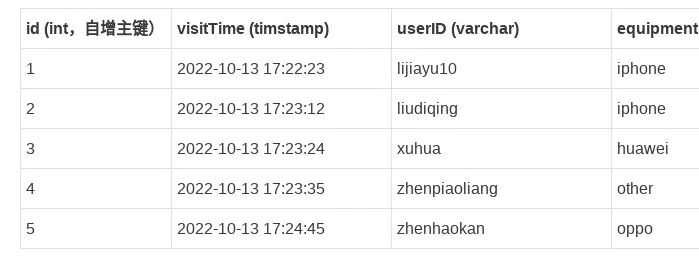 (2)准备 DWD 层结果表:DAU_FINAL此表用于统计最终结果。表结构如下:
(2)准备 DWD 层结果表:DAU_FINAL此表用于统计最终结果。表结构如下: 注意:由于模拟案例最终希望直接展示不同用户的计算结果,故需要向同一张已提前制作好对应 BI 报表的表内写数据,每人更新一行数据。正常业务场景下根据业务需求决定结果表结构和数量。
注意:由于模拟案例最终希望直接展示不同用户的计算结果,故需要向同一张已提前制作好对应 BI 报表的表内写数据,每人更新一行数据。正常业务场景下根据业务需求决定结果表结构和数量。 3.2.2 编辑 CDC 任务源端配置:表:DAU_DS传输起始位点:若只想消费新增数据,请选择最新数据,最终结果报表中将仅有体验当日的数据。若想先消费历史存量数据,之后再消费最新数据,请选择全量初始化,最终结果报表中将有历史数据。
3.2.2 编辑 CDC 任务源端配置:表:DAU_DS传输起始位点:若只想消费新增数据,请选择最新数据,最终结果报表中将仅有体验当日的数据。若想先消费历史存量数据,之后再消费最新数据,请选择全量初始化,最终结果报表中将有历史数据。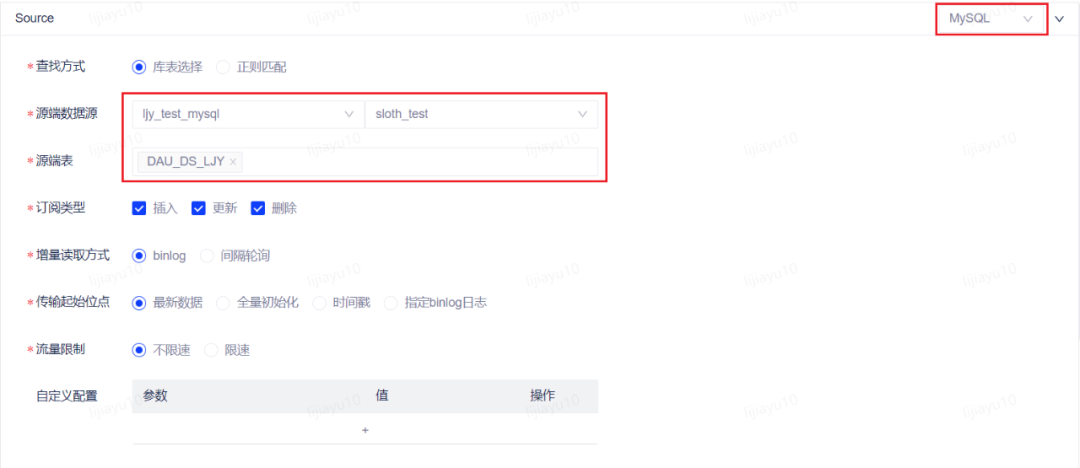 目标端配置:类型:kafka数据源:poc_kafkaTopic:自行命名,可通过目标 Topic 生成规则生成,也可在目标 Topic 中手动修改,建议修改目标 Topic 名称为自己的名称,方便下一步新建流表时使用。此处选择不存在的 Topic,在任务运行后对应 Topic 将被自动创建。序列化方式:canal-json
目标端配置:类型:kafka数据源:poc_kafkaTopic:自行命名,可通过目标 Topic 生成规则生成,也可在目标 Topic 中手动修改,建议修改目标 Topic 名称为自己的名称,方便下一步新建流表时使用。此处选择不存在的 Topic,在任务运行后对应 Topic 将被自动创建。序列化方式:canal-json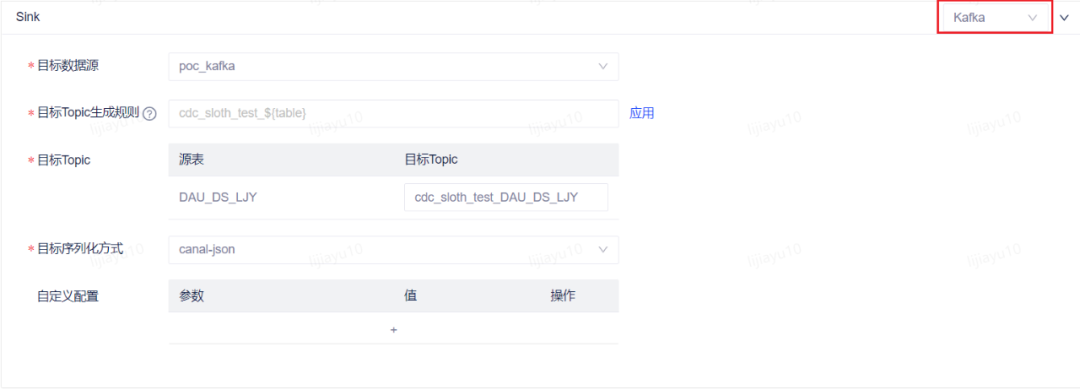 3.2.3 保存并一键发布任务点击页面上方的 保存 和 一键发布 按钮,填写任意提交描述,将任务发布至实时运维列表。
3.2.3 保存并一键发布任务点击页面上方的 保存 和 一键发布 按钮,填写任意提交描述,将任务发布至实时运维列表。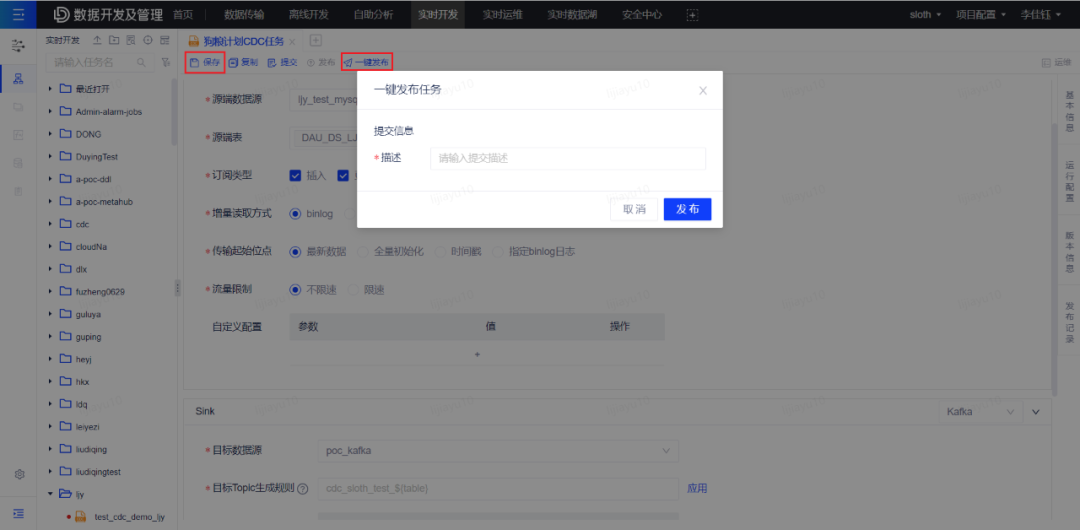 成功发布后可点击 运维 按钮前往任务运维页面。3.2.4 启动任务在运维页面找到对应任务后点击 启动 按钮启动任务。
成功发布后可点击 运维 按钮前往任务运维页面。3.2.4 启动任务在运维页面找到对应任务后点击 启动 按钮启动任务。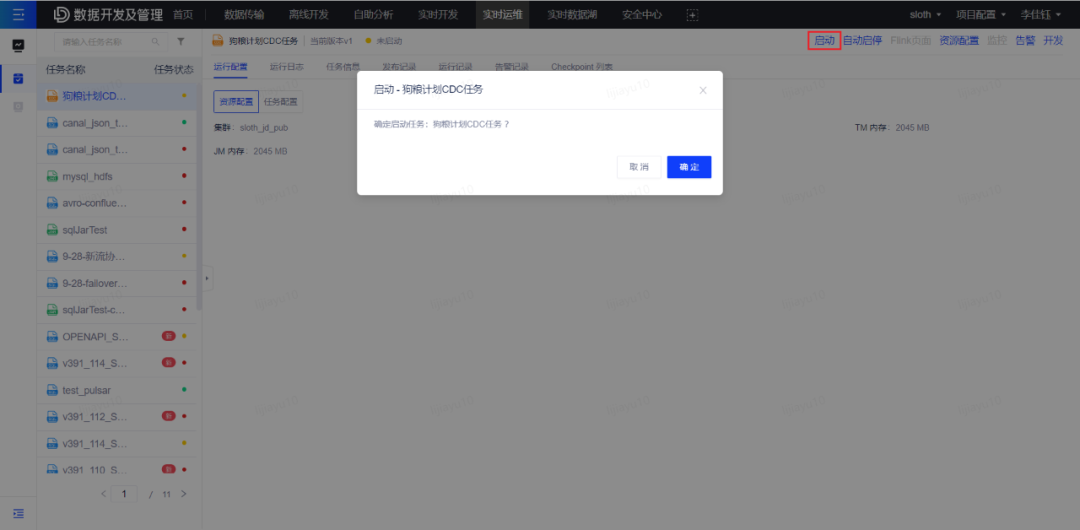 任务成功启动,任务状态变为运行中时,创建 CDC 任务步骤操作完成。
任务成功启动,任务状态变为运行中时,创建 CDC 任务步骤操作完成。 表名:自行命名topic:填写上一步 CDC 任务的目标 Topic 名称序列化方式:canal-json
表名:自行命名topic:填写上一步 CDC 任务的目标 Topic 名称序列化方式:canal-json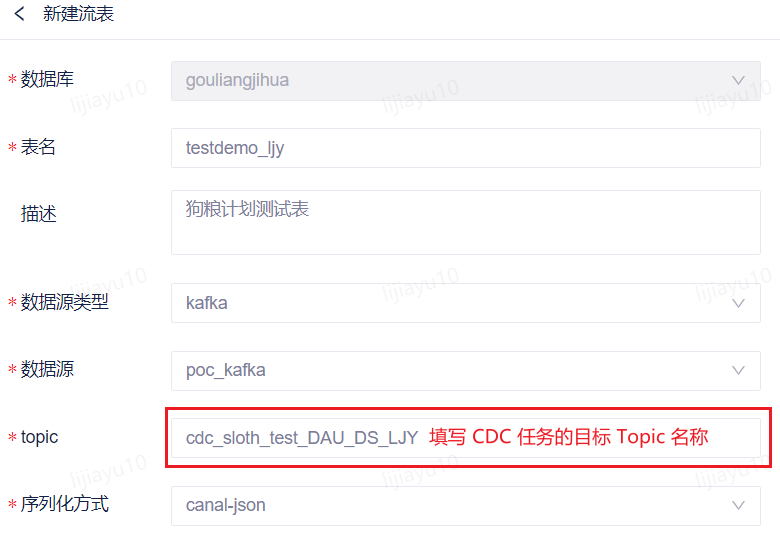 填写完以上信息后可开始进行字段自动解析。字段信息获取方式选择自动解析,之后点击获取数据,获取到数据样例后点击解析,即可解析出流表的字段信息。Tip:若 CDC 任务正常运行但此处未获取到样例数据,可能是因为数据暂未写入,稍等一分钟后重新尝试。
填写完以上信息后可开始进行字段自动解析。字段信息获取方式选择自动解析,之后点击获取数据,获取到数据样例后点击解析,即可解析出流表的字段信息。Tip:若 CDC 任务正常运行但此处未获取到样例数据,可能是因为数据暂未写入,稍等一分钟后重新尝试。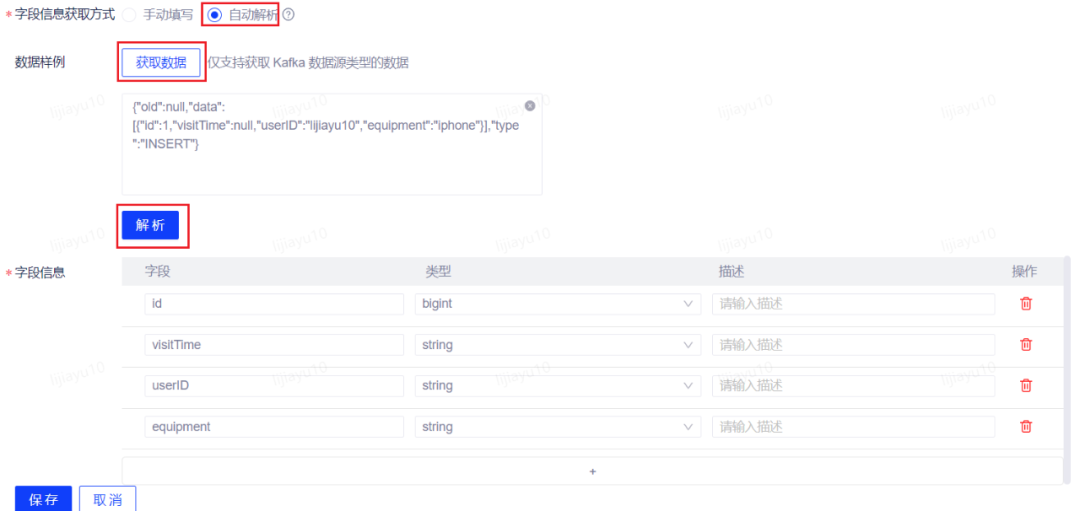 字段信息确认无误后即可保存流表。保存流表成功,即为此步骤操作完成。
字段信息确认无误后即可保存流表。保存流表成功,即为此步骤操作完成。-- 设置Kafka消费者组id,需要更改自己创建的流表名称, 配置方式:'{流表名称}.connections.group.id' = '{groupid-name}'set '这里填流表名称.connections.group.id' = 'example001'; -- 设置读取消息队列的位置, 配置方式:'{流表名称}.scan.startup.mode' = '{earliest-offset / latest-offset}'set '这里填流表名称.scan.startup.mode' = 'earliest-offset'; -- 设置流表主键,配置方式:'{流表名称}.primary.keys' = '{primary key name}'set '这里填流表名称.primary.keys' = 'id';--设置源端表表名CREATE view v1 ASSELECT SUBSTRING(visitTime, 0, 10) AS `date`, equipment from 这里填流表库名称.这里填流表名称;CREATE view v2 AS SELECT `date`, equipment, COUNT(equipment) AS eq_dauFROM v1GROUP BY `date`, equipment;--将你的名字填入 submitter 字段CREATE view v3 ASSELECT '这里填你的名字' AS submitter, `date`, SUM(CASE equipment WHEN 'iPhone' THEN eq_dau ELSE 0 END) AS iPhoneDAU, SUM(CASE equipment WHEN 'Huawei' THEN eq_dau ELSE 0 END) AS HuaweiDAU, SUM(CASE equipment WHEN 'OPPO' THEN eq_dau ELSE 0 END) AS oppoDAU, SUM(CASE equipment WHEN 'other' THEN eq_dau ELSE 0 END) AS otherDAUFROM v2 GROUP BY `date`;CREATE VIEW v4 ASSELECT (v3.iPhoneDAU + v3.HuaweiDAU + v3.oppoDAU + v3.otherDAU) AS totalDAU, submitter, `date`, iPhoneDAU, HuaweiDAU, oppoDAU, otherDAUFROM v3;set 'DAU_FINAL.primary.keys' = 'submitter,date';INSERT INTO MySQL数据源标识.MySQL数据库名称.DAU_FINALSELECT * FROM v4; (2)报表
(2)报表
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
使用带有Rails插件的vim,您可以创建一个迁移文件,然后一次性打开该文件吗?textmate也可以这样吗? 最佳答案 你可以使用rails.vim然后做类似的事情::Rgeneratemigratonadd_foo_to_bar插件将打开迁移生成的文件,这正是您想要的。我不能代表textmate。 关于ruby-使用VimRails,您可以创建一个新的迁移文件并一次性打开它吗?,我们在StackOverflow上找到一个类似的问题: https://sta
我需要从一个View访问多个模型。以前,我的links_controller仅用于提供以不同方式排序的链接资源。现在我想包括一个部分(我假设)显示按分数排序的顶级用户(@users=User.all.sort_by(&:score))我知道我可以将此代码插入每个链接操作并从View访问它,但这似乎不是“ruby方式”,我将需要在不久的将来访问更多模型。这可能会变得很脏,是否有针对这种情况的任何技术?注意事项:我认为我的应用程序正朝着单一格式和动态页面内容的方向发展,本质上是一个典型的网络应用程序。我知道before_filter但考虑到我希望应用程序进入的方向,这似乎很麻烦。最终从任何
我想要做的是有2个不同的Controller,client和test_client。客户端Controller已经构建,我想创建一个test_clientController,我可以使用它来玩弄客户端的UI并根据需要进行调整。我主要是想绕过我在客户端中内置的验证及其对加载数据的管理Controller的依赖。所以我希望test_clientController加载示例数据集,然后呈现客户端Controller的索引View,以便我可以调整客户端UI。就是这样。我在test_clients索引方法中试过这个:classTestClientdefindexrender:template=>
如果您尝试在Ruby中的nil对象上调用方法,则会出现NoMethodError异常并显示消息:"undefinedmethod‘...’fornil:NilClass"然而,有一个tryRails中的方法,如果它被发送到一个nil对象,它只返回nil:require'rubygems'require'active_support/all'nil.try(:nonexisting_method)#noNoMethodErrorexceptionanymore那么try如何在内部工作以防止该异常? 最佳答案 像Ruby中的所有其他对象
关闭。这个问题需要detailsorclarity.它目前不接受答案。想改进这个问题吗?通过editingthispost添加细节并澄清问题.关闭8年前。Improvethisquestion为什么SecureRandom.uuid创建一个唯一的字符串?SecureRandom.uuid#=>"35cb4e30-54e1-49f9-b5ce-4134799eb2c0"SecureRandom.uuid方法创建的字符串从不重复?
我有一个正在构建的应用程序,我需要一个模型来创建另一个模型的实例。我希望每辆车都有4个轮胎。汽车模型classCar轮胎模型classTire但是,在make_tires内部有一个错误,如果我为Tire尝试它,则没有用于创建或新建的activerecord方法。当我检查轮胎时,它没有这些方法。我该如何补救?错误是这样的:未定义的方法'create'forActiveRecord::AttributeMethods::Serialization::Tire::Module我测试了两个环境:测试和开发,它们都因相同的错误而失败。 最佳答案
我想在Ruby中创建一个用于开发目的的极其简单的Web服务器(不,不想使用现成的解决方案)。代码如下:#!/usr/bin/rubyrequire'socket'server=TCPServer.new('127.0.0.1',8080)whileconnection=server.acceptheaders=[]length=0whileline=connection.getsheaders想法是从命令行运行这个脚本,提供另一个脚本,它将在其标准输入上获取请求,并在其标准输出上返回完整的响应。到目前为止一切顺利,但事实证明这真的很脆弱,因为它在第二个请求上中断并出现错误:/usr/b
我想让一个yaml对象引用另一个,如下所示:intro:"Hello,dearuser."registration:$introThanksforregistering!new_message:$introYouhaveanewmessage!上面的语法只是它如何工作的一个例子(这也是它在thiscpanmodule中的工作方式。)我正在使用标准的rubyyaml解析器。这可能吗? 最佳答案 一些yaml对象确实引用了其他对象:irb>require'yaml'#=>trueirb>str="hello"#=>"hello"ir
我的问题的一个例子是体育游戏。一场体育比赛有两支球队,一支主队和一支客队。我的事件记录模型如下:classTeam"Team"has_one:away_team,:class_name=>"Team"end我希望能够通过游戏访问一个团队,例如:Game.find(1).home_team但我收到一个单元化常量错误:Game::team。谁能告诉我我做错了什么?谢谢, 最佳答案 如果Gamehas_one:team那么Rails假设您的teams表有一个game_id列。不过,您想要的是games表有一个team_id列,在这种情况下