当应用程序读写了这块虚拟内存,CPU就会去访问这个虚拟内存,这时会发现虚拟内存没有映射到物理内存,CPU就会产生缺页中断,进程会从用户态切换到内存态,并将缺页中断交给内核的page Fault handler(缺页中断函数)处理。
缺页中断处理函数会看是否有空闲的物理内存
32位操作系统和64位操作系统的虚拟地址空间大小是不同的,在Linux操作系统中,虚拟地址空间的内部又被分为内核空间和用户空间两部分:
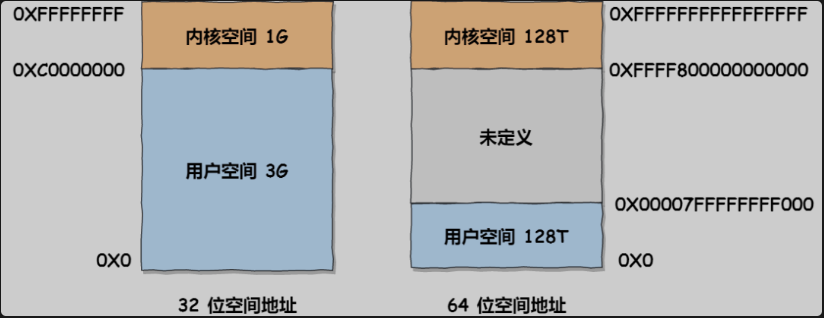
在32位操作系统上,进程最多申请3GB大小的虚拟内存空间,所以进程申请8GB内存的话,在申请虚拟内存阶段就会失败(可能错误原因是OOM)
在64位操作系统,进程可以使用128T大小的虚拟内存空间,所以进程申请8GB内存是没问题的,因为进程申请内存是申请虚拟内存,只要不读写这个虚拟内存,操作系统就不会分配物理内存。
测试方案:
先查寻当前设备物理内存
free -m
在机器上连续申请4次1GB内存,只单纯分配了虚拟内存,并没有使用此虚拟内存
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <errno.h>
#define MEM_SIZE 1024 * 1024 * 1024
int main() {
char* addr[4];
int i = 0;
for(i = 0; i < 4; ++i) {
addr[i] = (char*) malloc(MEM_SIZE);
if(!addr[i]) {
printf("执行 malloc 失败, 错误:%s\n",strerror(errno));
return -1;
}
printf("主线程调用malloc后,申请1gb大小得内存,此内存起始地址:0X%x\n", addr[i]);
}
//输入任意字符后,才结束
getchar();
return 0;
}
虽然物理内存只有2GB,但是程序正常分配了4G大小的虚拟内存:

通过一下命令查看进程(test)的虚拟内存大小:
ps aux
其中,VSZ 就代表进程使用的虚拟内存大小,RSS 代表进程使用的物理内存大小。可以看到,VSZ 大小为 4198540,也就是 4GB 的虚拟内存。


如果申请物理内存大小超过了空闲物理内存的大小,就要看操作系统有没有开启Swap机制:
什么是Swap机制?
当系统的物理内存不够用的时候,就需要将物理内存中的一部分空间释放出来,以供当前运行程序使用。那些被释放的空间可能来自一些很长时间没有什么操作的程序,这些被释放的空间会被临时保存到磁盘,等到那些程序要运行时,再从磁盘中恢复数据到内存中。
当内存使用存在压力的时候,会开始触发内存回收行为,会把这些不常访问的内存先写到磁盘中,然后释放这些内存,给其他更需要的进程使用。再次访问这些内存时,重新从磁盘中读入内存就可以了。
这种,将内存数据换出磁盘,又将磁盘中恢复数据到内存的过程,就是Swap机制负责的。
Swap就是把一块磁盘空间或者本地文件,当成内存来使用,包含换出和换入两个过程:
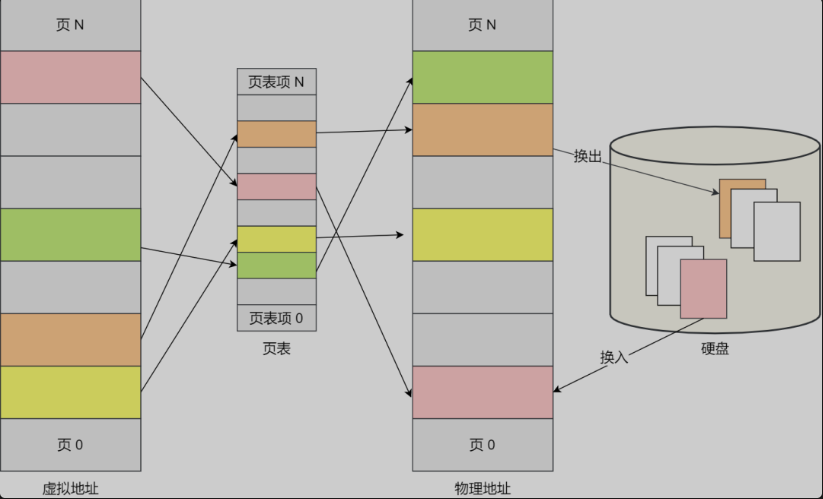
使用 Swap 机制优点是,应用程序实际可以使用的内存空间将远远超过系统的物理内存。由于硬盘空间的价格远比内存要低,因此这种方式无疑是经济实惠的。当然,频繁地读写硬盘,会显著降低操作系统的运行速率,这也是 Swap 的弊端。
Linux中的Swap机制会在内存不足和内存闲置的场景下触发:
Swap换入换出的是什么类型的内存?
内核缓存的文件数据,因为都有对应的磁盘文件,所以在回收文件数据的时候, 直接写回到对应的文件就可以了。
但是像进程的堆、栈数据等,它们是没有实际载体,这部分内存被称为匿名页。而且这部分内存很可能还要再次被访问,所以不能直接释放内存,于是就需要有一个能保存匿名页的磁盘载体,这个载体就是 Swap 分区。
匿名页回收的方式是通过 Linux 的 Swap 机制,Swap 会把不常访问的内存先写到磁盘中,然后释放这些内存,给其他更需要的进程使用。再次访问这些内存时,重新从磁盘读入内存就可以了。
实验测试:
我的Linux系统镜像是32位操作系统,物理内存设置2GB,带有Swap分区:

测试代码直接申请4GB虚拟内存后,通过memset函数访问
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <errno.h>
#define MEM_SIZE 1024 * 1024 * 1024
int main() {
char* addr[4];
int i = 0;
for(i = 0; i < 4; ++i) {
addr[i] = (char*) malloc(MEM_SIZE);
if(!addr[i]) {
printf("执行 malloc 失败, 错误:%s\n",strerror(errno));
return -1;
}
printf("主线程调用malloc后,申请1gb大小得内存,此内存起始地址:0X%x\n", addr[i]);
}
for(i = 0; i < 4; ++i) {
printf("开始访问第 %d 块虚拟内存(每一块虚拟内存为 1 GB)\n", i + 1);
memset(addr[i], 0, MEM_SIZE);
}
//输入任意字符后,才结束
getchar();
return 0;
}
运行结果:
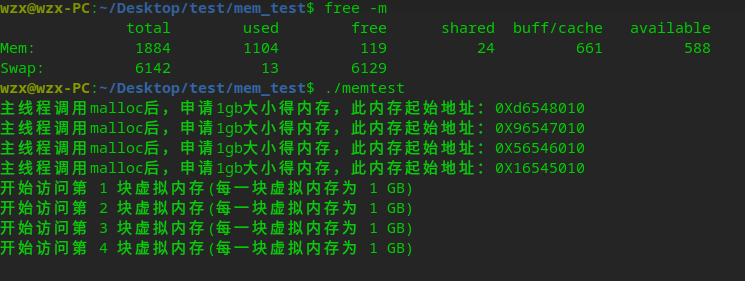
结论:
在有Swap机制的情况下,虽然物理内存只有2GB,也是可以申请4GB虚拟内存并使用的
修改测试代码:
申请8G内存(因为物理内存加Swap区接近8G),测试结果如下:
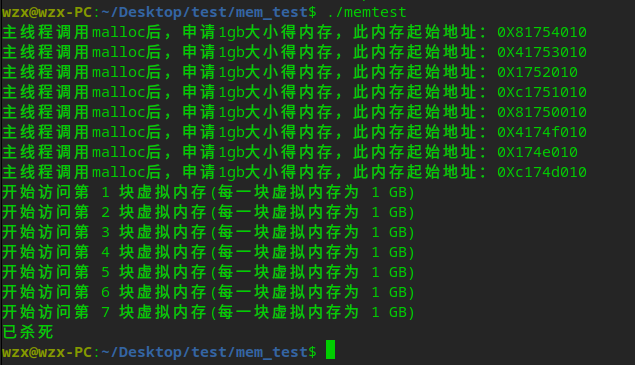

因为手头暂时没有现成的64位镜像,所64位结论采用参考文章的结论
在32位操作系统,因为进程最大只能申请3GB大小的虚拟内存,所以直接申请8G内存会申请失败
在64位操作系统,因为进程最大能申请128T大小的虚拟内存,即使物理内存只有4GB,申请8GB也是没有问题的,因为申请的内存是虚拟内存。如果这块虚拟内存被访问了,要看系统有没有Swap分区:
如果没有 Swap 分区,因为物理空间不够,进程会被操作系统杀掉,原因是 OOM(内存溢出);
如果有 Swap 分区,即使物理内存只有 2GB,程序也能正常使用 4GB 的内存(4G物理内存,申请8G内存同理),进程可以正常运行;
参考文章: https://mp.weixin.qq.com/s/QstLn7xmzS6TXb27_oLoSg
作为我的Rails应用程序的一部分,我编写了一个小导入程序,它从我们的LDAP系统中吸取数据并将其塞入一个用户表中。不幸的是,与LDAP相关的代码在遍历我们的32K用户时泄漏了大量内存,我一直无法弄清楚如何解决这个问题。这个问题似乎在某种程度上与LDAP库有关,因为当我删除对LDAP内容的调用时,内存使用情况会很好地稳定下来。此外,不断增加的对象是Net::BER::BerIdentifiedString和Net::BER::BerIdentifiedArray,它们都是LDAP库的一部分。当我运行导入时,内存使用量最终达到超过1GB的峰值。如果问题存在,我需要找到一些方法来更正我的代
我正在使用i18n从头开始构建一个多语言网络应用程序,虽然我自己可以处理一大堆yml文件,但我说的语言(非常)有限,最终我想寻求外部帮助帮助。我想知道这里是否有人在使用UI插件/gem(与django上的django-rosetta不同)来处理多个翻译器,其中一些翻译器不愿意或无法处理存储库中的100多个文件,处理语言数据。谢谢&问候,安德拉斯(如果您已经在rubyonrails-talk上遇到了这个问题,我们深表歉意) 最佳答案 有一个rails3branchofthetolkgem在github上。您可以通过在Gemfi
ruby如何管理内存。例如:如果我们在执行过程中采用C程序,则以下是内存模型。类似于这个ruby如何处理内存。C:__________________|||stack|||------------------||||------------------|||||Heap|||||__________________|||data|__________________|text|__________________Ruby:? 最佳答案 Ruby中没有“内存”这样的东西。Class#allocate分配一个对象并返回该对象。这就是程序
我安装了ruby版本管理器,并将RVM安装的ruby实现设置为默认值,这样'哪个ruby'显示'~/.rvm/ruby-1.8.6-p383/bin/ruby'但是当我在emacs中打开inf-ruby缓冲区时,它使用安装在/usr/bin中的ruby。有没有办法让emacs像shell一样尊重ruby的路径?谢谢! 最佳答案 我创建了一个emacs扩展来将rvm集成到emacs中。如果您有兴趣,可以在这里获取:http://github.com/senny/rvm.el
这似乎非常适得其反,因为太多的gem会在window上破裂。我一直在处理很多mysql和ruby-mysqlgem问题(gem本身发生段错误,一个名为UnixSocket的类显然在Windows机器上不能正常工作,等等)。我只是在浪费时间吗?我应该转向不同的脚本语言吗? 最佳答案 我在Windows上使用Ruby的经验很少,但是当我开始使用Ruby时,我是在Windows上,我的总体印象是它不是Windows原生系统。因此,在主要使用Windows多年之后,开始使用Ruby促使我切换回原来的系统Unix,这次是Linux。Rub
是否有简单的方法来更改默认ISO格式(yyyy-mm-dd)的ActiveAdmin日期过滤器显示格式? 最佳答案 您可以像这样为日期选择器提供额外的选项,而不是覆盖js:=f.input:my_date,as::datepicker,datepicker_options:{dateFormat:"mm/dd/yy"} 关于ruby-on-rails-事件管理员日期过滤器日期格式自定义,我们在StackOverflow上找到一个类似的问题: https://s
我想用这两种语言中的任何一种(最好是ruby)制作一个窗口管理器。老实说,除了我需要加载某种X模块外,我不知道从哪里开始。因此,如果有人有线索,如果您能指出正确的方向,那就太好了。谢谢 最佳答案 XCB,X的下一代API使用XML格式定义X协议(protocol),并使用脚本生成特定语言绑定(bind)。它在概念上与SWIG类似,只是它描述的不是CAPI,而是X协议(protocol)。目前,C和Python存在绑定(bind)。理论上,Ruby端口只是编写一个从XML协议(protocol)定义语言到Ruby的翻译器的问题。生
require"socket"server="irc.rizon.net"port="6667"nick="RubyIRCBot"channel="#0x40"s=TCPSocket.open(server,port)s.print("USERTesting",0)s.print("NICK#{nick}",0)s.print("JOIN#{channel}",0)这个IRC机器人没有连接到IRC服务器,我做错了什么? 最佳答案 失败并显示此消息::irc.shakeababy.net461*USER:Notenoughparame
你好,我无法成功如何在散列中删除key后释放内存。当我从哈希中删除键时,内存不会释放,也不会在手动调用GC.start后释放。当从Hash中删除键并且这些对象在某处泄漏时,这是预期的行为还是GC不释放内存?如何在Ruby中删除Hash中的键并在内存中取消分配它?例子:irb(main):001:0>`ps-orss=-p#{Process.pid}`.to_i=>4748irb(main):002:0>a={}=>{}irb(main):003:0>1000000.times{|i|a[i]="test#{i}"}=>1000000irb(main):004:0>`ps-orss=-p
这是我在ActiveAdmin中的自定义页面ActiveAdmin.register_page"Settings"doaction_itemdolink_to('Importprojects','settings/importprojects')endcontentdopara"Text"endcontrollerdodefimportprojectssystem"rakedataspider:import_projects_ninja"para"OK"endendend我想做的是,当我单击“导入项目”按钮时,我想在Controller中执行rake任务。但是我无法访问该方法。可能是什