作者:vivo 互联网服务器团队- Zhi Guangquan
HttpClient作为Java程序员最常用的Http工具,其对Http连接的管理能简化开发,并且提升连接重用效率;在正常情况下,HttpClient能帮助我们高效管理连接,但在一些并发高,报文体较大的情况下,如果再遇到网络波动,如何保证连接被高效利用,有哪些优化空间。
北京时间X月X日,浏览器信息流服务监控出现异常,主要表现在以下三个方面:
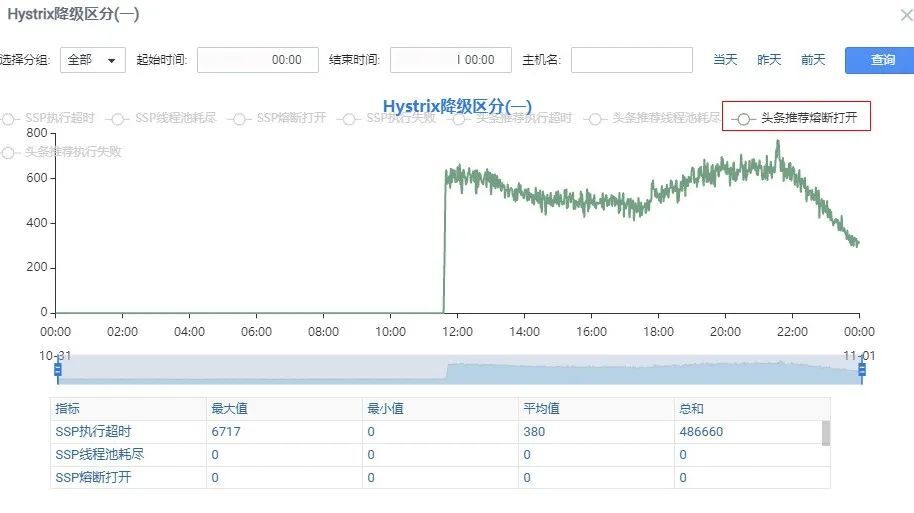
2. 从PAAS平台Hystrix熔断管理界面中可以进一步确认问题机器的所有Http接口调用均出现了熔断:
3. 日志中心有大量从Http连接池获取连接的异常:org.apache.http.impl.execchain.RequestAbortedException: Request aborted。
综合以上三个现象,大概可以推测出问题机器的TCP连接管理出了问题,可能是虚拟机问题,也可能是物理机问题;与运维与系统侧沟通后,发现虚拟机与物理机均无明显异常,第一时间联系运维重启了问题机器,线上问题得到解决。
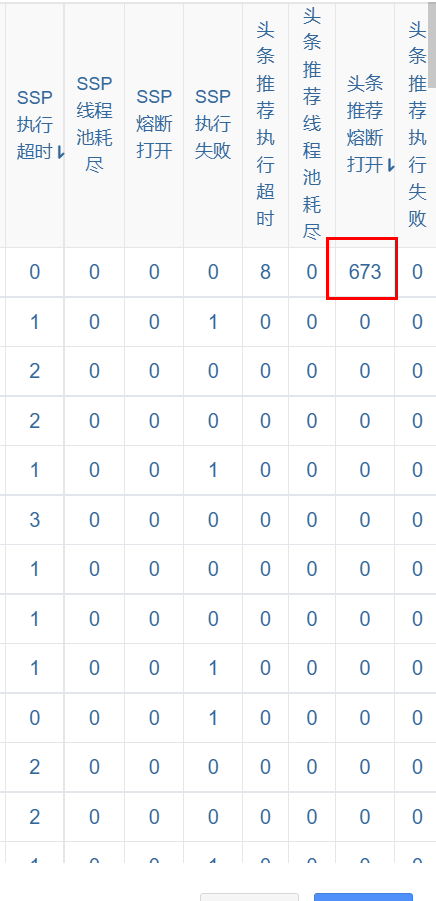
几天以后,线上部分其他机器也陆续出现了上述现象,此时基本可以确认是服务本身有问题;既然问题与TCP连接相关,于是联系运维在问题机器上建立了一个作业查看TCP连接的状态分布:
netstat -ant|awk '/^tcp/ {++S[$NF]} END {for(a in S) print (a,S[a])}'
结果如下:
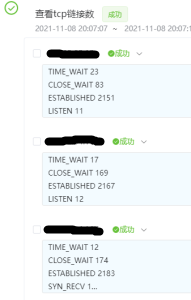
如上图,问题机器的CLOSE_WAIT状态的连接数已经接近200左右(该服务Http连接池最大连接数设置的250),那问题直接原因基本可以确认是CLOSE_WAIT状态的连接过多导致的;本着第一时间先解决线上问题的原则,先把连接池调整到500,然后让运维重启了机器,线上问题暂时得到解决。
调整连接池大小只是暂时解决了线上问题,但是具体原因还不确定,按照以往经验,出现连接无法正常释放基本都是开发者使用不当,在使用完成后没有及时关闭连接;但很快这个想法就被否定了,原因显而易见:当前的服务已经在线上运行了一周左右,中间没有经历过发版,以浏览器的业务量,如果是连接使用完没有及时关。
闭,250的连接数连一分钟都撑不到就会被打爆。那么问题就只能是一些异常场景导致的连接没有释放;于是,重点排查了下近期上线的业务接口,尤其是那种数据包体较大,响应时间较长的接口,最终把目标锁定在了某个详情页优化接口上;先查看处于CLOSE_WAIT状态的IP与端口连接对,确认对方服务器IP地址。
netstat-tulnap|grep CLOSE_WAIT
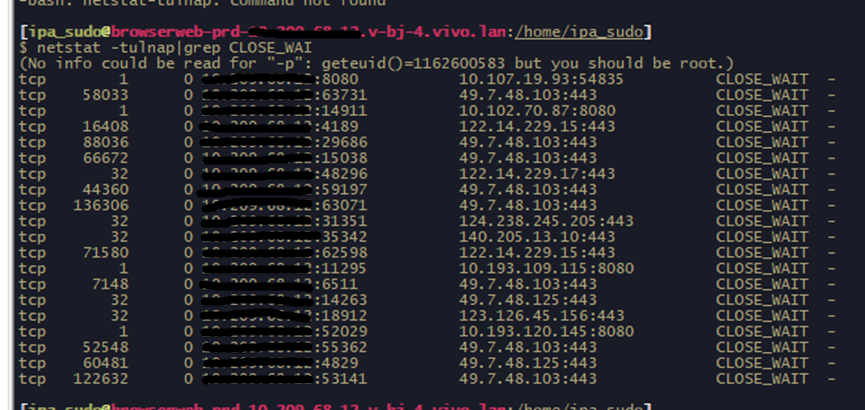
经过与合作方确认,目标IP均来自该合作方,与我们的推测是相符的。
在定位问题的同时,也让运维同事帮忙抓取了TCP的数据包,结果表明确实是客户端(浏览器服务端)没返回ACK结束握手,导致挥手失败,客户端处于了CLOSE_WAIT状态,数据包的大小也与怀疑的问题接口相符。
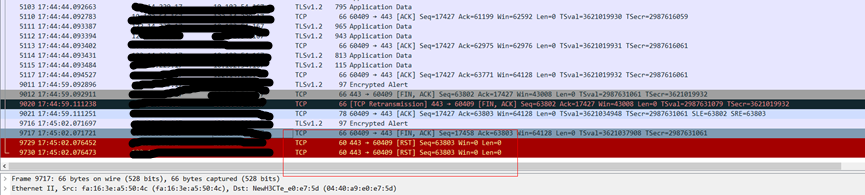
为了方便大家理解,我从网上找了一张图,大家可以作为参考:
CLOSE_WAIT是一种被动关闭状态,如果是SERVER主动断开的连接,那么就会在CLIENT出现CLOSE_WAIT的状态,反之同理;
通常情况下,如果客户端在一次http请求完成后没有及时关闭流(tcp中的流套接字),那么超时后服务端就会主动发送关闭连接的FIN,客户端没有主动关闭,所以就停留在了CLOSE_WAIT状态,如果是这种情况,很快连接池中的连接就会被耗尽。
所以,我们今天遇到的情况(处于CLOSE_WAIT状态的连接数每天都在缓慢增长),更像是某一种异常场景导致的连接没有关闭。
为了不影响其他业务场景,防止出现系统性风险,我们先把问题接口连接池进行了独立管理。
带着2.3的疑问我们仔细查看一下业务调用代码:
try {
httpResponse = HttpsClientUtil.getHttpClient().execute(request);
HttpEntity httpEntity = httpResponse.getEntity();
is = httpEntity.getContent();
}catch (Exception e){
log.error("");
}finally {
IOUtils.closeQuietly(is);
IOUtils.closeQuietly(httpResponse);
}
这段代码存在一个明显的问题:既关闭了数据传输流( IOUtils.closeQuietly(is)),也关闭了整个连接(IOUtils.closeQuietly(httpResponse)),这样我们就没办法进行连接的复用了;但是却更让人疑惑了:既然每次都手动关闭了连接,为什么还会有大量CLOSE_WAIT状态的连接存在呢?
如果问题不在业务调用代码上,那么只能是这个业务接口具有的某种特殊性导致了问题的发生;通过抓包分析发现该接口有一个明显特征:接口返回报文较大,平均在500KB左右。那么问题就极有可能是报文过大导致了某种异常,造成了连接不能被复用也不能被释放。
开始分析之前,我们需要了解一个基础知识:Http的长连接和短连接。所谓长连接就是建立起连接之后,可以复用连接多次进行数据传输;而短连接则是每次都需要重新建立连接再进行数据传输。
而通过对接口的抓包我们发现,响应头里有Connection:keep-live字样,那我们就可以重点从HttpClient对长连接的管理入手来进行代码分析。
初始化方法:
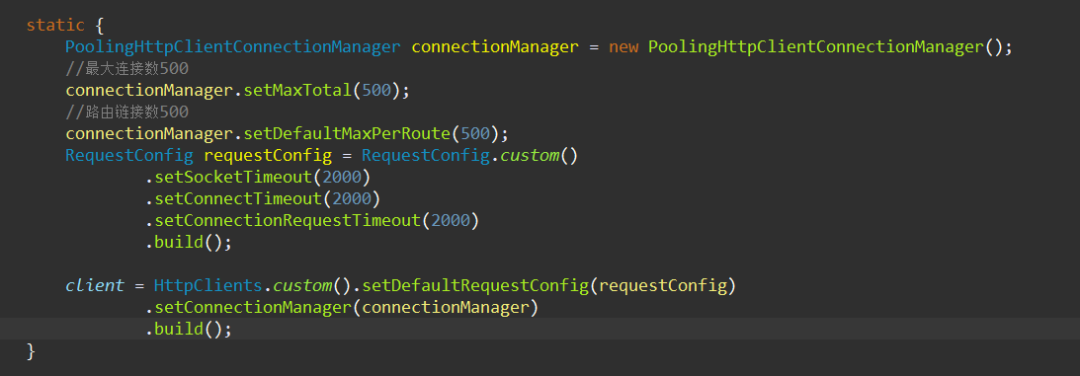
进入PoolingHttpClientConnectionManager这个类,有一个重载构造方法里包含连接存活时间参数:
顺着继续向下查看
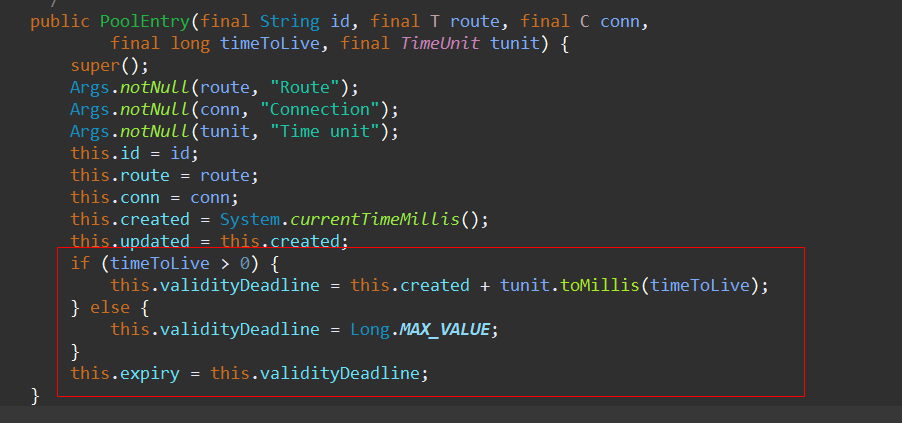
manager的构造方法到此结束,我们不难发现validityDeadline会被赋值给expiry变量,那我们接下来就要看下HttpClient是在哪里使用expiry这个参数的;
通常情况下,实例对象被构建出来的时候会初始化一些策略参数,此时我们需要查看构建HttpClient实例的方法来寻找答案:

此方法包含一系列的初始化操作,包括构建连接池,给连接池设置最大连接数,指定重用策略和长连接策略等,这里我们还注意到,HttpClient创建了一个异步线程,去监听清理空闲连接。
当然,前提是你打开了自动清理空闲连接的配置,默认是关闭的。
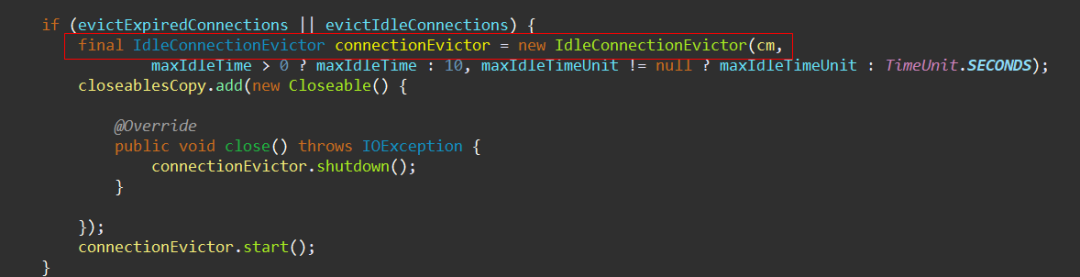
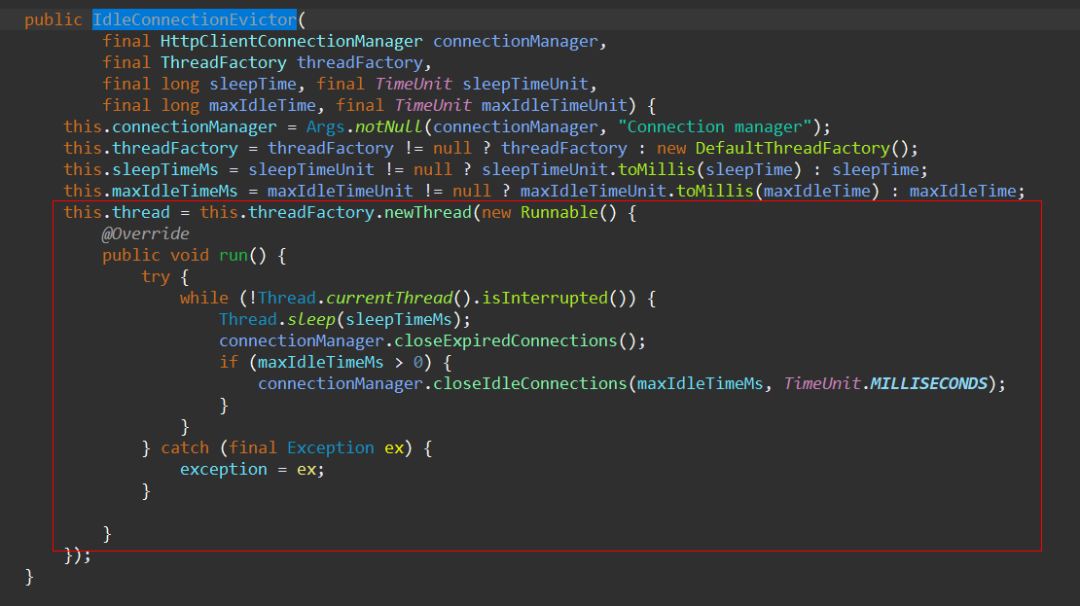
接着我们就看到了HttpClient关闭空闲连接的具体实现,里面有我们想要看到的内容:
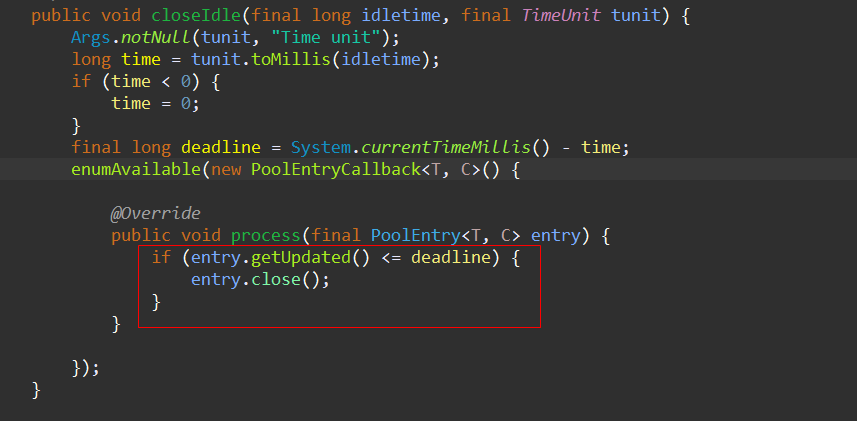
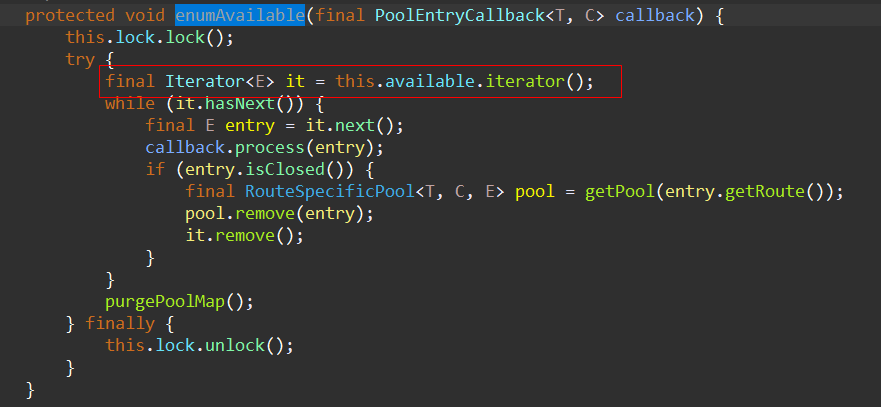
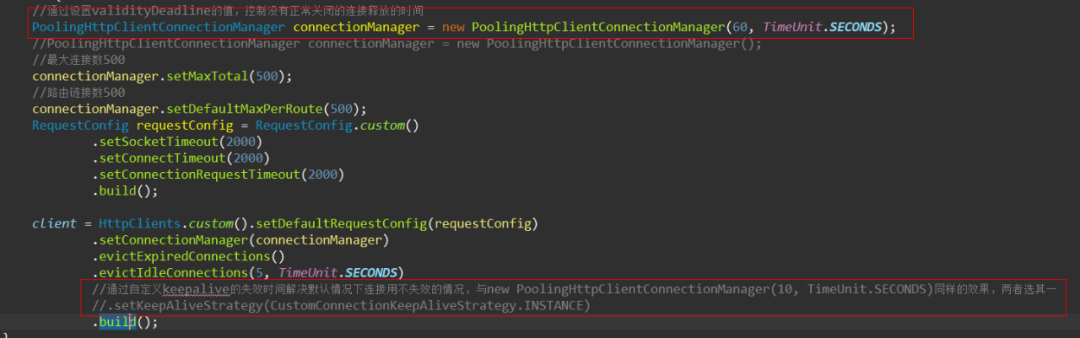
此时,我们可以得出第一个结论:可以在初始化连接池的时候,通过实现带参的PoolingHttpClientConnectionManager构造方法,修改validityDeadline的值,从而影响HttpClient对长连接的管理策略。
2.6.2 执行方法入口
先找到执行入口方法:org.apache.http.impl.execchain.MainClientExec.execute,看到了keepalive相关代码实现:
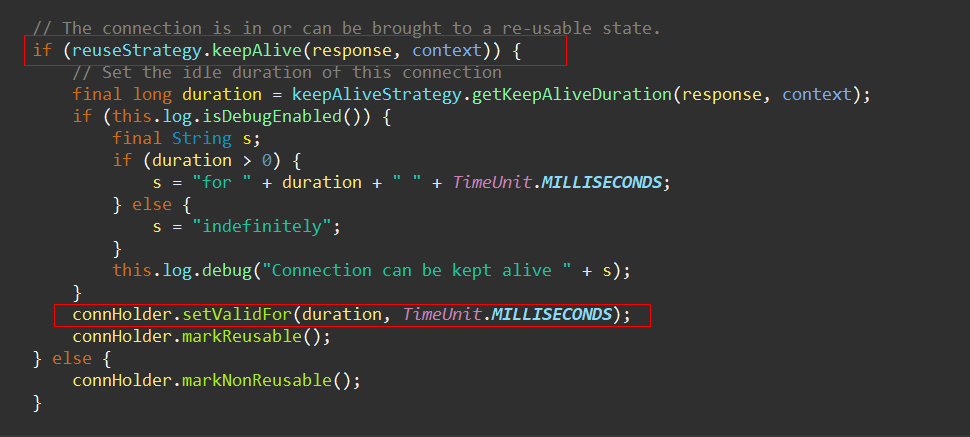
我们来看下默认的策略:
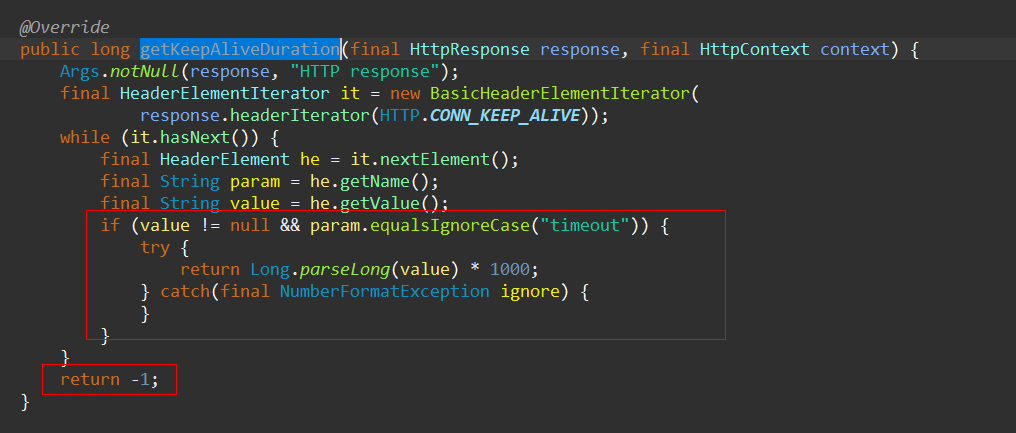
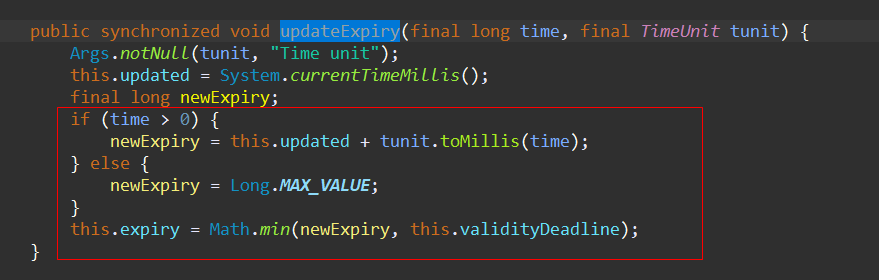
由于中间的调用逻辑比较简单,就不在这里一一把调用的链路贴出来了,这边直接给结论:HttpClient对没有指定连接有效时间的长连接,有效期设置为永久(Long.MAX_VALUE)。
综合以上分析,我们可以得出最终结论:
HttpClient通过控制newExpiry和validityDeadline来实现对长连接的有效期的管理,而且对没有指定连接有效时间的长连接,有效期设置为永久。
至此我们可以大胆给出一个猜测:长连接的有效期是永久,而因为某种异常导致长连接没有被及时关闭,而永久存活了下来,不能被复用也不能被释放。(只是根据现象的猜测,虽然最后被证实并不完全正确,但确实提高了我们解决问题的效率)。
基于此,我们也可以通过改变这两个参数来实现对长连接的管理:
这样简单修改上线后,处于close_wait状态的连接数没有再持续增长,这个线上问题也算是得到了彻底的解决。
但此时相信大家也都存在一个疑问:作为被广泛使用的开源框架,HttpClient难道对长连接的管理这么粗糙吗?一个简单的异常调用就能导致整个调度机制彻底崩溃,而且不会自行恢复;
于是带着疑问,再一次详细查看了HttpClient的源码。
开始分析之前,先简单介绍下几个核心类:
【PoolingHttpClientConnectionManager】:连接池管理器类,主要作用是管理连接和连接池,封装连接的创建、状态流转以及连接池的相关操作,是操作连接和连接池的入口方法;
【CPool】:连接池的具体实现类,连接和连接池的具体实现均在CPool以及抽象类AbstractConnPool中实现,也是分析的重点;
【CPoolEntry】:具体的连接封装类,包含连接的一些基础属性和基础操作,比如连接id,创建时间,有效期等;
【HttpClientBuilder】:HttpClient的构造器,重点关注build方法;
【MainClientExec】:客户端请求的执行类,是执行的入口,重点关注execute方法;
【ConnectionHolder】:主要封装释放连接的方法,是在PoolingHttpClientConnectionManager的基础上进行了封装。
最大连接数(maxTotal)
最大单路由连接数(maxPerRoute)
最大连接数,顾名思义,就是连接池允许创建的最大连接数量;
最大单路由连接数可以理解为同一个域名允许的最大连接数,且所有maxPerRoute的总和不能超过maxTotal。
以浏览器为例,浏览器对接了头条和一点,为了做到业务隔离,不相互影响,可以把maxTotal设置成500,而defaultMaxPerRoute设置成400,主要是因为头条的业务接口量远大于一点,defaultMaxPerRoute需要满足调用量较大的一方。
connectionRequestTimout
connetionTimeout
socketTimeout
【connectionRequestTimout】:指从连接池获取连接的超时时间;
【connetionTimeout】:指客户端和服务器建立连接的超时时间,超时后会报ConnectionTimeOutException异常;
【socketTimeout】:指客户端和服务器建立连接后,数据传输过程中数据包之间间隔的最大时间,超出后会抛出SocketTimeOutException。
一定要注意:这里的超时不是数据传输完成,而只是接收到两个数据包的间隔时间,这也是很多线上诡异问题发生的根本原因。
free
leased
pending
available
【free】:空闲连接的容器,连接还没有建立,理论上freeSize=maxTotal -leasedSize
- availableSize(其实HttpClient中并没有该容器,只是为了描述方便,特意引入的一个容器)。
【leased】:租赁连接的容器,连接创建后,会从free容器转移到leased容器;也可以直接从available容器租赁连接,租赁成功后连接被放在leased容器中,此种场景主要是连接的复用,也是连接池的一个很重要的能力。
【pending】:等待连接的容器,其实该容器只是在等待连接释放的时候用作阻塞线程,下文也不会再提到,感兴趣的可以参考具体实现代码,其与connectionRequestTimout相关。
【available】:可复用连接的容器,通常直接从leased容器转移过来,长连接的情况下完成通信后,会把连接放到available列表,一些对连接的管理和释放通常都是围绕该容器进行的。
注:由于存在maxTotal和maxPerRoute两个连接数限制,下文在提到这四种容器时,如果没有带前缀,都代表是总连接数,如果是r.xxxx则代表是路由连接里的某个容器大小。
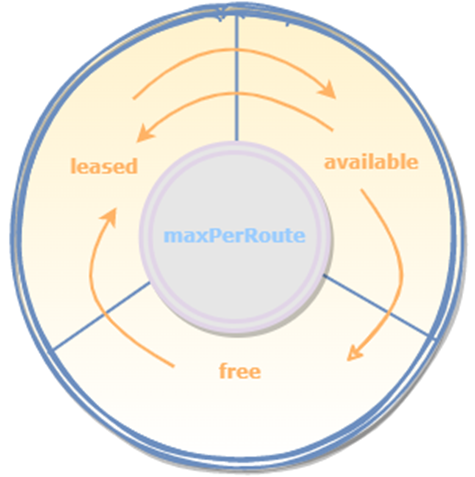
maxTotal的组成
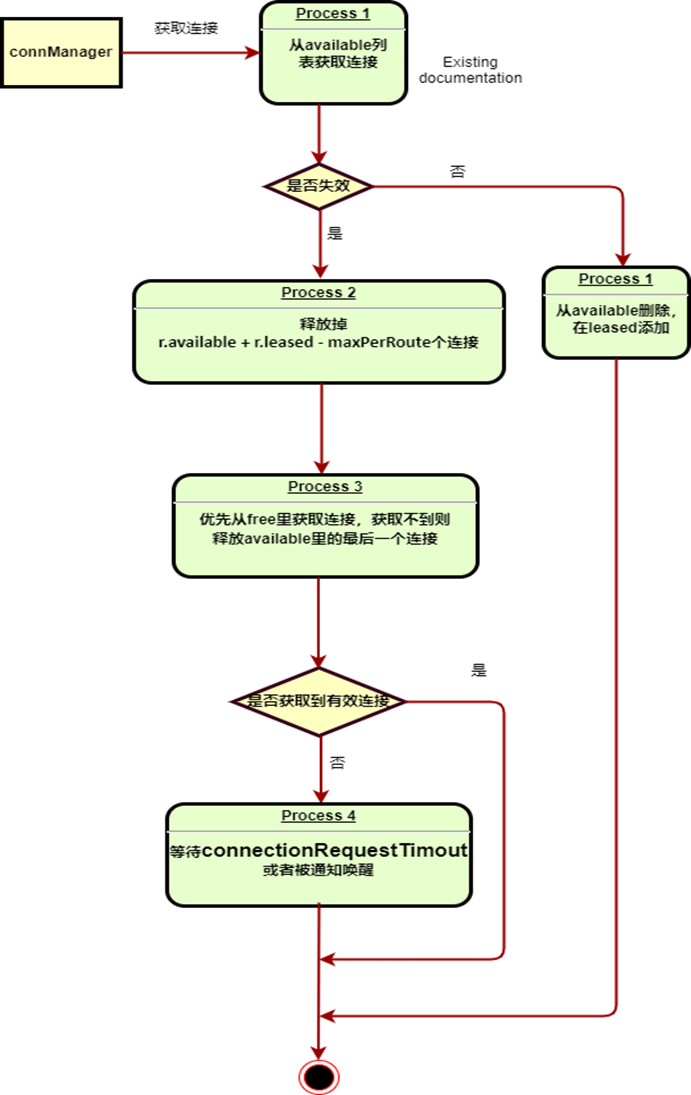
循环从available容器中获取连接,如果该连接未失效(根据上文提到的expiry字段判断),则把该连接从available容器中删除,并添加到leased容器,并返回该连接;
如果在第一步中没有获取到可用连接,则判断r.available + r.leased是否大于maxPerRoute,其实就是判断是否还有free连接;如果不存在,则需要把多余分配的连接释放掉(r. available + r.leased - maxPerRoute),来保证真实的连接数受maxPerRoute控制(至于为什么会出现r.leased+r.available>maxPerRoute的情况其实也很好理解,虽然在整个状态流转过程都加了锁,但是状态的流转并不是原子操作,存在一些异常的场景都会导致状态短时间不正确);所以我们可以得出结论,maxPerRoute只是一个理论上的最大数值,其实真实产生的连接数在短时间内是可能大于这个值的;
在真实的连接数(r .leased+ r .available)小于maxPerRoute且maxTotal>leased的情况下:如果free>0,则重新创建一个连接;如果free=0,则把available容器里的最早创建的一个连接关闭掉,然后再重新创建一个连接;看起来有点绕,其实就是优先使用free容器里的连接,获取不到再释放available容器里的连接;
如果经过上述过程仍然没有获取到可用连接,那就只能等待一个connectionRequestTimout时间,或者有其他线程的信号通知来结束整个获取连接的过程。
如果是长连接(reusable),则把该连接从leased容器中删除,然后添加到available容器的头部,设置有效期为expiry;
如果是短连接(non-reusable),则直接关闭该连接,并且从released容器中删除,此时的连接被释放,处于free容器中;
最后,唤醒“连接的产生与管理“第四部中的等待线程。
整个过程分析完,了解了httpclient如何管理连接,再回头来看我们遇到的那个问题就比较清晰了:
正常情况下,虽然建立了长连接,但是我们会在finally代码块里去手动关闭,此场景其实是触发了“连接的释放”中的步骤2,连接直接被关闭;所以正常情况下是没有问题的,长连接其实并没有发挥真正的作用;
那问题自然就只能出现在一些异常场景,导致了长连接没有被及时关闭,结合最初的分析,是服务端主动断开了连接,那大概率出现在一些超时导致连接断开的异常场景,我们再回到org.apache.http.impl.execchain.MainClientExec这个类,发现这样几行代码:
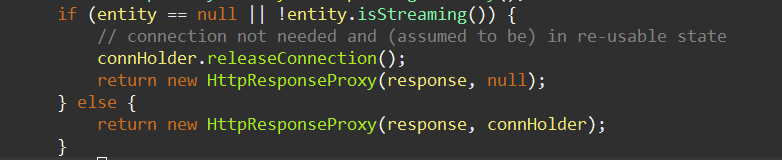
connHolder.releaseConnection()对应“连接的释放”中提到的步骤1,此时连接只是被放入了available容器,并且有效期是永久;
return new HttpResponseProxy(response, null)返回的ConnectionHolder是null,结合IOUtils.closeQuietly(httpResponse)的具体实现,连接并没有及时关闭,而是永久的放在了available容器里,并且状态为CLOSE_WAIT,无法被复用;

根据 “连接的产生与管理”的步骤3的描述,在free容器为空的时候httpclient是能够主动释放available里的连接的,即使连接永久的放在了available容器里,理论上也不会造成连接永远无法释放;
然而再结合“连接的产生与管理”的步骤4,当free容器为空了以后,从连接池获取连接时需要等待available容器里的连接被释放掉,整个过程是单线程的,效率极低,势必会造成拥堵,最终导致大量等待获取连接超时报错,这也与我们线上看到的场景相吻合。
连接池的主要功能有两个:连接的管理和连接的复用,在使用连接池的时候一定要注意只需关闭当前数据流,而不要每次都关闭连接,除非你的目标访问地址是完全随机的;
maxTotal和maxPerRoute的设置一定要谨慎,合理的分配参数可以做到业务隔离,但如果无法准确做出评估,可以暂时设置成一样,或者用两个独立的httpclient实例;
一定记得要设置长连接的有效期,用
PoolingHttpClientConnectionManager(60, TimeUnit.SECONDS)构造函数,尤其是调用量较大的情况,防止发生不可预知的问题;
可以通过设置evictIdleConnections(5, TimeUnit.SECONDS)定时清理空闲连接,尤其是http接口响应时间短,并发量大的情况下,及时清理空闲连接,避免从连接池获取连接的时候发现连接过期再去关闭连接,能在一定程度上提高接口性能。
HttpClient作为当前使用最广泛的基于Java语言的Http调用框架,在笔者看来其存在两点明显不足:
没有提供监控连接状态的入口,也没有提供能外部介入动态影响连接生命周期的扩展点,一旦线上出现问题可能就是致命的;
此外,其获取连接的方式是采用同步锁的方式,在并发较高的情况下存在一定的性能瓶颈,而且其对长连接的管理方式存在问题,稍不注意就会导致建立大量异常长连接而无法及时释放,造成系统性灾难。
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
我正在尝试在Ruby中制作一个cli应用程序,它接受一个给定的数组,然后将其显示为一个列表,我可以使用箭头键浏览它。我觉得我已经在Ruby中看到一个库已经这样做了,但我记不起它的名字了。我正在尝试对soundcloud2000中的代码进行逆向工程做类似的事情,但他的代码与SoundcloudAPI的使用紧密耦合。我知道cursesgem,我正在考虑更抽象的东西。广告有没有人见过可以做到这一点的库或一些概念证明的Ruby代码可以做到这一点? 最佳答案 我不知道这是否是您正在寻找的,但也许您可以使用我的想法。由于我没有关于您要完成的工作
我的主要目标是能够完全理解我正在使用的库/gem。我尝试在Github上从头到尾阅读源代码,但这真的很难。我认为更有趣、更温和的踏脚石就是在使用时阅读每个库/gem方法的源代码。例如,我想知道RubyonRails中的redirect_to方法是如何工作的:如何查找redirect_to方法的源代码?我知道在pry中我可以执行类似show-methodmethod的操作,但我如何才能对Rails框架中的方法执行此操作?您对我如何更好地理解Gem及其API有什么建议吗?仅仅阅读源代码似乎真的很难,尤其是对于框架。谢谢! 最佳答案 Ru
导读:随着叮咚买菜业务的发展,不同的业务场景对数据分析提出了不同的需求,他们希望引入一款实时OLAP数据库,构建一个灵活的多维实时查询和分析的平台,统一数据的接入和查询方案,解决各业务线对数据高效实时查询和精细化运营的需求。经过调研选型,最终引入ApacheDoris作为最终的OLAP分析引擎,Doris作为核心的OLAP引擎支持复杂地分析操作、提供多维的数据视图,在叮咚买菜数十个业务场景中广泛应用。作者|叮咚买菜资深数据工程师韩青叮咚买菜创立于2017年5月,是一家专注美好食物的创业公司。叮咚买菜专注吃的事业,为满足更多人“想吃什么”而努力,通过美好食材的供应、美好滋味的开发以及美食品牌的孵
我认为我的问题最好用一个例子来描述。假设我有一个名为“Thing”的简单模型,它有一些简单数据类型的属性。像...Thing-foo:string-goo:string-bar:int这并不难。数据库表将包含具有这三个属性的三列,我可以使用@thing.foo或@thing.bar之类的东西访问它们。但我要解决的问题是当“foo”或“goo”不再包含在简单数据类型中时会发生什么?假设foo和goo代表相同类型的对象。也就是说,它们都是“Whazit”的实例,只是数据不同。所以现在事情可能看起来像这样......Thing-bar:int但是现在有一个新的模型叫做“Whazit”,看起来
我有一个要在我的Rails3项目中使用的数组扩展方法。它应该住在哪里?我有一个应用程序/类,我最初把它放在(array_extensions.rb)中,在我的config/application.rb中我加载路径:config.autoload_paths+=%W(#{Rails.root}/应用程序/类)。但是,当我转到railsconsole时,未加载扩展。是否有一个预定义的位置可以放置我的Rails3扩展方法?或者,一种预先定义的方式来添加它们?我知道Rails有自己的数组扩展方法。我应该将我的添加到active_support/core_ext/array/conversion
在我的路线文件中我有:match'graphs/(:id(/:action))'=>'graphs#(:action)'如果是GET请求(工作)或POST请求(不工作),我想匹配它我知道我可以使用以下方法在资源中声明POST请求:post'/'=>:show,:on=>:member但是我怎样才能为比赛做到这一点呢?谢谢。 最佳答案 如果你同时想要POST和GETmatch'graphs/(:id(/:action))'=>'graphs#(:action)',:via=>[:get,:post]编辑默认值可以设置如下match'g
我要下载http://foobar.com/song.mp3作为song.mp3,而不是让Chrome在其native中打开它浏览器中的播放器。我怎样才能做到这一点? 最佳答案 您只需要确保发送这些header:Content-Disposition:attachment;filename=song.mp3;Content-Type:application/octet-streamContent-Transfer-Encoding:binarysend_file方法为您完成:get'/:file'do|file|file=File.
参见下面的示例,我想最好使用第二种方法,但第一种也可以。哪种方法最好,使用另一种的后果是什么?classTestdefstartp"started"endtest=Test.newtest.startendclassTest2defstartp"started"endendtest2=Test2.newtest2.start 最佳答案 我肯定会说第二种变体更有意义。第一个不会导致错误,但对象实例化完全过时且毫无意义。外部变量在类的范围内不可见:var="string"classAvar=A.newendputsvar#=>strin
如何通过HTTPClient使用持久HTTP连接?发送HTTP请求时是否只是设置KeepAlive的问题?文档指出支持持久连接,但没有告诉我们如何使用它们。 最佳答案 是availableinNet::HTTP如文档中所写,Net::HTTP.startimmediatelycreatesaconnectiontoanHTTPserverwhichiskeptopenforthedurationoftheblock.Theconnectionwillremainopenformultiplerequestsintheblockift