从计算的角度, 算子以外的代码都是在 Driver 端执行, 算子里面的代码都是在 Executor 端执行。那么在 scala 的函数式编程中,就会导致算子内经常会用到算子外的数据,这样就 形成了闭包的效果,如果使用的算子外的数据无法序列化,就意味着无法传值给 Executor 端执行,就会发生错误,所以需要在执行任务计算前,检测闭包内的对象是否可以进行序列 化,这个操作我们称之为闭包检测。Scala2.12 版本后闭包编译方式发生了改变
从计算的角度, 算子以外的代码都是在 Driver 端执行, 算子里面的代码都是在 Executor 端执行。
object spark_02 {
def main(args: Array[String]): Unit = {
//准备环境
//"*"代表线程的核数 应用程序名称"RDD"
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD")
val sc = new SparkContext(sparkConf)
val rdd: RDD[String] = sc.makeRDD(Array("hello world", "hello spark", "hive", "atguigu"))
//创建查询对象
val search = new Search("h")
//函数传递,打印:ERROR Task not serializable
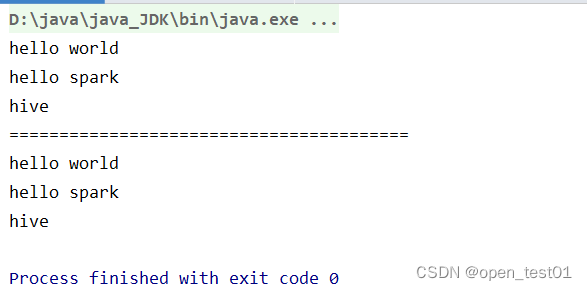
search.getMatch1(rdd).collect().foreach(println)
println("========================================")
//属性传递,打印:ERROR Task not serializable
search.getMatch2(rdd).collect().foreach(println)
//关闭环境
sc.stop()
}
}
//查询对象
//类的构造参数是类的属性,构造参数需要进行闭包检查(对类进行闭包检查)
class Search(query:String) extends Serializable {
def isMatch(s: String): Boolean = {
s.contains(query)
}
// 函数序列化案例
def getMatch1 (rdd: RDD[String]): RDD[String] = {
rdd.filter(isMatch)
}
// 属性序列化案例
def getMatch2(rdd: RDD[String]): RDD[String] = {
rdd.filter(x => x.contains(query))
}
}
相邻的两个RDD关系称之为依赖关系
多个连续的RDD的依赖关系称之为血缘关系
RDD 只支持粗粒度转换,即在大量记录上执行的单个操作。将创建 RDD 的一系列 Lineage (血统)记录下来,以便恢复丢失的分区。RDD 的 Lineage 会记录 RDD 的元数据信息和转 换行为,当该 RDD 的部分分区数据丢失时,它可以根据这些信息来重新运算和恢复丢失的 数据分区。
val fileRDD: RDD[String] = sc.textFile("input/1.txt")
println(fileRDD.toDebugString) //打印输出血缘关系
println("----------------------")
val wordRDD: RDD[String] = fileRDD.flatMap(_.split(" "))
println(wordRDD.toDebugString)
println("----------------------")
val mapRDD: RDD[(String, Int)] = wordRDD.map((_,1))
println(mapRDD.toDebugString)
println("----------------------")
val resultRDD: RDD[(String, Int)] = mapRDD.reduceByKey(_+_)
println(resultRDD.toDebugString)
resultRDD.collect()窄依赖表示每一个父(上游)RDD 的 Partition 最多被子(下游)RDD 的一个 Partition 使用, 窄依赖我们形象的比喻为独生子女。
宽依赖表示同一个父(上游)RDD 的 Partition 被多个子(下游)RDD 的 Partition 依赖,会 引起 Shuffle,总结:宽依赖我们形象的比喻为多生。
RDD 任务切分中间分为:Application、Job、Stage 和 Task:
注意:Application->Job->Stage->Task 每一层都是 1 对 n 的关系。
RDD 通过 Cache 或者 Persist 方法将前面的计算结果缓存,默认情况下会把数据以缓存 在 JVM 的堆内存中。但是并不是这两个方法被调用时立即缓存,而是触发后面的 action 算 子时,该 RDD 将会被缓存在计算节点的内存中,并供后面重用。
// cache 操作会增加血缘关系,不改变原有的血缘关系
println(wordToOneRdd.toDebugString)
// 数据缓存。
wordToOneRdd.cache()
// 可以更改存储级别
//mapRdd.persist(StorageLevel.MEMORY_AND_DISK_2)
缓存有可能丢失,或者存储于内存的数据由于内存不足而被删除,RDD 的缓存容错机 制保证了即使缓存丢失也能保证计算的正确执行。通过基于 RDD 的一系列转换,丢失的数 据会被重算,由于 RDD 的各个 Partition 是相对独立的,因此只需要计算丢失的部分即可, 并不需要重算全部 Partition。 Spark 会自动对一些 Shuffle 操作的中间数据做持久化操作(比如:reduceByKey)。这样 做的目的是为了当一个节点 Shuffle 失败了避免重新计算整个输入。但是,在实际使用的时 候,如果想重用数据,仍然建议调用 persist 或 cache。
所谓的检查点其实就是通过将 RDD 中间结果写入磁盘 由于血缘依赖过长会造成容错成本过高,这样就不如在中间阶段做检查点容错,如果检查点 之后有节点出现问题,可以从检查点开始重做血缘,减少了开销。 对 RDD 进行 checkpoint 操作并不会马上被执行,必须执行 Action 操作才能触发。
// 设置检查点路径
sc.setCheckpointDir("./checkpoint1")
// 创建一个 RDD,读取指定位置文件:hello atguigu atguigu
val lineRdd: RDD[String] = sc.textFile("input/1.txt")
// 业务逻辑
val wordRdd: RDD[String] = lineRdd.flatMap(line => line.split(" "))
val wordToOneRdd: RDD[(String, Long)] = wordRdd.map {
word => {
(word, System.currentTimeMillis())
}
}
// 增加缓存,避免再重新跑一个 job 做 checkpoint
wordToOneRdd.cache()
// 数据检查点:针对 wordToOneRdd 做检查点计算
wordToOneRdd.checkpoint()
// 触发执行逻辑
wordToOneRdd.collect().foreach(println)
我正在尝试修改当前依赖于定义为activeresource的gem:s.add_dependency"activeresource","~>3.0"为了让gem与Rails4一起工作,我需要扩展依赖关系以与activeresource的版本3或4一起工作。我不想简单地添加以下内容,因为它可能会在以后引起问题:s.add_dependency"activeresource",">=3.0"有没有办法指定可接受版本的列表?~>3.0还是~>4.0? 最佳答案 根据thedocumentation,如果你想要3到4之间的所有版本,你可以这
我收到这个错误:RuntimeError(自动加载常量Apps时检测到循环依赖当我使用多线程时。下面是我的代码。为什么会这样?我尝试多线程的原因是因为我正在编写一个HTML抓取应用程序。对Nokogiri::HTML(open())的调用是一个同步阻塞调用,需要1秒才能返回,我有100,000多个页面要访问,所以我试图运行多个线程来解决这个问题。有更好的方法吗?classToolsController0)app.website=array.join(',')putsapp.websiteelseapp.website="NONE"endapp.saveapps=Apps.order("
对于Rails模型,是否可以/建议让一个类的成员不持久保存到数据库中?我想将用户最后选择的类型存储在session变量中。由于我无法从我的模型中设置session变量,我想将值存储在一个“虚拟”类成员中,该成员只是将值传递回Controller。你能有这样的类(class)成员吗? 最佳答案 将非持久属性添加到Rails模型就像任何其他Ruby类一样:classUser扩展解释:在Ruby中,所有实例变量都是私有(private)的,不需要在赋值前定义。attr_accessor创建一个setter和getter方法:classUs
给定一个复杂的对象层次结构,幸运的是它不包含循环引用,我如何实现支持各种格式的序列化?我不是来讨论实际实现的。相反,我正在寻找可能会派上用场的设计模式提示。更准确地说:我正在使用Ruby,我想解析XML和JSON数据以构建复杂的对象层次结构。此外,应该可以将该层次结构序列化为JSON、XML和可能的HTML。我可以为此使用Builder模式吗?在任何提到的情况下,我都有某种结构化数据-无论是在内存中还是文本中-我想用它来构建其他东西。我认为将序列化逻辑与实际业务逻辑分开会很好,这样我以后就可以轻松支持多种XML格式。 最佳答案 我最
我的问题的一个例子是体育游戏。一场体育比赛有两支球队,一支主队和一支客队。我的事件记录模型如下:classTeam"Team"has_one:away_team,:class_name=>"Team"end我希望能够通过游戏访问一个团队,例如:Game.find(1).home_team但我收到一个单元化常量错误:Game::team。谁能告诉我我做错了什么?谢谢, 最佳答案 如果Gamehas_one:team那么Rails假设您的teams表有一个game_id列。不过,您想要的是games表有一个team_id列,在这种情况下
📢博客主页:https://blog.csdn.net/weixin_43197380📢欢迎点赞👍收藏⭐留言📝如有错误敬请指正!📢本文由Loewen丶原创,首发于CSDN,转载注明出处🙉📢现在的付出,都会是一种沉淀,只为让你成为更好的人✨文章预览:一.分辨率(Resolution)1、工业相机的分辨率是如何定义的?2、工业相机的分辨率是如何选择的?二.精度(Accuracy)1、像素精度(PixelAccuracy)2、定位精度和重复定位精度(RepeatPrecision)三.公差(Tolerance)四.课后作业(Post-ClassExercises)视觉行业的初学者,甚至是做了1~2年
假设我必须(小型到中型)阵列:tokens=["aaa","ccc","xxx","bbb","ccc","yyy","zzz"]template=["aaa","bbb","ccc"]如何确定tokens是否以相同的顺序包含template的所有条目?(请注意,在上面的示例中,应忽略第一个“ccc”,从而由于最后一个“ccc”而导致匹配。) 最佳答案 这适用于您的示例数据。tokens=["aaa","ccc","xxx","bbb","ccc","yyy","zzz"]template=["aaa","bbb","ccc"]po
有什么方法可以告诉sidekiq一项工作依赖于另一项工作,并且在后者完成之前无法开始? 最佳答案 仅使用Sidekiq;答案是否定的。正如DickieBoy所建议的那样,您应该能够在依赖作业完成时将其启动。像这样。#app/workers/hard_worker.rbclassHardWorkerincludeSidekiq::Workerdefperform()puts'Doinghardwork'LazyWorker.perform_async()endend#app/workers/lazy_worker.rbclassLaz
首先,我使用的是rails3.1.3和来自master的carrierwavegithub仓库的分支。我使用after_init钩子(Hook)来确定基于属性的字段页面模型实例并为这些字段定义属性访问器将值存储在序列化哈希中(希望它清楚我是什么谈论)。这是我正在做的事情的精简版:classPage省略mount_uploader命令让我可以访问我想要的属性。但是当我安装uploader时出现错误消息说“nil类的未定义新方法”我在源代码中读到有方法read_uploader和扩展模块中的write_uploader。我如何必须覆盖这些来制作mount_uploader命令使用我的“虚拟
我想合并多个事件记录关系例如,apple_companies=Company.where("namelike?","%apple%")banana_companies=Company.where("namelike?","%banana%")我想结合这两个关系。不是合并,合并是apple_companies.merge(banana_companies)=>Company.where("namelike?andnamelike?","%apple%","%banana%")我要Company.where("名字像?还是名字像?","%apple%","%banana%")之后,我会写代