1.先判断当前节点的no是否等于要查找的
2.如果是相等,则返回当前节点
3.如果不等,则判断当前节点的左子节点是否为空,如果不为空,则递归前序查找
4.如果左递归前序查找,找到节点,则返回,否继续判断,当前的节点的右子节点是否为空,如果不为空,则继续向右递归前序查找。
1.判断当前节点的左子节点是否为空,如果不为空,则递归中序查找
2.如果找到,则返回,如果没有找到,就和当前节点比较,如果是则返回当前节点,否则继续进行右递归的中序查找
3.如果右递归中序查找,找到就返回,否则返回null
1.判断当前节点的左子节点是否为空,如果不为空,则递归后序查找
2.如果找到,就返回,如果没有找到,就判断当前节点的右子节点是否为空,如果不为空,则右递归进行后序查找,如果找到,就返回
3.就和当前节点进行比较,如果是则返回,否则返回null
要求
1.请编写前序查找,中序查找和后序查找的方法。
2.并分别使用三种查找方式,查找 heroNO = 5 的节点
3.并分析各种查找方式,分别比较了多少次
代码实现:
先创建HeroNode 结点
class HeroNode {
private int no;
private String name;
private HeroNode left; //默认null
private HeroNode right; //默认null
public HeroNode(int no, String name) {
this.no = no;
this.name = name;
}
public int getNo() {
return no;
}
public void setNo(int no) {
this.no = no;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public HeroNode getLeft() {
return left;
}
public void setLeft(HeroNode left) {
this.left = left;
}
public HeroNode getRight() {
return right;
}
public void setRight(HeroNode right) {
this.right = right;
}
@Override
public String toString() {
return "HeroNode [no=" + no + ", name=" + name + "]";
}
//前序遍历
public void preOrder() {
System.out.println(this); //先输出父结点
//递归向左子树前序遍历
if(this.left != null) {
this.left.preOrder();
}
//递归向右子树前序遍历
if(this.right != null) {
this.right.preOrder();
}
}
//前序遍历查找
/**
*
* @param no 查找no
* @return 如果找到就返回该Node ,如果没有找到返回 null
*/
public HeroNode preOrderSearch(int no) {
System.out.println("进入前序遍历");
//比较当前结点是不是
if(this.no == no) {
return this;
}
//1.则判断当前结点的左子节点是否为空,如果不为空,则递归前序查找
//2.如果左递归前序查找,找到结点,则返回
HeroNode resNode = null;
if(this.left != null) {
resNode = this.left.preOrderSearch(no);
}
if(resNode != null) {//说明我们左子树找到
return resNode;
}
//1.左递归前序查找,找到结点,则返回,否继续判断,
//2.当前的结点的右子节点是否为空,如果不空,则继续向右递归前序查找
if(this.right != null) {
resNode = this.right.preOrderSearch(no);
}
return resNode;
}
//中序遍历查找
public HeroNode infixOrderSearch(int no) {
//判断当前结点的左子节点是否为空,如果不为空,则递归中序查找
HeroNode resNode = null;
if(this.left != null) {
resNode = this.left.infixOrderSearch(no);
}
if(resNode != null) {
return resNode;
}
System.out.println("进入中序查找");
//如果找到,则返回,如果没有找到,就和当前结点比较,如果是则返回当前结点
if(this.no == no) {
return this;
}
//否则继续进行右递归的中序查找
if(this.right != null) {
resNode = this.right.infixOrderSearch(no);
}
return resNode;
}
//后序遍历查找
public HeroNode postOrderSearch(int no) {
//判断当前结点的左子节点是否为空,如果不为空,则递归后序查找
HeroNode resNode = null;
if(this.left != null) {
resNode = this.left.postOrderSearch(no);
}
if(resNode != null) {//说明在左子树找到
return resNode;
}
//如果左子树没有找到,则向右子树递归进行后序遍历查找
if(this.right != null) {
resNode = this.right.postOrderSearch(no);
}
if(resNode != null) {
return resNode;
}
System.out.println("进入后序查找");
//如果左右子树都没有找到,就比较当前结点是不是
if(this.no == no) {
return this;
}
return resNode;
}
}
定义BinaryTree 二叉树
class BinaryTree {
private HeroNode root;
public void setRoot(HeroNode root) {
this.root = root;
}
//前序遍历查找
public HeroNode preOrderSearch(int no) {
if(root != null) {
return root.preOrderSearch(no);
} else {
return null;
}
}
//中序遍历查找
public HeroNode infixOrderSearch(int no) {
if(root != null) {
return root.infixOrderSearch(no);
}else {
return null;
}
}
//后序遍历查找
public HeroNode postOrderSearch(int no) {
if(root != null) {
return this.root.postOrderSearch(no);
}else {
return null;
}
}
}
测试:
public class BinaryTreeDemo {
public static void main(String[] args) {
//先需要创建一颗二叉树
BinaryTree binaryTree = new BinaryTree();
//创建需要的结点
HeroNode root = new HeroNode(1, "宋江");
HeroNode node2 = new HeroNode(2, "吴用");
HeroNode node3 = new HeroNode(3, "卢俊义");
HeroNode node4 = new HeroNode(4, "林冲");
HeroNode node5 = new HeroNode(5, "关胜");
//说明,我们先手动创建该二叉树,后面我们学习递归的方式创建二叉树
root.setLeft(node2);
root.setRight(node3);
node3.setRight(node4);
node3.setLeft(node5);
binaryTree.setRoot(root);
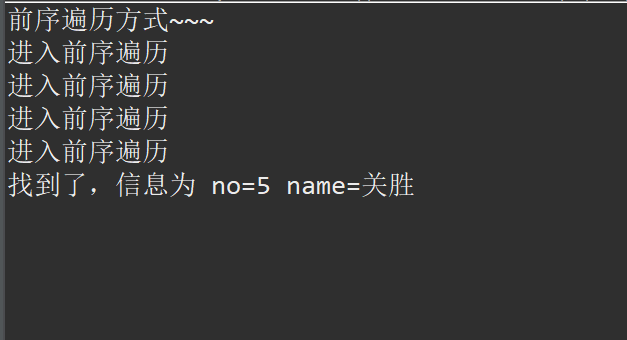
// 前序遍历
// 前序遍历的次数 :4
System.out.println("前序遍历方式~~~");
HeroNode resNode = binaryTree.preOrderSearch(5);
if (resNode != null) {
System.out.printf("找到了,信息为 no=%d name=%s", resNode.getNo(), resNode.getName());
} else {
System.out.printf("没有找到 no = %d 的英雄", 5);
}
/**
// 中序遍历查找
// 中序遍历3次
System.out.println("中序遍历方式~~~");
HeroNode resNode = binaryTree.infixOrderSearch(5);
if (resNode != null) {
System.out.printf("找到了,信息为 no=%d name=%s", resNode.getNo(), resNode.getName());
} else {
System.out.printf("没有找到 no = %d 的英雄", 5);
}
*/
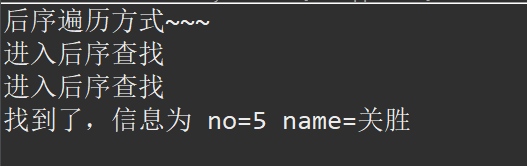
/**
// 后序遍历查找
// 后序遍历查找的次数 2次
System.out.println("后序遍历方式~~~");
HeroNode resNode = binaryTree.postOrderSearch(5);
if (resNode != null) {
System.out.printf("找到了,信息为 no=%d name=%s", resNode.getNo(), resNode.getName());
} else {
System.out.printf("没有找到 no = %d 的英雄", 5);
}
*/
}
}
运行结果如图:
前序遍历:
中序遍历:

后序遍历:
要求
1.如果删除的节点是叶子节点,则删除该节点
2.如果删除的节点是非叶子节点,则删除该子树.
3.测试,删除掉 5 号叶子节点
思路:
1.考虑如果树是空树root,如果只有一个root节点,则等价将二叉树置空
2.因为我们的二叉树是单向的,所以我们是判断当前节点的子节点是否是需要删除节点,而不能去判断当前这个节点是不是需要删除节点。
3.如果当前节点的左子节点不为空,并且左子节点就是要删除节点,就将this.left=null;
并且就返回(结束递归删除)
4.如果当前节点的右子节点不为空,并且右子节点就是要删除节点,就将this.right=null;
并且就返回(结束递归删除)
5.如果3,4步没有删除节点,那么我们就需要向左子树进行递归删除
6.如果第5步也没有删除节点,则应当向右子树进行递归删除。
代码实现:
//HeroNode 类增加方法
//递归删除结点
//1.如果删除的节点是叶子节点,则删除该节点
//2.如果删除的节点是非叶子节点,则删除该子树
public void delNode(int no) {
//思路
/*
* 1. 因为我们的二叉树是单向的,所以我们是判断当前结点的子结点是否需要删除结点,而不能去判断当前这个结点是不是需要删除结点.
2. 如果当前结点的左子结点不为空,并且左子结点 就是要删除结点,就将this.left = null; 并且就返回(结束递归删除)
3. 如果当前结点的右子结点不为空,并且右子结点 就是要删除结点,就将this.right= null ;并且就返回(结束递归删除)
4. 如果第2和第3步没有删除结点,那么我们就需要向左子树进行递归删除
5. 如果第4步也没有删除结点,则应当向右子树进行递归删除.
*/
//2. 如果当前结点的左子结点不为空,并且左子结点 就是要删除结点,就将this.left = null; 并且就返回(结束递归删除)
if(this.left != null && this.left.no == no) {
this.left = null;
return;
}
//3.如果当前结点的右子结点不为空,并且右子结点 就是要删除结点,就将this.right= null ;并且就返回(结束递归删除)
if(this.right != null && this.right.no == no) {
this.right = null;
return;
}
//4.我们就需要向左子树进行递归删除
if(this.left != null) {
this.left.delNode(no);
}
//5.则应当向右子树进行递归删除
if(this.right != null) {
this.right.delNode(no);
}
}
//在 BinaryTree 类增加方法
//删除结点
public void delNode(int no) {
if(root != null) {
//如果只有一个root结点, 这里立即判断root是不是就是要删除结点
if(root.getNo() == no) {
root = null;
} else {
//递归删除
root.delNode(no);
}
}else{
System.out.println("空树,不能删除~");
}
}
//在 BinaryTreeDemo 类增加测试代码:
//测试一把删除结点
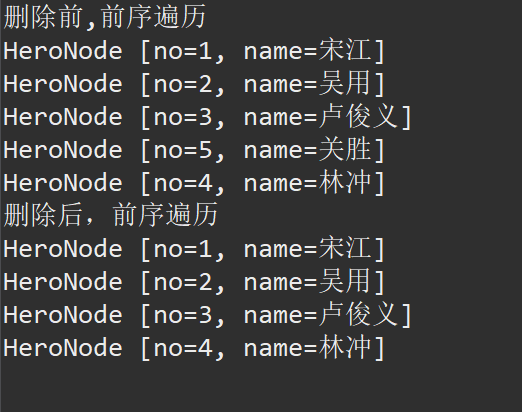
System.out.println("删除前,前序遍历");
binaryTree.preOrder(); // 1,2,3,5,4
binaryTree.delNode(5);
//binaryTree.delNode(3);
System.out.println("删除后,前序遍历");
binaryTree.preOrder(); // 1,2,3,4
代码运行如图:
这篇博客是我在B站看韩顺平老师数据结构和算法的课时的笔记,记录一下,防止忘记,也希望能帮助各位朋友。
Rackup通过Rack的默认处理程序成功运行任何Rack应用程序。例如:classRackAppdefcall(environment)['200',{'Content-Type'=>'text/html'},["Helloworld"]]endendrunRackApp.new但是当最后一行更改为使用Rack的内置CGI处理程序时,rackup给出“NoMethodErrorat/undefinedmethod`call'fornil:NilClass”:Rack::Handler::CGI.runRackApp.newRack的其他内置处理程序也提出了同样的反对意见。例如Rack
我有一个对象has_many应呈现为xml的子对象。这不是问题。我的问题是我创建了一个Hash包含此数据,就像解析器需要它一样。但是rails自动将整个文件包含在.........我需要摆脱type="array"和我该如何处理?我没有在文档中找到任何内容。 最佳答案 我遇到了同样的问题;这是我的XML:我在用这个:entries.to_xml将散列数据转换为XML,但这会将条目的数据包装到中所以我修改了:entries.to_xml(root:"Contacts")但这仍然将转换后的XML包装在“联系人”中,将我的XML代码修改为
查看Ruby的CSV库的文档,我非常确定这是可能且简单的。我只需要使用Ruby删除CSV文件的前三列,但我没有成功运行它。 最佳答案 csv_table=CSV.read(file_path_in,:headers=>true)csv_table.delete("header_name")csv_table.to_csv#=>ThenewCSVinstringformat检查CSV::Table文档:http://ruby-doc.org/stdlib-1.9.2/libdoc/csv/rdoc/CSV/Table.html
我发现ActiveRecord::Base.transaction在复杂方法中非常有效。我想知道是否可以在如下事务中从AWSS3上传/删除文件:S3Object.transactiondo#writeintofiles#raiseanexceptionend引发异常后,每个操作都应在S3上回滚。S3Object这可能吗?? 最佳答案 虽然S3API具有批量删除功能,但它不支持事务,因为每个删除操作都可以独立于其他操作成功/失败。该API不提供任何批量上传功能(通过PUT或POST),因此每个上传操作都是通过一个独立的API调用完成的
我正在尝试修改当前依赖于定义为activeresource的gem:s.add_dependency"activeresource","~>3.0"为了让gem与Rails4一起工作,我需要扩展依赖关系以与activeresource的版本3或4一起工作。我不想简单地添加以下内容,因为它可能会在以后引起问题:s.add_dependency"activeresource",">=3.0"有没有办法指定可接受版本的列表?~>3.0还是~>4.0? 最佳答案 根据thedocumentation,如果你想要3到4之间的所有版本,你可以这
我有一个这样的哈希数组:[{:foo=>2,:date=>Sat,01Sep2014},{:foo2=>2,:date=>Sat,02Sep2014},{:foo3=>3,:date=>Sat,01Sep2014},{:foo4=>4,:date=>Sat,03Sep2014},{:foo5=>5,:date=>Sat,02Sep2014}]如果:date相同,我想合并哈希值。我对上面数组的期望是:[{:foo=>2,:foo3=>3,:date=>Sat,01Sep2014},{:foo2=>2,:foo5=>5:date=>Sat,02Sep2014},{:foo4=>4,:dat
我刚刚被困在这个问题上一段时间了。以这个基地为例:moduleTopclassTestendmoduleFooendend稍后,我可以通过这样做在Foo中定义扩展Test的类:moduleTopmoduleFooclassSomeTest但是,如果我尝试通过使用::指定模块来最小化缩进:moduleTop::FooclassFailure这失败了:NameError:uninitializedconstantTop::Foo::Test这是一个错误,还是仅仅是Ruby解析变量名的方式的逻辑结果? 最佳答案 Isthisabug,or
我正在尝试解析一个CSV文件并使用SQL命令自动为其创建一个表。CSV中的第一行给出了列标题。但我需要推断每个列的类型。Ruby中是否有任何函数可以找到每个字段中内容的类型。例如,CSV行:"12012","Test","1233.22","12:21:22","10/10/2009"应该产生像这样的类型['integer','string','float','time','date']谢谢! 最佳答案 require'time'defto_something(str)if(num=Integer(str)rescueFloat(s
在Ruby中是否有Gem或安全删除文件的方法?我想避免系统上可能不存在的外部程序。“安全删除”指的是覆盖文件内容。 最佳答案 如果您使用的是*nix,一个很好的方法是使用exec/open3/open4调用shred:`shred-fxuz#{filename}`http://www.gnu.org/s/coreutils/manual/html_node/shred-invocation.html检查这个类似的帖子:Writingafileshredderinpythonorruby?
我正在尝试找到一种方法来规范化字符串以将其作为文件名传递。到目前为止我有这个:my_string.mb_chars.normalize(:kd).gsub(/[^\x00-\x7F]/n,'').downcase.gsub(/[^a-z]/,'_')但第一个问题:-字符。我猜这个方法还有更多问题。我不控制名称,名称字符串可以有重音符、空格和特殊字符。我想删除所有这些,用相应的字母('é'=>'e')替换重音符号,并将其余的替换为'_'字符。名字是这样的:“Prélèvements-常规”“健康证”...我希望它们像一个没有空格/特殊字符的文件名:“prelevements_routin