词法分析器的功能:输入源程序,输出单词字符。单词字符一般可以分为下面五种。
(1)关键字 是由程序语言定义的具有固定意义的标识符。有时称这些标识符为保留字或者基本字。例如c语言中的int,char,define,strcut,double,if,else.等等
(2)标识符 用来表示各种名字,如变量名,数组名,过程名。
(3)常数 常数的类型一般有整形,实型,布尔型等
(4)运算符 如+,-,*,/。
(5)界符 如逗号,分号,括号,%,//,等。
词法分析器的目标就是把程序分成一个一个单词。并给出单词符号的种类,以及种类值。
代码实现:
代码是贴的别人的,我在上面改善了一些实现的功能。自己发了三四个小时看明白了。自己完完全全写的确好多东西要学一下。比如一些文件的操作还不是特别的熟悉。等等呀!代码中还用到了结构体,我之前也做过一篇文章分析了,这里用结构体来实现关键字表,应该不是很难的。
普通标识符的种类编码1
无符号整数的种类编码2
“int”,的种类编码3
“char”,的种类编码4
“float”,的种类编码5
“main”,的种类编码6
“double”,的种类编码7
“case”, 的种类编码8
“for”,的种类编码9
“if”,的种类编码10
“auto”,的种类编码11
“else”,的种类编码12
“do”,的种类编码13
“while”,的种类编码14
“void”,的种类编码15
“static”, 的种类编码16
“return”,的种类编码17
“break”,的种类编码18
“struct”,的种类编码19
“const”,的种类编码20
“union”,的种类编码21
“switch”,的种类编码22
“typedef”,的种类编码23
"enum"的种类编码24
( 的种类编码25
)的种类编码26
[ 的种类编码27
] 的种类编码28
; 的种类编码29
. 的种类编码30
, 的种类编码31
: 的种类编码32
{的种类编码33
} 的种类编码34
% 的种类编码35
" 的种类编码36
\ 的种类编码37
# 的种类编码38
/ 的种类编码39
++的种类编码41
+=的种类编码42
+的种类编码43
–的种类编码44
-=的种类编码45
-的种类编码46
*的种类编码47
=的种类编码48
>= 的种类编码49
> 的种类编码50
等
那个模块不是很清楚的话可以评论哈!!!
/*附录源程序清单:*/
#include<string.h>
#include<stdio.h>
#define MAX 22 /*分析}表的最大容量*/
#define RES_MAX 10 /*关键字的最大长度*/
#define MAXBUF 255 /*缓冲区的大小*/
char ch =' '; /*存放读入当前的输入字符*/
int Line_NO; /*纪录行号*/
struct keywords /*关键字*/
{
char lexptr[MAXBUF];
int token;
};
struct keywords symtable[MAX];
char str[MAX][10]={"int","char","float","main","double","case", "for","if","auto","else","do","while","void","static", "return","break","struct","const","union","switch","typedef","enum"};
/*对关键字表进行初始化,div,mod,and,or也作为关键字处理*/
/*最小的token是program:3,最大的token是or:24*/
void init()
{
int j;
for(j=0; j<MAX; j++)
{
strcpy(symtable[j].lexptr,str[j]);
symtable[j].token=j+3;
}
}
/***************对关键字进行搜索**************/
int Iskeyword(char * is_res){
int i;
for(i=0;i<MAX;i++){
if((strcmp(symtable[i].lexptr,is_res))==0) break;
}
if(i<MAX) return symtable[i].token;
else return 0;
}
/*****************判断是否为字母*****************/
int IsLetter(char c)
{
if(((c<='z')&&(c>='a'))||((c<='Z')&&(c>='A'))) return 1;
else return 0;
}
/*************判断是否为数字**************/
int IsDigit(char c){
if(c>='0'&&c<='9') return 1;
else return 0;
}
/***************分析程序**************/
void analyse(FILE *fpin,FILE *fpout){
/* 输入缓冲区,存放一个单词符号 */
char arr[MAXBUF];
int j=0;
while((ch=fgetc(fpin))!=EOF){
/*碰到空格、tab则跳过*/
if(ch==' '||ch=='\t'){}
else if(ch=='\n'){Line_NO++;}
/*********************字符串的处理*************************/
else if(IsLetter(ch)){
while(IsLetter(ch)|IsDigit(ch)|ch=='_'){
if((ch<='Z')&&(ch>='A'))
ch=ch+32; /*忽略大小写*/
arr[j]=ch;
j++;
ch=fgetc(fpin);
}
/*输入指针回退一个字符*/
fseek(fpin,-1L,SEEK_CUR);
arr[j]='\0';
j=0;
if (Iskeyword(arr)){ /*如果是关键字*/
fprintf(fpout,"%s\t\t%d\t\t关键字\n",arr,Iskeyword(arr));
}else
fprintf(fpout,"%s\t\t%d\t\t标识符\n",arr,1); /*普通标识符*/
/*************************数字的处理****************************/
}else if(IsDigit(ch)){
int s=0;
while(IsDigit(ch)|IsLetter(ch)){
if(IsLetter(ch)){
arr[j]=ch;
j++;
ch=fgetc(fpin);
s=1;
}
else if(IsDigit(ch)){
arr[j]=ch;
j++;
ch=fgetc(fpin);
}
}
fseek(fpin,-1L,SEEK_CUR);
arr[j]='\0';
j=0;
if(s==0)
fprintf(fpout,"%s\t\t%d\t\t无符号整数\n",arr,2) ;
else if(s==1)
fprintf(fpout,"%s\t\t%d\t\t错误\n",arr,3) ;
}else switch(ch){
case'+' :
ch=fgetc(fpin);
if(ch=='+'){
fprintf(fpout,"%s\t\t%d\t\t自加运算符\n","++",41);
break;
}
else if(ch=='='){
fprintf(fpout,"%s\t\t%d\t\t运算符\n","+=",42);
break;
}
else
fseek(fpin,-1L,SEEK_CUR);
fprintf(fpout,"%s\t\t%d\t\t运算符\n","+",43);
break;
case'-' :
ch=fgetc(fpin);
if(ch=='-'){
fprintf(fpout,"%s\t\t%d\t\t自减运算符\n","--",44);
break;
}
else if(ch=='='){
fprintf(fpout,"%s\t\t%d\t\t运算符\n","-=",45);
break;
}
else
fseek(fpin,-1L,SEEK_CUR);
fprintf(fpout,"%s\t\t%d\t\t运算符\n","-",46);
break;
case'*' :fprintf(fpout,"%s\t\t%d\t\t运算符\n","*",47);break;
case'(' :fprintf(fpout,"%s\t\t%d\t\t分界符\n","(",25);break;
case')' :fprintf(fpout,"%s\t\t%d\t\t分界符\n",")",26);break;
case'[' :fprintf(fpout,"%s\t\t%d\t\t分界符\n","[",27);break;
case']' :fprintf(fpout,"%s\t\t%d\t\t分界符\n","]",28);break;
case';' :fprintf(fpout,"%s\t\t%d\t\t分界符\n",";",29);break;
case'=' :fprintf(fpout,"%s\t\t%d\t\t运算符\n","=",48);break;
case'.' :fprintf(fpout,"%s\t\t%d\t\t分界符\n",".",30);break;
case',' :fprintf(fpout,"%s\t\t%d\t\t分界符\n",",",31);break;
case':' :fprintf(fpout,"%s\t\t%d\t\t分界符\n",":",32);break;
case'{' :fprintf(fpout,"%s\t\t%d\t\t分界符\n","{",33);break;
case'}' :fprintf(fpout,"%s\t\t%d\t\t分界符\n","}",34);break;
case'%' :fprintf(fpout,"%s\t\t%d\t\t分界符\n","%",35);break;
case'\"' :fprintf(fpout,"%s\t\t%d\t\t分界符\n","\"",36);break;
case'\\' :fprintf(fpout,"%s\t\t%d\t\t分界符\n","\\",37);break;
case'#' :fprintf(fpout,"%s\t\t%d\t\t分界符\n","#",38);break;
case'>' :{
ch=fgetc(fpin);
if(ch=='=')
fprintf(fpout,"%s\t\t%d\t\t运算符\n",">=",49);
else {
fprintf(fpout,"%s\t\t%d\t\t运算符\n",">",50);
fseek(fpin,-1L,SEEK_CUR);
}
}break;
case'<' :{
ch=fgetc(fpin);
if(ch=='=')
fprintf(fpout,"%s\t\t%d\t\t运算符\n","<=",51);
else if(ch=='>')
fprintf(fpout,"%s\t\t%d\n","<>",52);
else{
fprintf(fpout,"%s\t\t%d\t\t运算符\n","<",53);
fseek(fpin,-1L,SEEK_CUR);}
}break;
/***************出现在/ /之间的全部作为注释部分处理*******************/
case'/' :{
ch=fgetc(fpin);
if(ch=='/'){
while(ch!='\n'){
ch=fgetc(fpin);
}
}
else if(ch=='*'){
while(ch!='/'&&ch!=EOF){
ch=fgetc(fpin);
}
if(ch==EOF)
fprintf(fpout,"缺少一个'/'");}
else {
fprintf(fpout,"%s\t\t%d\t\t运算符\n","/",39);
fseek(fpin,-1L,SEEK_CUR);
}
break;
}
/***************非法字符*******************/
default :fprintf(fpout,"在第%d行无法识别的字符\t%c\n",Line_NO,ch);
}
}
}
/**********主程序中完成对输入输出文件的读写***********/
int main(){
char in_fn[25],out_fn[25];
FILE * fpin,* fpout; printf("<<<<<<<<<<<<<<<<<<WELCOME>>>>>>>>>>>>>>>>>>>>>>>>>>>\n");
printf("..............词法分析程序实验......................\n");
printf("\n");
printf(".....目前共有词法程序范例: 1个 \n");
printf(".....程序范例1:data.txt \n");
printf(".....输入一个已有的程序:\n");
scanf("%s",in_fn);
printf(".....输入你想要保存分析的目标文件名:\n");
scanf("%s",out_fn);
fpin=fopen(in_fn,"r");
fpout=fopen(out_fn,"w");
fprintf(fpout,"单词符\t\t种类编码\t\t种类\n");
init();
analyse(fpin,fpout);
fclose(fpin);
fclose(fpout);
printf(".....程序已分析完成分析并保存至目标文件\n");
printf("........<谢谢使用>......\n");
return 0;
}
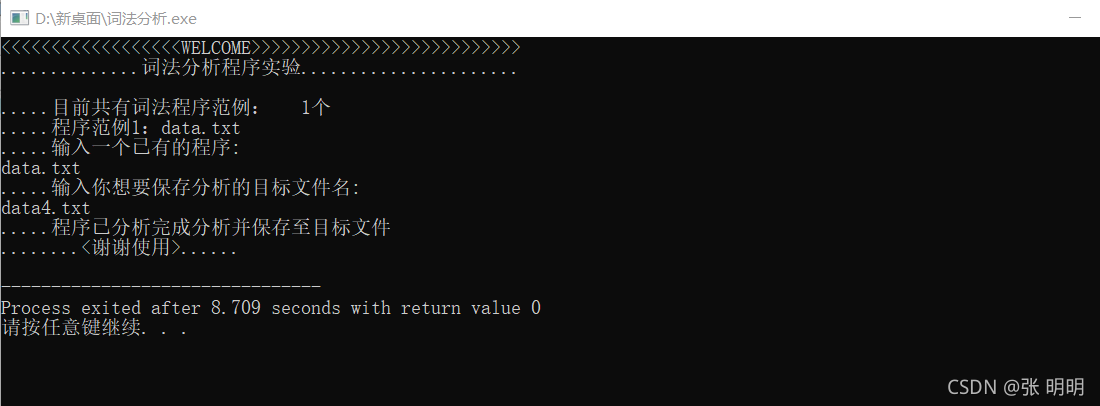

我用这个代码本身做的测试!汉字不能够分析,还有一些字符也没有加进去
如&,|。等有兴趣的小伙伴可以试试!
给大家看看结果!!!

因为加种类编码,所以可能有些混乱!看懂原理就行了!结构不是很复杂,希望对大家有所帮助。
我正在寻找执行以下操作的正确语法(在Perl、Shell或Ruby中):#variabletoaccessthedatalinesappendedasafileEND_OF_SCRIPT_MARKERrawdatastartshereanditcontinues. 最佳答案 Perl用__DATA__做这个:#!/usr/bin/perlusestrict;usewarnings;while(){print;}__DATA__Texttoprintgoeshere 关于ruby-如何将脚
我有一个用户工厂。我希望默认情况下确认用户。但是鉴于unconfirmed特征,我不希望它们被确认。虽然我有一个基于实现细节而不是抽象的工作实现,但我想知道如何正确地做到这一点。factory:userdoafter(:create)do|user,evaluator|#unwantedimplementationdetailshereunlessFactoryGirl.factories[:user].defined_traits.map(&:name).include?(:unconfirmed)user.confirm!endendtrait:unconfirmeddoenden
几个月前,我读了一篇关于rubygem的博客文章,它可以通过阅读代码本身来确定编程语言。对于我的生活,我不记得博客或gem的名称。谷歌搜索“ruby编程语言猜测”及其变体也无济于事。有人碰巧知道相关gem的名称吗? 最佳答案 是这个吗:http://github.com/chrislo/sourceclassifier/tree/master 关于ruby-寻找通过阅读代码确定编程语言的rubygem?,我们在StackOverflow上找到一个类似的问题:
华为OD机试题本篇题目:明明的随机数题目输入描述输出描述:示例1输入输出说明代码编写思路最近更新的博客华为od2023|什么是华为od,od薪资待遇,od机试题清单华为OD机试真题大全,用Python解华为机试题|机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南华为o
?博客主页:https://xiaoy.blog.csdn.net?本文由呆呆敲代码的小Y原创,首发于CSDN??学习专栏推荐:Unity系统学习专栏?游戏制作专栏推荐:游戏制作?Unity实战100例专栏推荐:Unity实战100例教程?欢迎点赞?收藏⭐留言?如有错误敬请指正!?未来很长,值得我们全力奔赴更美好的生活✨------------------❤️分割线❤️-------------------------
嗨~大家好,这里是可莉!今天给大家带来的是7个C语言的经典基础代码~那一起往下看下去把【程序一】打印100到200之间的素数#includeintmain(){ inti; for(i=100;i 【程序二】输出乘法口诀表#includeintmain(){inti;for(i=1;i 【程序三】判断1000年---2000年之间的闰年#includeintmain(){intyear;for(year=1000;year 【程序四】给定两个整形变量的值,将两个值的内容进行交换。这里提供两种方法来进行交换,第一种为创建临时变量来进行交换,第二种是不创建临时变量而直接进行交换。1.创建临时变量来
C#实现简易绘图工具一.引言实验目的:通过制作窗体应用程序(C#画图软件),熟悉基本的窗体设计过程以及控件设计,事件处理等,熟悉使用C#的winform窗体进行绘图的基本步骤,对于面向对象编程有更加深刻的体会.Tutorial任务设计一个具有基本功能的画图软件**·包括简单的新建文件,保存,重新绘图等功能**·实现一些基本图形的绘制,包括铅笔和基本形状等,学习橡皮工具的创建**·设计一个合理舒适的UI界面**注明:你可能需要先了解一些关于winform窗体应用程序绘图的基本知识,以及关于GDI+类和结构的知识二.实验环境Windows系统下的visualstudio2017C#窗体应用程序三.
MIMO技术的优缺点优点通过下面三个增益来总体概括:阵列增益。阵列增益是指由于接收机通过对接收信号的相干合并而活得的平均SNR的提高。在发射机不知道信道信息的情况下,MIMO系统可以获得的阵列增益与接收天线数成正比复用增益。在采用空间复用方案的MIMO系统中,可以获得复用增益,即信道容量成倍增加。信道容量的增加与min(Nt,Nr)成正比分集增益。在采用空间分集方案的MIMO系统中,可以获得分集增益,即可靠性性能的改善。分集增益用独立衰落支路数来描述,即分集指数。在使用了空时编码的MIMO系统中,由于接收天线或发射天线之间的间距较远,可认为它们各自的大尺度衰落是相互独立的,因此分布式MIMO
遍历文件夹我们通常是使用递归进行操作,这种方式比较简单,也比较容易理解。本文为大家介绍另一种不使用递归的方式,由于没有使用递归,只用到了循环和集合,所以效率更高一些!一、使用递归遍历文件夹整体思路1、使用File封装初始目录,2、打印这个目录3、获取这个目录下所有的子文件和子目录的数组。4、遍历这个数组,取出每个File对象4-1、如果File是否是一个文件,打印4-2、否则就是一个目录,递归调用代码实现publicclassSearchFile{publicstaticvoidmain(String[]args){//初始目录Filedir=newFile("d:/Dev");Datebeg
通常,数组被实现为内存块,集合被实现为HashMap,有序集合被实现为跳跃列表。在Ruby中也是如此吗?我正在尝试从性能和内存占用方面评估Ruby中不同容器的使用情况 最佳答案 数组是Ruby核心库的一部分。每个Ruby实现都有自己的数组实现。Ruby语言规范只规定了Ruby数组的行为,并没有规定任何特定的实现策略。它甚至没有指定任何会强制或至少建议特定实现策略的性能约束。然而,大多数Rubyist对数组的性能特征有一些期望,这会迫使不符合它们的实现变得默默无闻,因为实际上没有人会使用它:插入、前置或追加以及删除元素的最坏情况步骤复